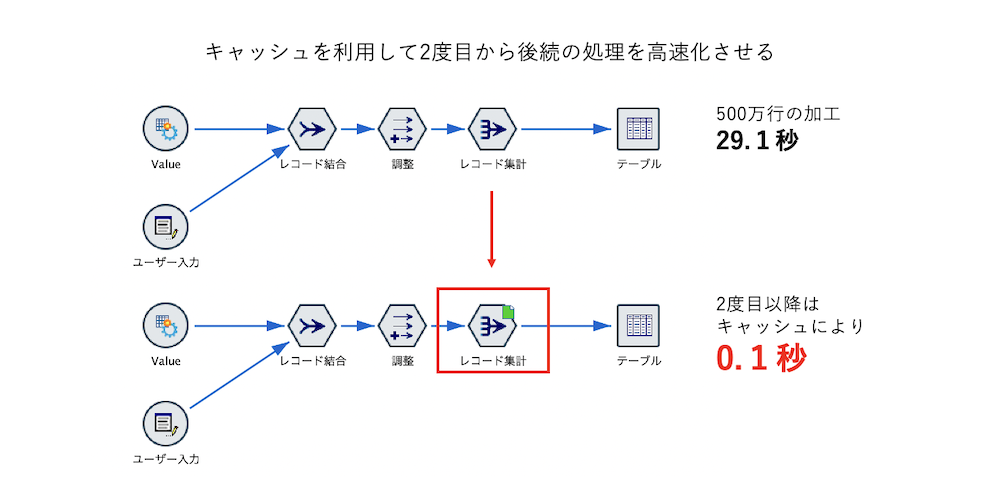
キャッシュで2度目以降の処理速度を上げる
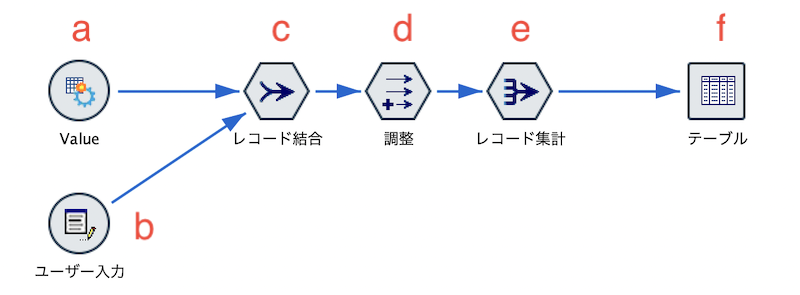
1.想定される利用目的
・大規模なCSVなどのフラットファイルを入力にした際のデータ加工速度の向上
2.サンプルストリームのダウンロード
3.サンプルストリームの説明
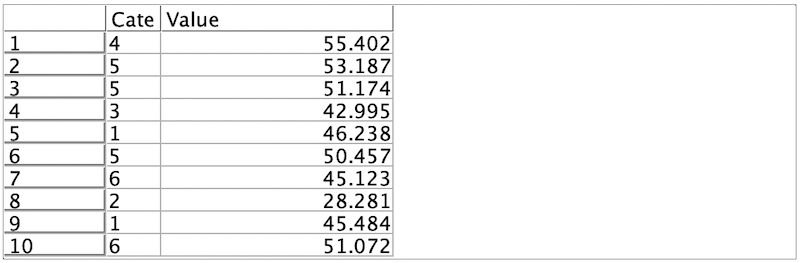
a.入力するデータのひとつ目です。6種類のカテゴリーと値が100万レコード(行)生成されます。
b.入力ふたつ目はカテゴリの重みマスタです。

