フリーコメントから頻出ワードを機械的にフラグ化する
この記事はSPSS Modeler Premium Ver18.6から追加された日本語テキスト機能を利用して書いています。SPSS Modeler Professionalをお使いの方はアップグレードするかPython連携を用いて実現します。
Python連携を紹介する記事はこちら
1.想定される利用目的
・コンタクトセンターの応答ログから解約に影響する単語の探索
・営業日報のコメントから成約予測モデルの説明変数を作成
・アンケート自由回答データからブランドと評価のポジショニングマップを作成
2.ストリームとデータのダウンロード
ストリーム
データ
3.サンプルストリームの説明

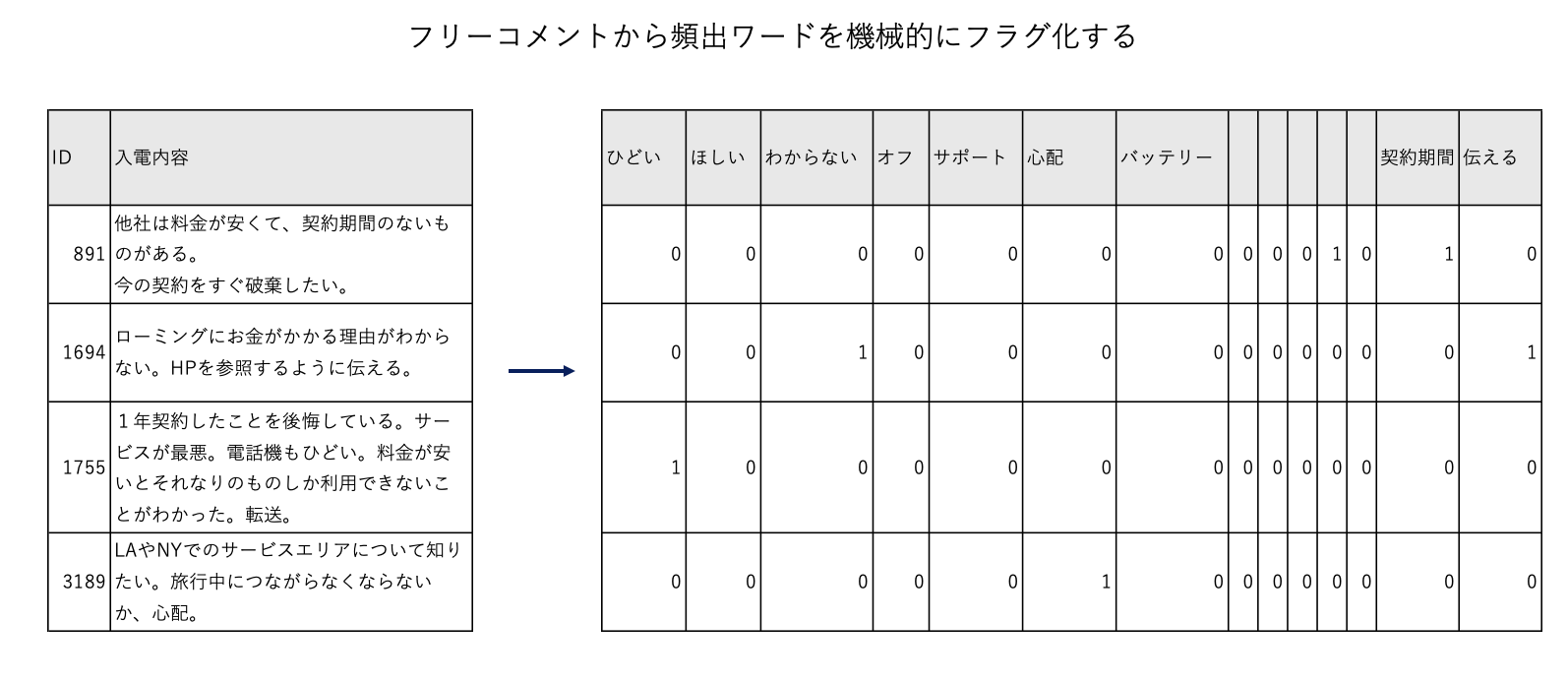
a.入力データは以下の通りです。[comment]列の文章から頻出ワードを列に展開します。

b.[テキストマイニング]ノードを編集します。[ビルドモード]を[直接生成]に変更します。[モデルが含む最大コンセプト数]を[50]に変更します。

[テキストマイニング]ノードを実行します。cが生成されます。
c.[テキストマイニング]ナゲットを編集します。[真/偽の値]を[1/0]に変更します。

[テーブル]を実行します。

注意事項
今回は頻出ワード上位50に接頭辞コンセプトをつけて列に展開しましたが、後続処理でフィールド名(変数名)が不要になる場合に以下のように省略します。

抽出されたワード(コンセプト)がそのままフィールド名になります。

4.参考情報
Python連携によるテキストマイニング
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)