3-7 データ区分ノード[フィールド作成]
1.ノードの目的
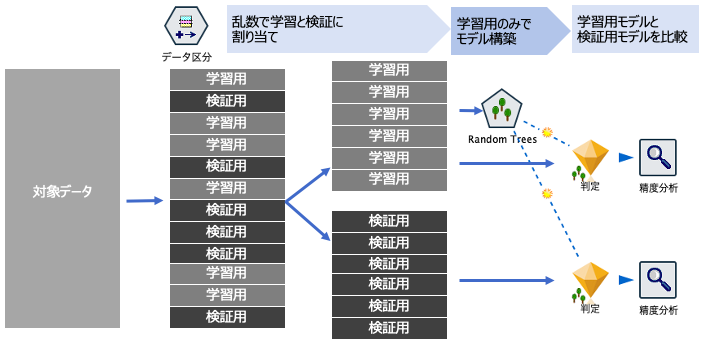
データを学習用と検証用に区分します。予測モデルの前方に配置することで学習用と検証用にデータをランダムに割り当て、後続のモデル評価で個別に表示します。これにより過学習を回避し汎化性能を確保します。
以下のイメージを実現します。
2.解説動画(60秒)
3.クイックスタート
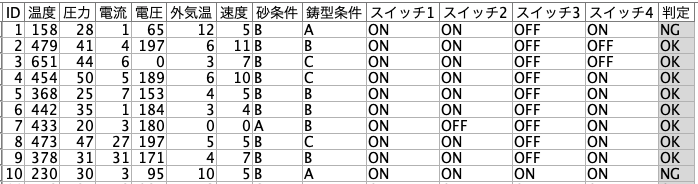
判定を予測するモデルを作り、学習と検証データを切り分けて精度分析を行います。
*入力データは[5.参考情報]からダウンロードできます。
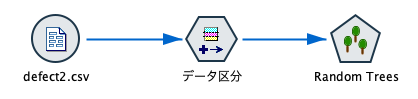
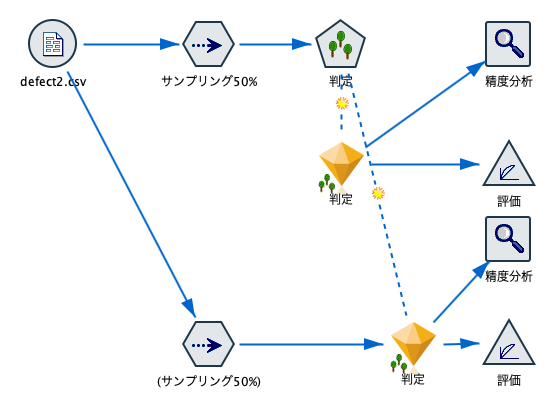
[可変長ファイル]に[データ区分]、[Random Trees]を接続します。
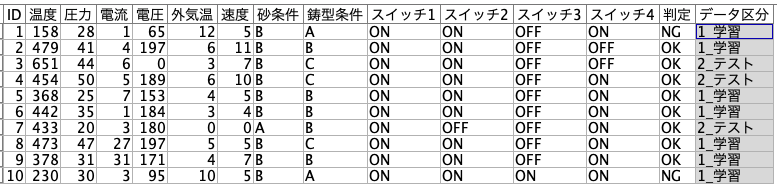
[可変長ファイル]の[データ型]タブで[値の読み込み]ボタンを押した後に、予測の[ロール]を設定します。
