自動で類似ワード群(カテゴリ)を作成しフラグ化する
この記事はSPSS Modeler Premium Ver18.6から追加された日本語テキスト機能を利用して書いています。SPSS Modeler Professionalをお使いの方はアップグレードするかPython連携を用いて実現します。
Python連携を紹介する記事はこちら
1.想定される利用目的
・コンタクトセンターの応答ログから解約に影響する単語の探索
・営業日報のコメントから成約予測モデルの説明変数を作成
・アンケート自由回答データからブランドと評価のポジショニングマップを作成
2.ストリームとデータのダウンロード
ストリーム
データ
3.サンプルストリームの説明
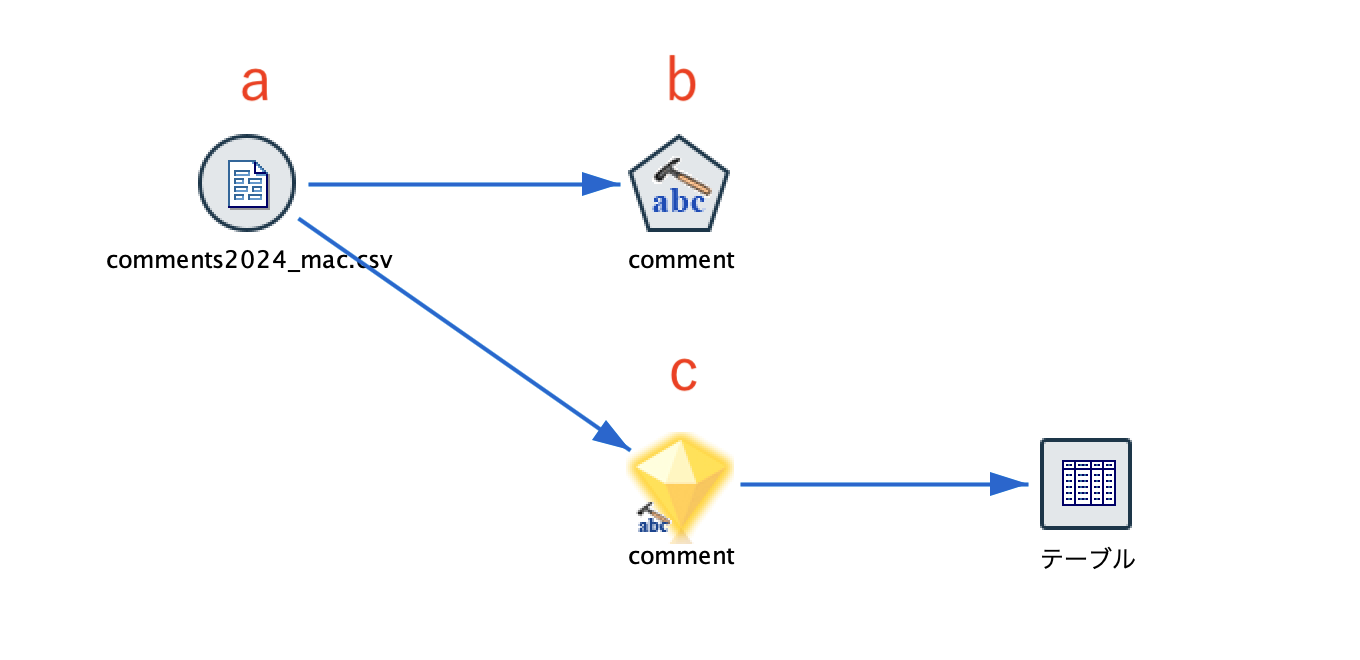
a.入力データは以下の通りです。[comment]列の文章から頻出ワード群を自動作成してフラグ化します。

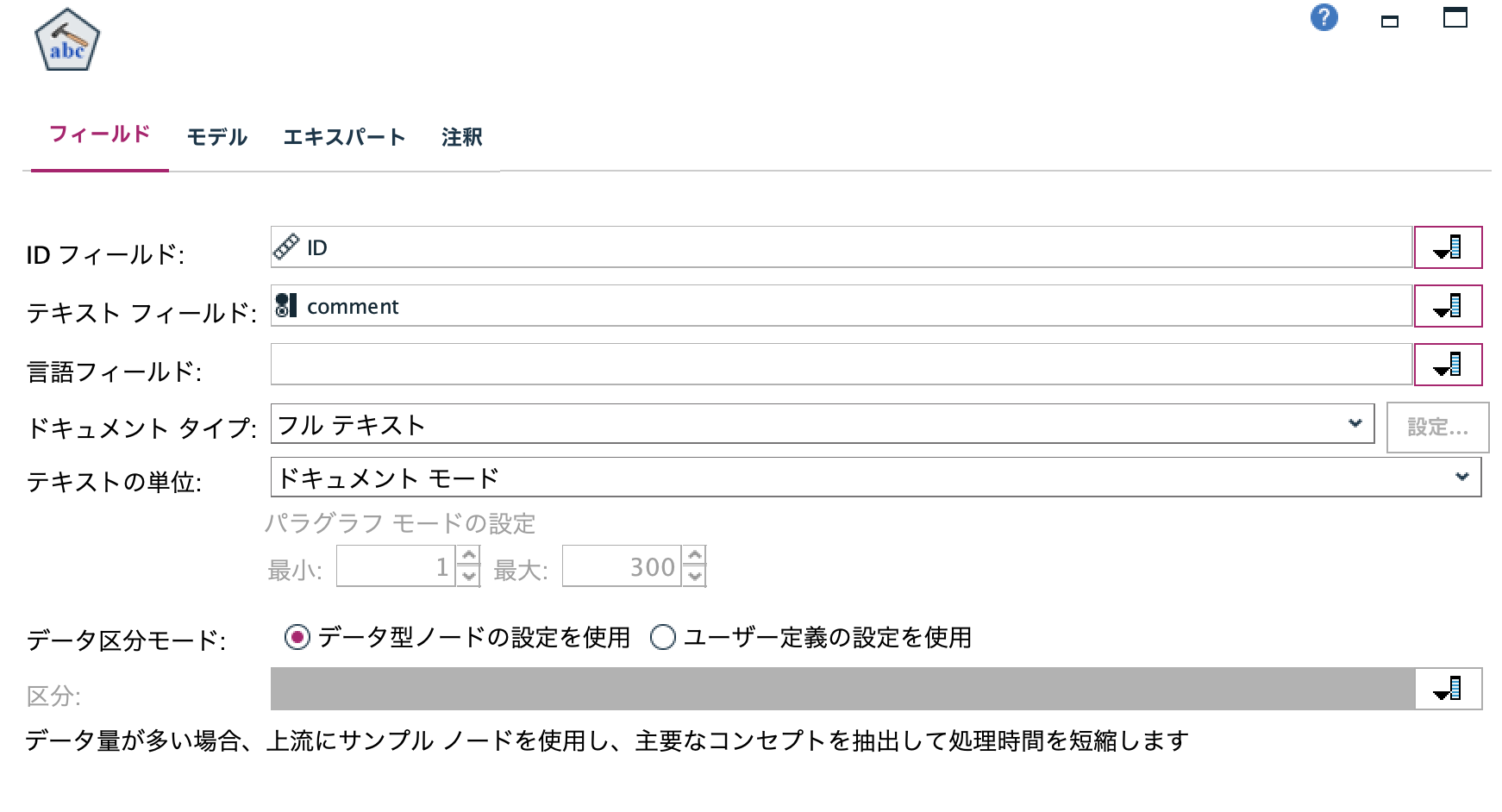
