知識不足な学生が勉強がてら色々やってみたので,その記録のために書きました.
背景
宗教上の理由により,私の所属する研究室のスケジューラは研究室内の端末からのみ見れるようになっています.
「上手いことしてslackに毎朝予定を通知することができれば,学校行けなかった期間に把握し損ねた予定をすっぽかしたりすることがないよな」と思っていたので,今回このタスクに着手することになりました.
ちなみにこれをやる前にgoogle calendar app の導入を試みたのですが,研究室の管理ツールをそっちに移したりすることもできず連携も上手くできなかったので導入を諦めました.
概要
今回通知を行うシステムは以下のような構成になっています.(図は超適当に作りました.)
scraping.pyとnotif.pyは研究室のサーバでcronで決まった時刻に動くようになっています.
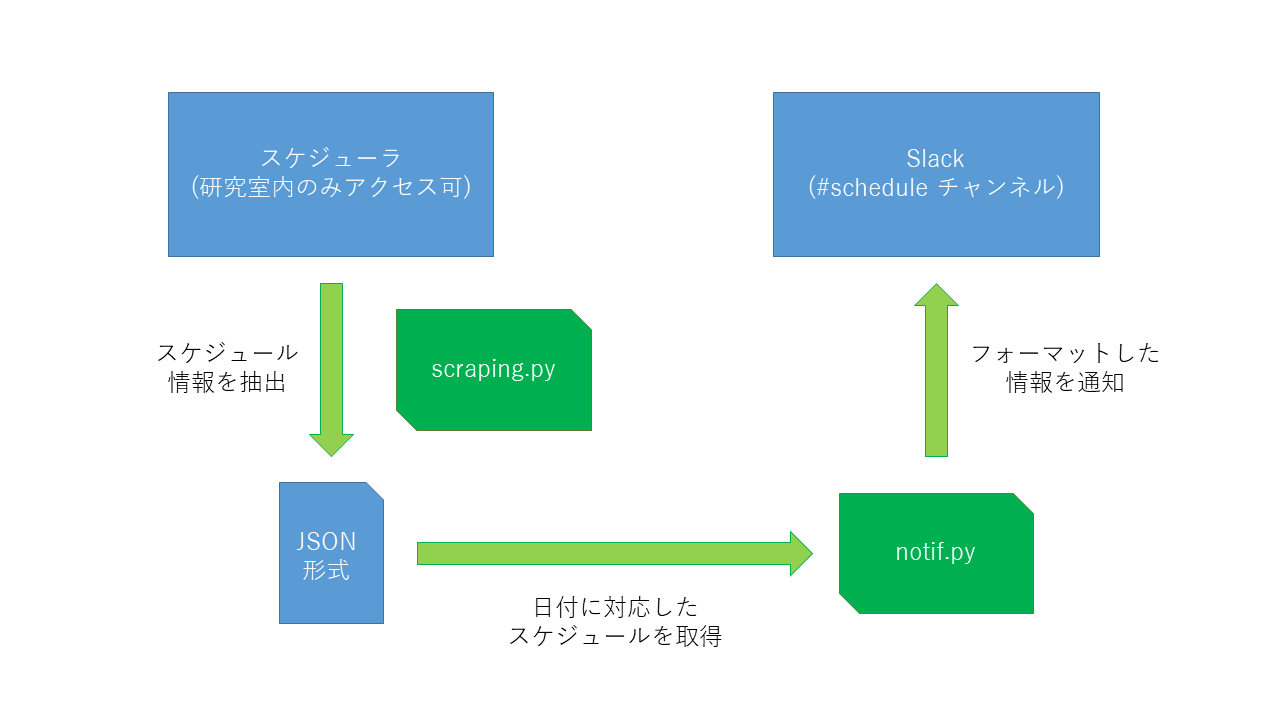
スケジューラのデータ取得と保存
scraping.pyあたりについてです.
trial and errorでスクレイピング.
正規表現らへんを少し触ってみたかったので
import re
import requests
...
html = requests.get('url').text
...
とページの情報を取得して,残りは気合で不要な情報をどんどん削って必要な部分を取り出しました.
そこらへんの話はggれば沢山出てくるのでそちらにお任せします.
今回はスケジューラから各スケジュールの「年月日と曜日」「タイトル」「本文」を取り出して以下のようにまとめました.
{'date': {'year': 2017, 'month': 10, 'day': 2, 'dow': 'Mon'}, 'title': '〇〇さん', 'text': '△限: 進捗報告'}
研究室のスケジューラの本文('text')にはaタグやspanタグを書くことができる仕様になっていて,抽出しただけでは悲惨なことになります.
それをslackにいい感じに表示してあげられるように整形しました.
import re
...
sentence = re.sub('<a href=\"(.*?)\">(.*?)</a>', r' <\1|\2> ')
sentence = re.sub('<span .*?>(.*?)</span>', r' *\1* ')
...
後はこの辞書をschedule_listなど適当なリストに月単位でまとめて,それを以下のように月別のjsonファイルに吐き出しました.
import json
...
with open(filename, 'w') as f:
json.dump(schedule_list, f, ensure_ascii = False, indent = 4, sort_keys = True, separators(',', ': '))
...
これにてデータの取得は完了です.
Slackへの通知
まずはSlack側の準備からです.
Slackにスケジュールを通知するチャンネルを作成して,Webhook URLを取得します.
URLの取得は下記リンクからできるので,準備しておきましょう.
https://slack.com/services/new/incoming-webhook
続いて,notif.pyあたりについてです.
以下のように,datetimeを使うことで現在の時刻情報を取得できます.
from datetime import datetime
...
today = {'year': datetime.now().year, 'month': datetime.now().month, 'day': datetime.now().day}
...
