はじめに
この記事は、Rは知らないけど、SQLとか他のプログラミング言語はある程度やったことあるみたいな人向けです。
興味がなかったり、意味のないデータを取り除きたいと思ったことはありませんか? データをフィルタリングすることは、データ分析をする上での基本的な操作です。dplyrには、filter()関数というのが備わっています。しかし本当にdplyrがすごい理由は、実はデータの加工、分析のための文法なのです。そのため、データを抽出するために元々作られたSQLや他のBIツールと違って、もっと、データを直感的に分析し、さらには分析している最中に必要であればデータの加工もしていくことが簡単にステップを重ねていくようにできます。
dplyrとは
データフレームの操作に特化したRのパッケージです。
Rの一般的な関数に比べて、dplyrはC++で書かれているのでかなり高速に動作します。
SQLと比較するとわかりやすいです。主要なdplyrの機能とSQLの対比は、下図となります。
|dplyr |SQL |説明 |
|:-----------|:------------|:---------------------------------|
|filter |where |行の絞り込み |
|group by |group_by |グルーピングする |
|select |select |データフレームから指定した列のみ抽出する |
|arrange |order by |行を並べ替える |
|summarise |count,max |集計する |
これから、Rのフロントエンドと呼ばれているデータ分析ツールExploratoryを使いながら、dplyrについて簡単に説明していきます。データはこちらからダウンロードできます。
データをインポートする
まず、ここからプロジェクトを作ることができます。
次に、ここからデータをインポートできます。

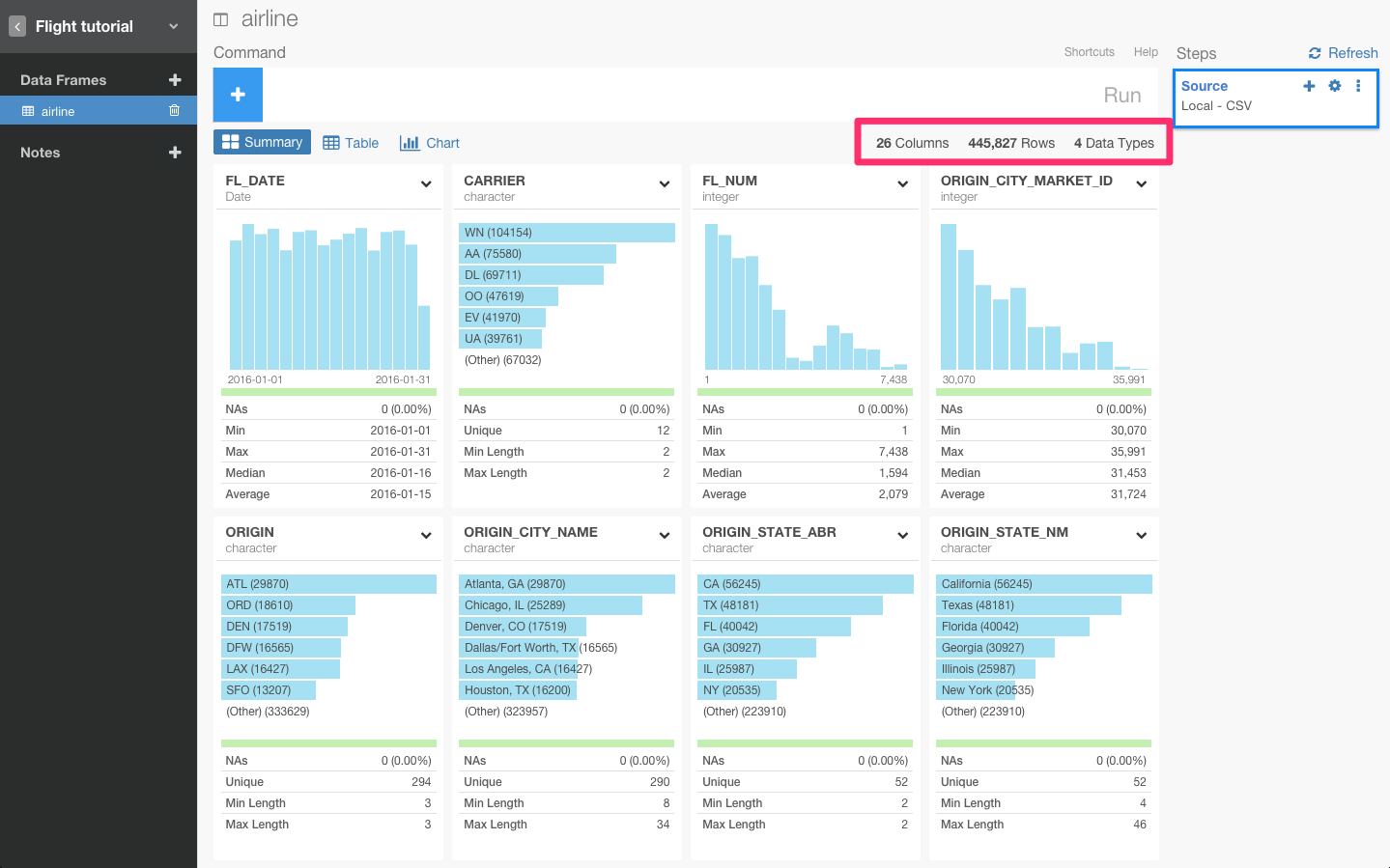
データをインポートすると、データのサマリー画面を見ることができます。