b.[テキストマイニング]ノードを編集します。[IDフィールド]と[テキストフィールド]を以下の通り選択します。
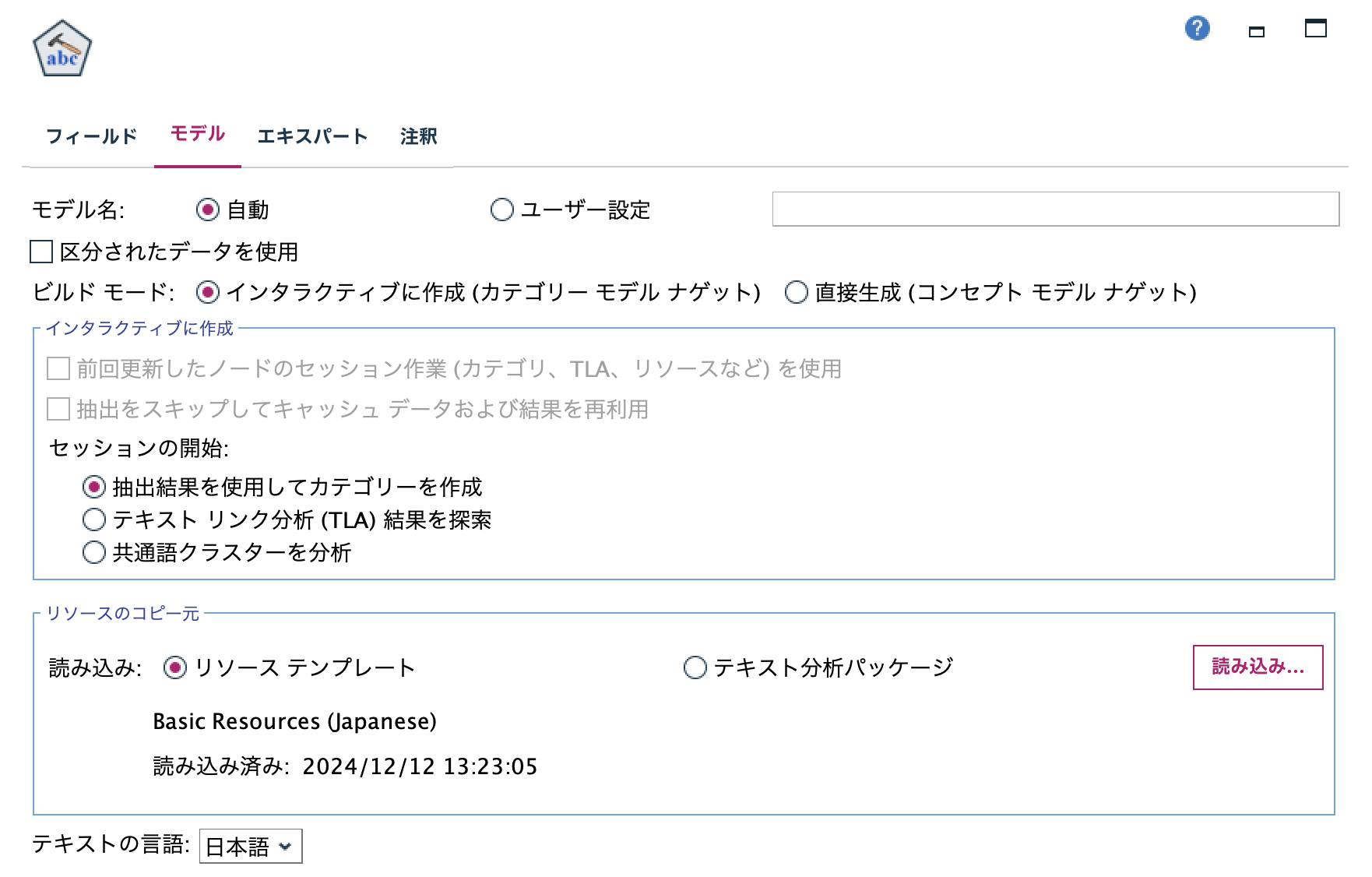
[モデル]タブを以下の通り設定して[実行]します。
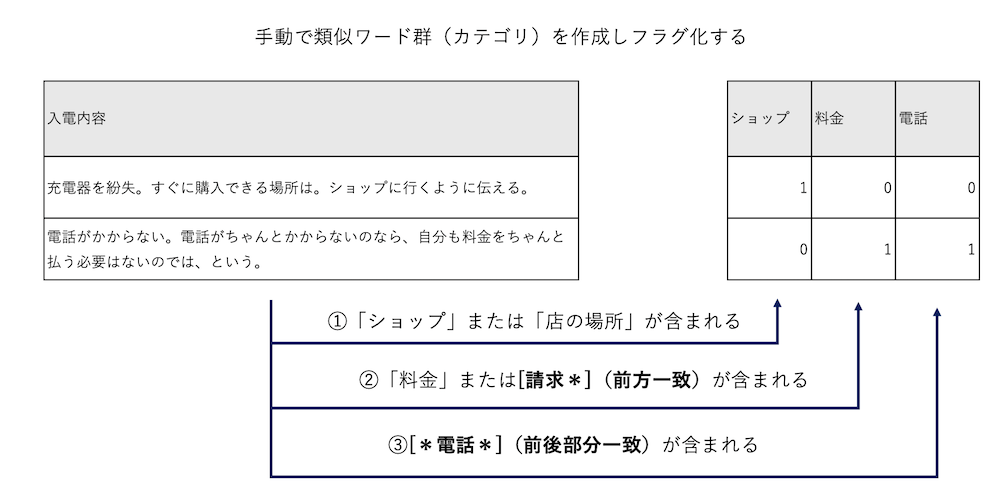
以下のインタラクティブウインドウが表示されます。左下の領域に多頻度ワード(コンセプト)が列挙されます。[ショップ] [電話][料金]の3つを選択して赤枠ボタンを押します。
