無限長系列を扱うことができる言語モデルアーキテクチャを考案したのでそのメモです。
レポジトリにコードがあります。(色々継ぎ足しつつツギハギのコードなので汚いですが…)
以下では提案手法をSConvと呼びます。
(2023-09-05追記SpiralConvという名前が既に使われているようなので名前を変えました )
Hyena
SConvのベースとなるHyenaの構造でSConvに関係する部分について簡単に説明します。
Hyenaの各層における入力系列の特定の次元の値$x$に着目します。
このとき特定次元に着目した長さ$n$の入力系列は$x_0,x_1,\dots,x_{n-1}$となります。
Hyenaの処理では入力$x$にフィルタ$h$を畳み込みします:
\begin{align}
h_i &= {\rm FFN}({\rm POS}(i)) \\
y_i &= x_0\cdot h_i+x_1\cdot h_{i-1}+\cdots+x_i\cdot h_0\\
&=\sum_{j=0}^i x_jh_{i-j}\\
y_{[0,n)} &= x_{[0,n)}*h_{[0,n)}
\end{align}
ここで${\rm FFN}()$は学習可能なフィードフォワードネットワーク、${\rm POS}()$は位置エンコーディングです。
SConv
SConvではフィルタ$h$を減衰する複素等比数列とします。具体的には学習可能な複素数$z,w$に対して
\begin{align}
\zeta &= \frac{z}{|z|}\cdot e^{-|z|}\\
h_i &= \zeta^i\cdot w
\end{align}
とします。$w$が初期位相、初期振幅を表すパラメータで、$\zeta$が周波数と減衰に対応します。
$y_{[0,2n)}$の計算について考えると
\begin{align}
y_{n+i} &= x_0\cdot h_{n+i}+x_1\cdot h_{n+i-1}+\cdots+x_{n-1}\cdot h_{i+1}+x_n\cdot h_i+\cdots+x_{n+i}\cdot h_0\\
&= (x_0\cdot h_{n-1}+x_1\cdot h_{n-2}+\cdots+x_{n-1}\cdot h_0)\cdot\zeta^{i+1}+x_n\cdot h_i+\cdots+x_{n+i}\cdot h_0\\
&=y_{n-1}\cdot\zeta^{i+1}+x_n\cdot h_i+\cdots+x_{n+i}\cdot h_0
\end{align}
すなわち
y_{[0,2n)} = [y_{n-1},y_{n-1},\dots,y_{n-1}]\otimes[\zeta,\zeta^2,\dots,\zeta^n]+x_{[n,2n)}*h_{[0,n)}
となり、系列帳$n$毎に処理することを考えたときに前ステップの出力の最後の要素に$[\zeta,\zeta^2,\dots,\zeta^n]$をかけて現在ステップの畳み込みと足すことで過去も含めたフィルタの畳み込みができます。