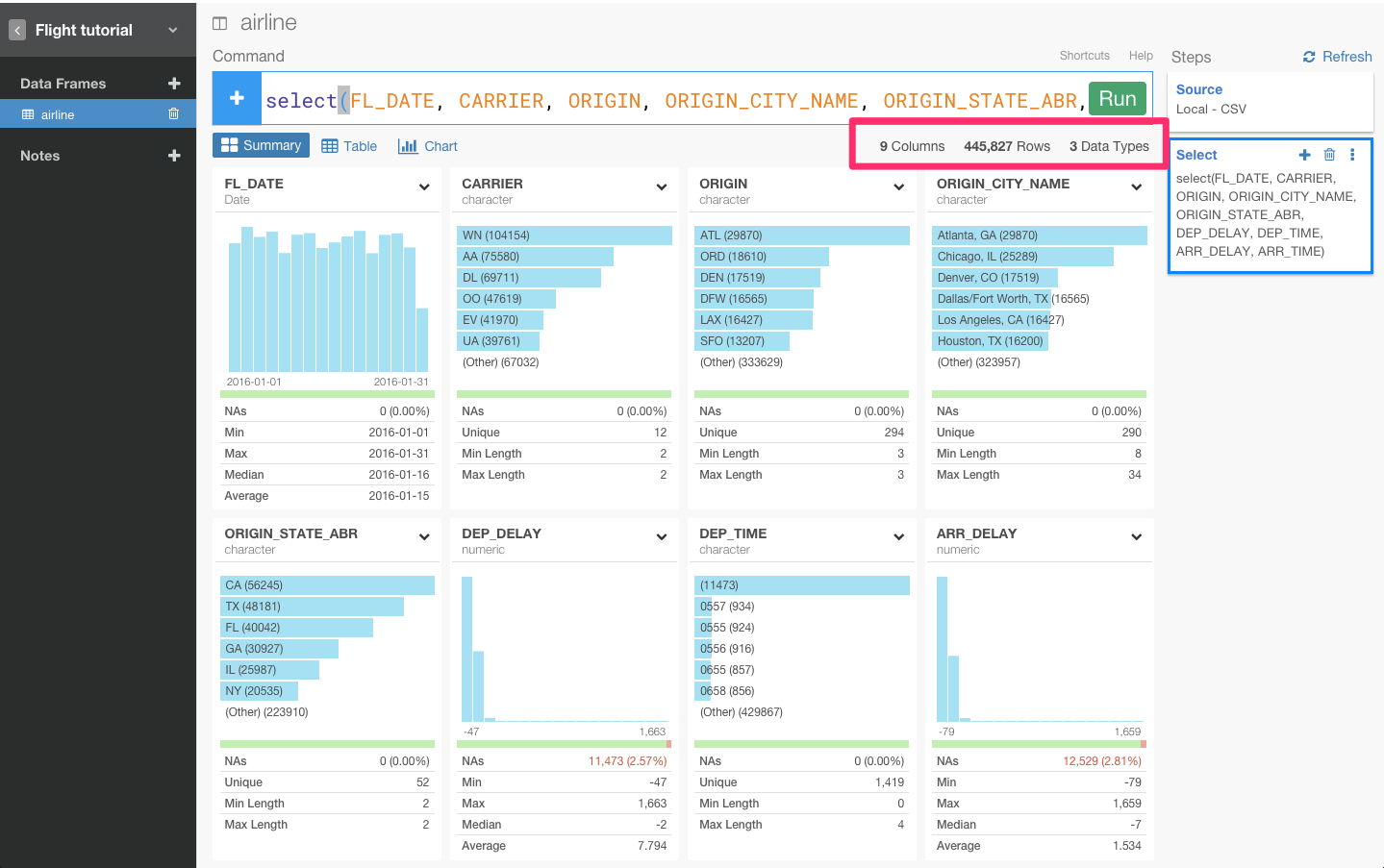
Selectコマンドを使って、列を選択する
Selectコマンドを使うことで、分析したい列だけを選ぶことができます。
知りたいデータだけをフィルタリングする
例えば、United Airline (UA)会社のフライトのデータだけを見てみましょう。
列のヘッダーをクリックしてfilterコマンドを選びます。
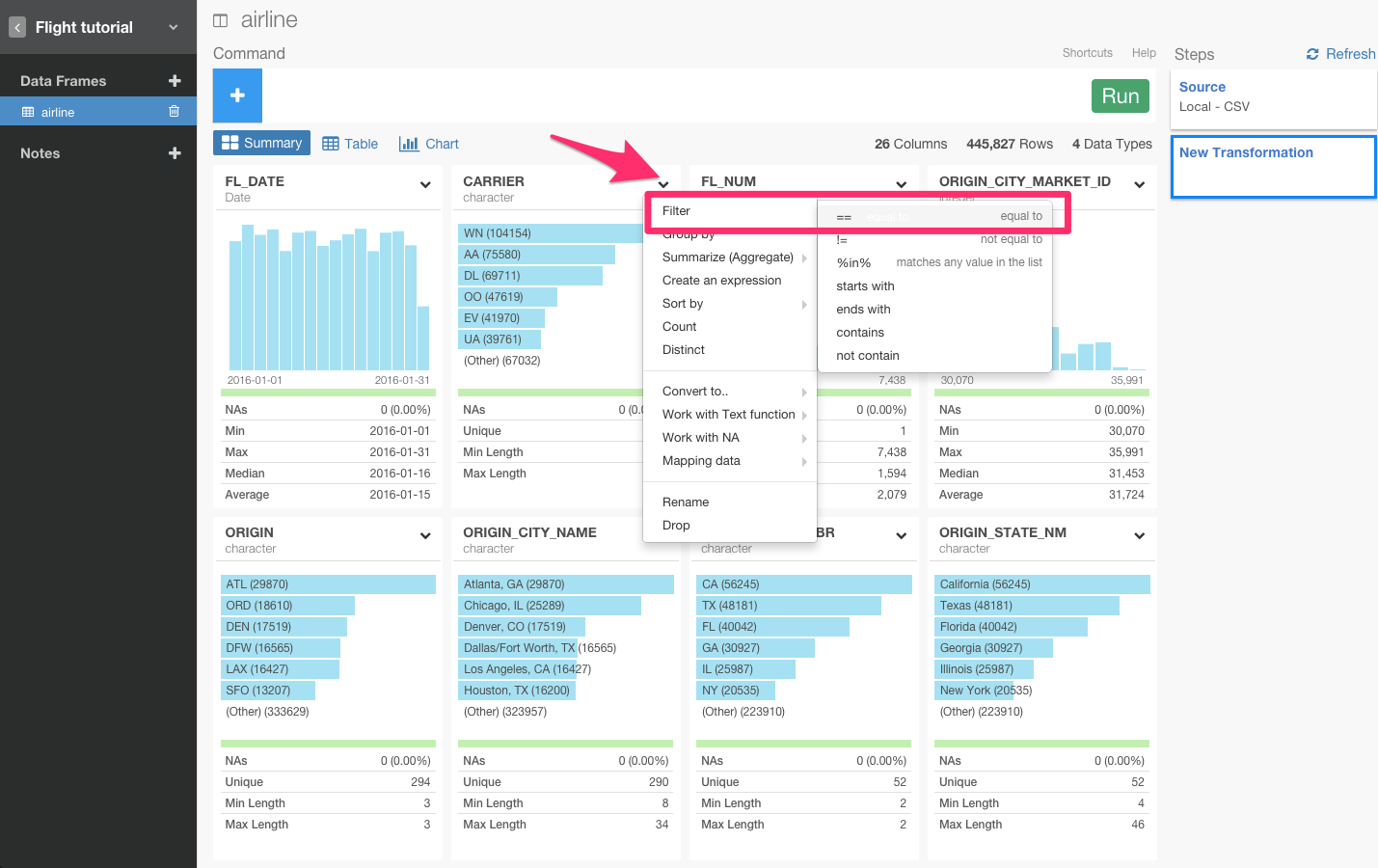
すると、自動的にfilter(CARRIER == )が入力されます。次に、レコメンドされている候補からUAを選びます。