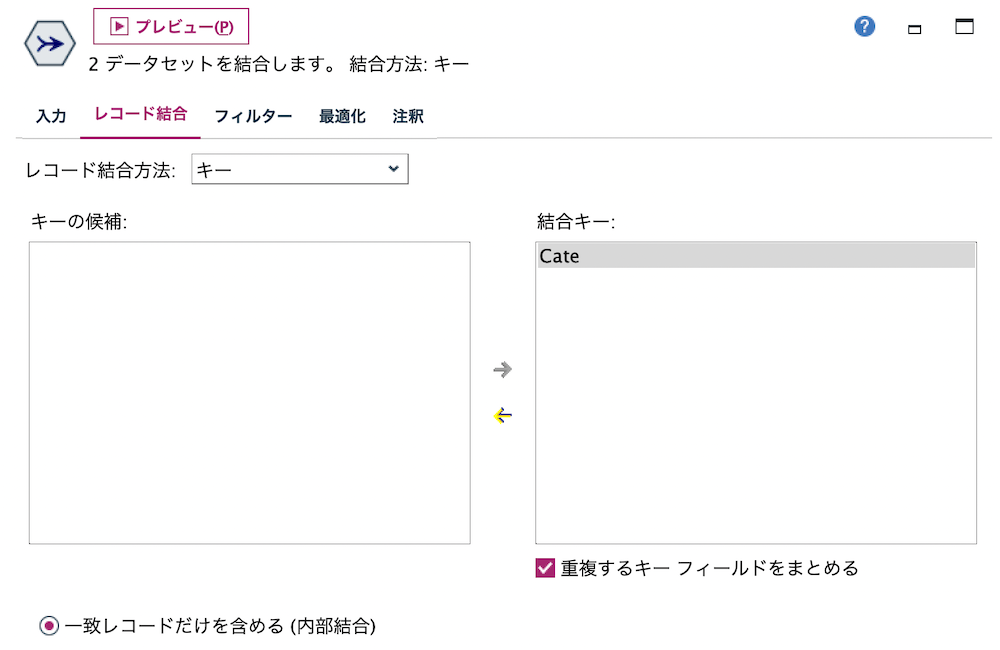
c.[レコード結合]ノードを編集します。ふたつの入力データを[Cate]をキーに内部結合します。
d.[フィールド作成]ノードを編集します。値に重みを掛けます。
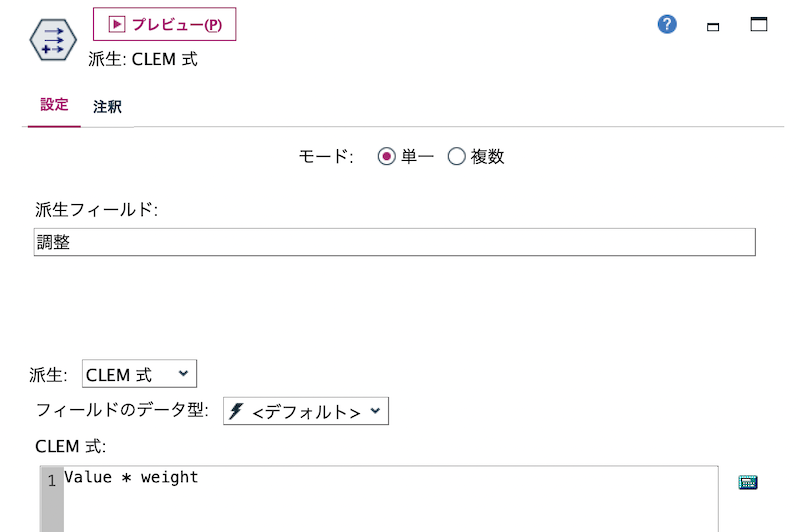
[プレビュー]します。
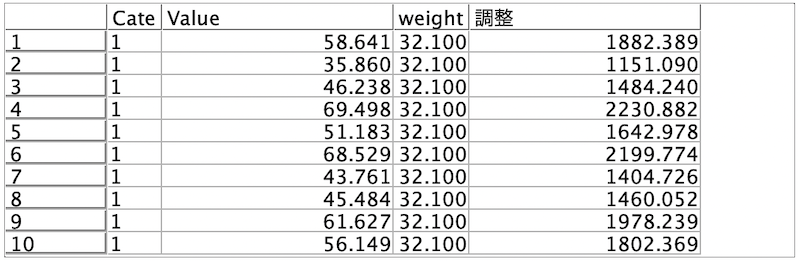
e.[レコード集計]ノードを編集します。
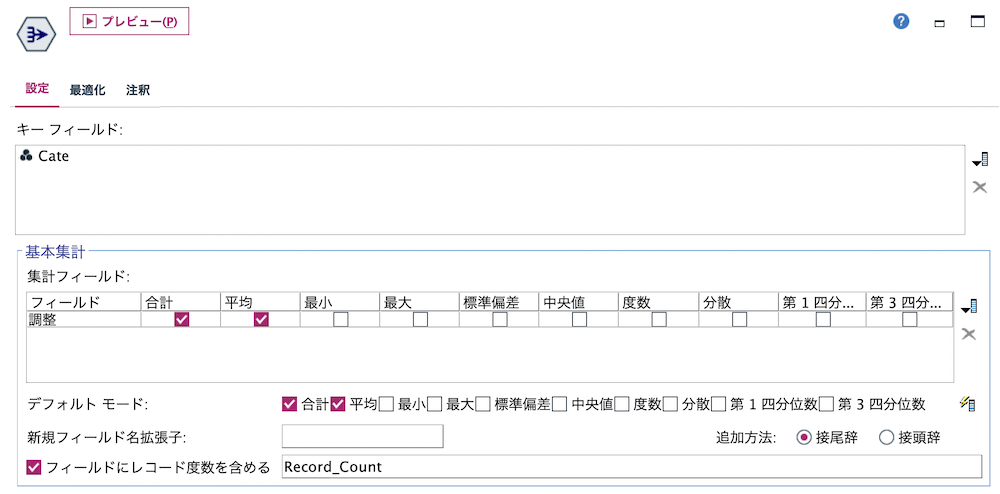
[レコード集計]ノードを右クリックして[キャッシュを使用する]を選択します。