続いて,現在の日付に対応した情報をscraping.pyのときに取得したデータから取り出します.
import json
from datetime import datetime
...
with open(filename, 'r') as f:
schedule_list = json.load(f)
for schedule in schedule_list:
# 今回は年月ごとに一つのファイルを作ったので日付のみの比較
if schedule['date']['day'] == today['day']:
today_schedule_list.append(schedule)
...
予定がなければ(len(today_schedule_list) == 0)その旨を通知し,予定があればスケジュールの情報をattachmentsにまとめて通知する.
import requests
...
if len(today_schedule_list) == 0:
# urlはwebhookのurl
requests.post('url', data = json.dumps({
'text': 'There are no events today. :heart_eyes: ',
'username': 'Schedule Bot',
'icon_emoji': ':calendar:',
}))
else:
today_schedule_json = {'text': 'There are ' + str(len(today_schedule_list)) + ' events today.', 'username': 'Schedule Bot', 'icon_emoji': ':calendar:', 'attachments': []}
for schedule in today_schedule_list:
attachment = {'color': '#36a64f', 'title', '', 'title_link', 'scheduler_url', 'footer': 'Schedule Bot ' + str(schedule['date']['year']) + '/' + str(schedule['date']['month']) + '/' + str(schedule['date']['day']) + ' (' + str(schedule['date']['dow']) + ')'}
attachment['title'] = schedule['title']
attachment['text'] = schedule['text']
today_schedule_json['attachments'].append(attachment)
requests.post('url', data = json.dumps(today_schedule_json))
...
これにて今日の予定をSlackに通知する部分は完了です.
自動スクレイピングと自動通知
最後にscraping.pyとnotif.pyを自動で動かすcronの設定です.
crontab -eでcrontabの編集,crontab -lでcrontabの確認,crontab -rでcrontabの削除(全て削除)ができます.
書き方としては
[分] [時間] [日] [月] [年] 実行するコマンド
となっているそうです.
今回は「毎朝9時に本日の予定を通知」と「毎時間50分にスケジューラの情報を更新」の二つを行いたかったので,以下のように設定
0 9 * * * bash -l -c 'cd schedule_dir && /usr/local/bin/python3 notif.py'
50 * * * * bash -l -c 'cd schedule_dir && /usr/local/bin/python3 scraping.py'
これで自分の設定した時刻にpythonのプログラムが自動で実行されるようになりました.
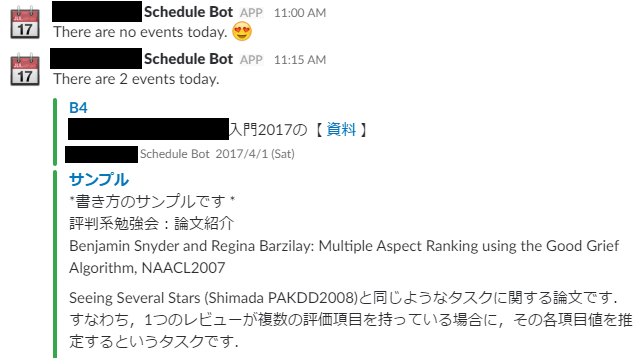
結果
以下のように,いい感じに通知が飛んでくるようになりました!
(このスクショはテストで動かしたものなので時刻のズレは気にしないでください.)
今後の課題
時々spanタグの処理がおかしなことになるので,そこらへん直せたらなと思います.
あとは折角なので日曜日に一週間の予定を通知したり,botを導入して予定を問い合わせたら予定のリストを返してくれるようなことができれば更に便利かなと思っています.(やるかは未定)
もしやる余裕があってやったらここにまとめます.
追記(2017/11/23)
このリマインダーを運用していると研究室の方々からいくつかフィードバックをいただきました.
-
スケジュールの無い日に通知くるのはちょっと...
-
朝9時にスケジュール飛んでくるのはいいけど俺その時間起きてないし(真顔)
-
そもそも1限は8時50分からだから予定のリマインド間に合ってない(白目)
というわけで改良を加えました.
import datetime
...
tm = datetime.datetime.now() + datetime.timedelta(days = 1)
tomorrow = {'year': tm.year, 'month': tm.month, 'day': tm.day}
...
import json
...
with open(filename, 'r') as f:
schedule_list = json.load(f)
for schedule in schedule_list:
# 今回は年月ごとに一つのファイルを作ったので日付のみの比較
if schedule['date']['day'] == tomorrow['day']:
tomorrow_schedule_list.append(schedule)
...
import requests
...
if len(tomorrow_schedule_list) != 0:
tomorrow_schedule_json = {'text': 'There will be ' + str(len(tomorrow_schedule_list)) + ' events tomorrow.', 'username': 'Schedule Bot', 'icon_emoji': ':calendar:', 'attachments': []}
for schedule in tomorrow_schedule_list:
attachment = {'color': '#36a64f', 'title', '', 'title_link', 'scheduler_url', 'footer': 'Schedule Bot ' + str(schedule['date']['year']) + '/' + str(schedule['date']['month']) + '/' + str(schedule['date']['day']) + ' (' + str(schedule['date']['dow']) + ')'}
attachment['title'] = schedule['title']
attachment['text'] = schedule['text']
tomorrow_schedule_json['attachments'].append(attachment)
requests.post('url', data = json.dumps(tomorrow_schedule_json))
...
0 21 * * * bash -l -c 'cd schedule_dir && /usr/local/bin/python3 notif.py'
50 * * * * bash -l -c 'cd schedule_dir && /usr/local/bin/python3 scraping.py'
大きな変更(?)としてはここら辺で,後は適宜変数名やスクレイピングの範囲などをいじりました.