2-7 サンプリングノード[レコード設定タブ]
1.ノードの目的
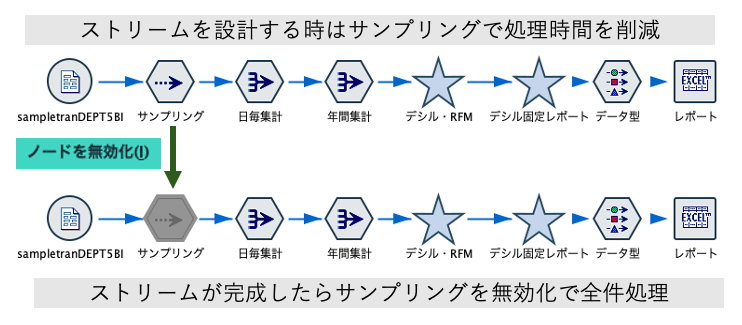
レコードをサンプリングします。対象データが大規模な場合、サンプルデータでストリームを設計し完了後に全件データで処理することでプロジェクトの時間を短縮します。
2.解説動画(60秒)
3.クイックスタート
Webログデータを上から1000件表示します。
*データは[5.参考情報]からダウンロードできます。
[可変長ファイル]、[サンプリング]、[テーブル]の順でノードを接続します。
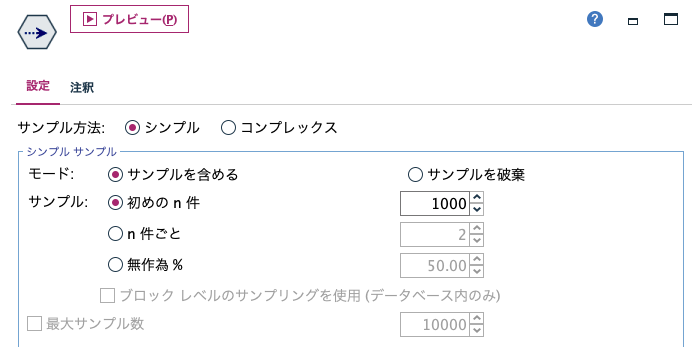
[サンプリング]ノードを編集し[はじめのN件:]を[1000]に設定します。
[テーブル]を実行します。先頭レコードの1000件が表示されています。
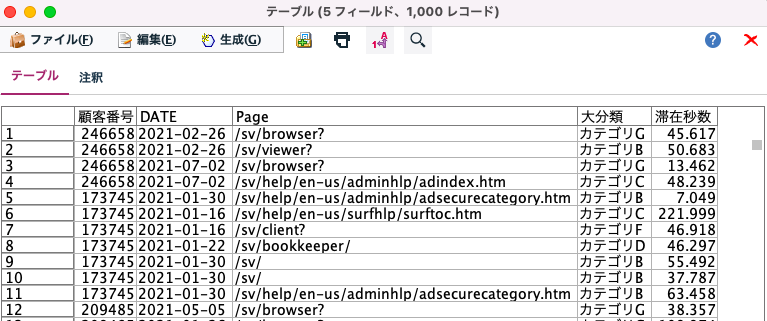
プレビューとの違い
プレビューはどのノードからも10レコード(初期設定)を表示可能です。逆に表示のみなのでグラフや統計量の確認にはサンプリングノードが適しています。

初期設定はツール>ストリームのプロパティで変更できます。
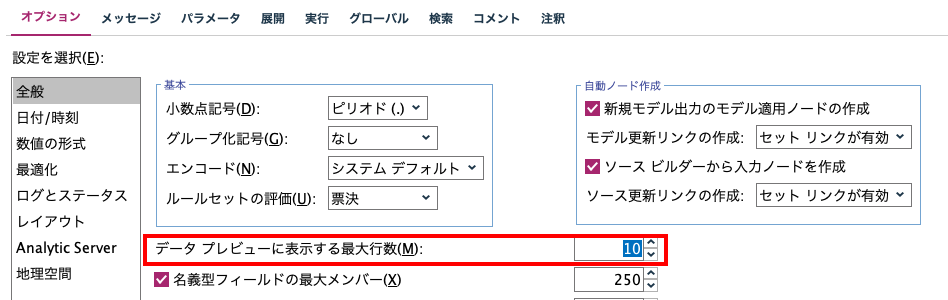
サンプリングノードの注意点
交差検証とランダムサンプリング
交差検証などでデータをランダムに学習用と検証用に分割する際に乱数固定による再現性について注意する必要があります。
ノードリファレンス3-7データ区分でも触れていますが
以下のストリームではランダムに選ばれた5割と、選ばれなかった5割を正確に区分する必要があります。(毎回乱数の影響を受ける可能性を排除)
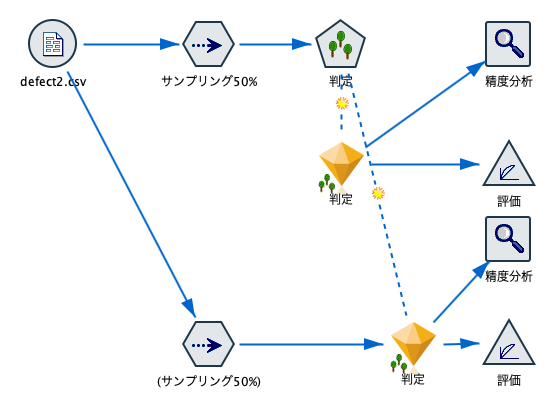
サンプリングノードではまずランダムシードを固定し(青枠)、その上でノードを複製して、一方を[サンプルを破棄]にする必要があります(赤枠)。
乱数を固定するためにキャッシュを利用する方法もあります。
4.Tips
ログやトランザクションのランダム抽出では個体を先にサンプリングする
たとえばWebログを50%にランダムサンプリングする際に、レコード全体で行うと視聴者ごとにログが半分失われ、後続の分析に支障をきたします。まず視聴者を乱数で選抜し、選ばれた視聴者の全てのログを付与する必要があります。
*ハイライトされたレコードが破棄されるイメージです。