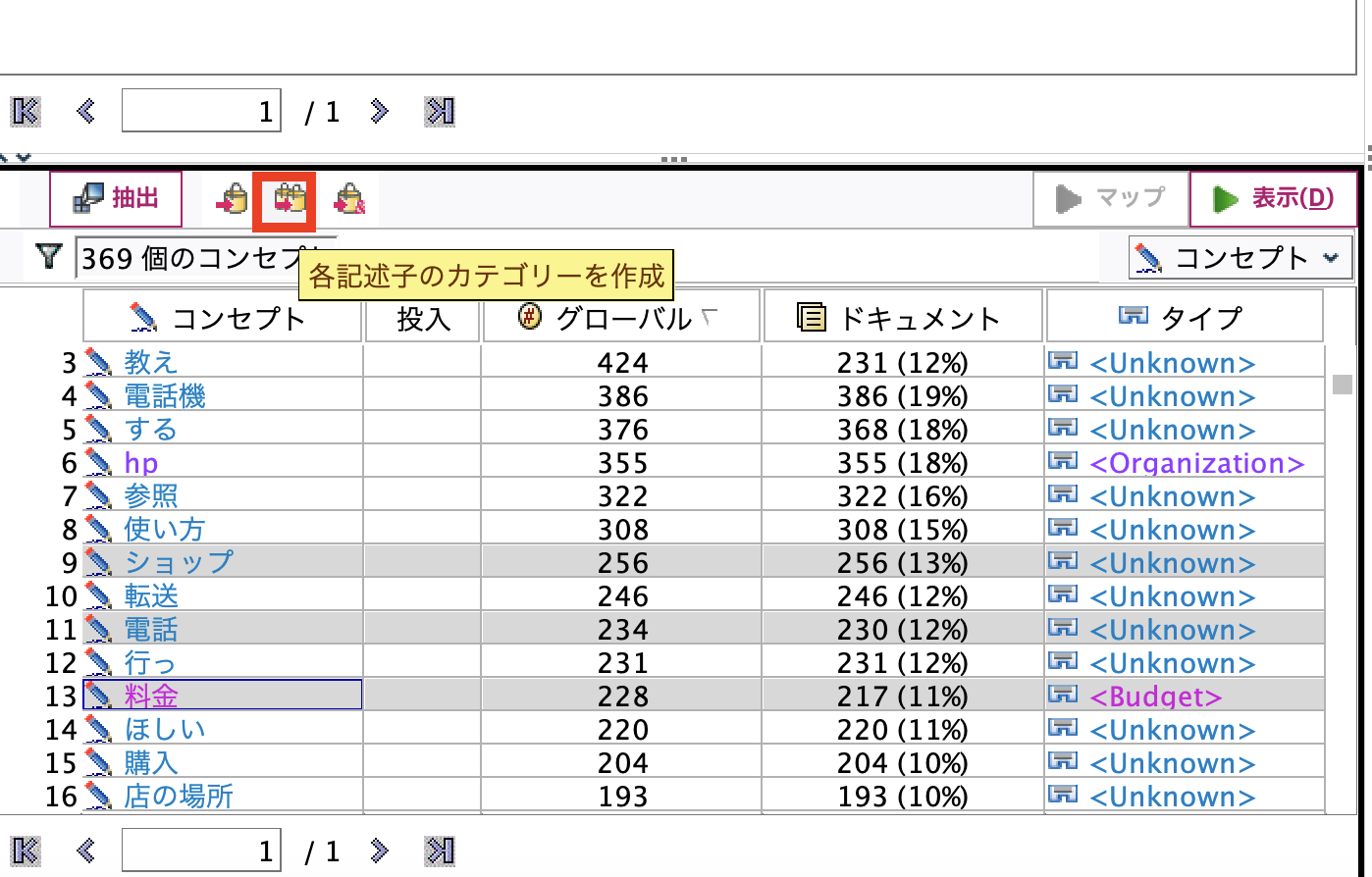
ドラッグアンドドロップで類義語処理(カテゴリにメンバーを追加)
3つのカテゴリを作成しました。[ショップ]に類義語として[店の場所]を追加するために
ドラッグアンドドロップします。
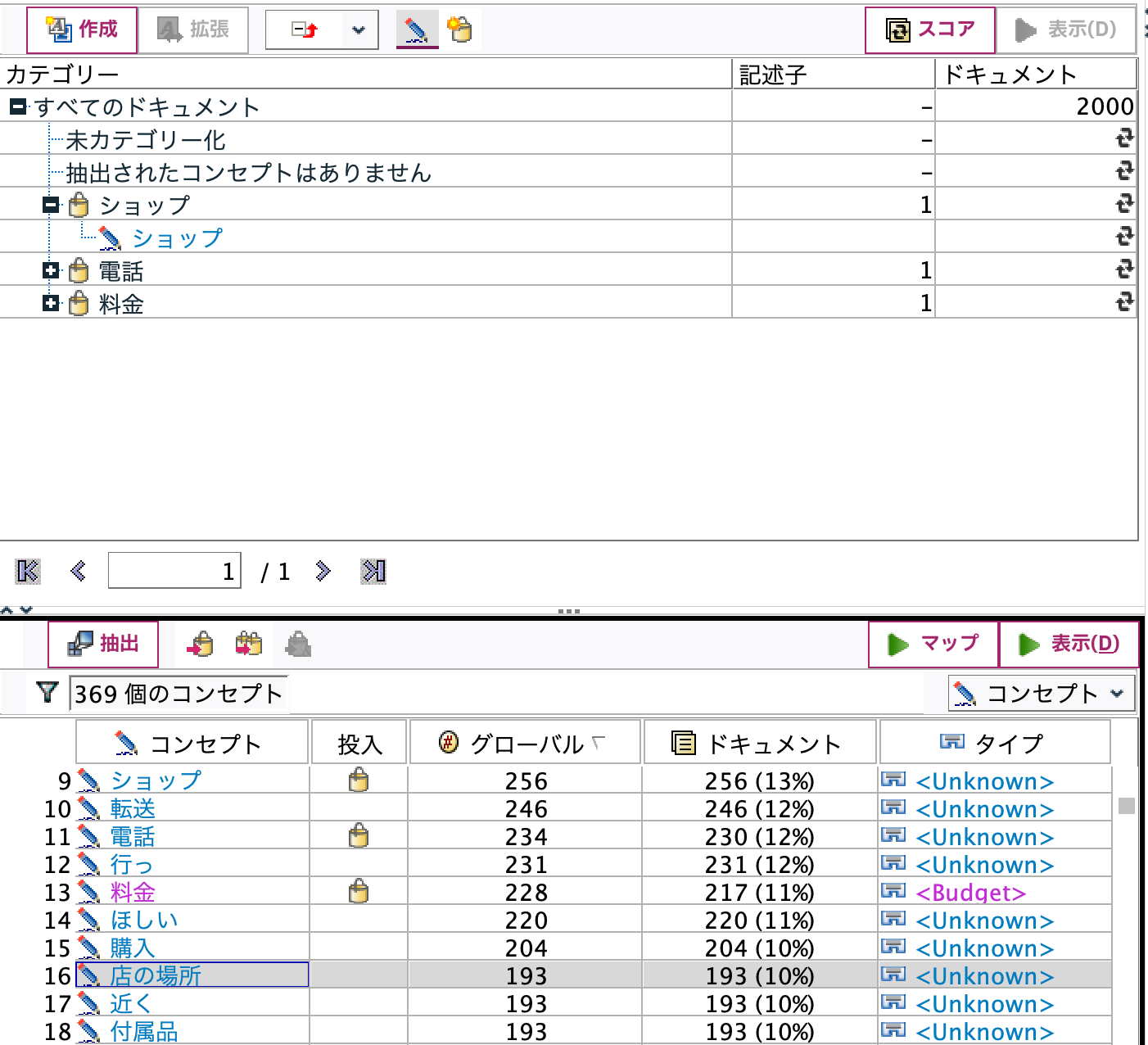
コンセプト[店の場所]はカテゴリ[ショップ]に含まれるように設定されました。類義語の表記揺れの基本的操作です。