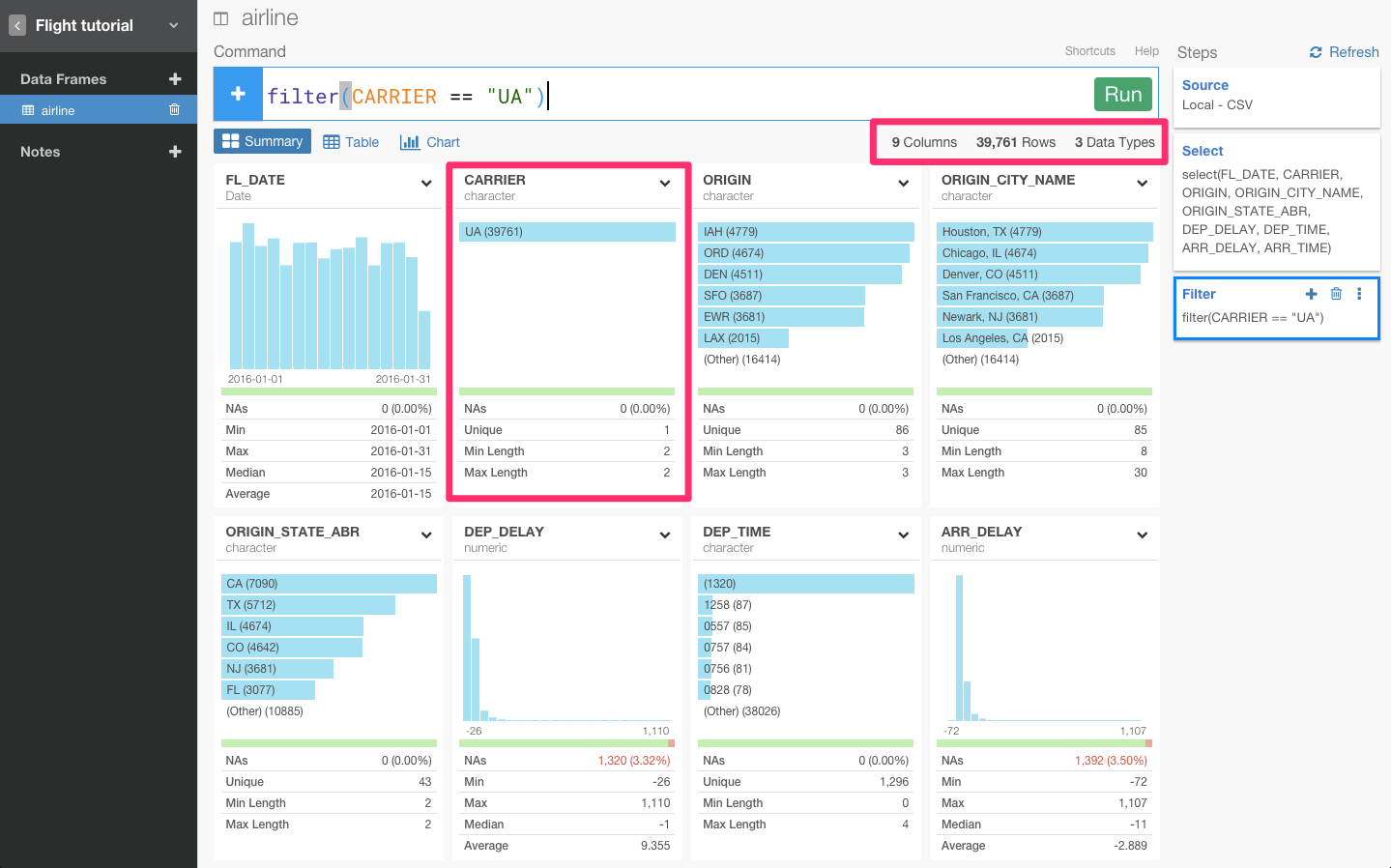
また、andを意味する&演算子を使うと、条件を加えることができます。&を使って、United Airline (UA)会社のフライトに加え、出発地点がSan Francisco airport (SFO)のフライトのデータも見てみましょう。
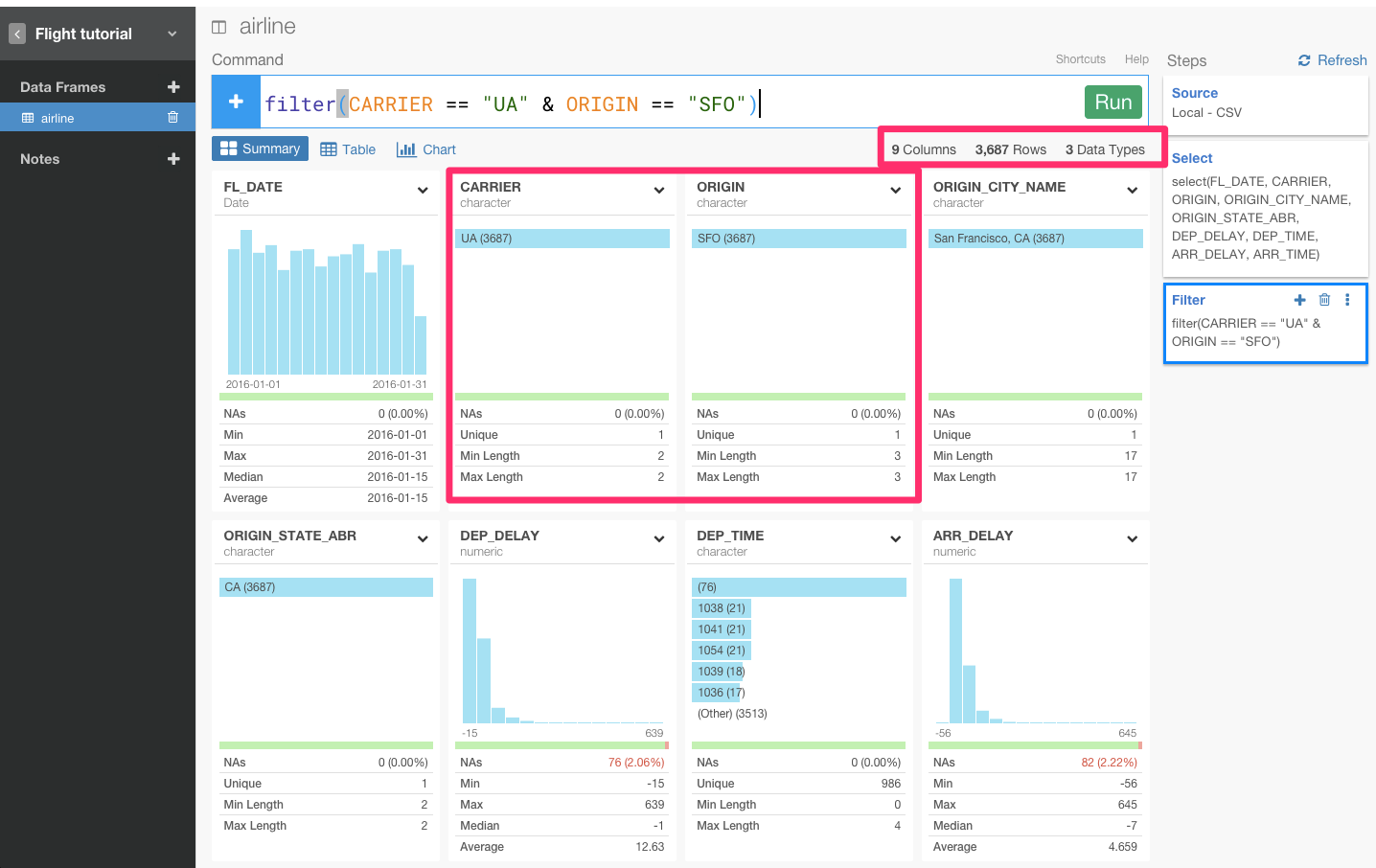
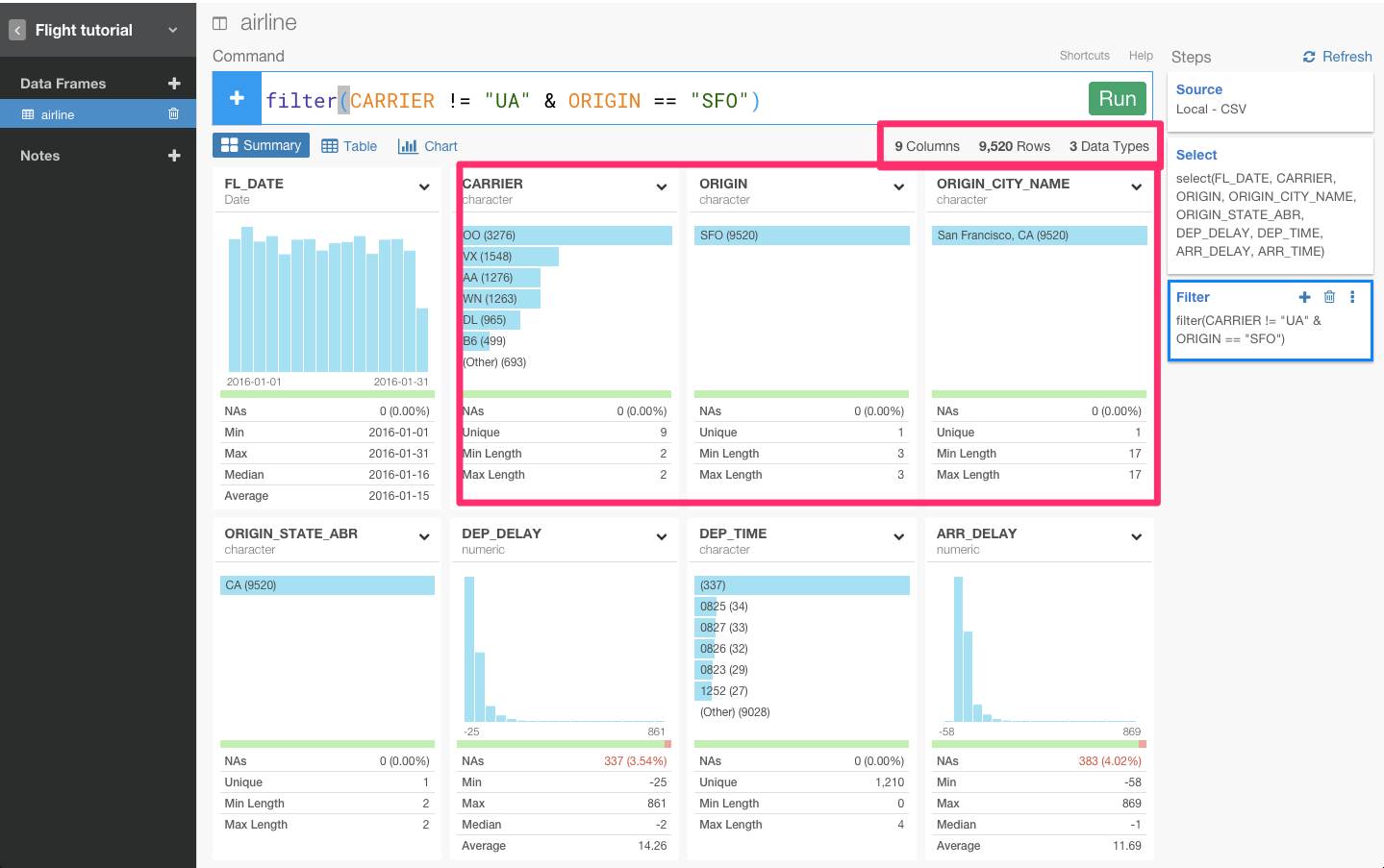
もしくは、!=演算子を使って、条件を反対にすることもできます。!