上位/下位1%を外れ値と定義して削除/抽出(外れ値の処理)
1.想定される利用目的
・予測モデルの精度安定化のための前処理
・異常検知のためのデータ理解
2.サンプルストリームのダウンロード
3.サンプルストリームの説明

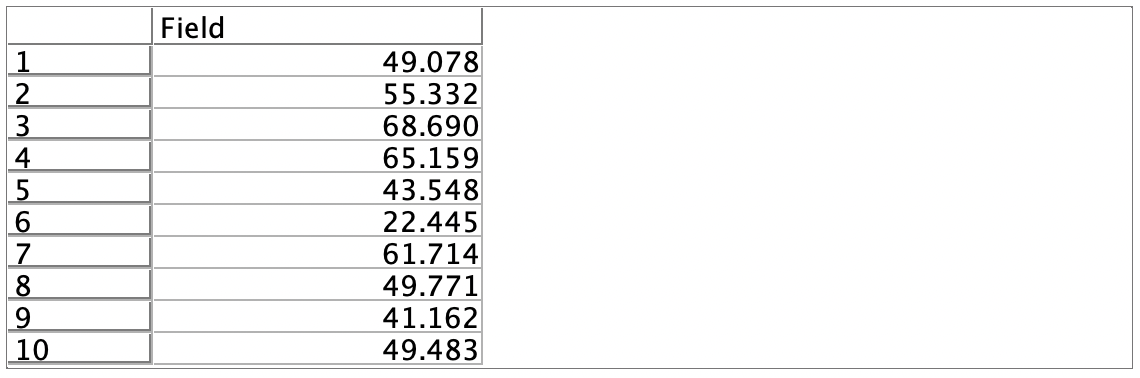
a.入力するデータは以下の通りです。平均50、標準偏差10、サンプル数10,000レコードで正規分布するようにデータを発生させています。
