いままでに、MongoDBのデータ分析に困ったことはありませんか?
一般的に、MongoDBのデータは、リレーショナルデータベースや表形式データと違うので、データが、よく階層になっていたり、入れ子構造になっていたり、配列を含んだりしていて、データの抽出や分析には適していないと言われています。でも、RのためのUIであるExploratoryを使えば、そんなMongoDBのデータでさえ簡単にインポートして、データを分析することができます。
Exploratoryの記事については、こちらでも詳しく書いています。
- Rのフロントエンドということで話題になっている、Exploratoryの対話的なデータ分析環境で「ヨーロッパはほんとに女性が活躍しやすい社会か」どうか分析してみた
- 本当にITバブルなのか?? RのフロントエンドExploratoryでユニコーン企業のデータを超簡単にスクレイピングしてきて、分析してみた
- テキスト・データを簡単にクリーン・アップしながらExploratoryのベータ版に世界中から登録してくれたユーザーの普段使っているデータ分析ツール上位ランキングを出してみた
1. MongoDB Dataのデータをインポート
これから、レストランのデータが集められている標準的なMongoDBのデータベースを使います。データはこちらからダウンロードできます。MongoDB website
Mongo DB のインポートダイアログを開いてください
New Data Frameメニューからデータを選んで、Import Remote Dataを選んでください。