SConvはこの畳込み操作による時間方向の混ぜ合わせとFFNを交互に積み重ねた構造となっています。
またTransformerと同様にLayerNormとResidualConnectionも用いています。
特徴
再帰性
上記のように前ステップの出力を用いて過去方向に無制限の畳み込みを行うことができ、TransformerやHyenaのような推論できるコンテキスト長の制限が存在しません。
軽量
Hyenaで用いているPositionalEncodingのFFNが存在しないため層あたりのパラメータ数は少なくなります。
また、畳み込み処理はFFTを用いて高速化できます。
実験ではVRAM24GBの環境(RTX4090)で1024次元、コンテキスト1024の学習でSConvを128層積み重ねて学習を行っています。
実験
学習
こちらで公開されている夏目漱石のデータセットを利用して実験を行いました(実験時のコミット)。
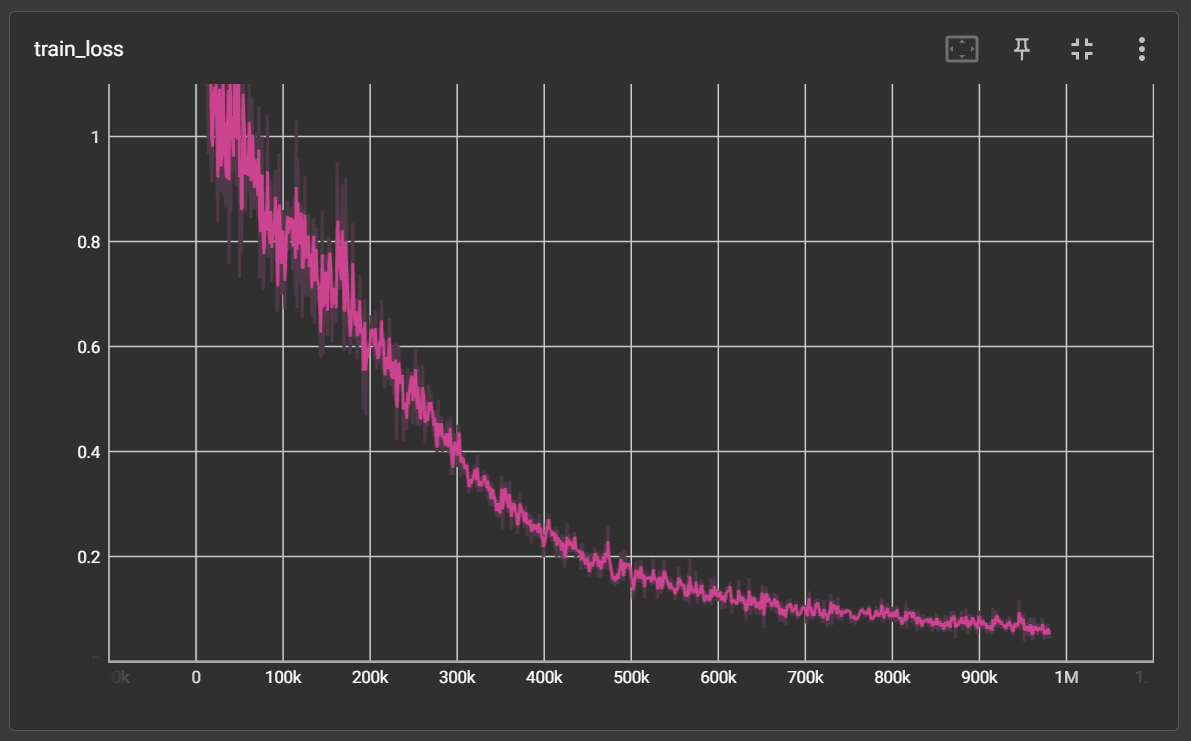
処理次元数を1024としてSConvを128層重ね、100epoch学習を行いました。
以下は学習時のCrossEntropy損失のグラフです(PyTorchLightning+Tensorboardの仕様で横軸はステップ数です)。
生成
SConvはRWKVのように学習時と生成時のコンテキストサイズを変更することができます。
推論時のコンテキストサイズが小さいほど推論にかかる時間は小さくなります。
今回学習時のコンテキストサイズは1024としましたが、推論時は256とし、長さ1024の生成をしてみました(プログラムがまだ十分でないため、コンテキストサイズは入力文字列のバイト数より大きくしましたが原理上コンテキストサイズは1でも推論はできます)。
入力した文字列:
吾輩は猫である
生成された文字列
吾輩は猫である今を至ると直に気召のない男――でなんだ事を予期、人生の時面に近側を受けて満足するからではない。
唐津田の前である。
教場へ出ると、柿はとうとあんなの馬車馬の香鹿と名乗りつけたるのもろか、タトメイされた名古屋と云ふものは全部、鉄瓶の悲劇があると云々、ことむしくでき上の非道を見守るので、蝙岡ではあるれ、乾々、やはり普通一般に及上りとする今ではなかったか)。
もう少し曲抔を持って東京まらんものもありゃしませりで、余まりは無了なのです。
生きていると思ったかり、文壇の中に跳るものがあったかも知れないが」と顛が出てきて、地球より光った時の価値の世界はともに動きう事もない。
元を短いても、国定の光線も非山に組み立てられている以上は、虚学というやはり一条にぬれたる運動がある。
懐師�
若干支離滅裂ですが概ね日本語の文法に従った文字列が生成されているようです。
最後の�はUTF-8のバイト列を直接生成していることによるエラー文字です。
今後
正常に学習ができるようなので次は日本語Wikipediaを学習させようかと思います。
また計算資源が有り余っている方でSConvのアルゴリズムに興味を持っていただけたら是非再現実装・実験していただけると幸いです。