シミュレーションノードを利用して正規分布を作成する方法は以下で解説しています。
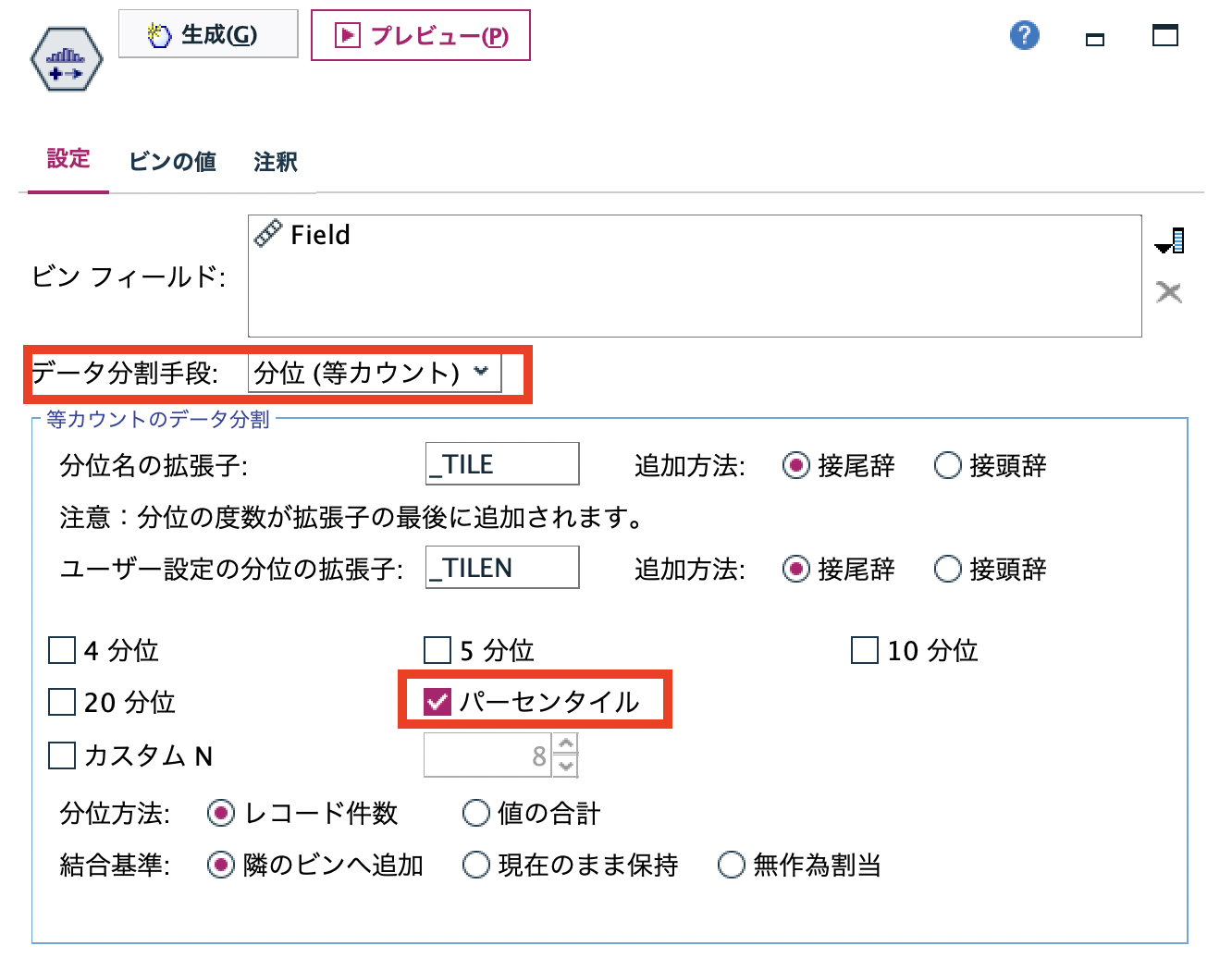
b.[データ分割]ノードを編集します。[データ分割手段]を[分位]にして[パーセンタイル]を指定します。
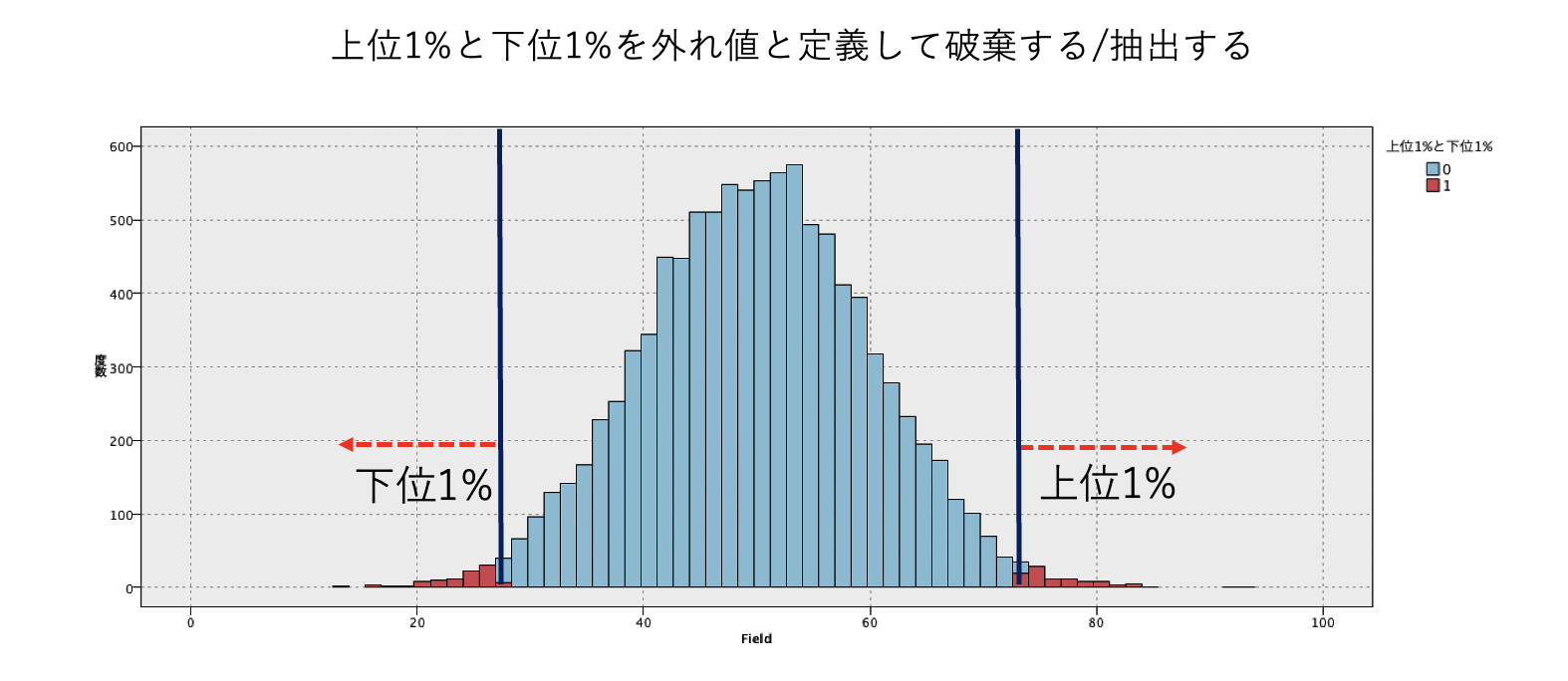