具体的なストリームは以下のようになります。
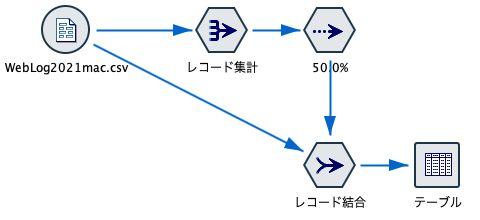
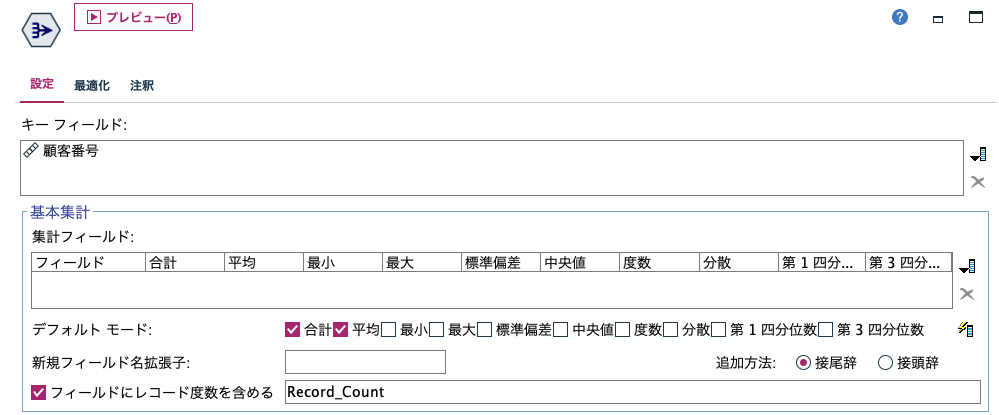
[レコード集計]か[重複]ノードで視聴者を1レコードにします。
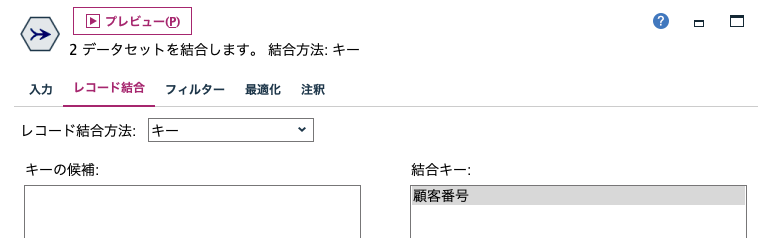
5割にランダムサンプリングした後に、選ばれた視聴者と全体レコードをキーで結合します。
コンプレックスサンプリング
自動車のスペックデータから[生産国]の分布を維持してサンプリングします。
ストリームは次の通りです。
オリジナルデータの生産国の分布です。

[コンプレックス]モードでサンプリングします。[クラスターと階層化]ボタンを押します。
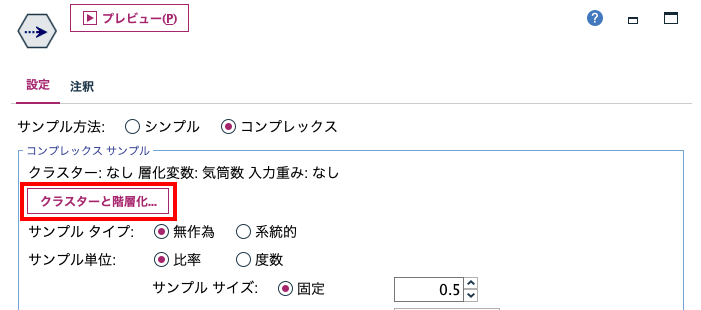
[階層化]に[生産国]を選択します。

[生産国]の比率を維持してランダムに5割サンプリングしました。

5.参考情報
利用データ
右クリックでリンク先を保存してください。
①Webログ
②自動車スペック
SPSS ModelerのサンプリングノードをPythonで書き換える
SQLプッシュバックでソートとサンプリングを組み合わせる場合の注意点
ノードのヘルプ
SPSS Modeler 逆引きストリーム集(データ加工)
SPSS Modeler ノードリファレンス目次