5-11 自動分類[モデル作成タブ]

1.ノードの目的
搭載されているすべての判別モデルを評価し、最も精度の高いN個のアンサンブル(多数決)によってスコアリングします(Autoモデリング)。
2.解説動画(60秒)
3.クイックスタート
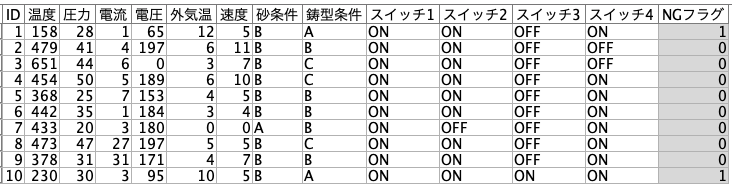
製造条件からNG(不良品)になる予測モデルを自動分類で作成します。
*サンプルデータ(CSV)は[5.参考情報]からダウンロードできます。
[可変長ファイル]から[データ区分]、[自動分類]の順に接続します。
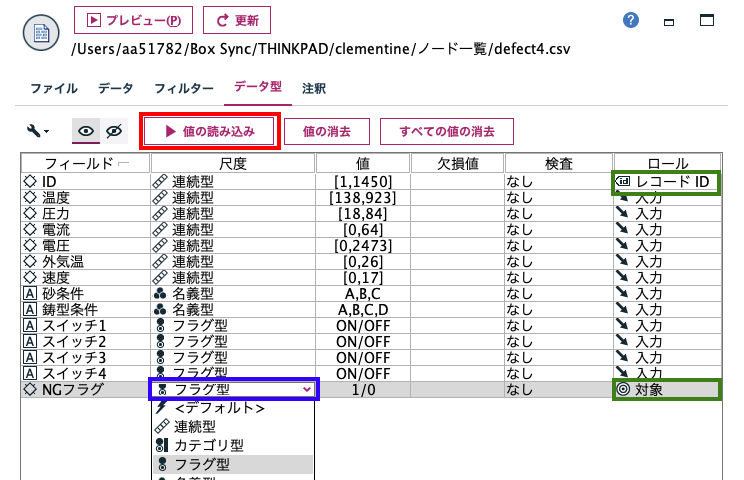
[可変長ファイル]で[データ型]タブを開きます。[NGフラグ]の尺度を[フラグ](青枠)にして[値の読み込み]ボタンを押します(赤枠)。予測の入出力を決める[ロール]の[ID]を[レコードID]へ。[NGフラグ]を[対象]に変更します(緑枠)。
[データ区分]ノードは初期設定のまま何も編集しません。5割のレコードを学習、残りを検証に乱数で割り当てます。このノードの詳しい説明は以下の記事をご覧ください。
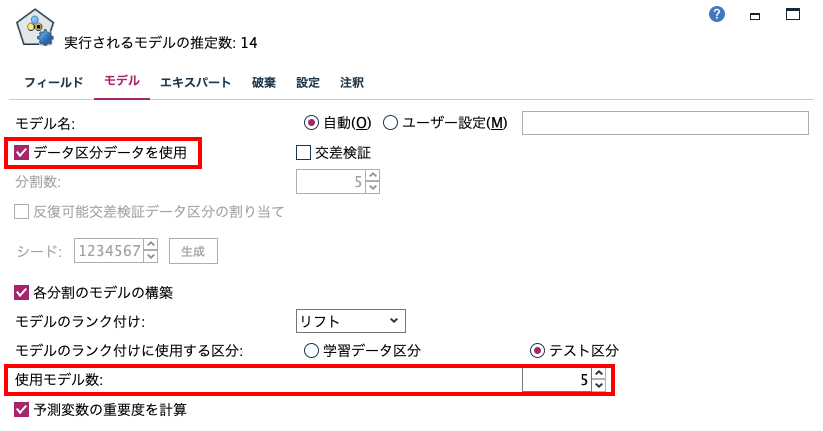