Mongo DBをクリックしてください。

パラメータを設定してください
data frameの名前を入力してください。
Mongo DBの設定情報を入力してください。
- Host name
- Port number
- Database name
- Collection name
- Username
- Password
- Query - あなたが、特定のクエリを使っていない限り、デフォルトのままで大丈夫です。
- Flatten - 大抵の場合、デフォルトのままで大丈夫です。
注意:もし、MongoDBをローカルにインストールしている場合でも、ユーザーネーム、パスワードを指定した上での接続が必要になります。ユーザーネーム、パスワードなしでの接続はこれからのサポートしていく予定です。
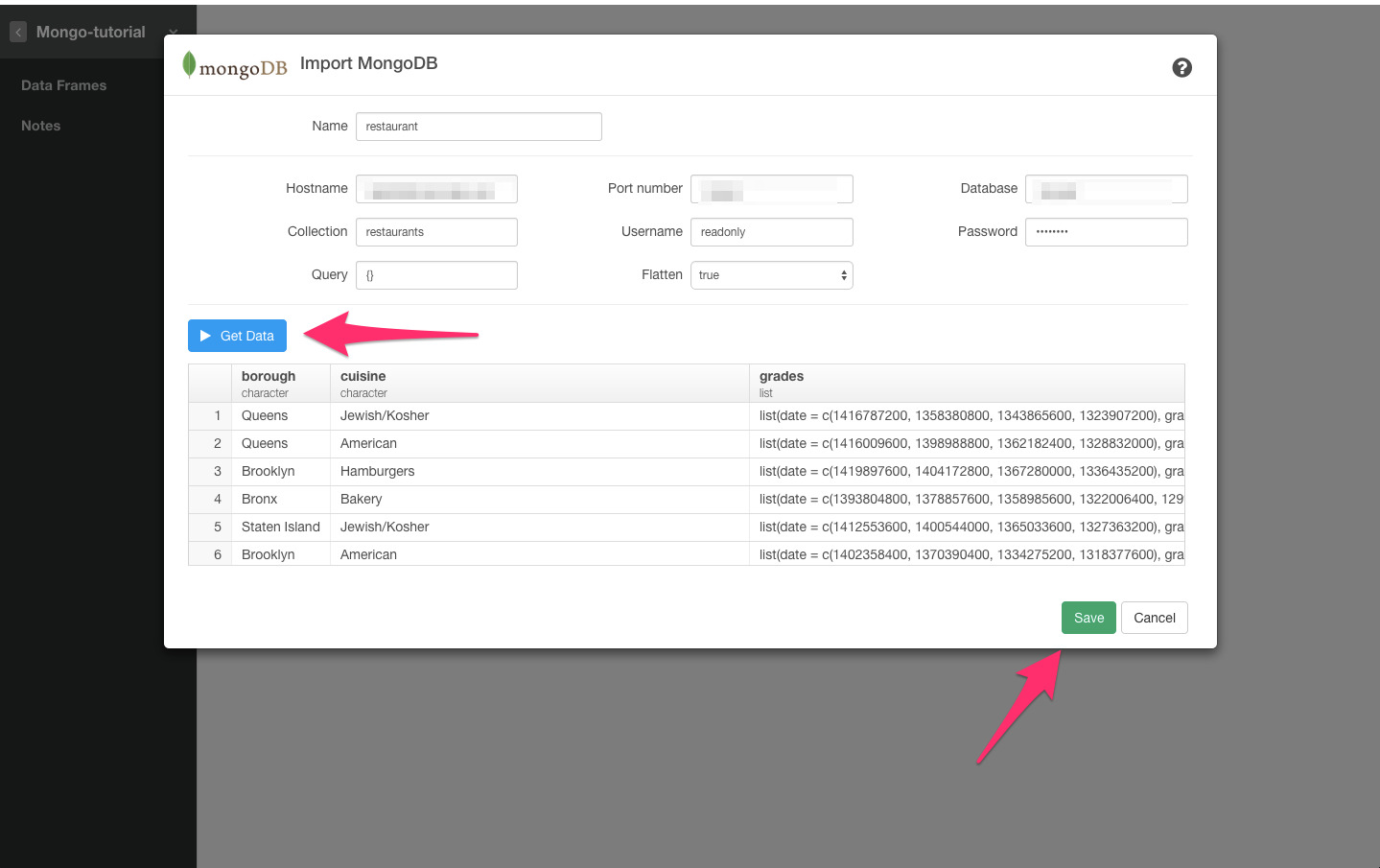
Mongo DBのデータを見れるように、GET DATAボタンをクリックしてください。
大丈夫そうだったら、データをExploratoryにインポートするためにSAVEボタンをクリックしてください。
すると、このようにデータがサマリー画面に表示されます。
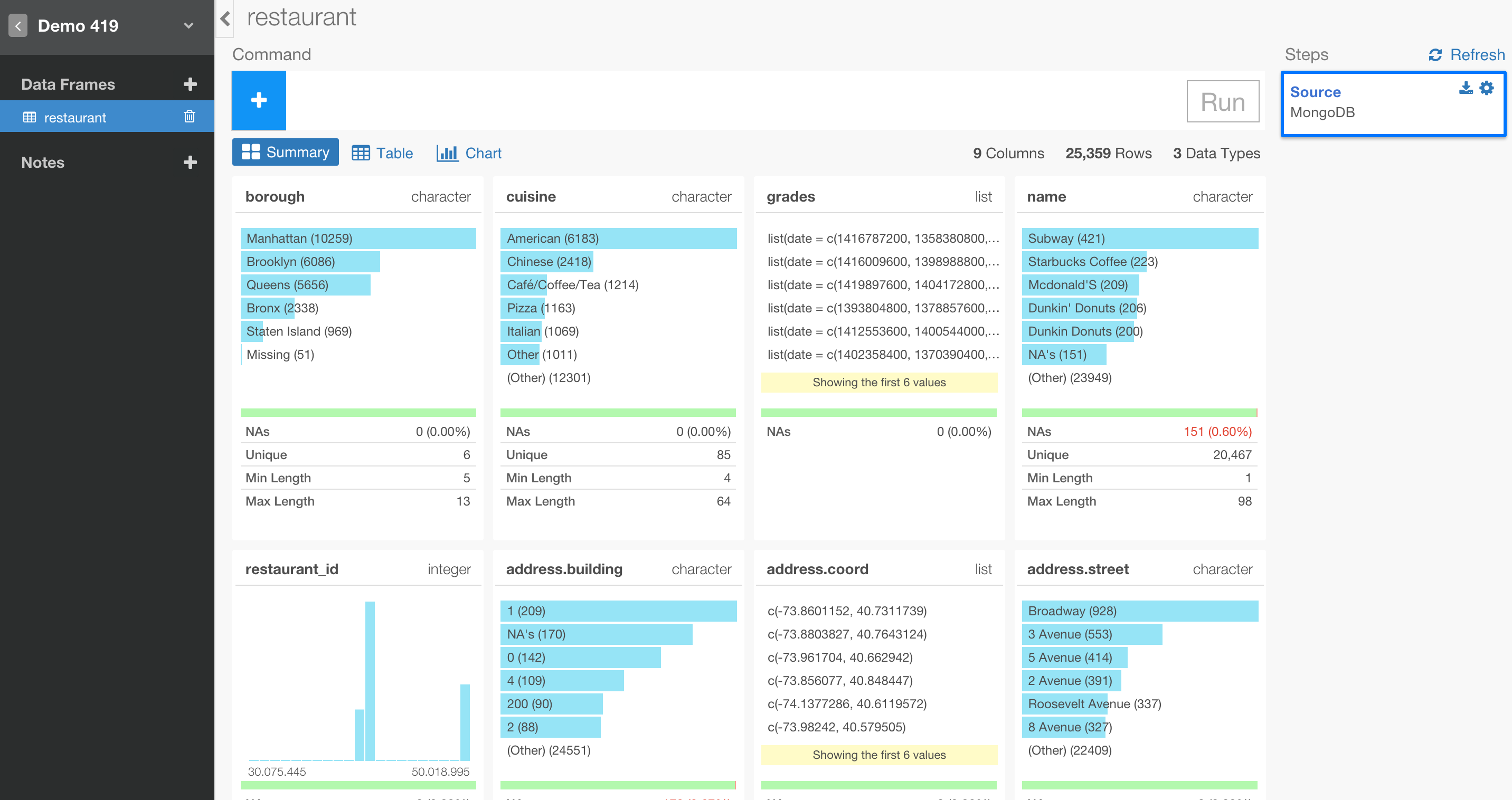
2. 入れ子構造になっているデータをUnnestしよう
MongoDBのデータベースは、リレーショナルデータベースではないので、データがよく入れ子構造になっていることが多いです。このデータでも、grades列を見てみると、データタイプがlistになってますよね。

テーブル画面に行くともう少し詳しく見ることができます。それぞれの日付に対して、レストランのgradesを持っている形になっています。

なので、この入れ子構造(nest)になっているのを、ほどいて(Unnest)、grade, score, date をそれぞれの行に落としこむ必要があります。Unnest関数を使うとそれをすることができます
grade列のヘッダーメニューからUnnestを選んでください。