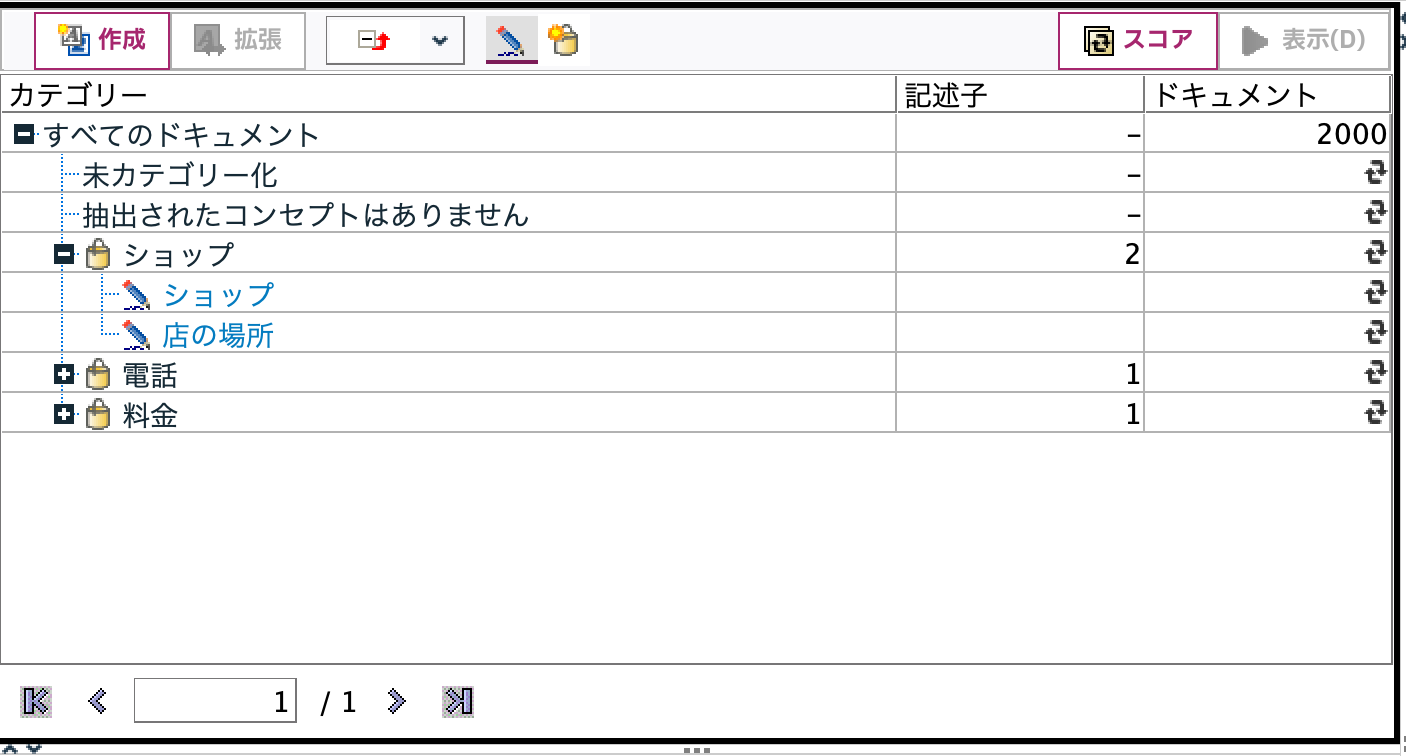
ボタンで類義語処理(カテゴリにメンバーを追加)
同じ処理を赤枠ボタンでも実行可能です。[請求書]を選択して赤枠ボタンを押し、[料金]を選択してOKします。
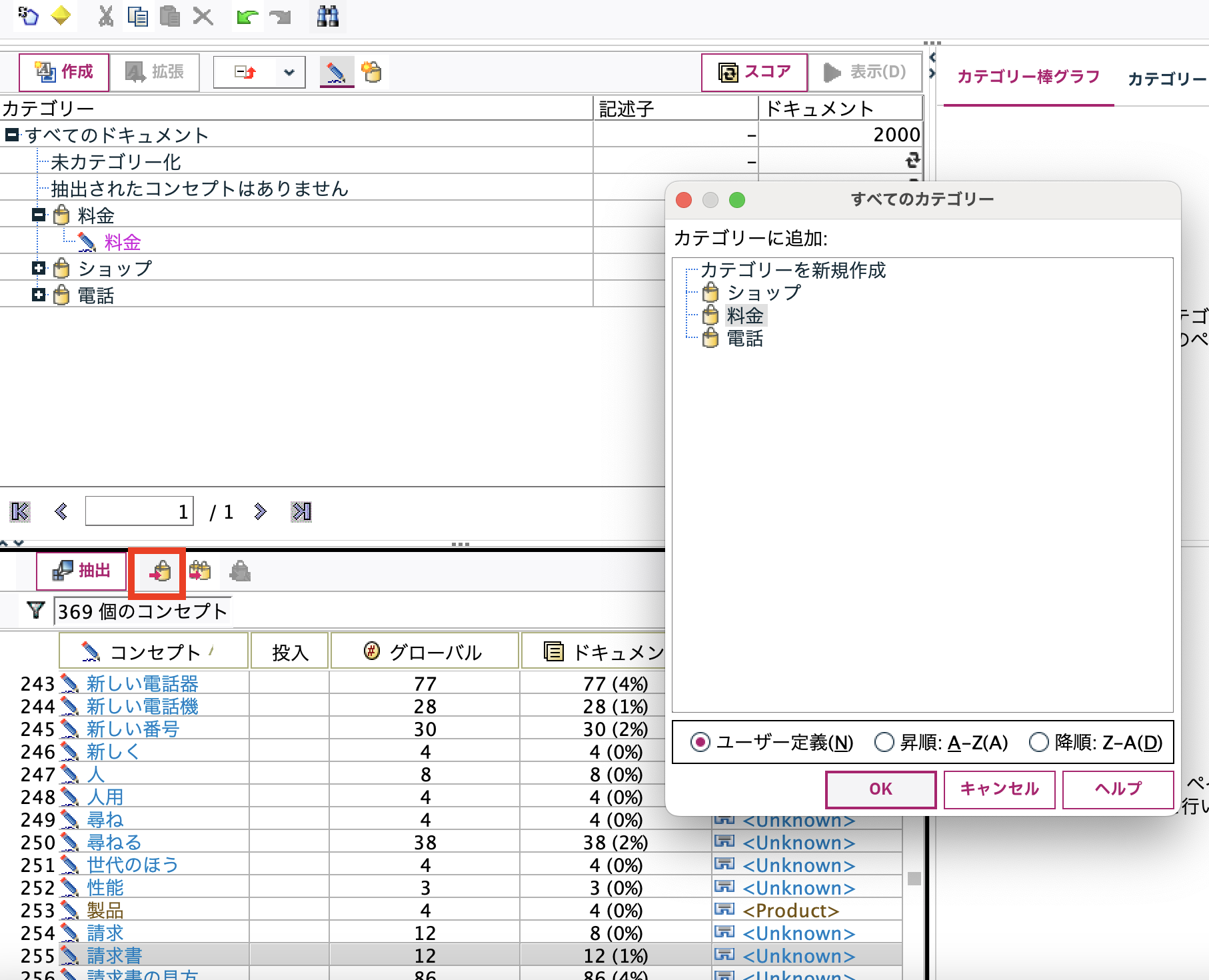
文字列の部分一致でカテゴリを拡張する
カテゴリ[料金]を選択した状態で[拡張]ボタンを選択します。