=を使って、出発地点は、San Francisco airport (SFO)のままだけれど、United Airline (UA)会社ではないフライトのデータを見ることもできます。
複数の値をフィルタリングする
United Airline (UA)とAmerican Airline (AA)の両方のフライトのデータだけを見たい場合は、SQLにおけるINにあたる%in%を使うと見ることができます。
列のヘッダーをクリックしてfilterコマンドを選びます。
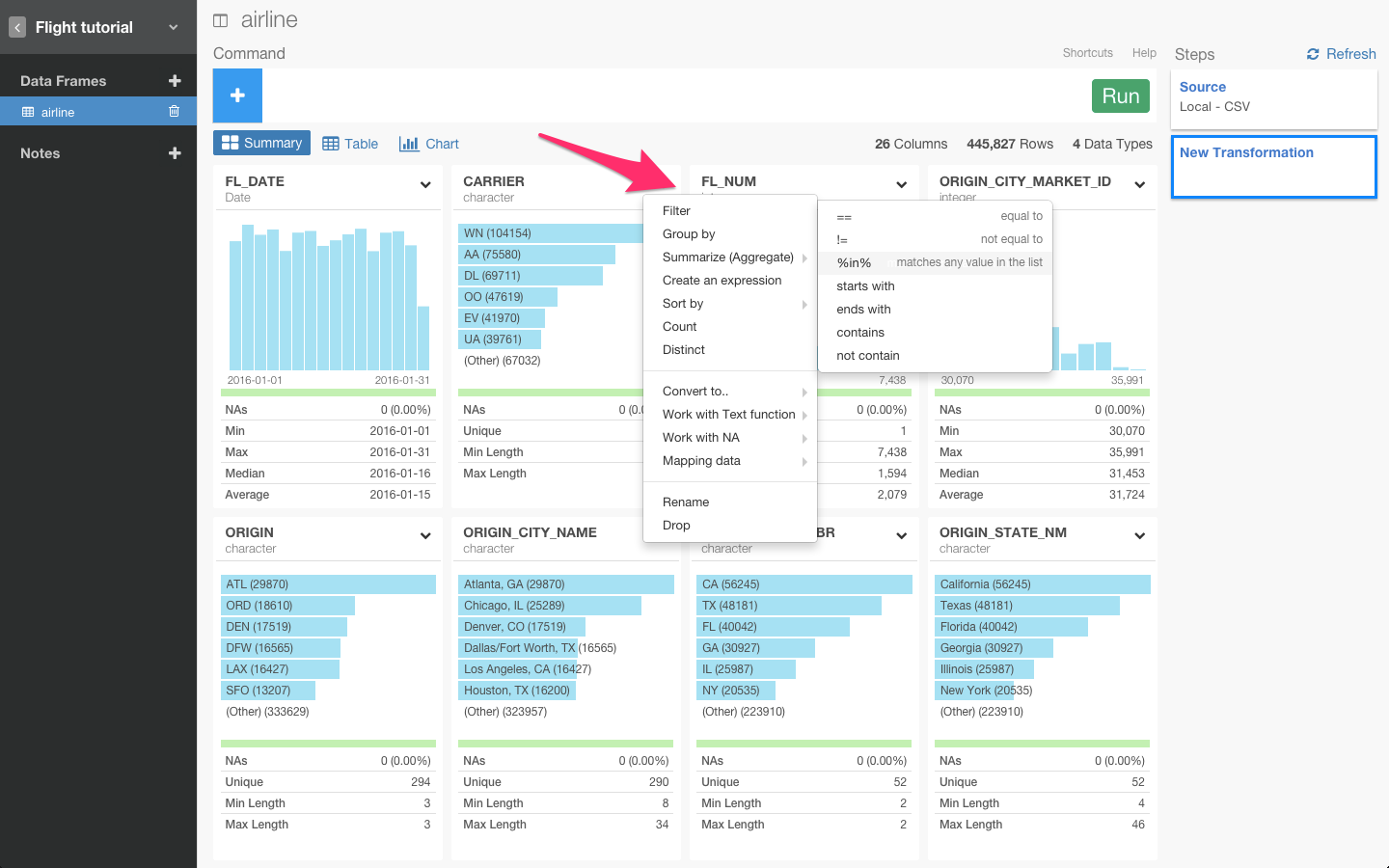
すると、自動的にfilter(CARRIER %in% c())が入力されます。次に、レコメンドされている候補からUAとAAを選びます。