すると、自動的にコマンドが入力されて、入れ子になっていたデータ構造がUnnestされて、date,grade,scoreの3つの列に分割されたのがわかりますね。
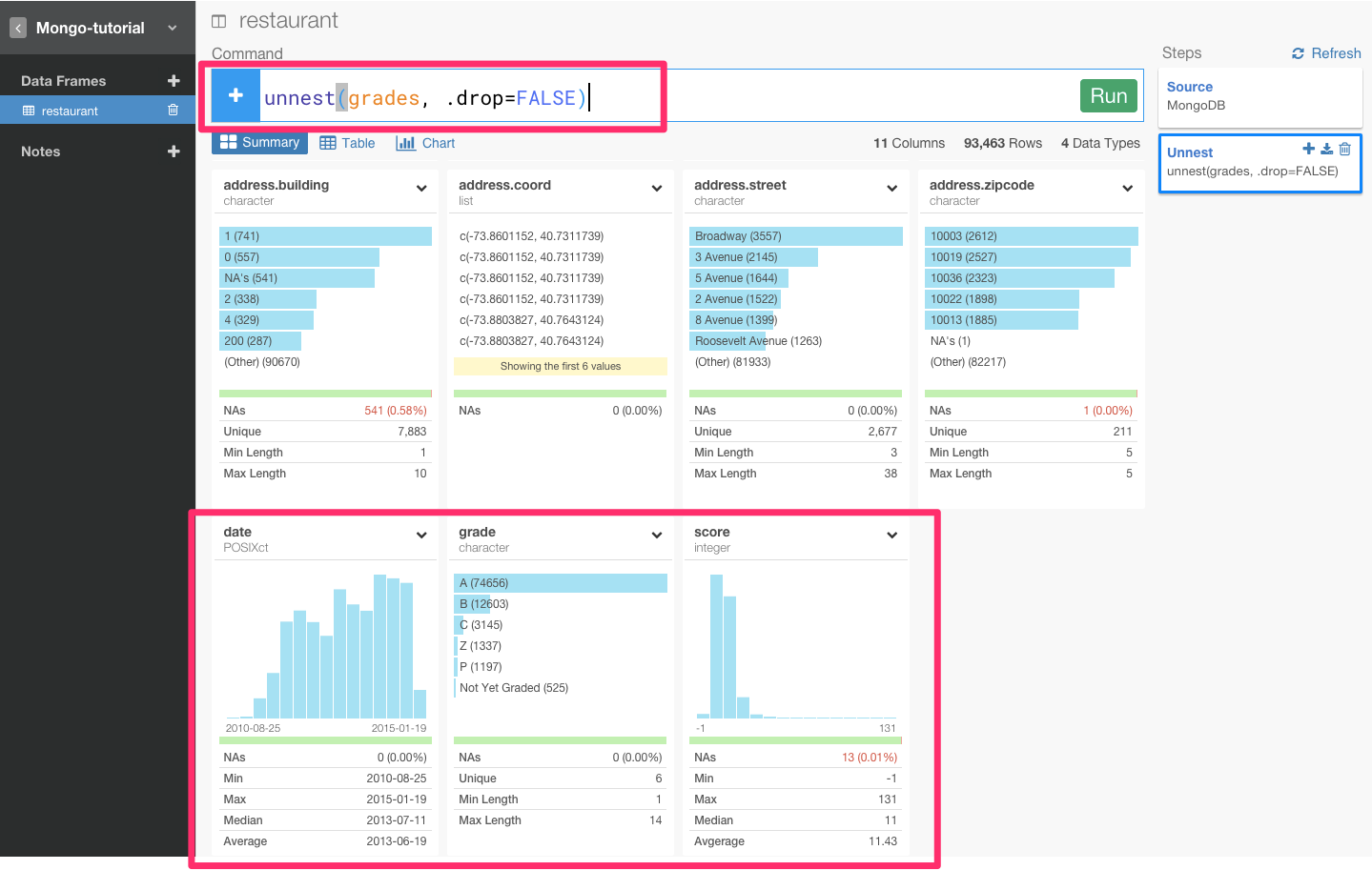
テーブルviewでも同様に。

ところで、このaddress.coordは、経度と緯度を表しているんですね。このカラムもlistになっているので、またunnestして2つの行にわけることももちろんできるんですが、経度と緯度という列を使って、ビジュアライズすることもできます。

そうするときは、いくつかやり方があるんですが、これから一番簡単な方法をご紹介します。
3. データタイプがListになっている列から値を抽出しよう
+アイコンを押すと出てくるドロップダウンメニューからMutateを選んでください。

新しいカラムとしてlongitudeと入力したあとに、=を入力してください。

スペースをタイプすると、列と関数の一覧がレコメンドされます。Open Function Selectorでは、関数をタイプ別から検索することができます。クリックしてください。

Listカテゴリーを選んでください。

すると、データタイプが、Listのものに対して使うことができる関数を見ることができます。そこから、list_extract関数を選んでください。

Insert Functionをクリックしてください。

レコメンドされたリストからaddress.coord列を選んでください。

カンマの後に、1と入力してください。
mutate(longitude = list_extract(address.coord, 1))
同じように、latitudeの値を抽出するために、'mutate()'コマンドの中にlatitude列を加えてください。カンマの後に、2と入力してください。
mutate(longitude = list_extract(address.coord, 1), latitude = list_extract(address.coord, 2))
Runボタンを押してください。すると、いま作成したlongitude列とlatitude列ができているのがわかりますね。

これでデータは充分です。経度と緯度の列ができたので、この2つを使って、データをビジュアライズ化してわかりやすくしてみましょう。
チャート画面に行って、チャートタイプでマップを選んで、Longitudeにlongitude列を、Latitudeにlatitude列を指定してください。

あれ? でも結果は少し変ですね。

boroughカラムを見てみると、レストランのほとんどは、マンハッタンとかブルックリンとかクイーンなどニューヨークの都市になっています。でも、マップを見てみると、ニューヨーク以外にもたくさんあるように見えますよね?