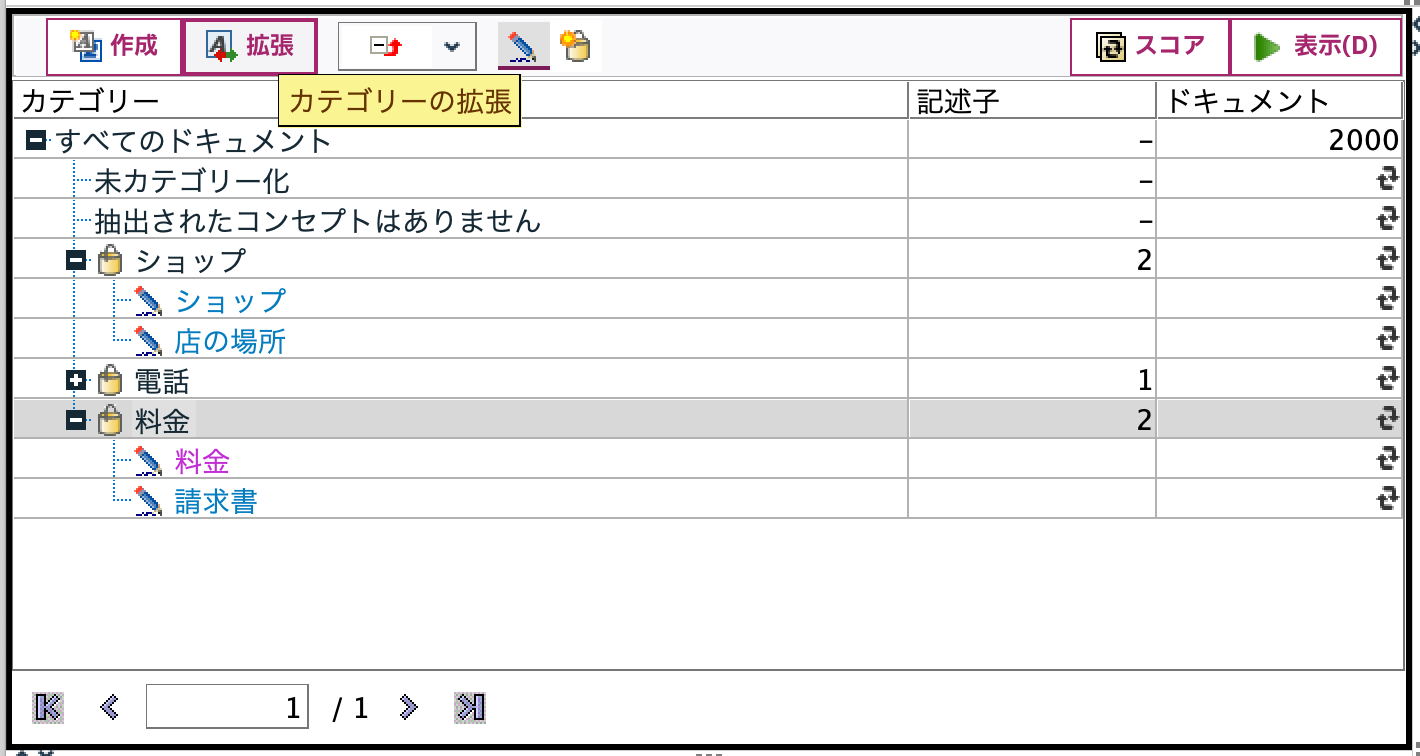
[今すぐ拡張]を選択します。

[請求書]に関数のマークが付与され、後方にアスタリスクがつきました。これによりコンセプト「請求書の見方」はカテゴリ[料金]に含まれます。
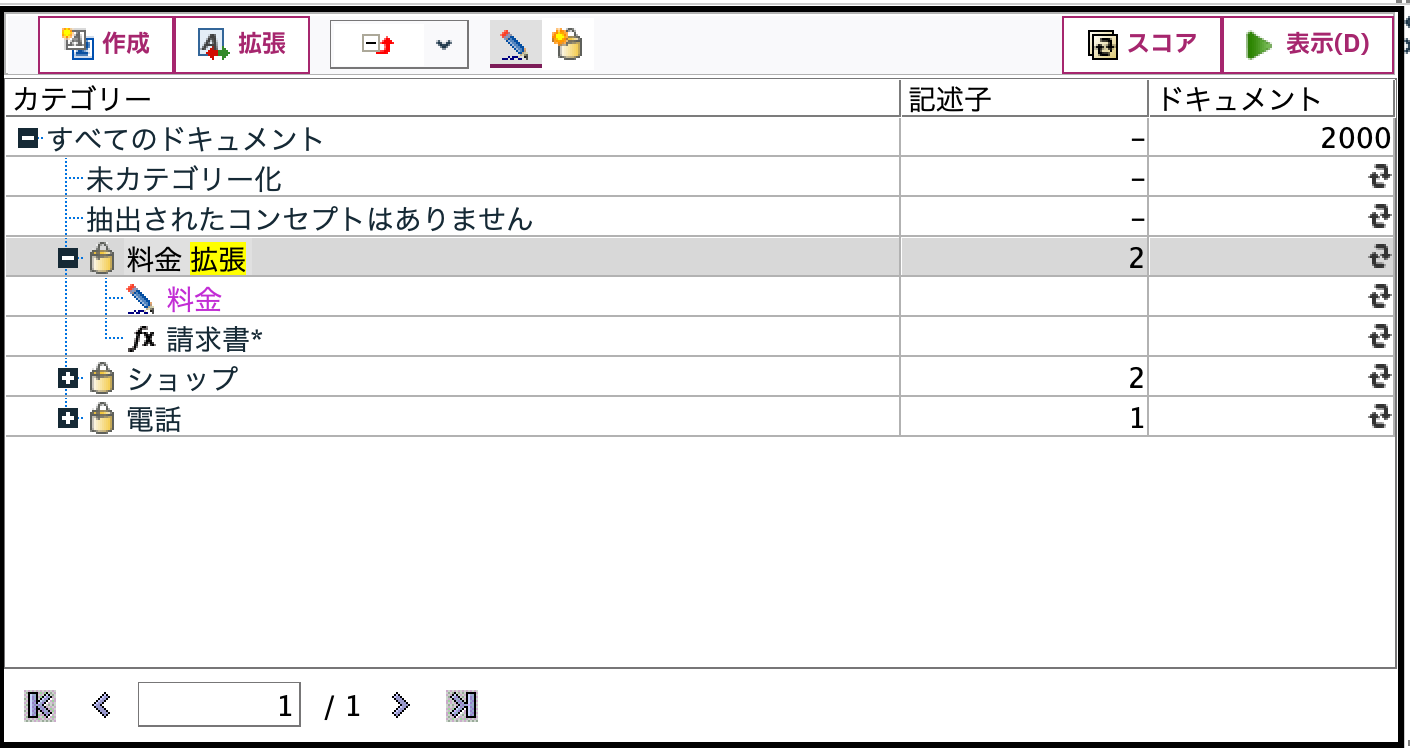
拡張の定義を編集する
カテゴリ[電話]についても[拡張]してみます。
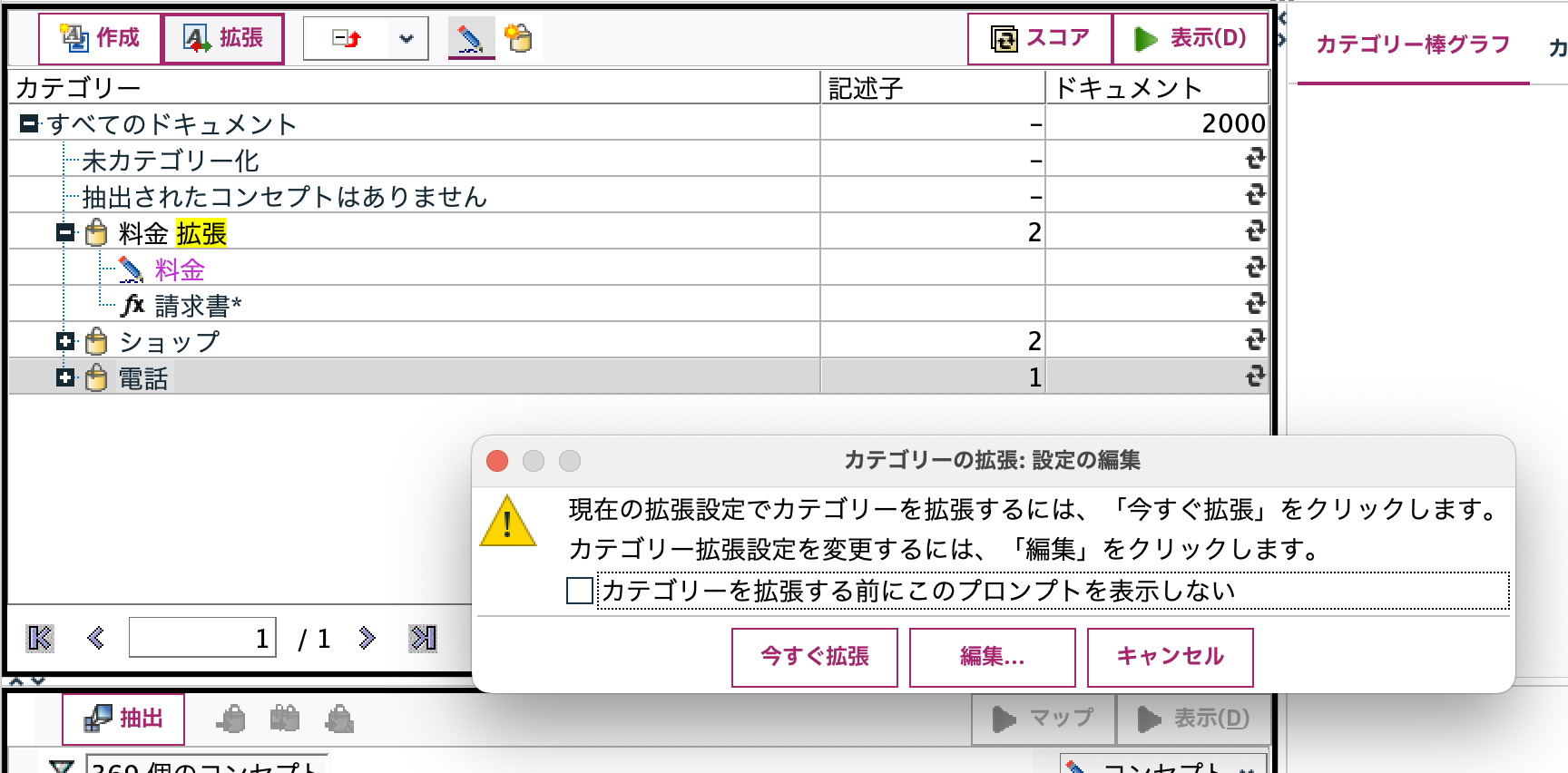
