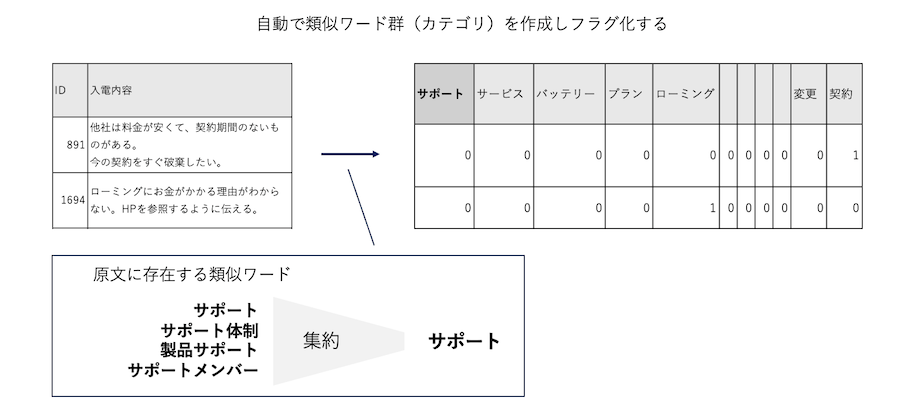
自動で類似ワード群(カテゴリ)を作成しフラグ化する
この記事はSPSS Modeler Premium Ver18.6から追加された日本語テキスト機能を利用して書いています。SPSS Modeler Professionalをお使いの方はアップグレードするかPython連携を用いて実現します。