[レコード集計]ノードに白いバッジがつきました。
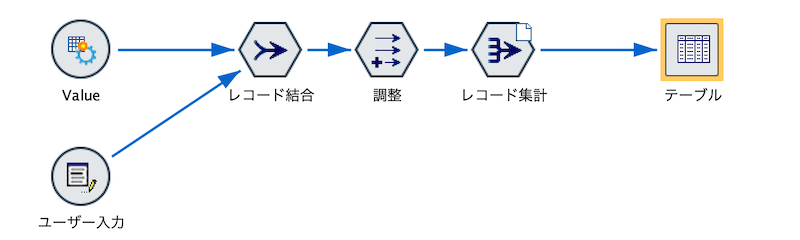
f.[テーブル]を実行します。バッジが緑に点灯しました。

メモリ16GBのMacで28秒処理に時間がかかりました。

もう一度[テーブル]実行します。レコード集計段階でキャッシュされているため1秒かからずテーブルが表示されます。後続処理が続く場合には時間の短縮が期待できます。

注意事項
後続でもキャッシュを利用すると全体としてメモリ超過になるため適宜不要なキャッシュは[キャッシュを使用しない]で解放します。またストリームが完成してバッチ化される際には全てキャッシュは不要です。
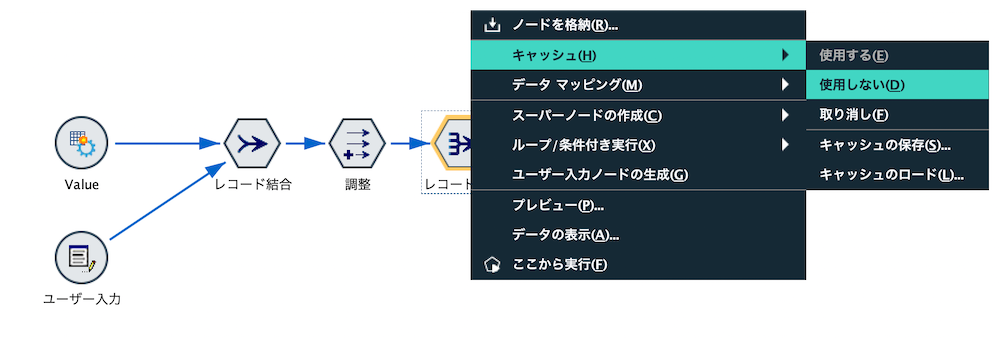
キャッシュを中間ファイルとして[保存]して、次回の作業で呼び出([ロード])して再利用することも可能です。SPSS形式であるため圧縮率が高いメリットがあります。もちろん明示的に中間ファイルを作成していただいても結構です。
4.参考情報
キャッシュを解説した記事
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)