[自動分類]ノードを編集します。使用モデル数を5にすると、上位5モデルを選出します。
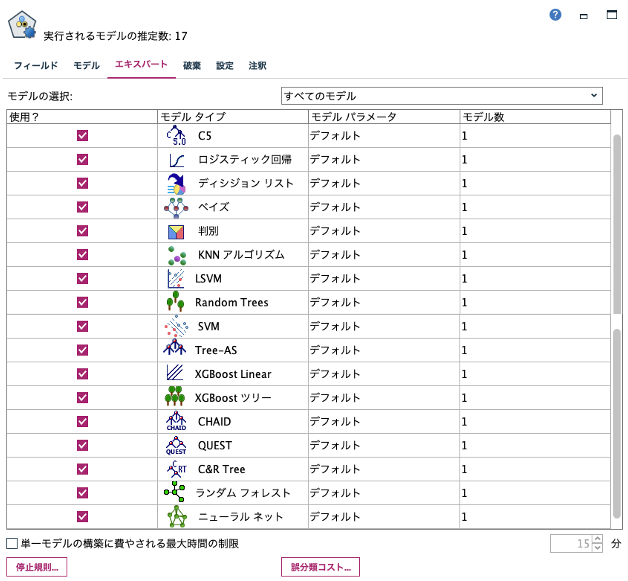
[エクスパート]タブでは利用するモデルを選択できます。最大17種類を実行できますが計算時間を考慮して初期設定の14モデルで[実行]します。
モデルが生成されました。モデルナゲットを右クリックで編集します。
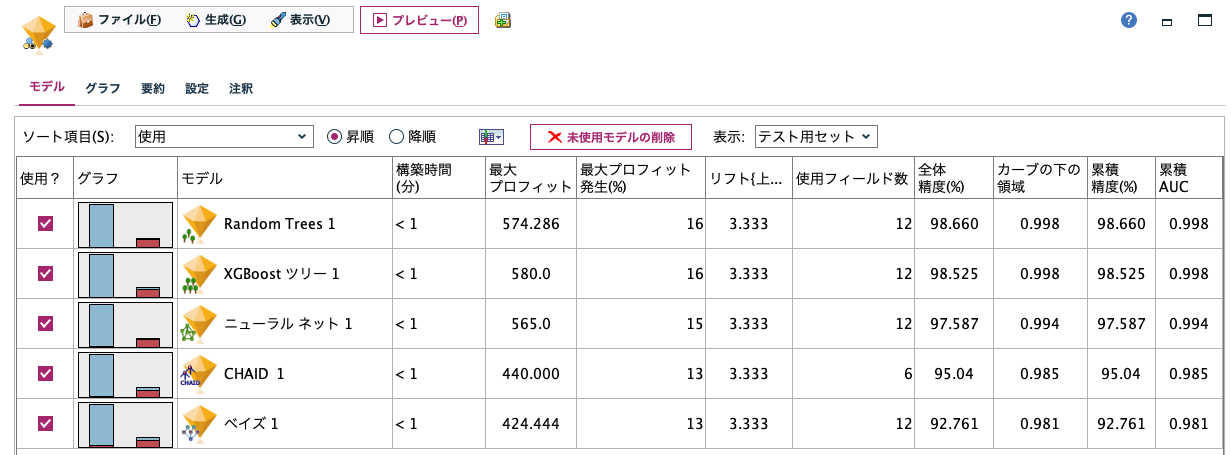
14のモデルから上位5つが選ばれました。
モデルナゲットを右クリックでプレビューします。
[$XF-NGフラグ]は5つの上位モデルの評決(多数決)によって確定されています。
もうひとつのフィールドはどれだけ予測が確からしいかを表す確信度です。

モデルナゲットに[精度分析]を接続します。
上位モデルのアンサンブル学習による精度を確認します。
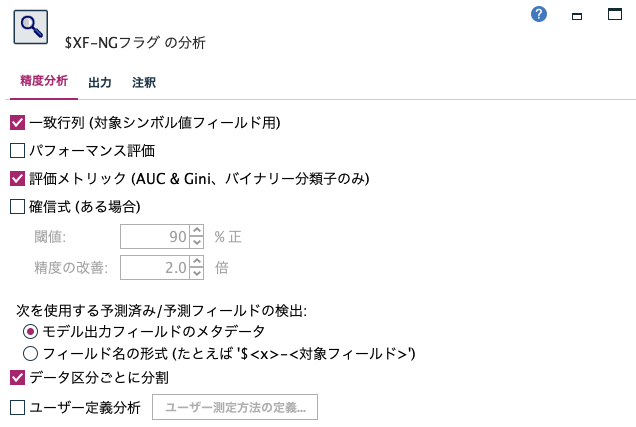
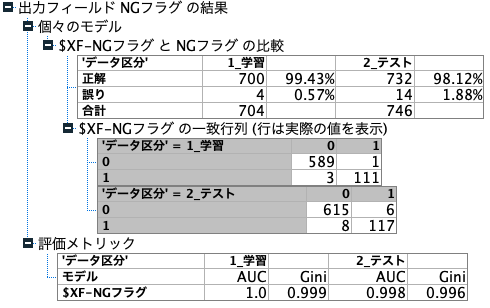
精度分析の結果の解釈は以下の記事をご覧ください。
4.Tips
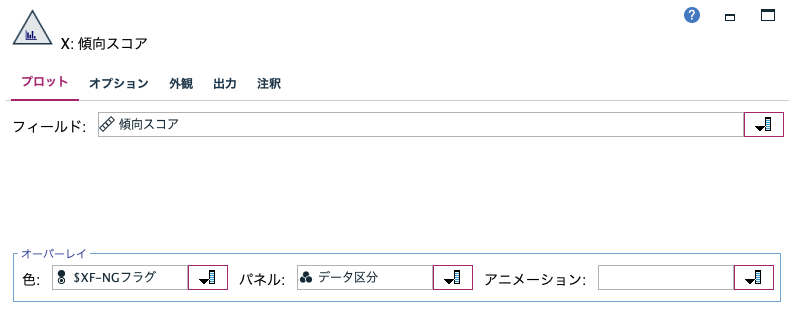