Python連携を紹介する記事はこちら
1.想定される利用目的
・コンタクトセンターの応答ログから解約に影響する単語の探索
・営業日報のコメントから成約予測モデルの説明変数を作成
・アンケート自由回答データからブランドと評価のポジショニングマップを作成
2.ストリームとデータのダウンロード
ストリーム
データ
3.サンプルストリームの説明
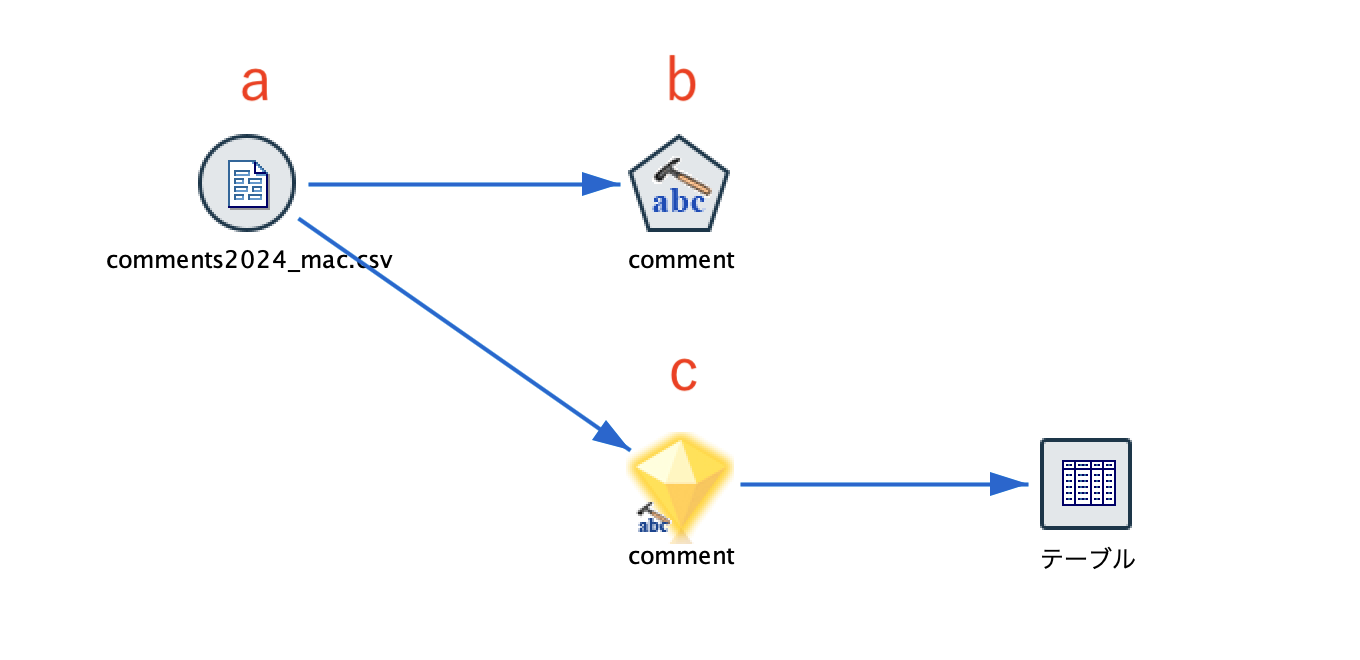
a.入力データは以下の通りです。[comment]列の文章から頻出ワード群を自動作成してフラグ化します。

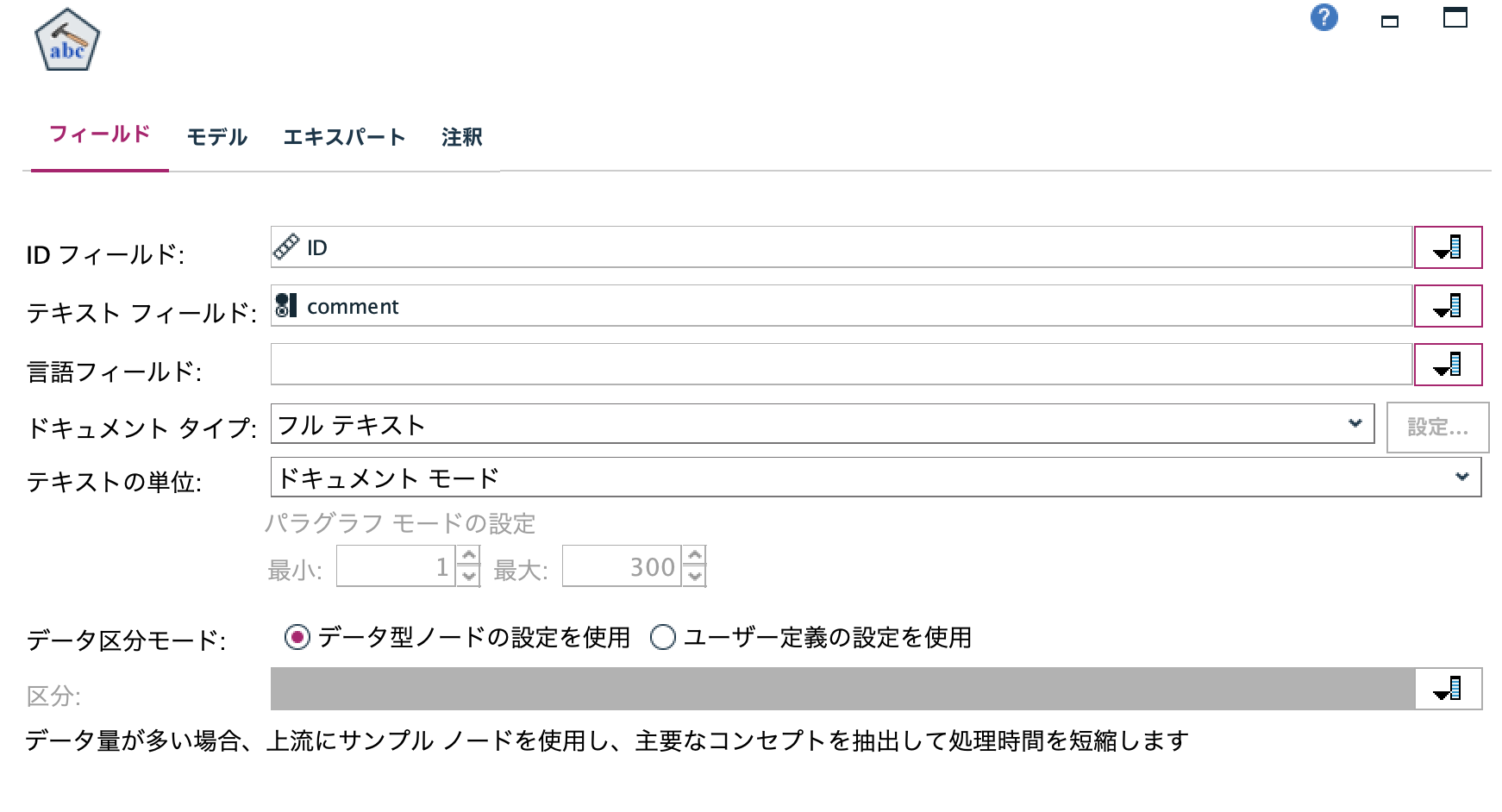
