深層学習
Section1:強化学習
- 長期的に報酬を最大化できるように環境のなかで行動を選択できるエージェントを作ることを目標とする機械学習の一分野
- 行動の結果として与えられる利益(報酬)をもとに、行動を決定する原理を改善していく仕組み
- 不完全な知識を元に行動しながら、データを収集し、最適な行動を見つけていく。
Section2:Alpha Go
- Google DeepMindによって開発されたコンピュータ囲碁プログラム
- CNNを用いて予測する
- 勝敗のみを使って探索を行うモンテカルロ木探索を行う。
- AlphaGo Zeroの学習は自己対局による教師データの作成、学習、ネットワークの更新の3ステップで構成される
Section3:軽量化・高速化技術
データ並列化
- 親モデルを各ワーカーに子モデルとしてコピーする。
- データを分割し、各ワーカーごとに計算させることで、分散学習ができるようになる。
- 各モデルのパラメータの合わせ方で、同期型か非同期型か決まる。
- 現在は同期型の方が精度が良いことが多いので、主流となっている。
モデル並列化
- 親モデルを各ワーカーに分割し、それぞれのモデルを学習させる。
- 全てのデータで学習が終わった後で、一つのモデルに復元する。
- モデルを分割し、各ワーカーごとに計算させることで、分散学習ができるようになる。
- モデルのパラメータ数が多いほど、スピードアップの効率も向上する。
量子化
- 軽量化の手法の一つ
- ネットワークが大きくなると大量のパラメータが必要なり、学習や推論に多くのメモリと演算処理が必要なため、パラメータの精度を落とす。
- 計算の高速化と省メモリ化が期待できるが、精度が落ちる可能性がある。
蒸留
- 精度の高いモデルはニューロンの規模が大きなモデルになっているため、推論に多くのメモリと演算処理が必要
- 規模の大きなモデルの知識を使い軽量なモデルの作成を行うことを蒸留という。
- 知識の継承により、軽量でありながら複雑なモデルに匹敵する精度のモデルを得ることが期待できる
プルーニング
- ネットワークが大きくなると大量のパラメータなるがすべてのニューロンの計算が精度に寄与しているわけではない
- モデルの精度に寄与が少ないニューロンを削減することでモデルの軽量化、高速化が見込まれる
- 寄与の少ないニュローンの削減を行いモデルの圧縮を行うことで高速化に計算を行うことができる
Section4:応用技術
MobileNet
- ディープラーニングモデルは精度は良いが、その分ネットワークが深くなり計算量が増える。
- 計算量が増えると、多くの計算リソースが必要で、お金がかかってしまう。
- ディープラーニングモデルの軽量化・高速化・高精度化を実現(その名の通りモバイルなネットワーク)
- Depthwise ConvolutionとPointwise Convolutionの組み合わせで軽量化を実現する
DenseNet
- ニューラルネットワークでは層が深くなるにつれて、学習が難しくなるという問題があった。
- 前方の層から後方の層へアイデンティティ接続を介してパスを作ることで層が深くても学習できるようにした。
- 前方の各層からの出力を全て後方の層への入力に用いる。