でもデータをズームしてみると、ほとんどのレストランはニューヨークに集中していることも確認できます。
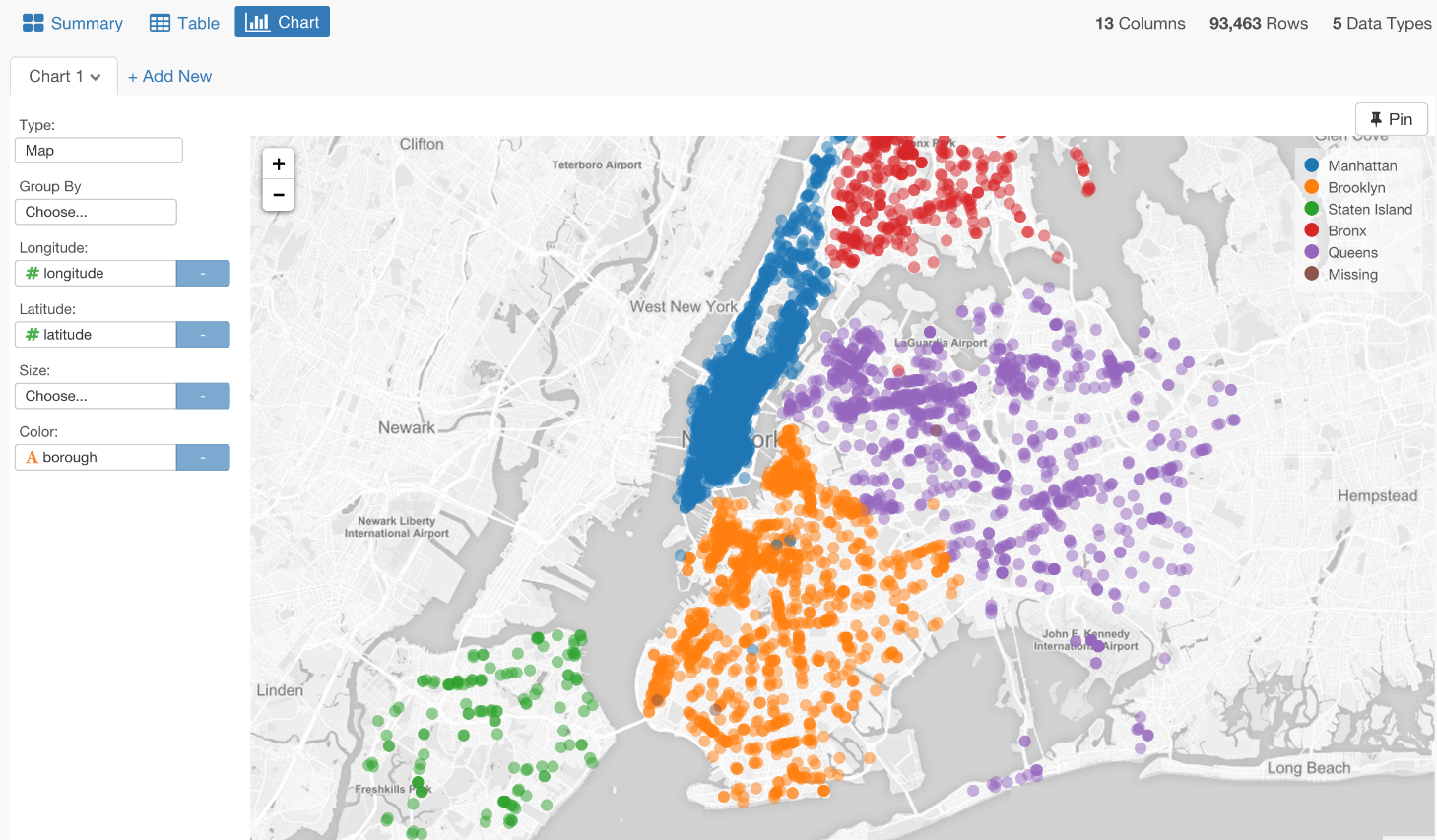
これはつまり、いつかのレストランは間違った位置データを持っているということなんです。
4. 四分位数範囲を計算して、外れ値を見つけて、取り除く
間違った位置データを除くためには、データの25%から75%の間を意味する四分位数範囲を計算する必要があります。quantile関数を使うと、引数で指定した、分位数を取得することができます。例えば、0.75なら第三四分位数を取得できます。四分位数範囲のことを英語で、interquartile rangeと呼ぶんですが、Rでは、その3文字をとったiqr関数を使うことで、データの四分位数範囲を取得できます。そして、四分位数範囲を取得すると、第三四分位数に対して、iqrの1.5倍を足したもののほうをupper_rangeという名前の列にして、第一四分位数に対して、iqrの1.5倍をひいたもののほうを、lower_rangeとします。
upper_range = iqr(latitude) * 1.5 + quartile(latitude, .75)
lower_range = quartile(latitude, .25) - iqr(latitude) * 1.5
Exploratoryを使ってひとつづつやっていきましょう。
緯度のUpper Range を計算する
計算結果をわかりやすく見るために、テーブル画面に行ってください。
新しいステップを加えるために、+ボタンをクリックしてください。そして、下記のように入力してください。
mutate(upper_range = IQR(latitude, na.rm=TRUE) * 1.5 + quantile(latitude, 0.75, na.rm=TRUE))

