こんにちは。現在 python & AI を勉強中のデザイナー yu です。
画像分類モデルの制作過程をアウトプット課題の一環&覚書用途で投稿します。
後々、デザイナー的に便利だと感じたpythonを使った作業効率化なども投稿していきたいなと考えています。
まだひたすらコードを書いて慣れようとしている段階のプログラミング初心者ですが、
暖かくご指摘・コメントいただければ幸いです。
制作の流れ
1.学習用データの準備
2.画像の前処理
3.モデルの定義
4.モデルの学習
5.モデルの評価と予測
6.モデルの保存
Step 1. 学習用データの準備
学習データとしてKaggleのデータセットを使用します
花の種類は以下の5種類です
- Daisy: 雛菊
- Dandelion: 蒲公英
- Rose: 薔薇
- Sunflower: 向日葵
- Tulip: チューリップ
Step 2. 画像の前処理
フォルダ名のリストを取得します。
※後ほどファイルパスや、花の名前の診断に使います。
path_datasets = "/content/flowers_datasets/"
# フォルダ名をリストで取得
flowers_data = os.listdir("/content/flowers_datasets")
flowers_data.sort()
>>>
['daisy', 'dandelion', 'rose', 'sunflower', 'tulip']
花のデータセットを読み込んで、すべてのフォルダのデータを合体させるfor文をまわします。
このとき画像サイズを 64x64 の正方形にリサイズし、
enumerate関数を使って、フォルダのindexも花を分類するためのラベルとして取得します。
num_classes = len(labels)
img_size = 64, 64
image_names = []
all_images = []
all_labels = []
# 各フォルダから画像をリサイズ&フォルダごとのラベルをつける
for label, flower in enumerate(flowers_data):
for file in os.listdir(os.path.join(path_datasets, flower)):
if file.endswith("jpg"):
# 画像のリサイズ
img = cv2.imread(os.path.join(path_datasets, flower, file))
im = cv2.resize(img,img_size)
all_images.append(im)
# フォルダのindexをラベルとして使う
all_labels.append(label)
else:
continue
上記でまとめた画像データをnumpy配列に変換して、シャッフルします。
# データをnumpy配列に変換
X = np.array(all_images)
y = np.array(all_labels)
# データのシャッフル
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
画像とラベルデータを学習用:80%, テスト用:20%に分割します。
numpy配列の配列[0,255]の値を[0,1]に正規化
ラベル用データをto_categorical()でベクトル化する
# データの分割
# データの分割
X_train, y_train = X[:int(len(X)*0.8)], y[:int(len(y)*0.8)]
X_test, y_test = X[int(len(X)*0.8):], y[int(len(y)*0.8):]
X_train, X_test = X_train / 255.0, X_test / 255.0
y_train, y_test = to_categorical(y_train), to_categorical(y_test)
Step 3. モデルの定義
下記のコードでモデルの定義を行います。
今回はKerasのSequentialモデルと学習済モデルVGG16を使った転移学習で分類をしていきます。
VGG16は、大量のデータですでに学習され公開されている
畳み込み13層+全結合層3層=16層のニューラルネットワークで、
学習済みのモデルを使って新たなモデルの学習を行うことを「 転移学習 」といいます。
まず最初にVGG16のインスタンスをつくります。
その後、Sequentialのインスタンスを作成して、新しく3層追加してVGG16と連結させます。
最後に 学習率の変更方法や損失関数をどうするか、表示する精度指標を何にするかなどを選択して
コンパイルを行い、ニューラルネットワークモデルの生成を終了します。
# vgg16のインスタンスの生成
# ---------------------------
input_tensor = Input(shape=(img_size[0], img_size[1], 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# ---------------------------
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
Dropout(rate=0.5)
top_model.add(Dense(num_classes), activation='softmax'))
# モデルの連結
# ---------------------------
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# ---------------------------
# vgg16の重みの固定
# ---------------------------
for layer in model.layers[:15]:
layer.trainable = False
# ---------------------------
# 転移学習をする場合、最適化はSGDで行うと良い
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
Step 4. モデルの学習
ローカル環境で実行するとマシンスペックにもよりますがとても時間がかかります。
GoogleColabのGPUを使用すると早く学習が終わります。ただし、リミット制限にすぐひっかかるので注意。
# モデルの学習
history = model.fit(X_train, y_train, batch_size=16, epochs=10, verbose=2, validation_data=(X_test, y_test))
学習結果を分かりやすくするためにmatplotlibでグラフ化します。
# 可視化
plt.plot(history.history['accuracy'], label='acc', ls='-', marker='o')
plt.plot(history.history['val_accuracy'], label='val_acc', ls='-', marker='x')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.suptitle('model2', fontsize=12)
plt.legend()
plt.show()
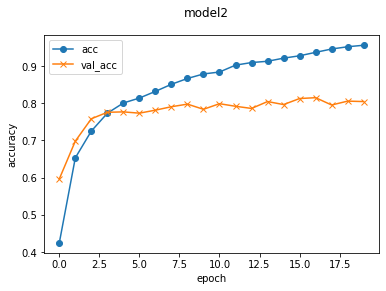
訓練データの精度:94% テストデータの精度:80%
学習データの精度はぐんぐん上がったけれども、テストデータは途中から横ばいなので過学習だな…
下記を参考に後日調整しようと思います。
Step 5. モデルの評価と予測
学習に使用していないテストデータを使用してモデルの評価を行います。
score = model.evaluate(X_test, y_test)
モデルの予測を受け取ります。
pred = np.argmax(model.predict(分類したい画像))
Step 6. モデルの保存
学習したモデルを保存します。
# resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
model.save(os.path.join(result_dir, 'model.h5'))
files.download( '/content/results/model.h5' )
Webアプリに実装
作った学習モデルを Flaskを使用して制作したWebアプリに実装します。
制作アプリ
CLASSIFY 5 FLOWERS APP
動作実験
画像検索で手に入れた向日葵の画像を使って実験をしてみました。
めっちゃ分かりやすい画像のおかげか、ちゃんと認識できたようです ![]()

おまけ
花のイラストでも実験してみました。向日葵は残念ながら不正解でしたが、
薔薇はなんと正解しました!! 形に特徴があるから認識しやすかったのか…?
今度、イラストも学習データに加えたバージョンを試してみようと思います。
CNNには他にもたくさん技術があるので、深堀りしていろいろチャレンジしていきたいと思います。