BatchNorm
- レイヤー間を流れるデータの分布を、ミニバッチ単位で平均が0、分散が1になるように正規化する。
- ニューラルネットワークにおいて学習時間の短縮や初期値への依存低減、過学習の抑制など効果がある。
- Batch Sizeが小さい条件下では、学習が収束しないことがあり、代わりにLayer Normalizationなどの正規化手法が使われることが多い。
LayerNorm
- 全てのチャネルの平均と分散を求め正規化する。
- 入力データや重み行列に対して、入力データをスケールしても、出力が変わらない。
- 入力データや重み行列に対して、重み行列をスケールやシフトしても、出力が変わらない。
WaveNet
- 生の音声波形を生成する深層学習モデル
- Pixel CNN(高解像度の画像を精密に生成できる手法)を音声に応用したもの
- 時系列データに対して畳み込み(Dilated convolution)を適用する
- 層が深くなるにつれて畳み込むリンクを離すDilated convolutionを提案した。
Seq2seq
- Encoder-Decoderモデルの一種を指す。
- 機械対話や、機械翻訳などに使用されている。
- Encoderの最終状態をDecoderの初期状態にすることで元の文を元に文を生成できるようにする。
- Decoderは生成した単語を元に次の単語を出力する。
Transformer
- RNNによるseq2seqモデルは文章が長くなると表現力が足りなくなるという問題があった。
- 長い文章でも扱えるようにするためAttention機構を用いた。
- AttentionのSource、key, targetに全て同じものを使うことでRNNなどの再起的構造を持つニューラルネットを排除できる(Self-Attention)
物体検知

鳥瞰図:広義の物体認識タスクhttps://engineering.matterport.com/splash-of-color-instance-segmentation-with-mask-r-cnn-and-tensorflow-7c761e238b46
分類は画像に対し単一(または複数の)クラスラベルを出力するのに対し、物体検知はBounding Boxを出力する。
また、分類は物体の位置に関係なく行えるが、物体検知は位置が重要になるため、タスクとしてはより難しい。
VOC12、ILSVRC17、MS COCO18、OICOD18などのデータセットがある。

物体検知における一般的な出力例9https://arxiv.org/abs/1506.01497
セグメンテーション
入力画像の各ピクセルに対しラベル付けをするタスク。
CNNのPoolingによって落ちてしまった解像度をUp-samplingにより元に戻す。
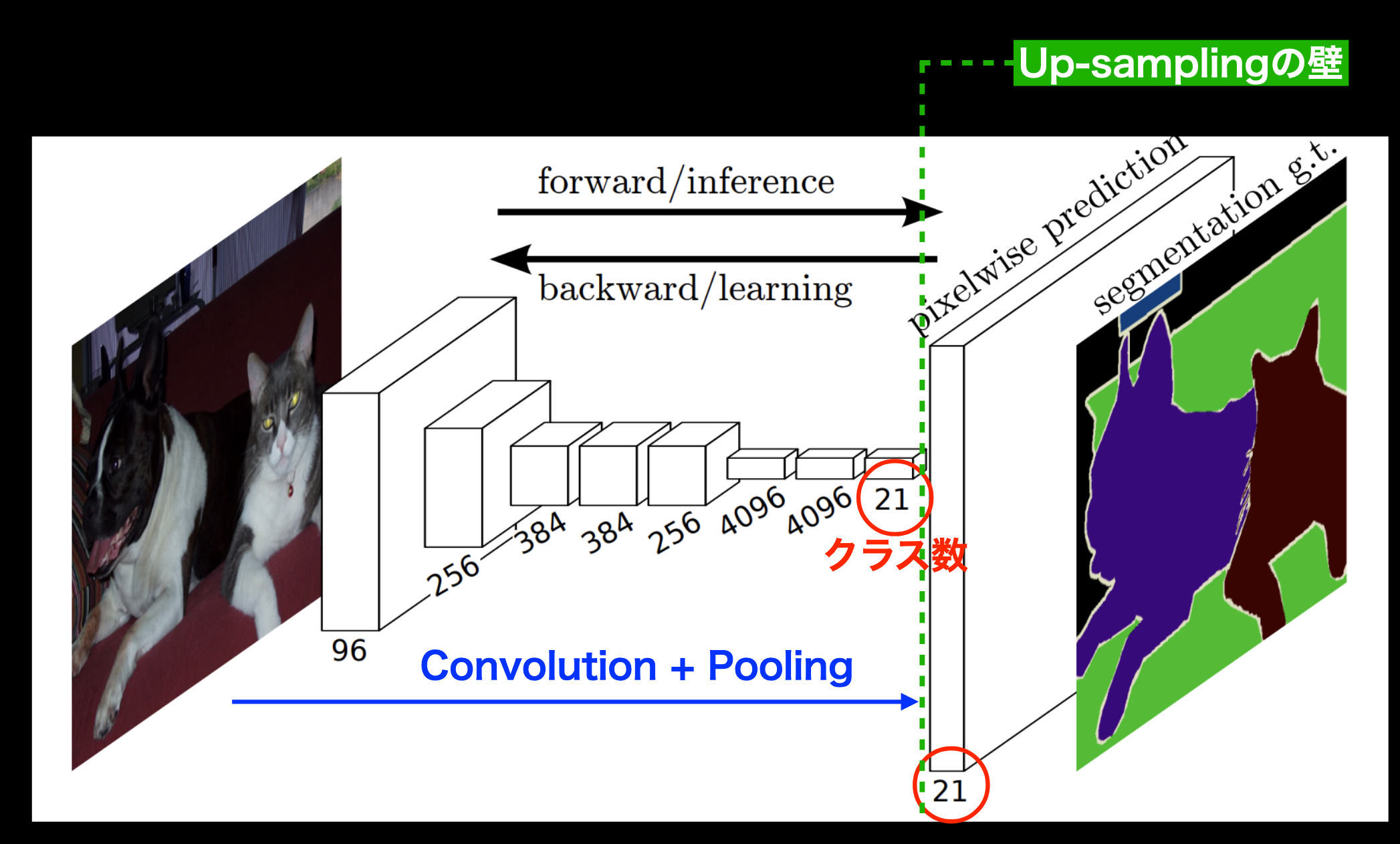
https://arxiv.org/pdf/1411.4038.pdf
Fully Convolution Networkを用いて最終的な出力がヒートマップのようになるように工夫し、低レイヤーPooling層の出力をelement-wise additionすることで輪郭情報を反映する。