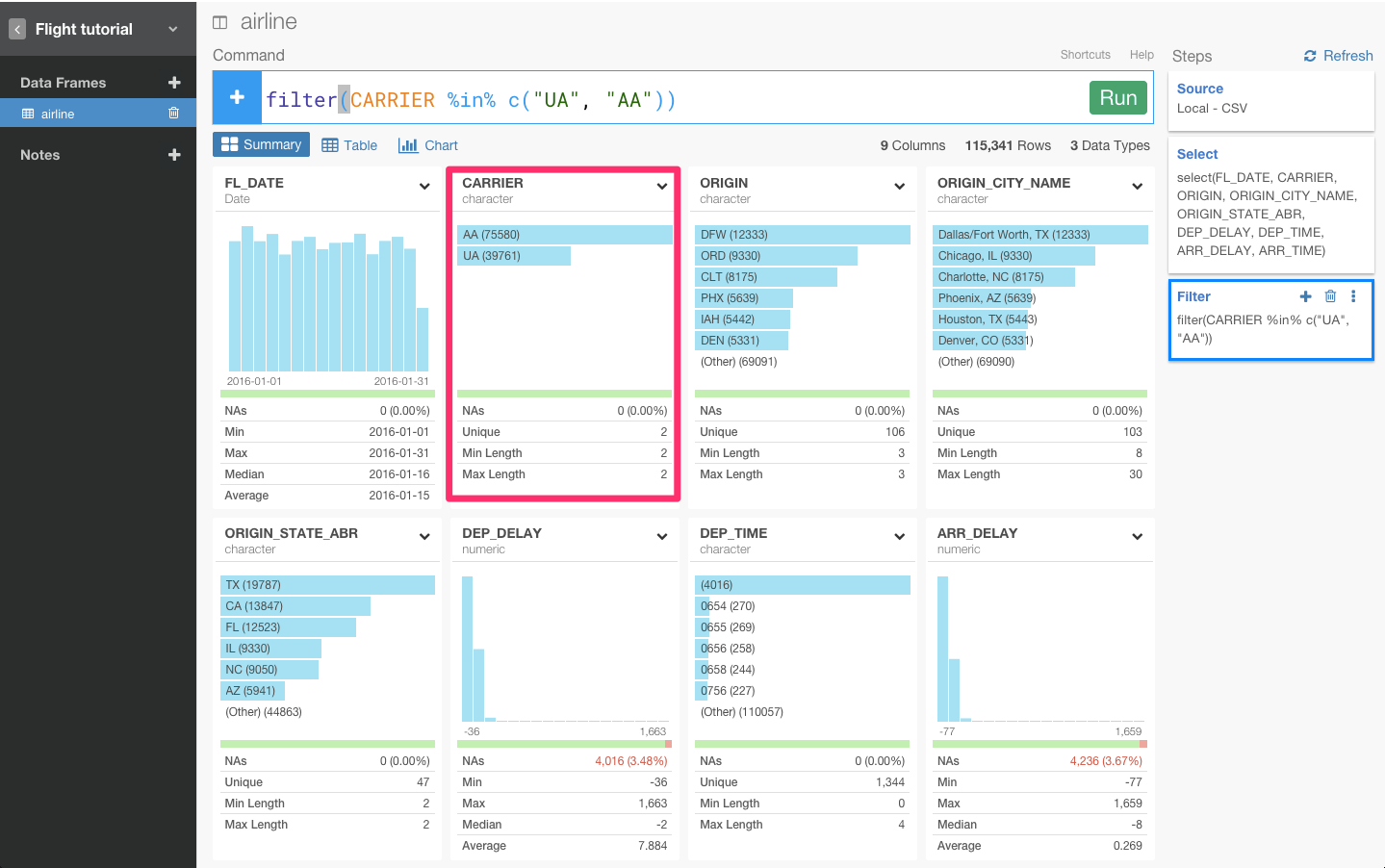
本当にうまくいってるのかを確認するために、count()関数を使って、簡単にデータを集計してみましょう。
列のヘッダーをクリックしてcountを選びます。
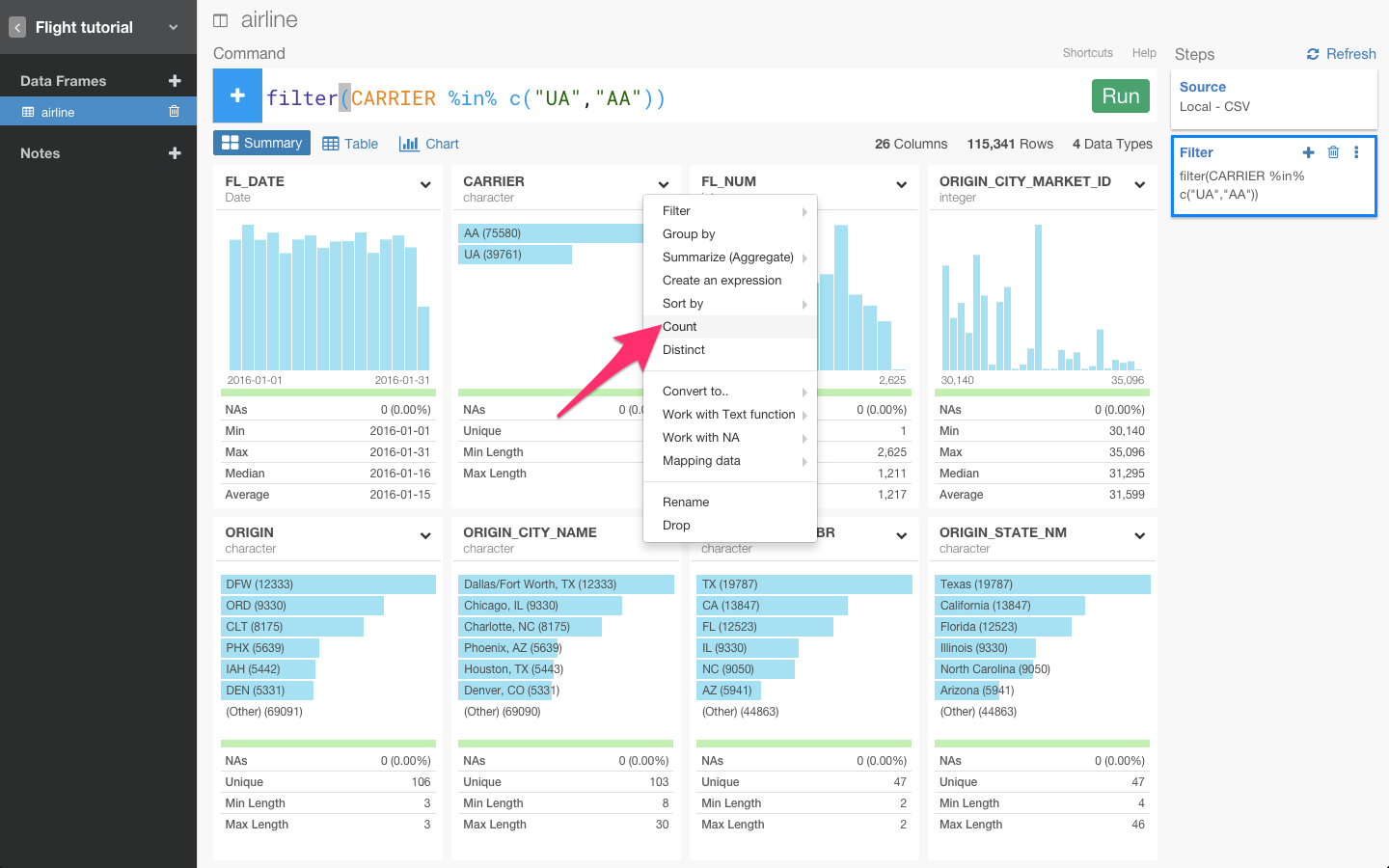
すると、自動的にcount(CARRIER)が入力されます。
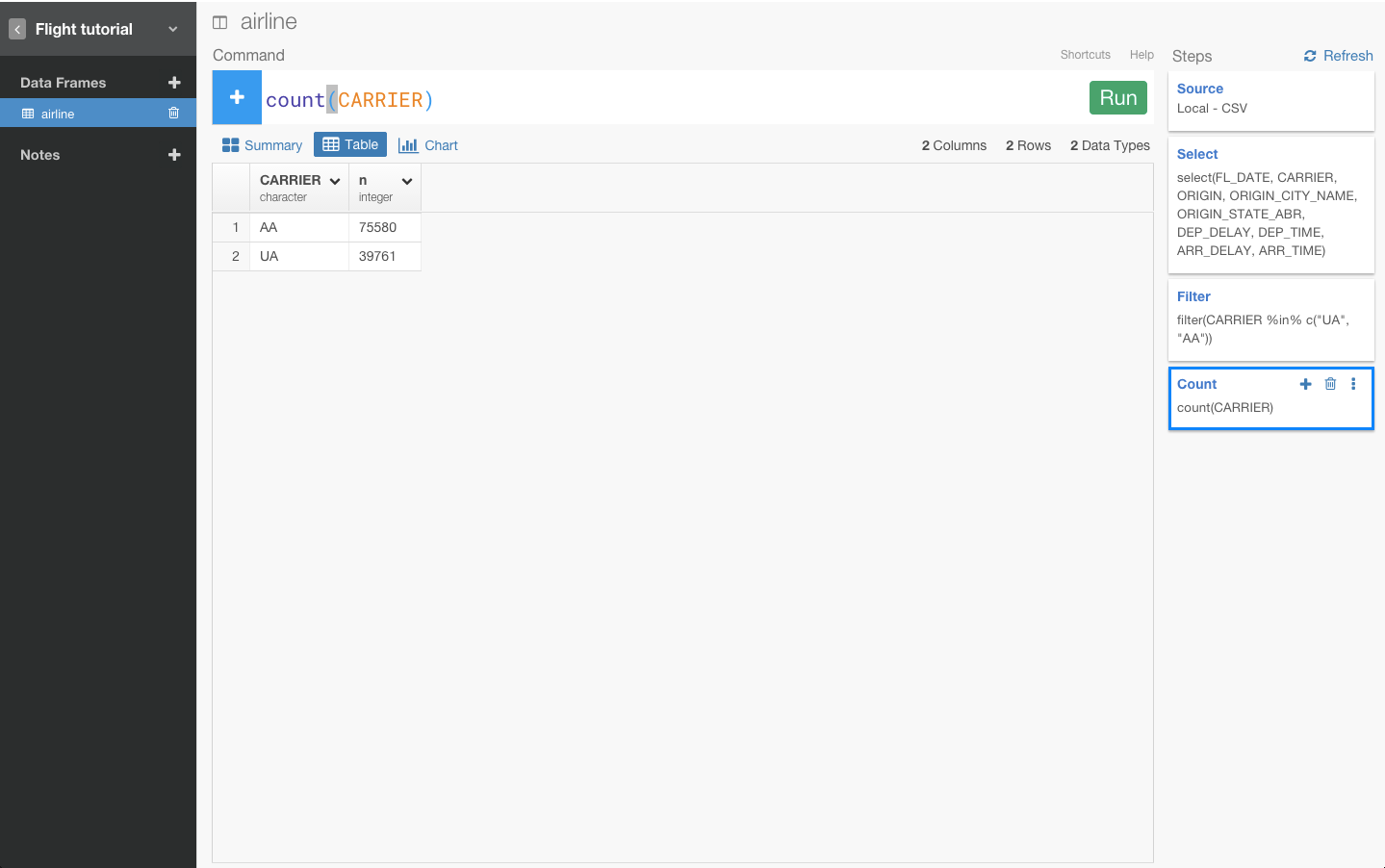
思ったとおり、AAとUAだけでしたね。ご覧のとおりcount関数は、とても直感的で便利です。この関数は、指定したグループの行の数を返します。この場合なら、CARRIERですね。