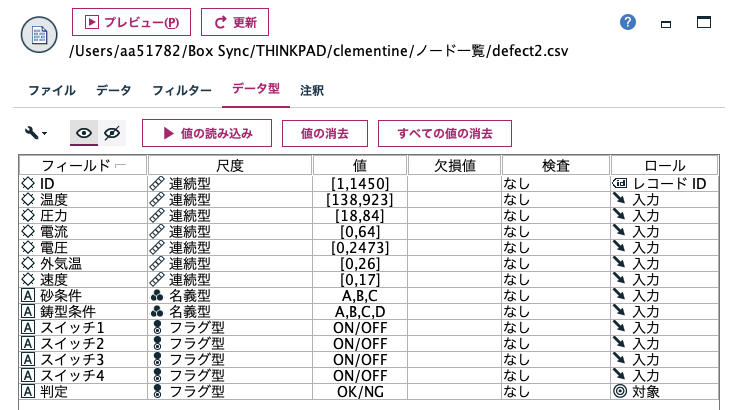
また[判定]の左にあるAボタンをダブルクリックします。
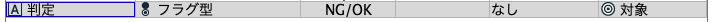
真と偽をそれぞれNGとOKに変更します。
[データ区分]には何も設定をしません。
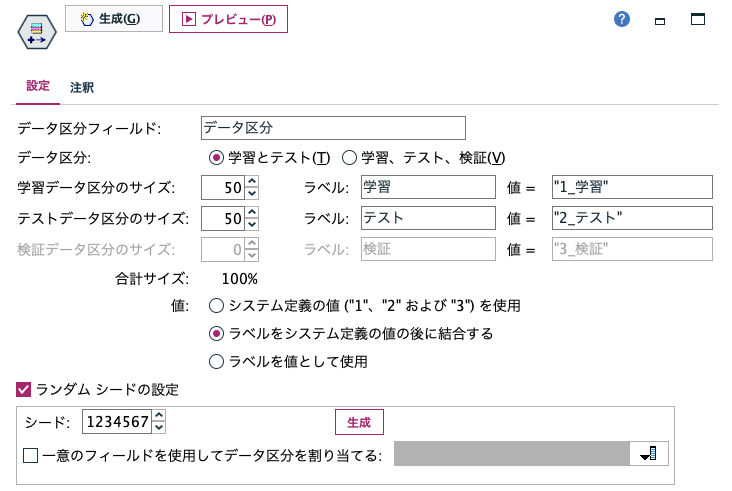
50%のレコードをランダムに学習、残りを検証としてアサインしてます。
[Random Trees]を実行します。出来上がったモデルナゲットに[精度分析]と[評価]グラフを接続します。
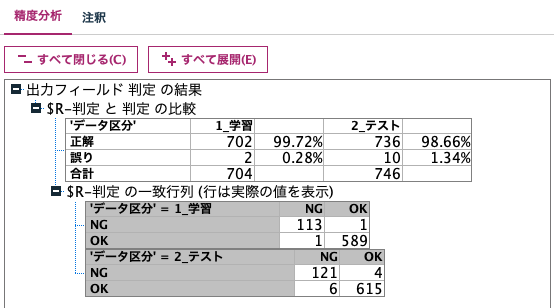
[精度分析]では[一致行列]にチェックをいれます。

Confusion Matrixが学習用と検証(テスト)用分けて表示されます。
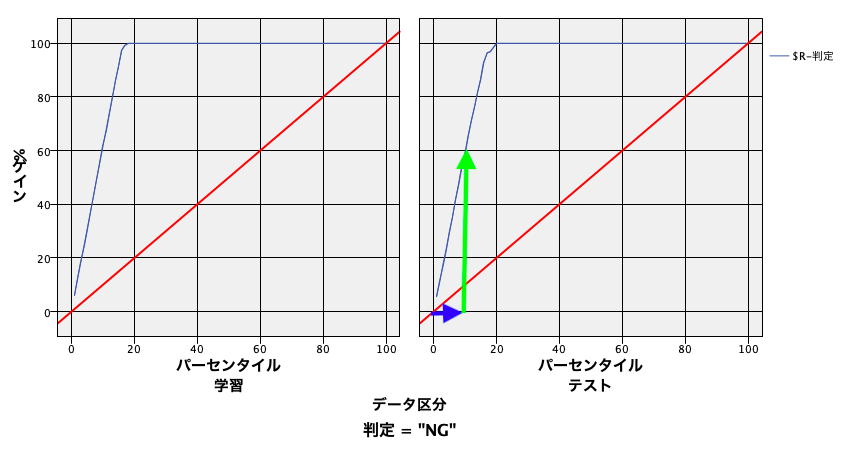
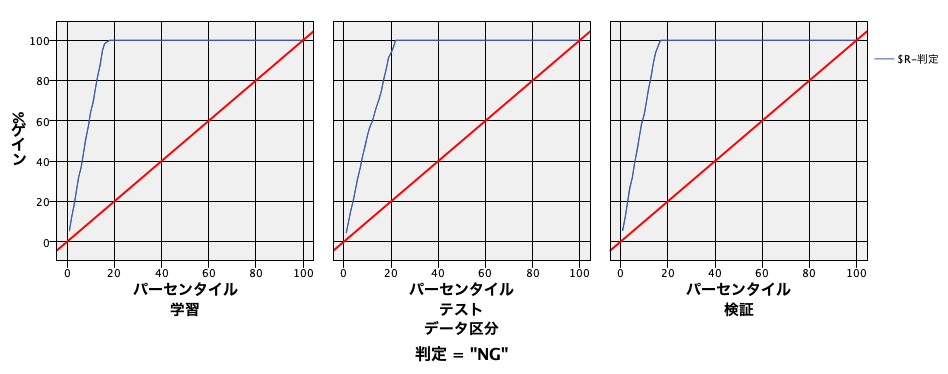
[評価]グラフを実行します。ゲインチャートが表示されます。
テストのゲインチャートから、最もNG(欠陥)が疑われる上位10%のレコード(青矢印)に、実際の60%のNG(欠陥)が含まれていることがわかり、モデルが効率よく欠損を検知できる性能を示しています。
