ポジティブ/ネガティブフラグを作成する

この記事はSPSS Modeler Premium Ver18.6から追加された日本語テキスト機能を利用して書いています。SPSS Modeler Professionalをお使いの方はアップグレードするかPython連携を用いて実現します。
Python連携を紹介する記事はこちら
1.想定される利用目的
・文章に含まれるポジティブ/ネガティブの要素をフラグにして集計可能にする。
2.ストリームとデータのダウンロード
ストリーム
3.サンプルストリームの説明
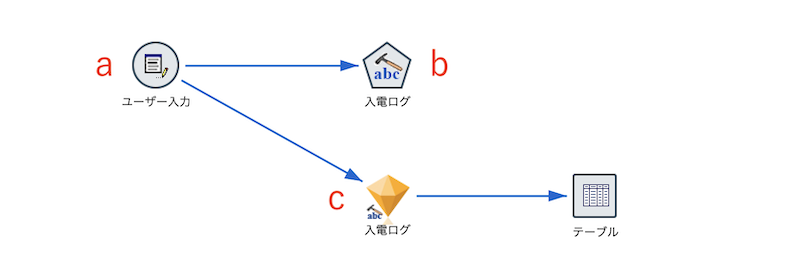
a.入力データは以下の通りです。

b.[テキストマイニング]ノードを編集します。[IDフィールド]と[テキストフィールド]を以下の通り選択します。