緯度のLower Rangeを計算する
+ボタンをクリックしてください。そして、下記のように入力してください。
mutate(lower_range = quantile(latitude, 0.25, na.rm=TRUE) - IQR(latitude, na.rm=TRUE) * 1.5)

緯度がupper rangeとlower rangeの間にあるか確認する
今なら、latitudeカラムがupper_rangeとlower_rangeの間にあるかを確認することができます。
+ボタンをクリックしてください。そして、下記のように入力してください。
mutate(within_range = latitude < upper_range & latitude > lower_range)
lower_rangeとupper_rangeの間であるという条件を満たしているかどうかの結果がwithing_rangeという列にTRUEかFALSEとして入ります。

今なら、チャート画面に行って、色にこの新しいwithin_rangeカラムを指定することができます。そして、ニューヨークに向かってズームしてください。
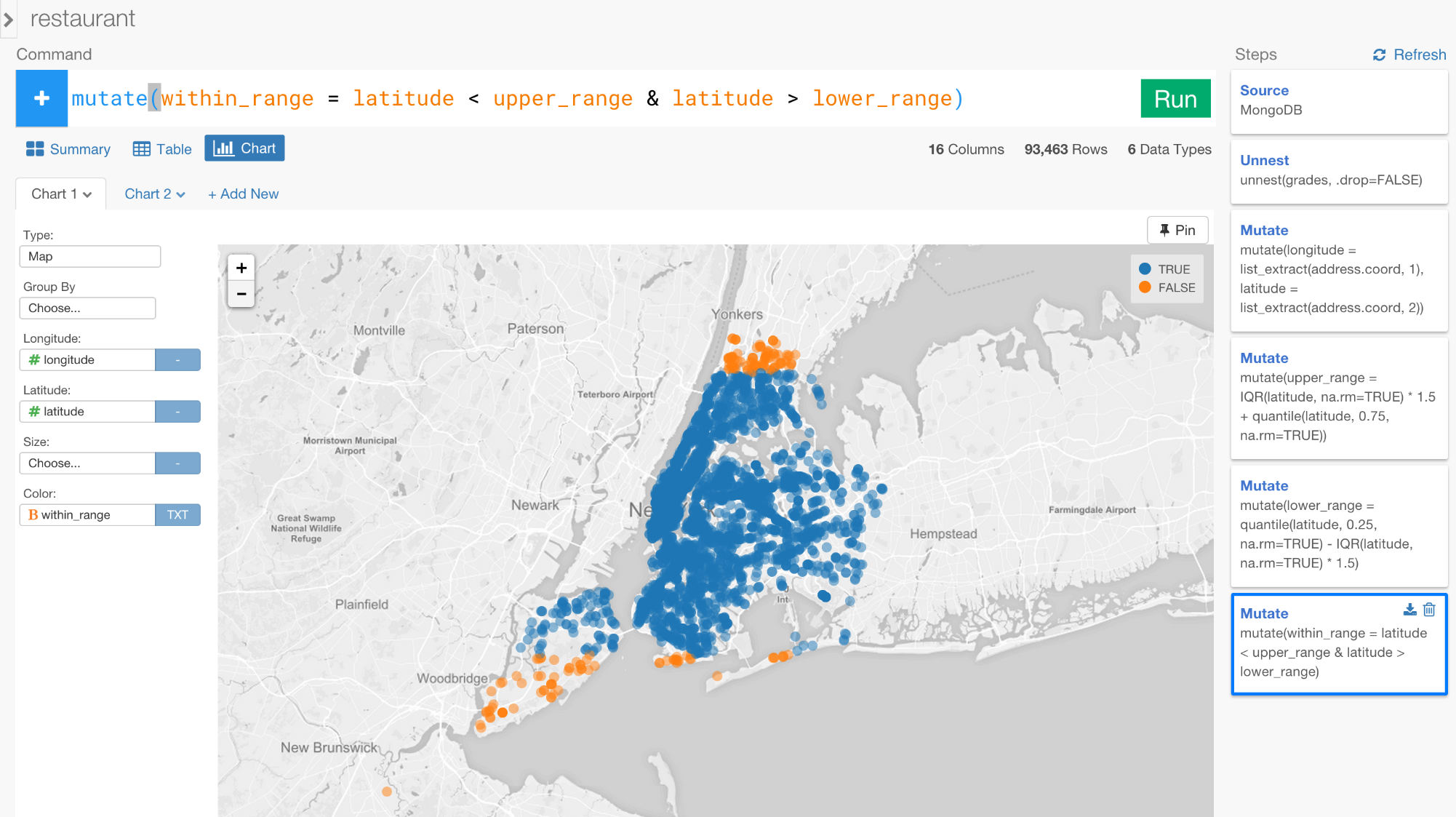
ほとんどのレストランが、外れ値ではないけれども、まだいくつかは外れ値になっています。これは、閾値として指定した1.5倍という数字がきつすぎたからかもしれません。1.5ではなく3に更新することで、この外れ値を取り除くことができます。
更新するために前のステップに戻る前に、Pinボタンをクリックしてください。
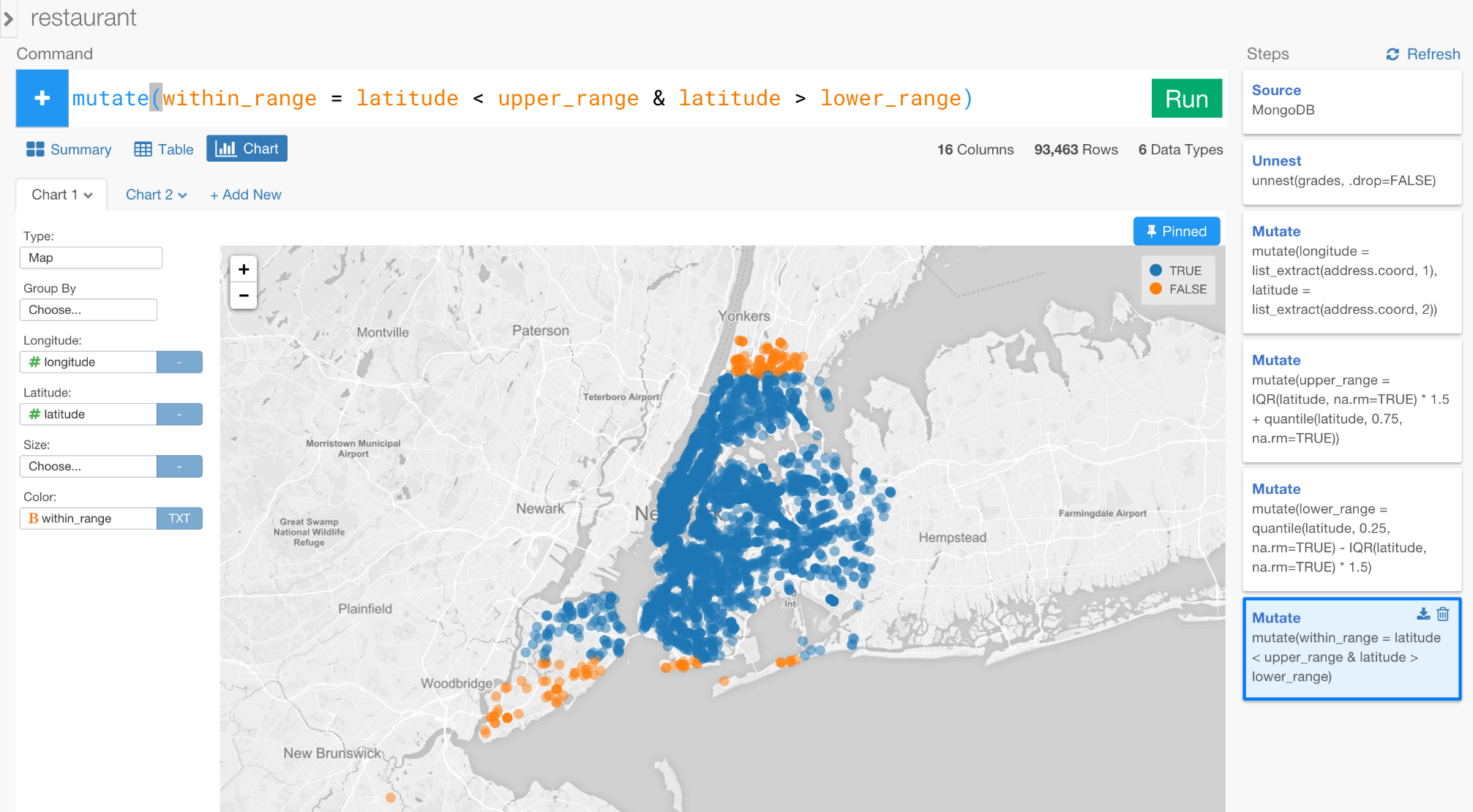
Pinボタンをクリックをすると、あなたがどのステップをクリックしようと、Pinされたステップにチャートを固定することができます。