b.[テキストマイニング]ノードを編集します。[IDフィールド]と[テキストフィールド]を以下の通り選択します。
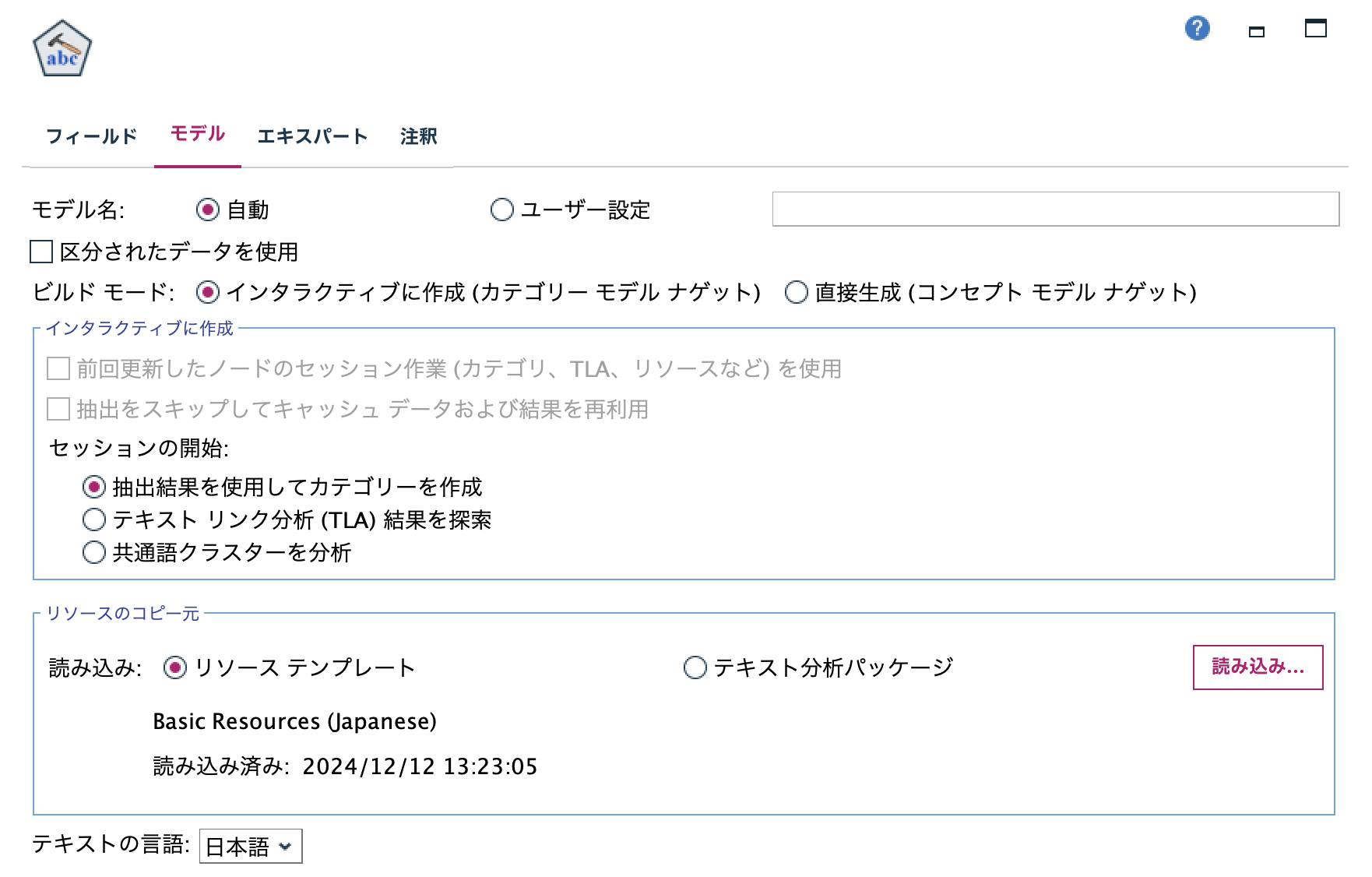
[モデル]タブを以下の通り設定して[実行]します。
以下のインタラクティブウインドウが表示されます。左下の領域に多頻度ワード(コンセプト)が列挙されます。類似ワード群(カテゴリ)を作るため[作成]ボタンを押します。