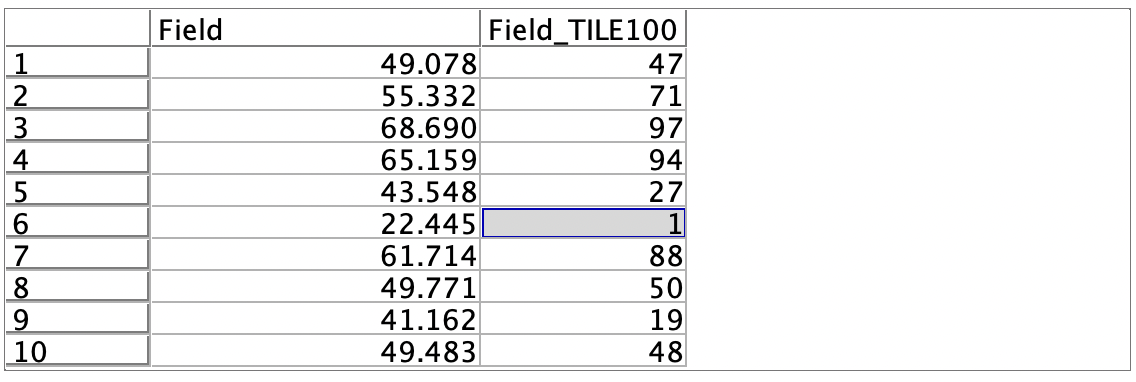
[プレビュー]をします。[FIELD_TILE100]の[1]が最も値の小さい1%を[100]が最大の1%を示します。レコード数が10,000なので上位1%と下位1%にそれぞれ100レコードが該当します。
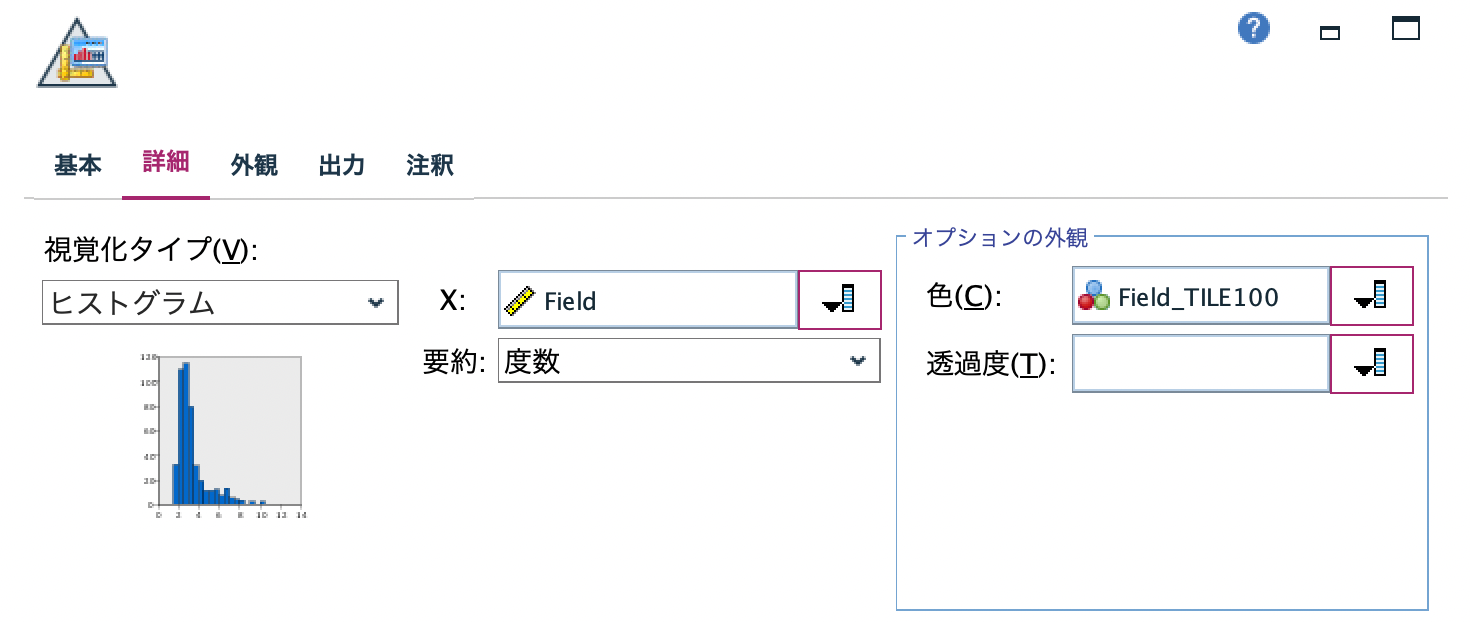