傾向スコアを作成する
モデルナゲットから[フィールド作成]と[ヒストグラム]を順番に接続します。
[フィールド作成]を編集します。
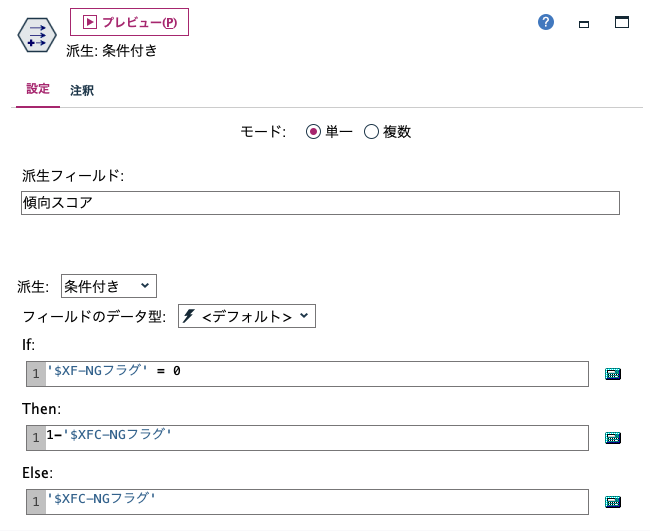
[フィールド作成]でプレビューします。
[$XF-NGフラグ]が0の場合は確信度を1から引いた傾向スコアが出来ています。
これにより予測の1/0に関わらず全てのレコードが不良品になる見込みを求められます。

傾向スコアの分布をヒストグラムで確認します。
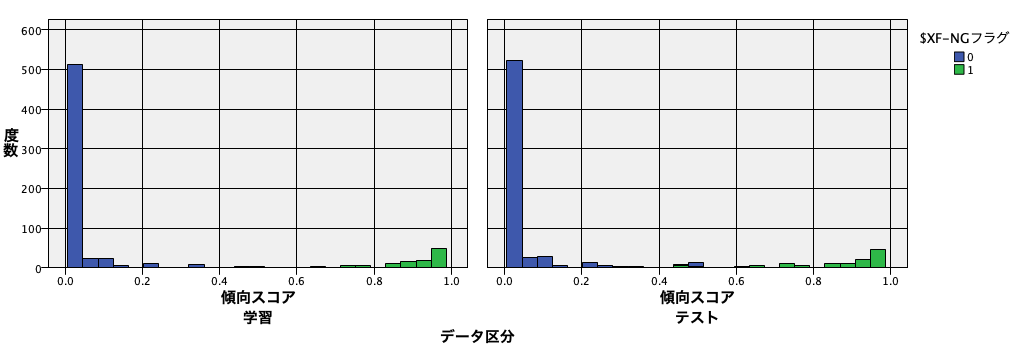
傾向スコアは以下の記事で解説しています。
交差検証(クロスバリデーション)
[モデル]タブで交差検証を設定できます。
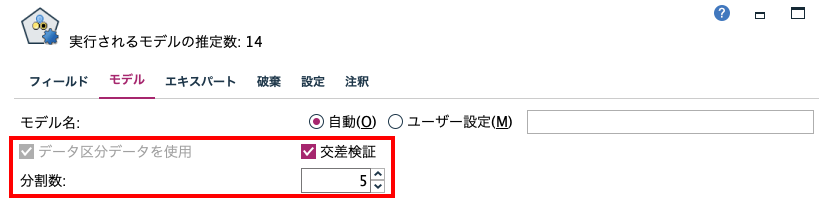
交差検証(クロスバリデーション)の目的は次の記事をご覧ください。
モデルパラメータ変更やアンサンブルについて解説した記事
5.参考情報
利用データ
右クリックでリンク先を保存してください。
ノードのヘルプ
SPSS Modeler 逆引きストリーム集(データ加工)
SPSS Modeler ノードリファレンス目次