自動的に前方にアスタリスクがつきましたが、後方も含めた前後部分一致にするため右クリックし[カテゴリー規則を編集]を選択します。
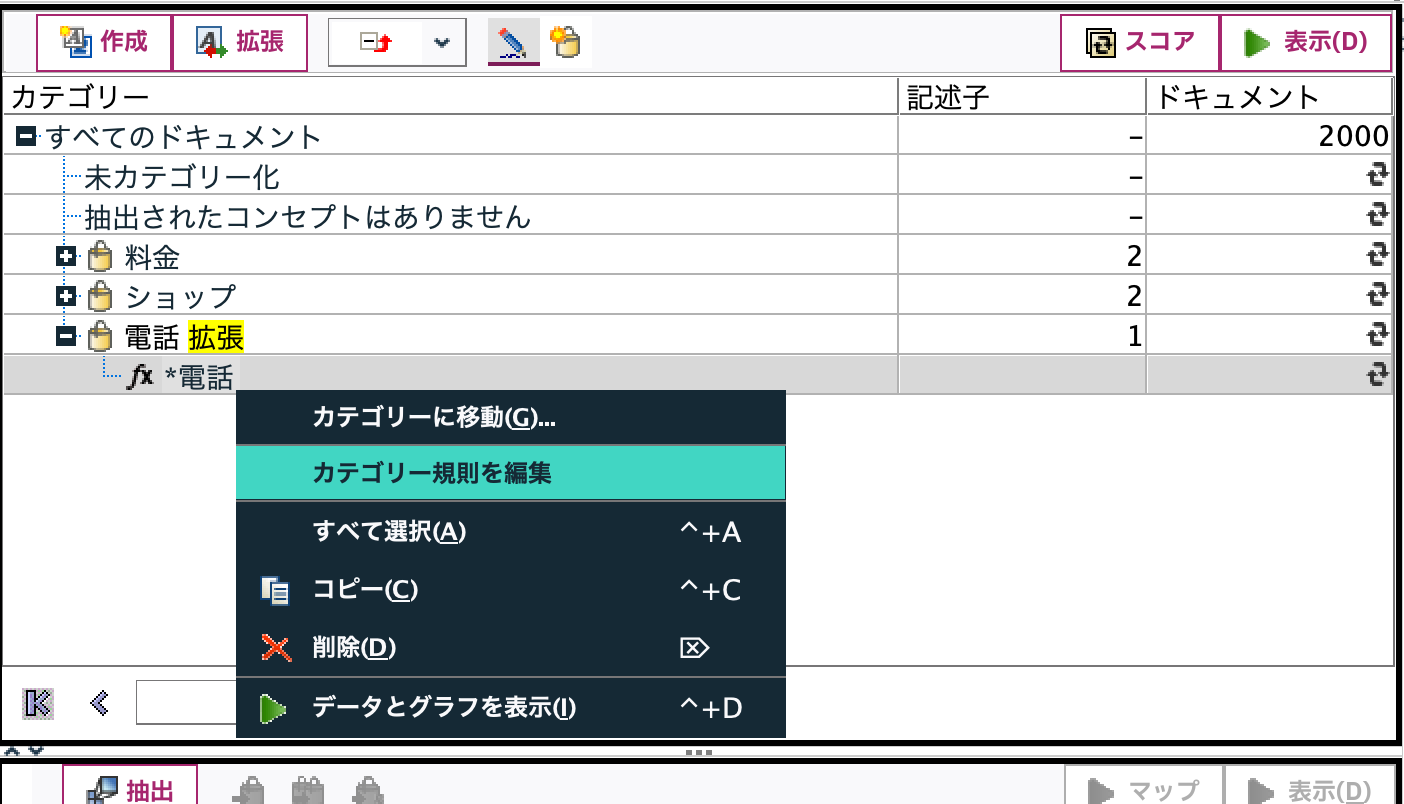
編集用エディタが表示されるので、[電話]の後にアスタリスクをつけ[保存して閉じる]を選択します。
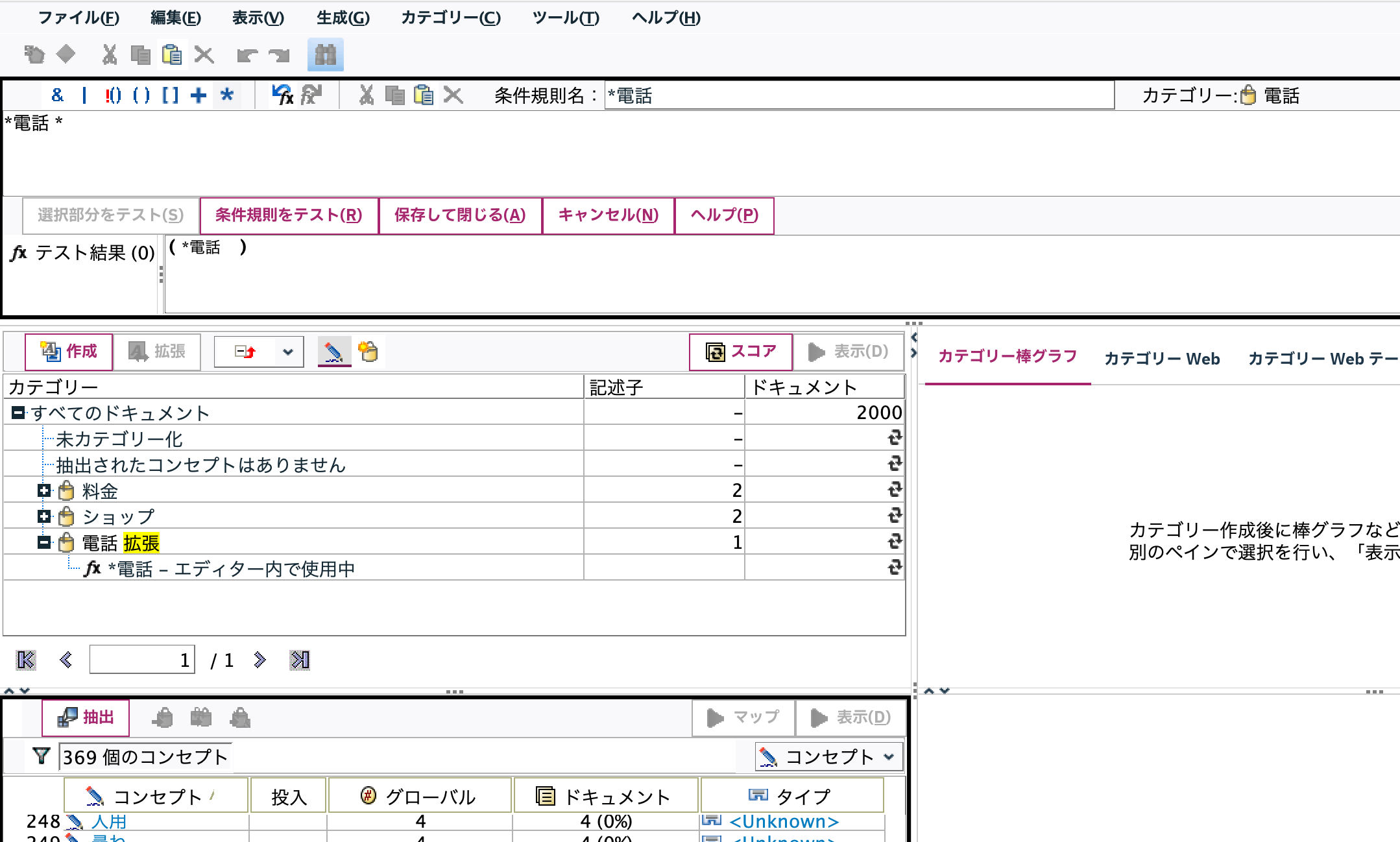
カテゴリをフラグ化するために[生成]メニューからモデルを生成します。