データ区分を利用しないで同じことを実行するには以下のようなストリームになります。
4.Tips
検証データを2セット用意する
新しいデータへの当てはまりの安定性(汎化性能)を確認するために検証を「テスト」と「検証」の2セット準備できます。


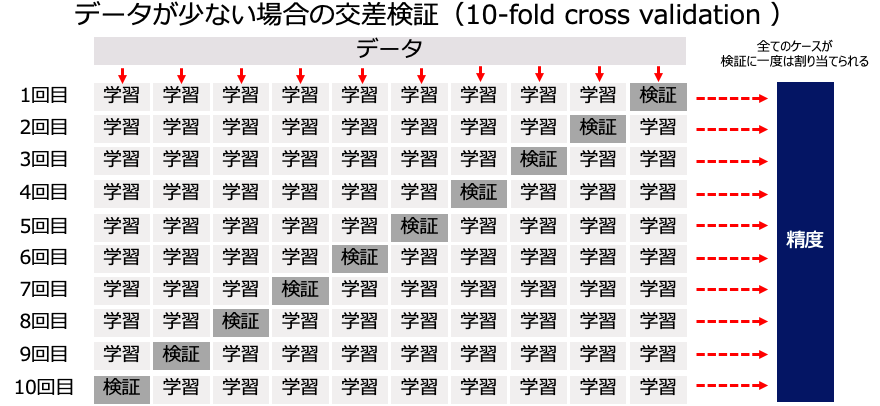
SPSS Modelerとクロスバリデーション(交差検証)
比較的データセットが小さい場合(レコード数が300程度など)でも汎化性能を確保する場合にはデータセットをいくつかに分割し、どれも一度は学習と検証に使うN分割交差検証を行います。
複数の教師あり学習モデルを自動で評価している[自動分類][自動数値]には交差検証を行うオプションが備わっています。
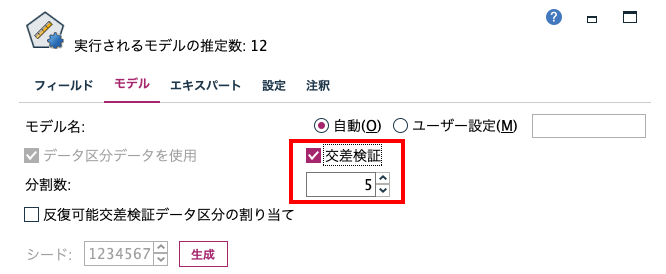
N分割交差検証について以下の記事で詳しく解説しています。
5.参考情報
利用データ
右クリックでリンク先を保存してください。
ノードのヘルプ
SPSS Modeler 逆引きストリーム集(データ加工)
SPSS Modeler ノードリファレンス目次