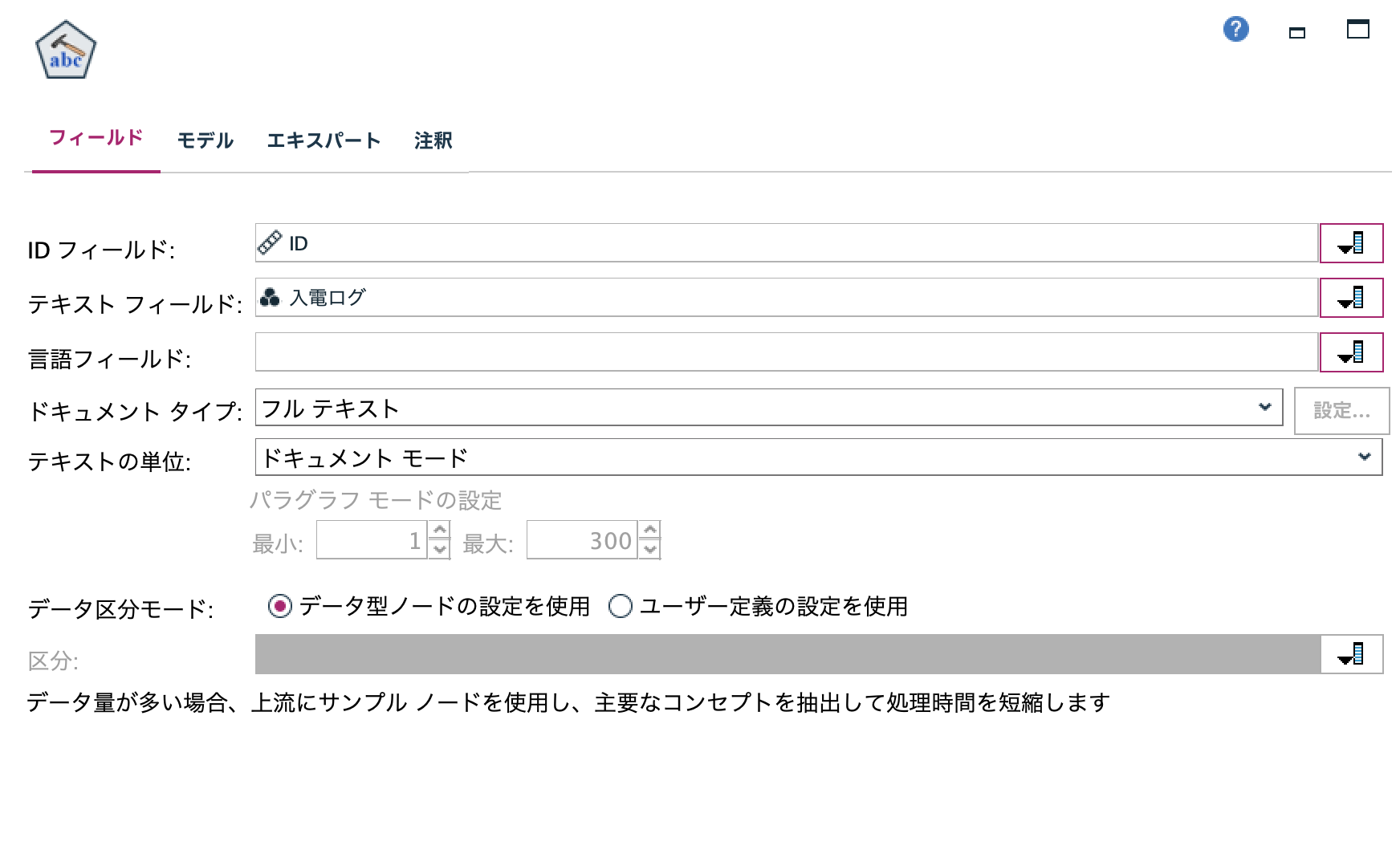
[モデル]タブを編集します。[抽出結果を利用して...]を選択します。感情を識別するために[リソーステンプレート]を[読み込み]ボタンを押して[Opinions(Japanese)]を選択します。

[実行]します。抽出したコンセプトの3つの[Negative]タイプを指定して[カテゴリーに追加]ボタンを押します。