c.[グラフボード]ノードを編集します。
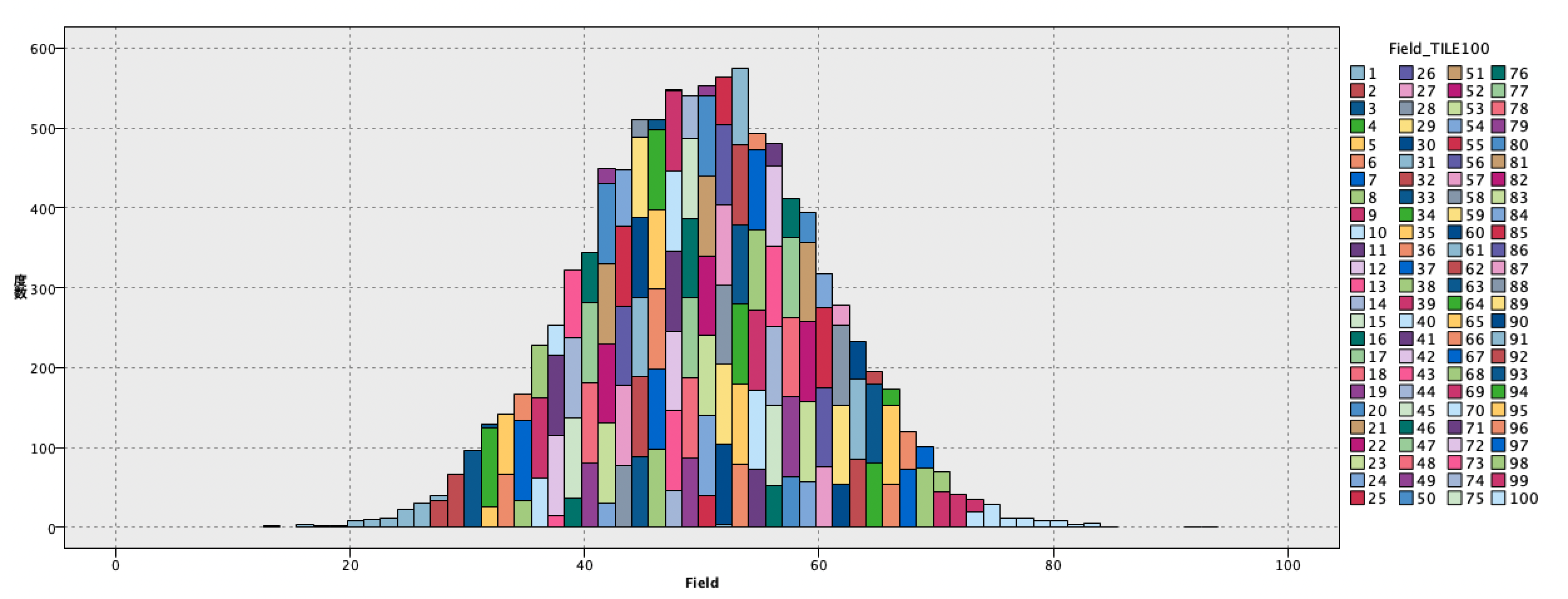
[グラフボード]ノードを実行します。100色の凡例がそれぞれのパーセンタイルを示します。
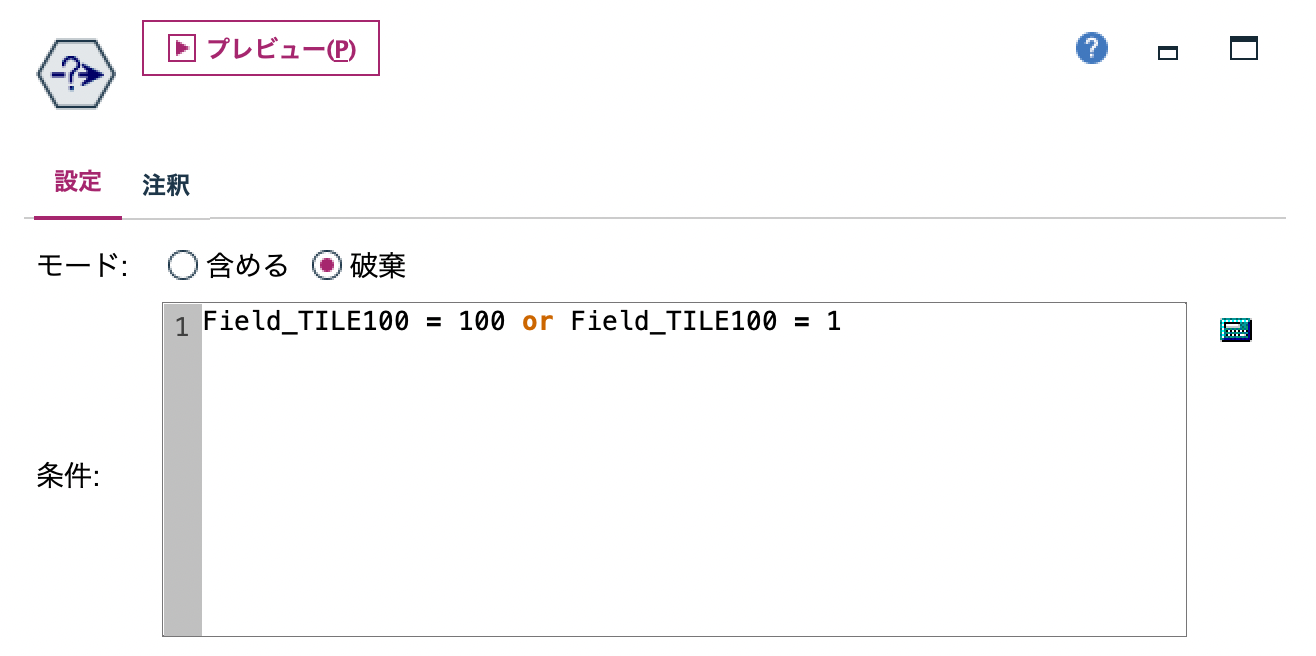
d.[条件抽出]ノードを編集します。外れ値のパーセンタイルを1と100と確定して破棄しています。