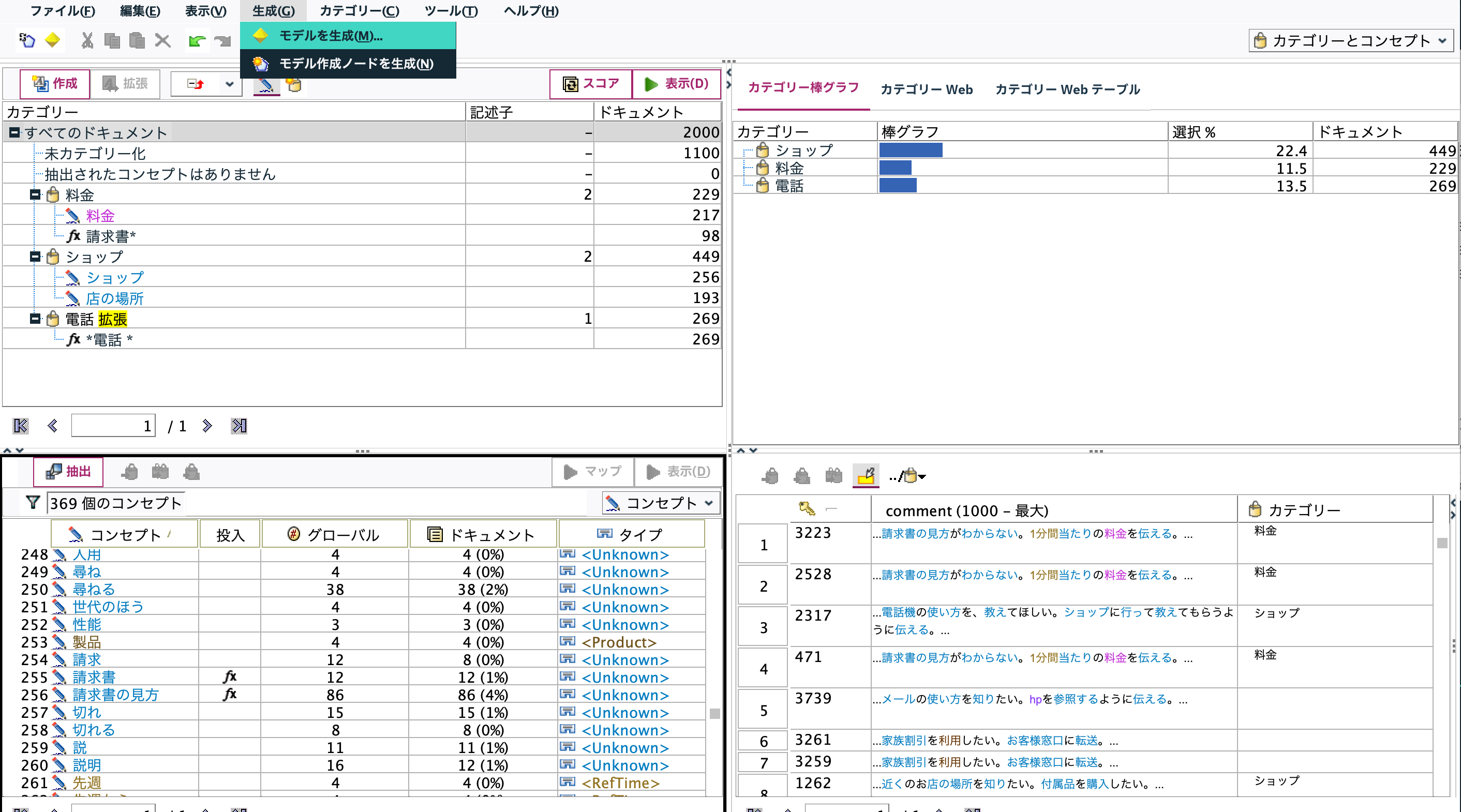
c.[テキストマイニング]ナゲットを編集します。
[テーブル]を実行します。
注意事項
実際の業務では13-3である程度のカテゴリを自動で作成した上、今回のように手動で調整、追加をするのが一般的です。
4.参考情報
Python連携によるテキストマイニング
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)