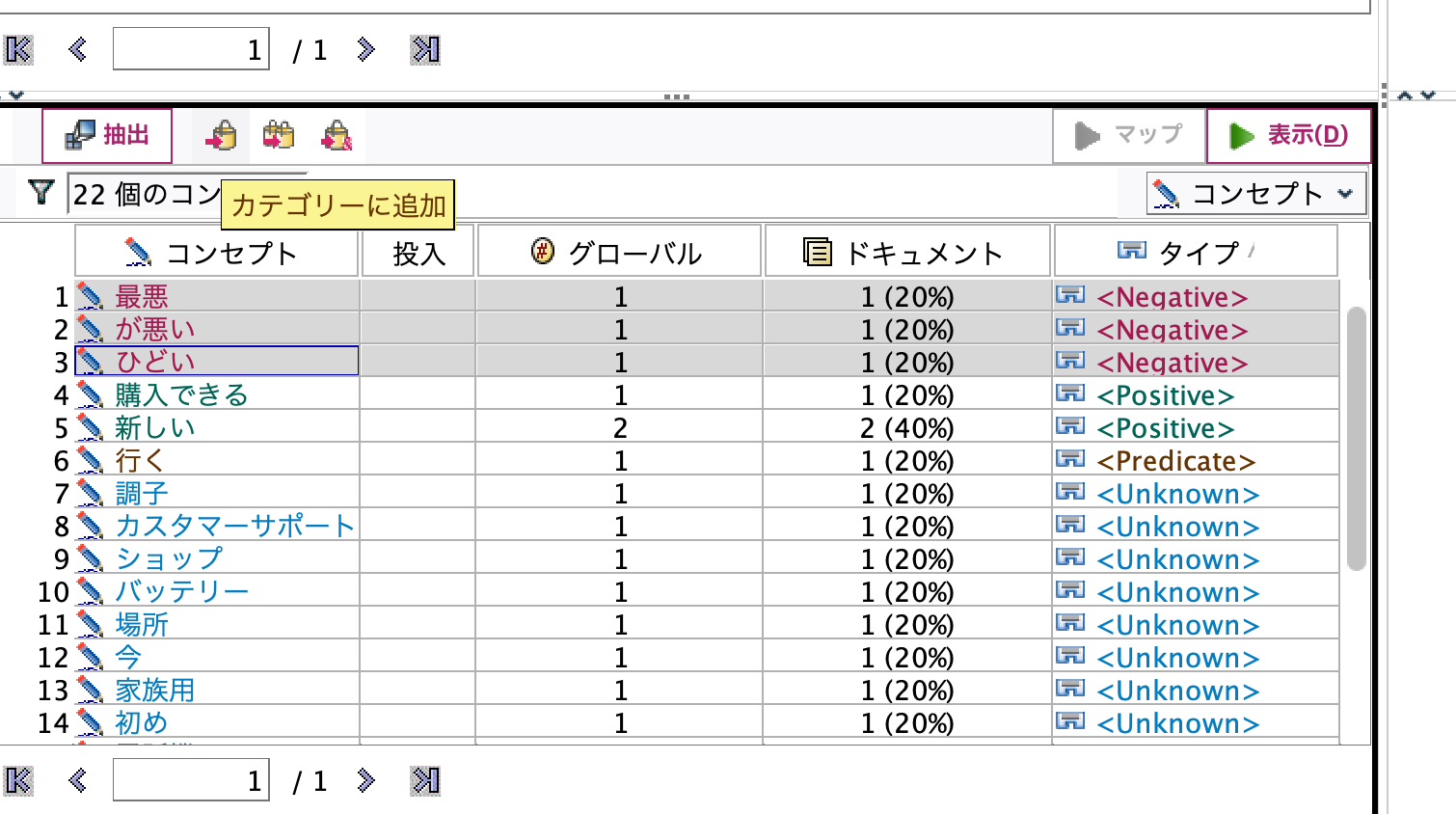
[カテゴリーを新規作成]で[OK]します。

[カテゴリー名を変更]し[ネガティブ]にします。
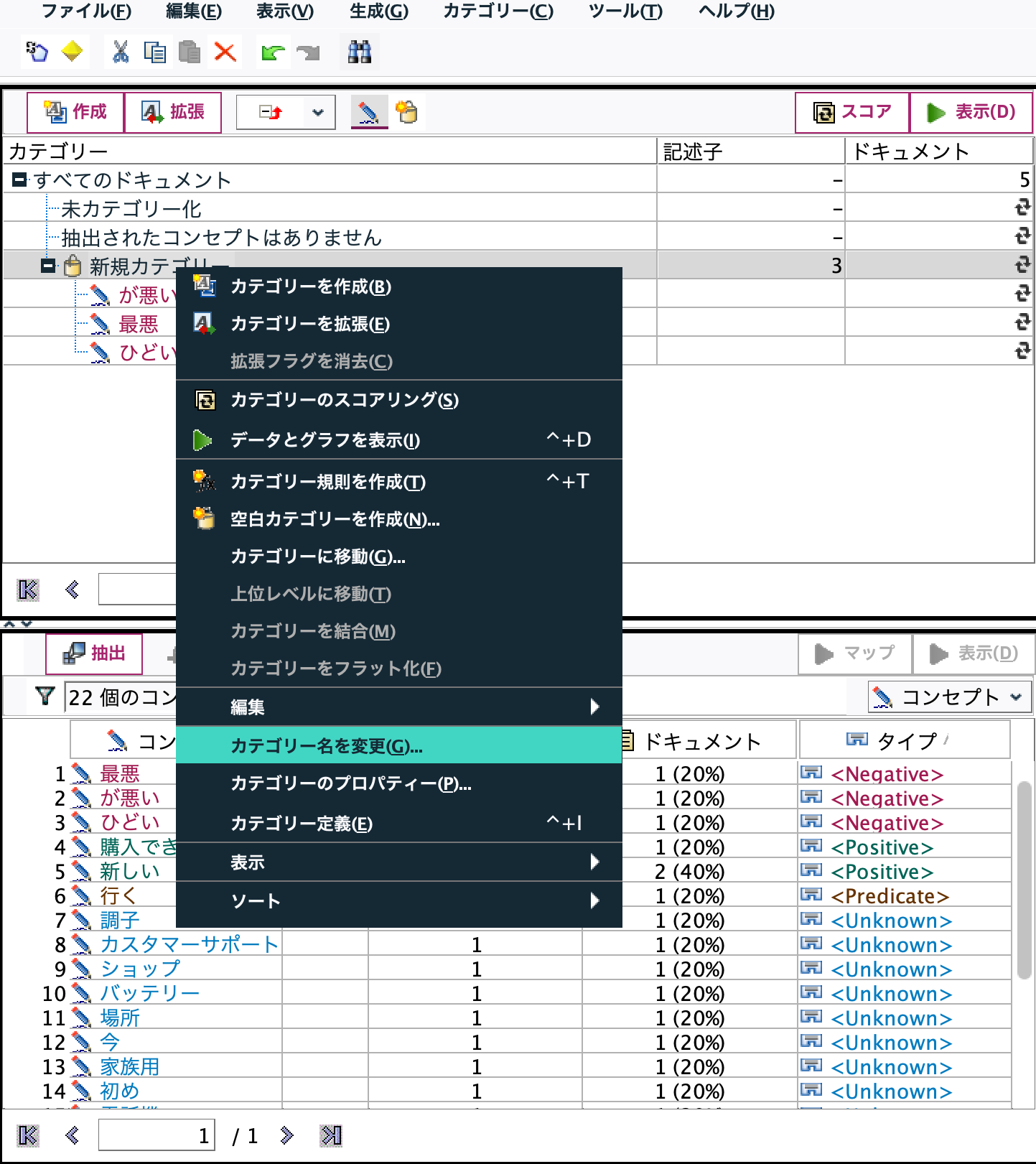
同じようにポジティブを作成します。[ほしい]は[wish]と分類されていますが含めます。