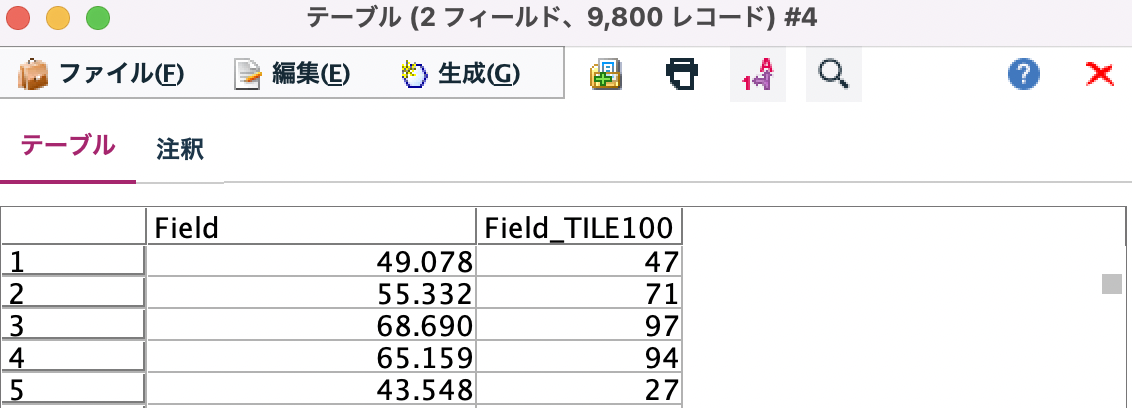
[プレビュー]をします。[外れ値]を破棄した9,800レコードが抽出されました。
e.[条件抽出]ノードを編集します。外れ値のパーセンタイルを1と100と確定して抽出しています。
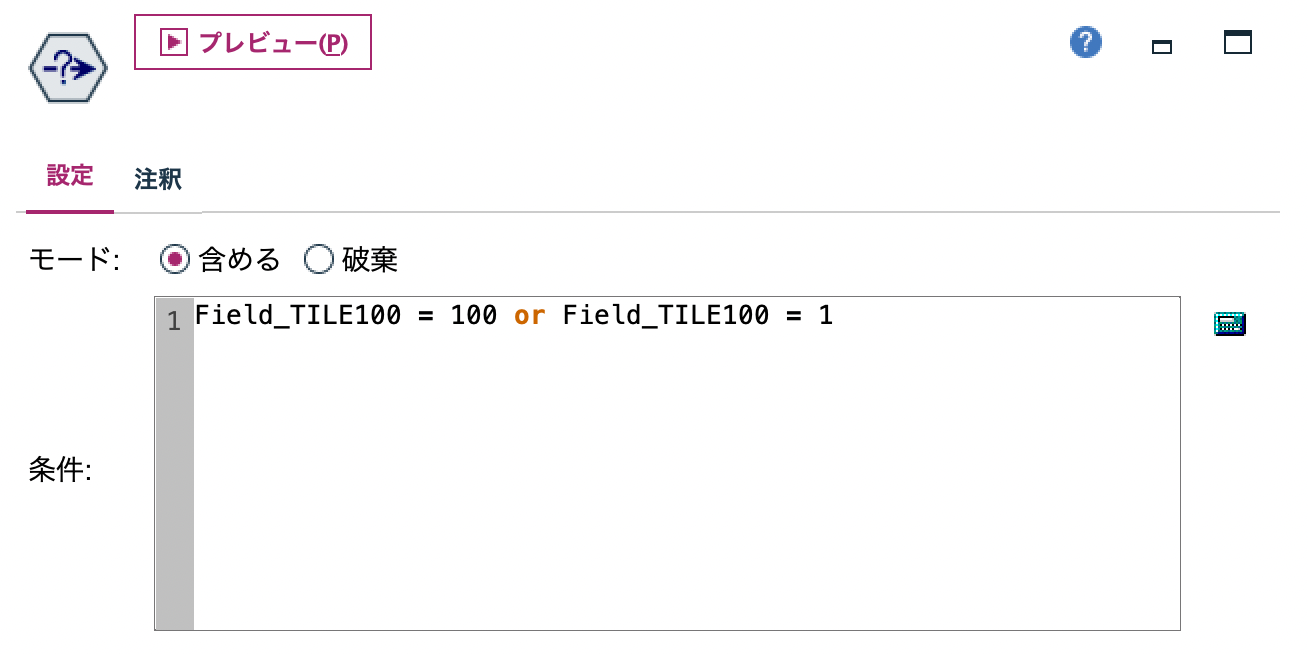
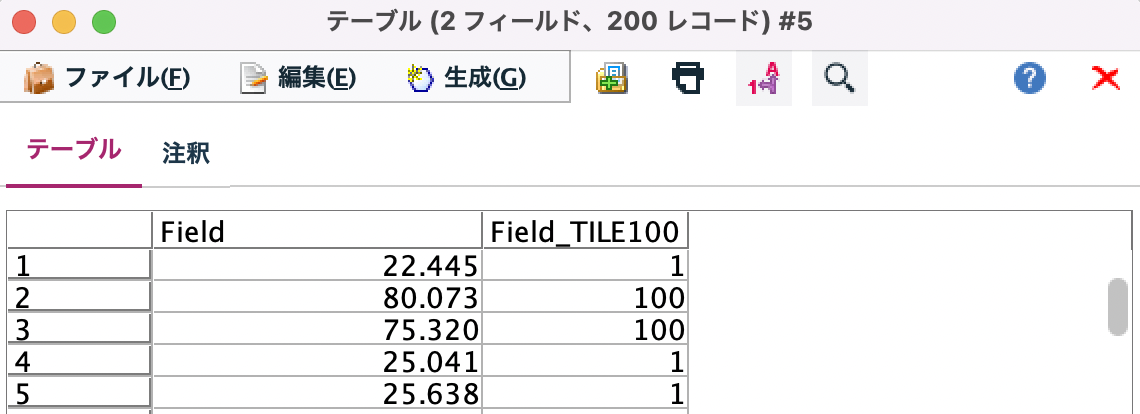
[プレビュー]をします。[外れ値]の200レコードが抽出されました。
注意点
値が同じレコードが多数存在すると分位グループが統合されるため、分位数が指定した数にならない場合があります。
4.参考情報
正規分布やワイブル分布を生成する
デシル分析(10分位)を解説した記事
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)