Pinされた今なら、私たちが、upper rangeとlower rangeを計算したステップに戻って、1.5から3に更新することができます。
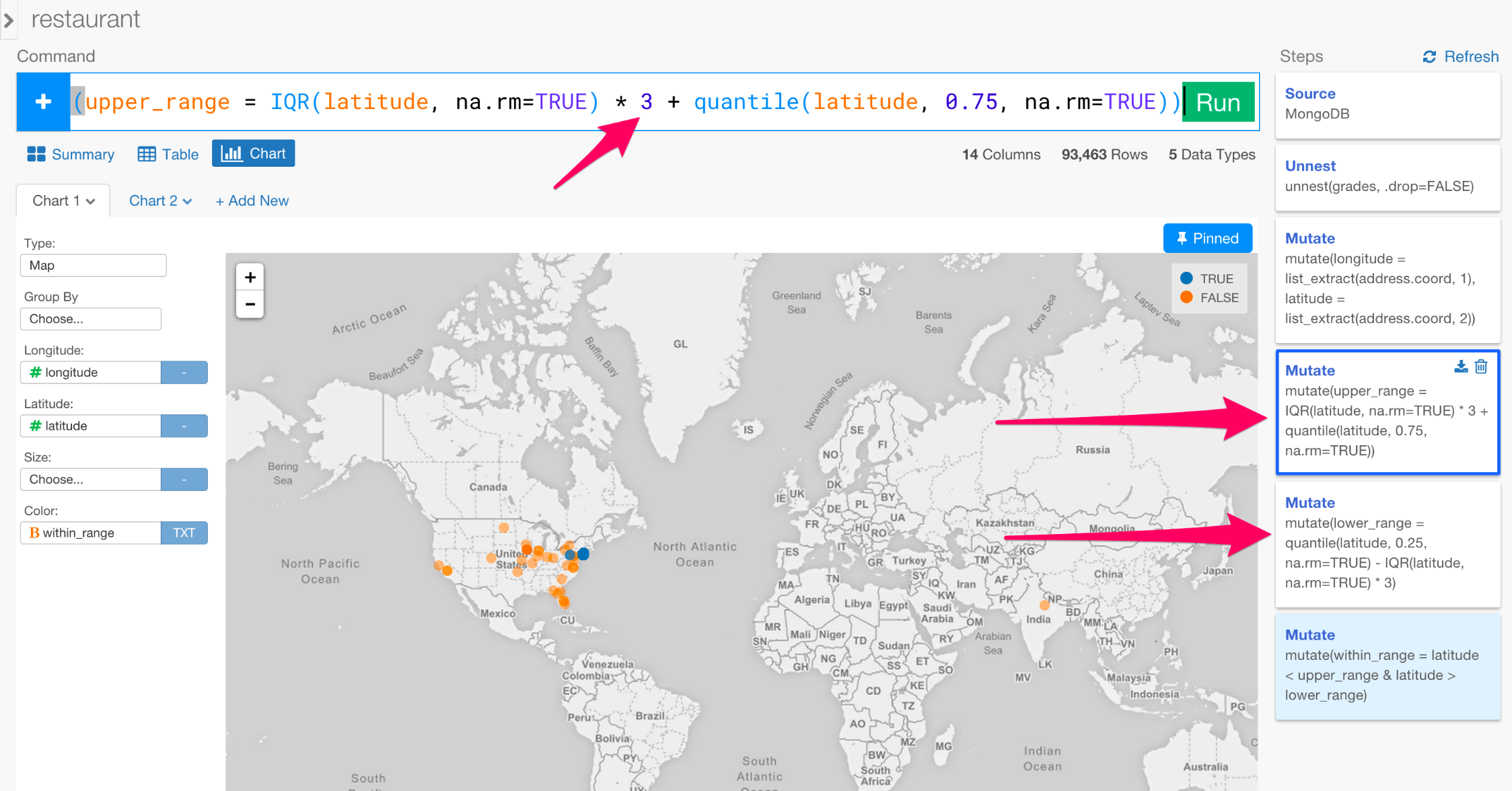
ステップを更新するたびにRunボタンをクリックすることを忘れないで下さい。すると、マップをニューヨークにズームしたとき、このような感じになります。
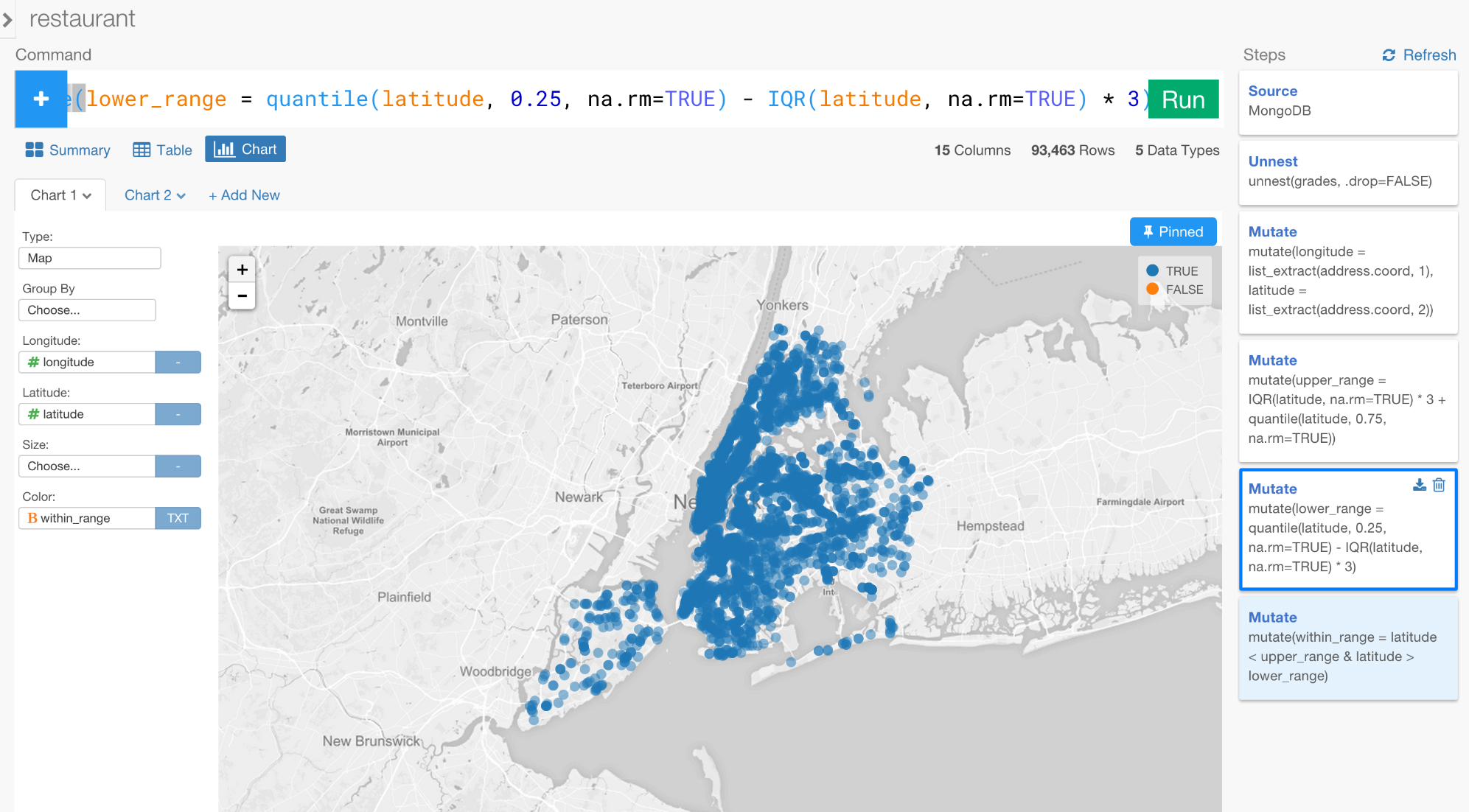
今回は、ニューヨークの中の円がwithin_range列の範囲であることを示す青色になっていますね。
今回は、外れ値の閾値の設定がうまくいっているようですね。外れ値をフィルタリングするために新しいステップをこのように加えてください。
filter(within_range)
