自動分類ノードで2値の判別予測の確信度が0.5を下回る理由
1.想定されるトラブル
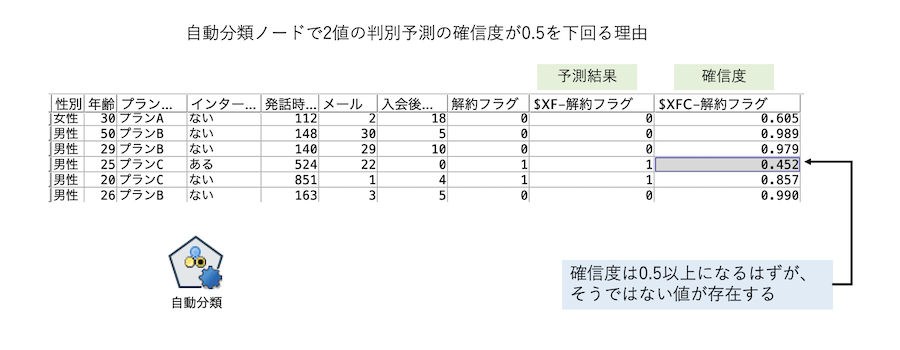
・2値の判別予測時に自動分類ノードを用いると不自然な確信度が表示される
→シングルモデルによる2値分類では確信度0.5を分岐点に真偽を判別するため、
確信度は0.5以上ですが、 アンサンブル学習のロジック上、起こり得る現象です。
2.ストリームのダウンロード
3.サンプルストリームの説明

a.入力は以下の通りです。スマートフォンの利用状況から事後の解約を予測するためのデータです。

不自然な確信度の確認
b.[データ型]ノードを編集します。

c.[自動分類]ノードを編集します。[使用モデル数]を説明しやすいように3つにしています。

d.[自動分類]ナゲットを編集します。[C5.0][XGBoostツリー][CHAID]の3つのモデルが選択されました。

e.[ソート]ノードを編集します。確信度を[昇順]で並び替えます。

f.[テーブル]ノードを実行します。3つのモデルを統合した確信度[$XFC-解約フラグ]には本来存在しない0.5以下のスコアが表示されています。

確信度算出のロジックを確認
g.[自動分類]ノードを編集します。[アンサンブル モデルにより生成された...]のチェックを外します。

h.[テーブル]ノードを実行します。

先頭レコードの確信度が0.452になる理由は
C5.0 はTrue と予測して確信度が0.800
XGBoost はTure と予測して確信度が0.555
CHAID は False と予測して確信度が0.818
Tureの確信度のみ合計し、モデル数で按分 (0.8+0.55)/3 = 0.452になります。
アンサンブルの記事でも取り上げています。
注意事項
SPSS Modeler (Ver18.5) では確信度=0.5丁度の場合にはFalse
SPSS Statistics (Ver30) では確信度=0.5丁度の場合にはTure
で判定されます。Statisticsにはアンサンブルや自動分類がないためこの記事の主旨とは
異なりますが参考まで。
4.参考情報
自動分類ノード
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)