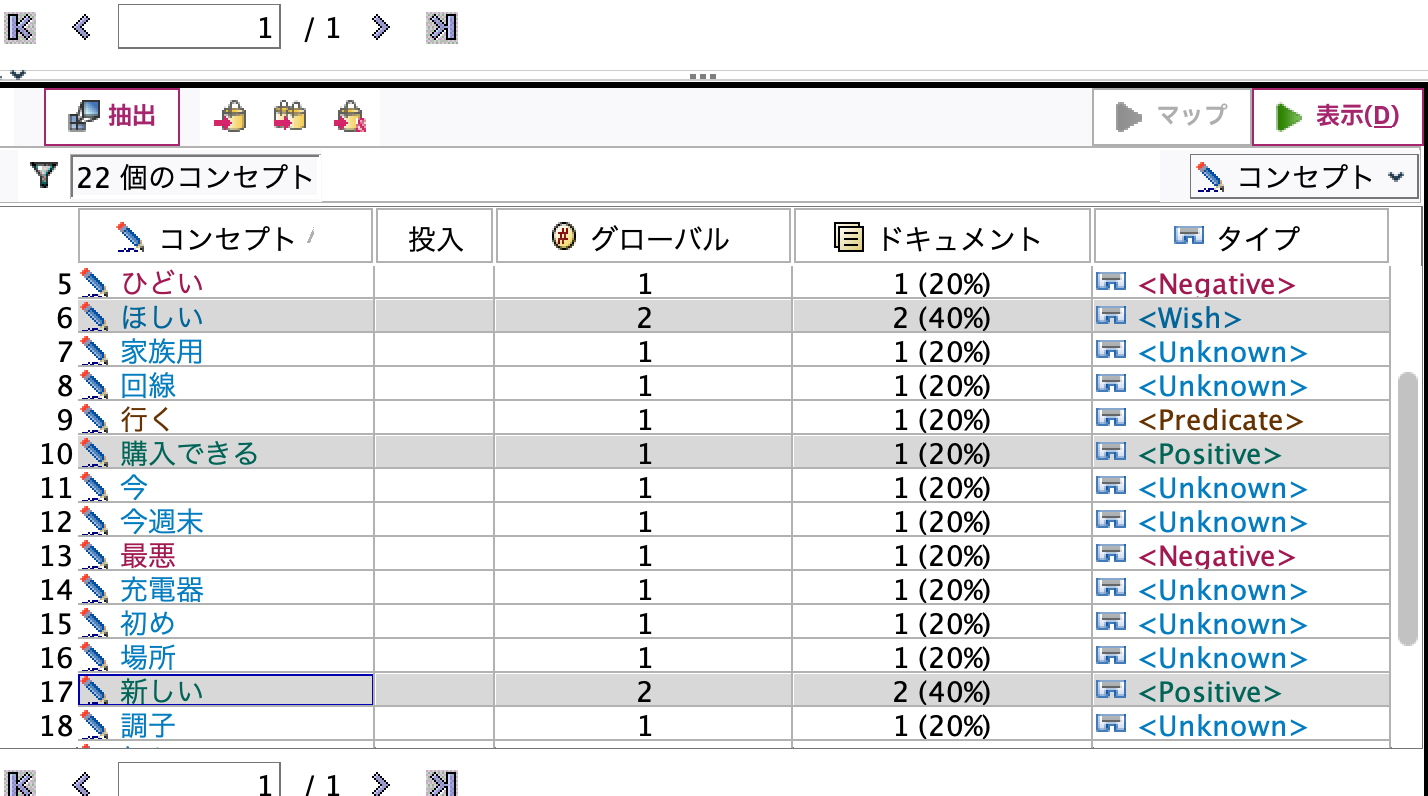
ネガティブとポジティブのカテゴリにそれぞれ3つのコンセプトが登録されました。[モデルを作成]ボタンを押します。cが作成されます。
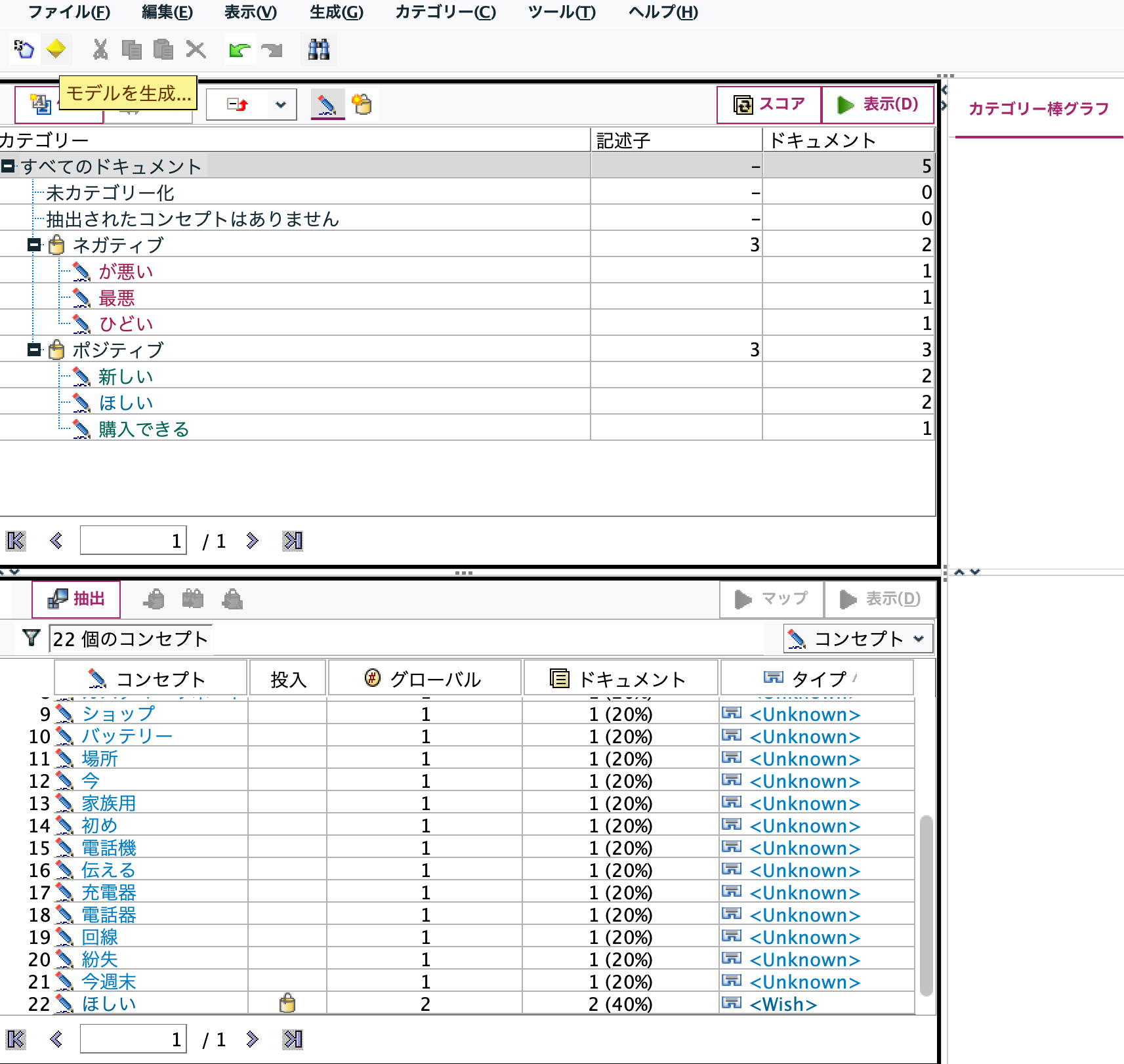
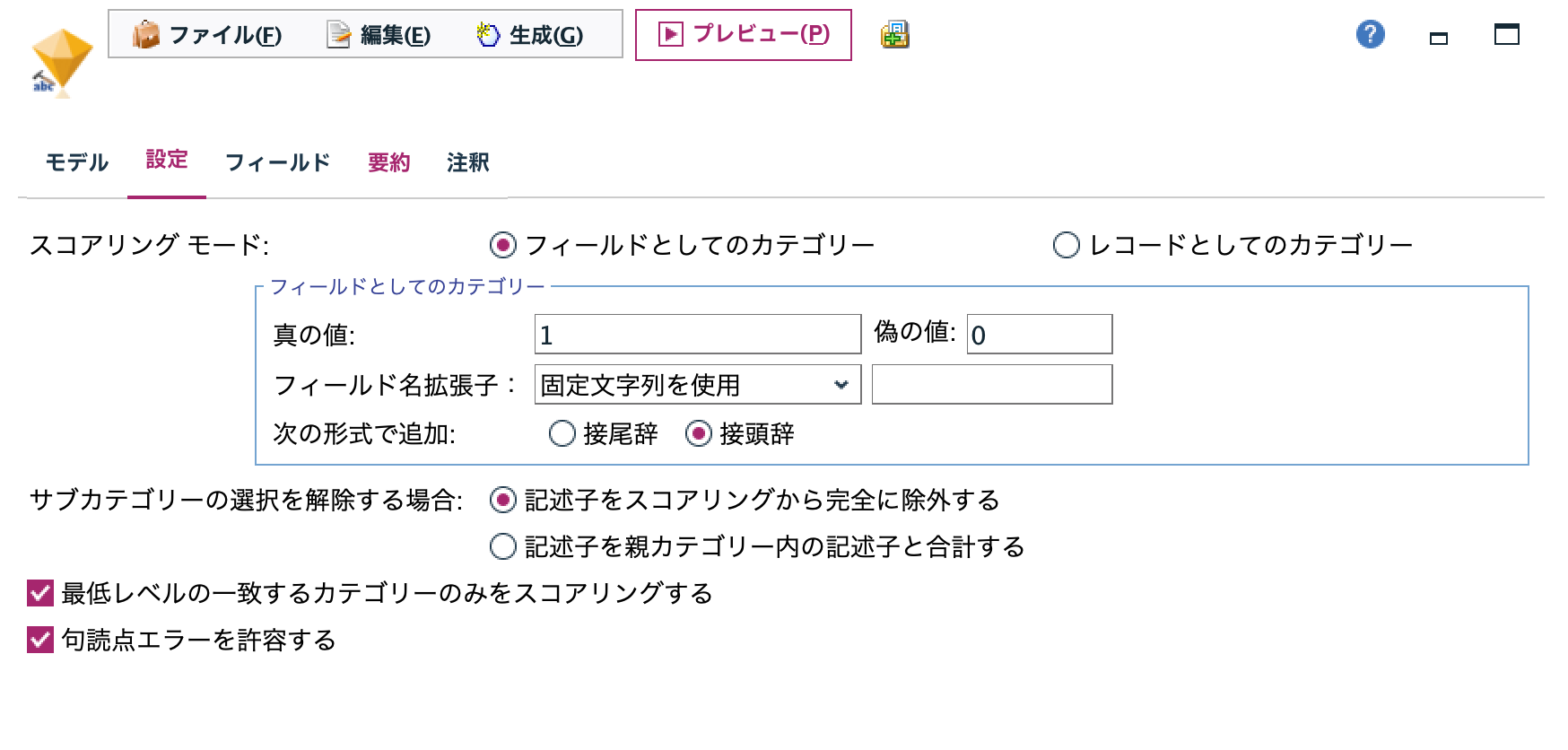
c.[テキストマイニング]ナゲットを編集します。[設定タブ]で真偽をT/Fから1/0へ[フィールド名拡張子]をブランクにします。
注意事項
ネガティブが機能、サービス、価格の何を対象にした評価なのかを階層化して持たせるとより情報量が上がります。
4.参考情報
Python連携によるテキストマイニング
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)