Runボタンを押して、Pinボタンを外すと、地図はこのような感じになります。
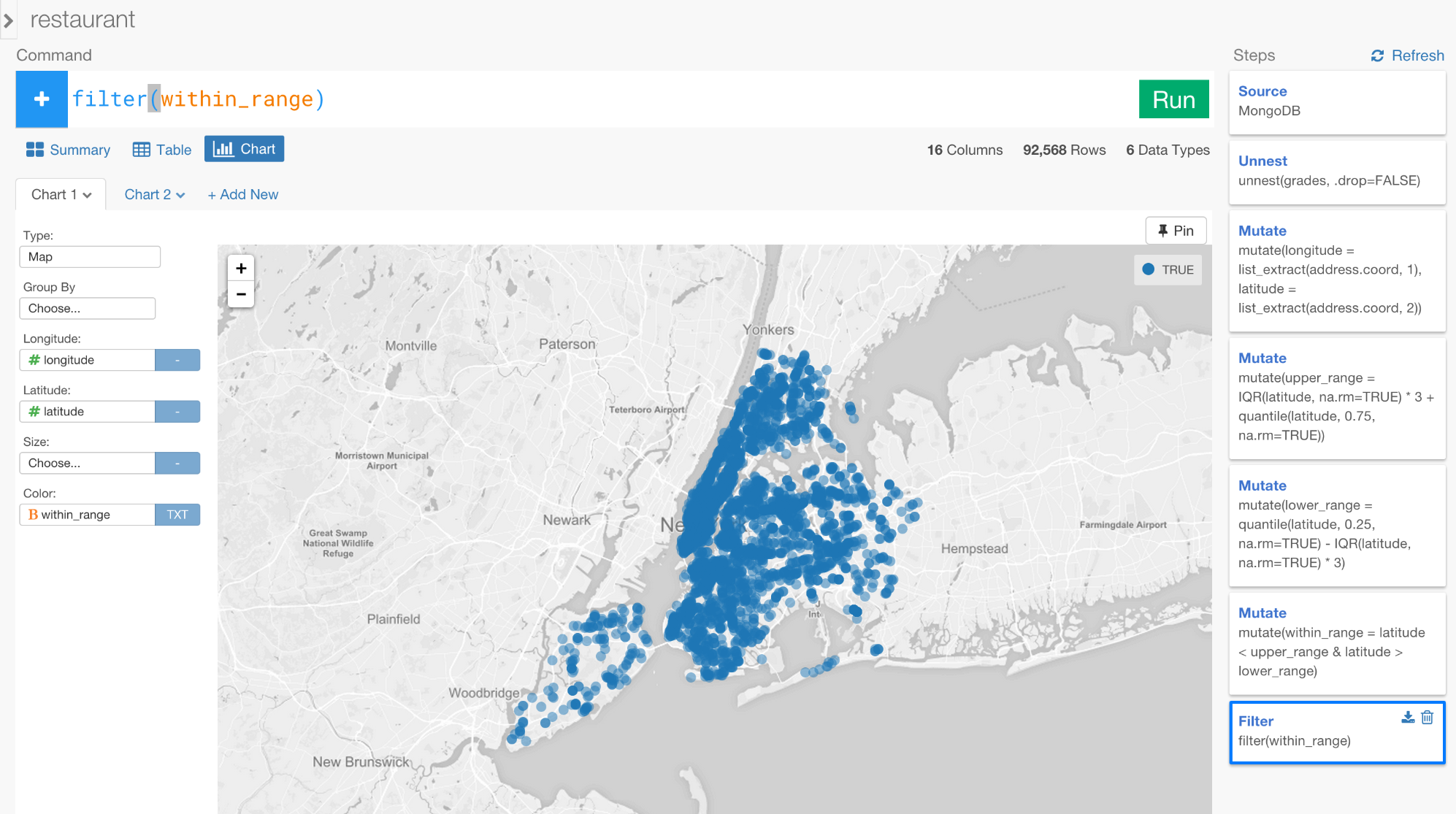
まだ、ニューヨーク以外にもいくつかのデータが残っているかもしれません。また同じことを繰り返すこと、外れ値をもっと取り除くこともできます。
今回は、MongoDBのデータベースを使いましたが、MySQLのデータベースでもほぼ同じようなことができます。
興味を持っていただいた方、実際に触ってみたい方へ
Exploratoryはこちらからβ版の登録ができます。こちらがinviteを完了すると、ダウンロードできるようになります。
チュートリアルはこちらから見ることができます。
Exploratoryの日本ユーザー向けのFacebookグループを作ったのでよろしかったらどうぞ
分析してほしいデータがある方や、データ分析のご依頼はhidetaka.koh@gmail.comまでどうぞ