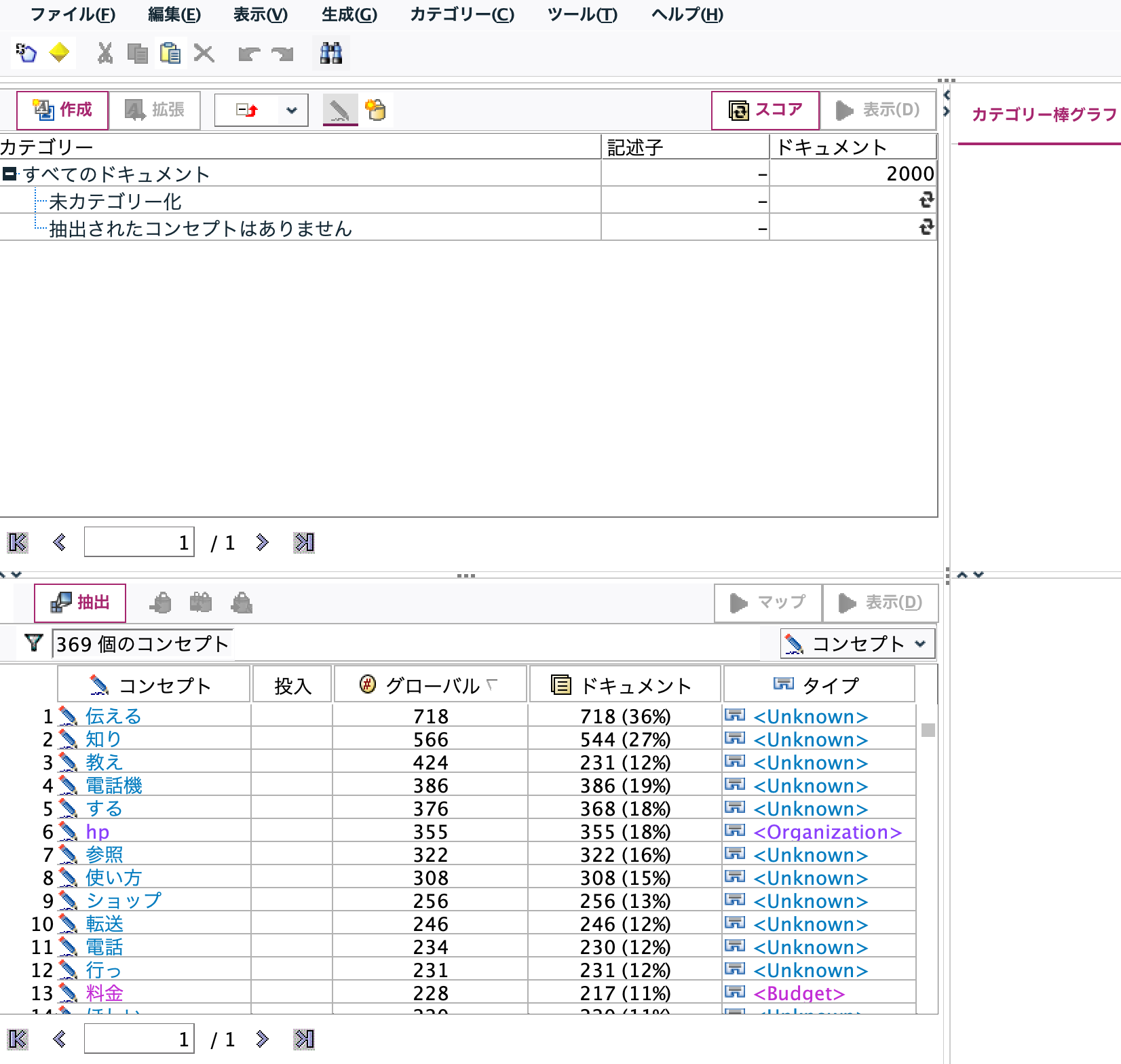
カテゴリが右上に自動的に作成されました。[スコア]ボタンを押します。
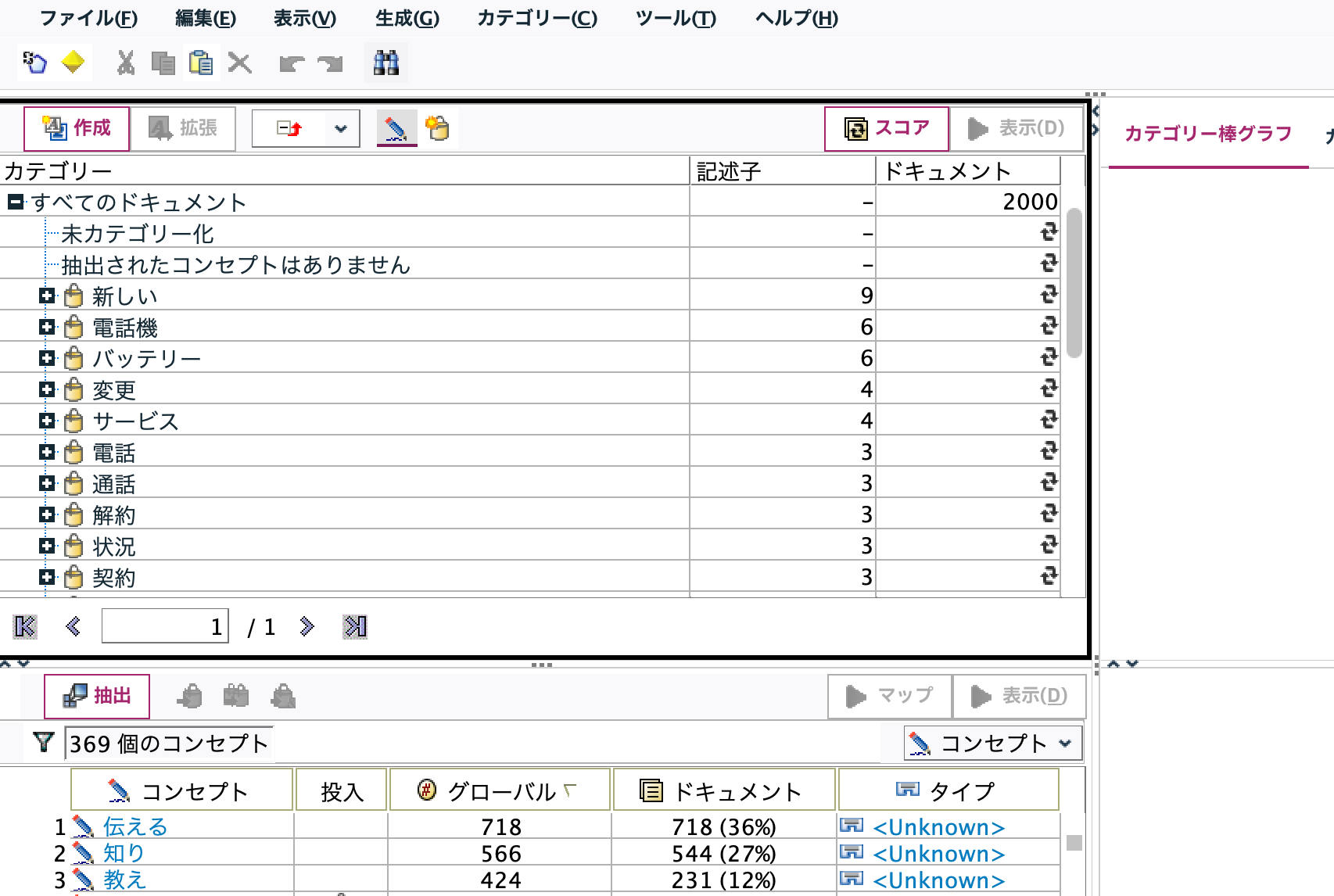
[表示]ボタンを押します。4つの領域にアイテム(コンセプト、カテゴリ、棒グラフ、原文)が表示されているのを確認してから[生成]メニューから[モデルを生成]を選択するとcが生成されます。
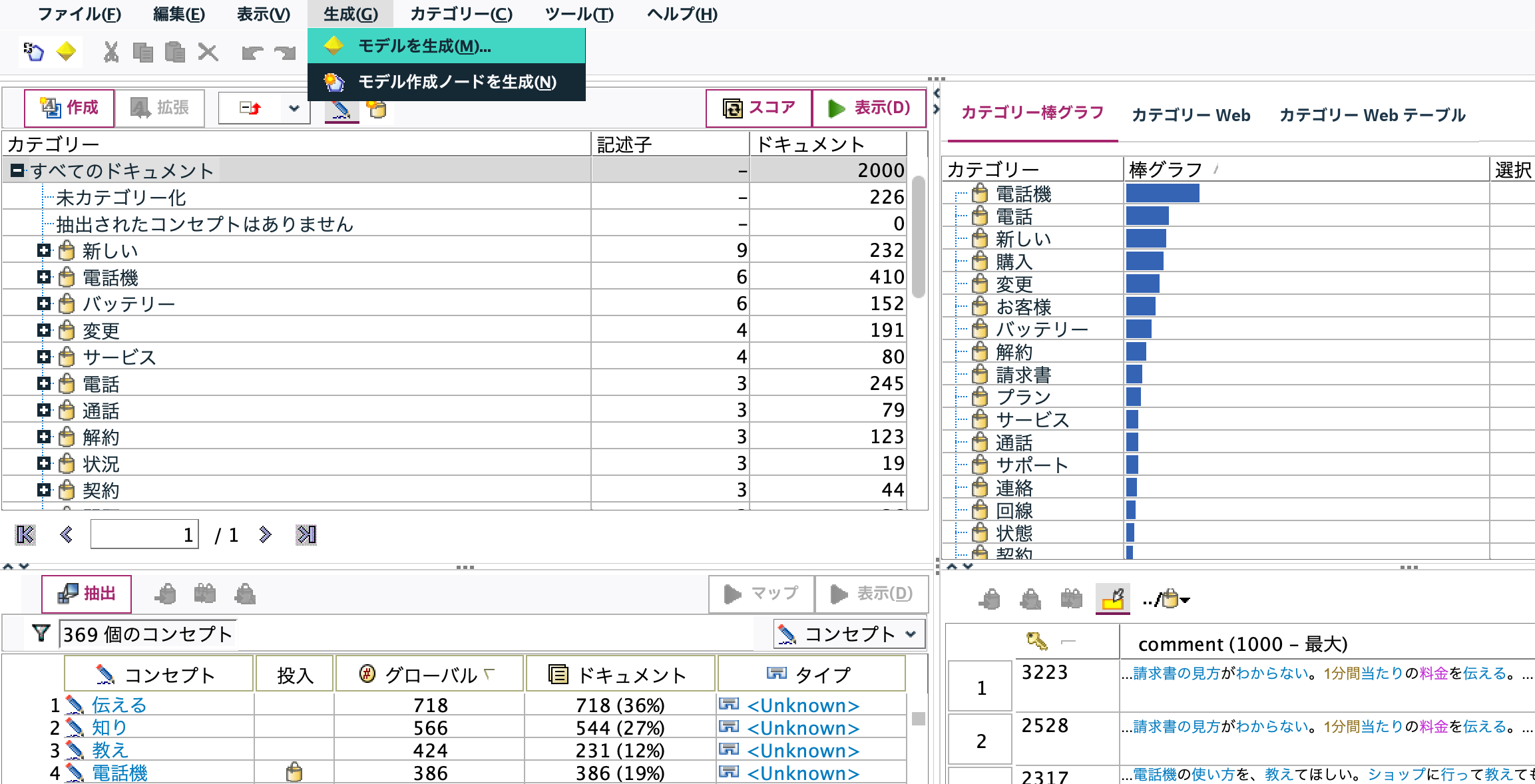
c.[テキストマイニング]ナゲットを編集します。
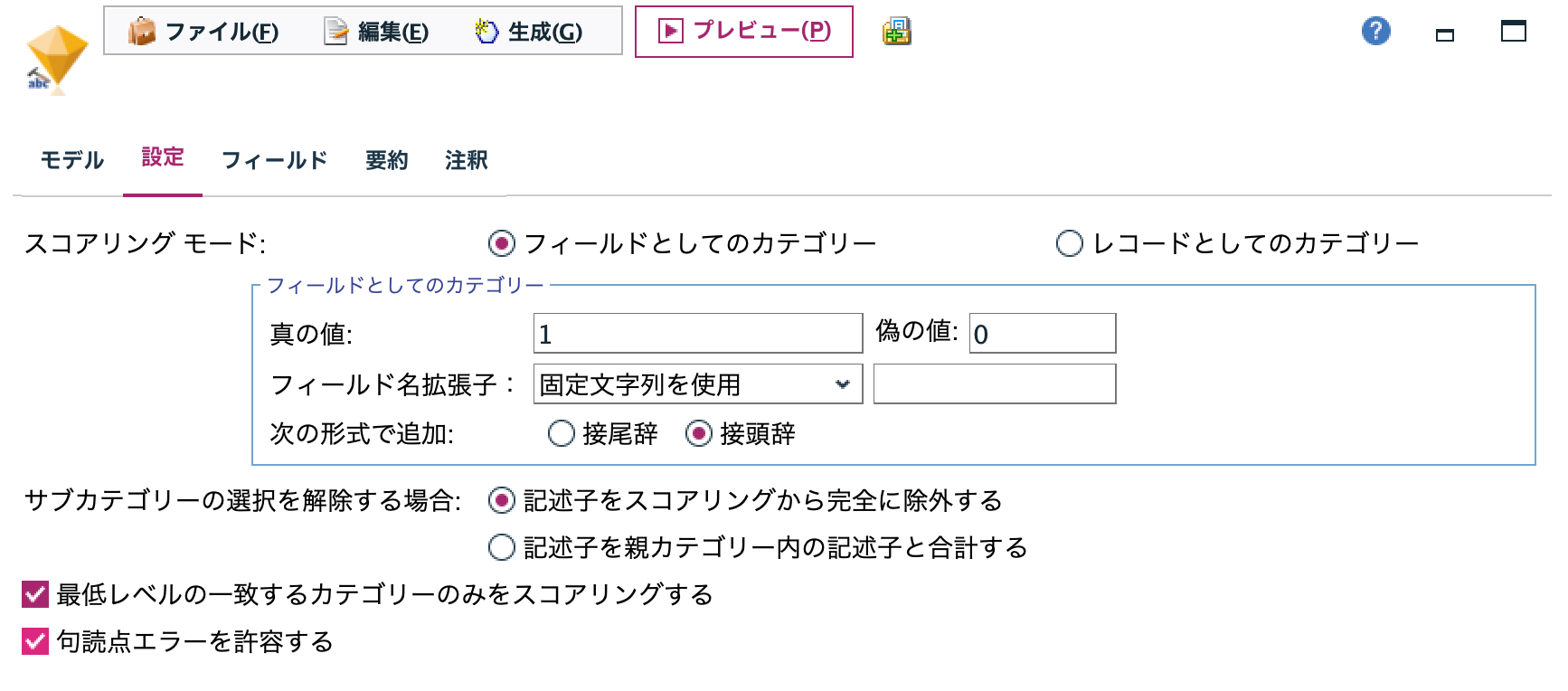
[テーブル]を実行します。

注意事項
本来定性的な情報(原文)から定量情報を抽出するには目的があり、自動で集約されたカテゴリは丁寧に手動で再構成する必要があります。あくまで初動を効率化するための機能と捉えることをお勧めします。
4.参考情報
Python連携によるテキストマイニング
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)