NA値をフィルタリングする
データを見ていくと、ARR_DELAY列にいくつかNA値があることが確認できますね。
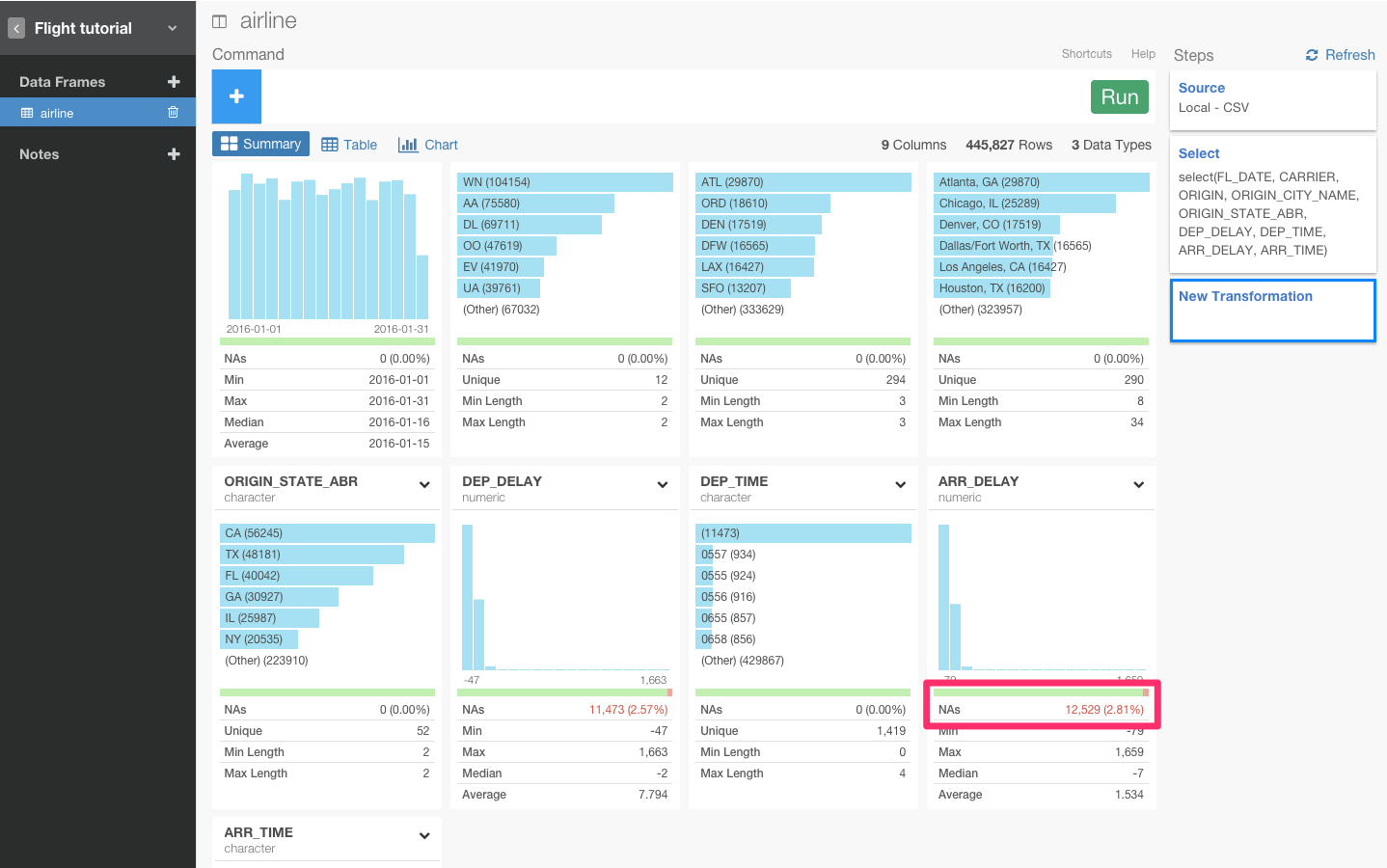
値が、NA値だったら、TRUEを返して、そうでなければFALSEを返すis.na()関数を使うと、それらを簡単に取り除くことができます。
列のヘッダーをクリックしてWorking with NAからDrop NAを選びます。
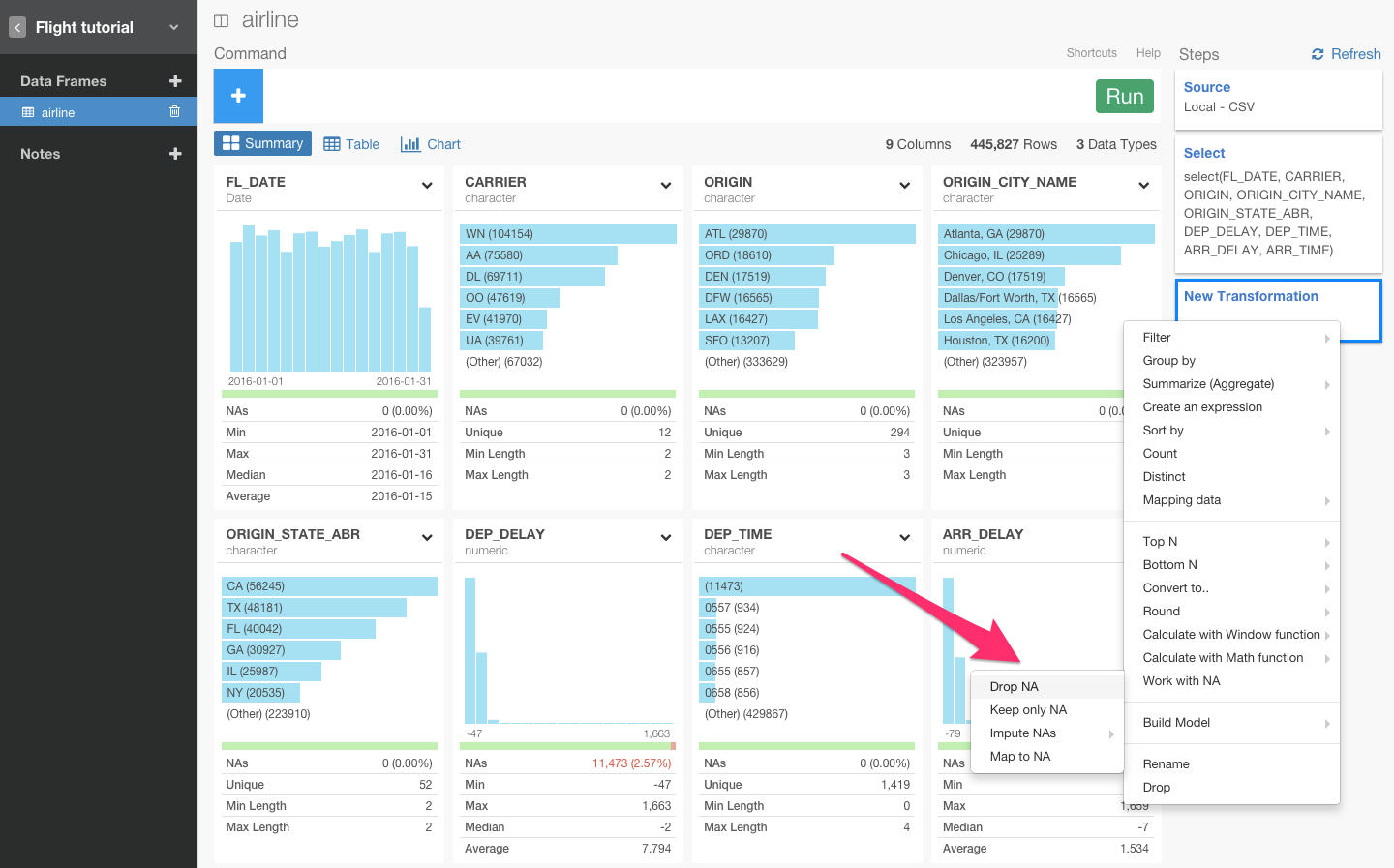
すると、自動的にfilter(!is.na(ARR_DELAY))が入力されます。
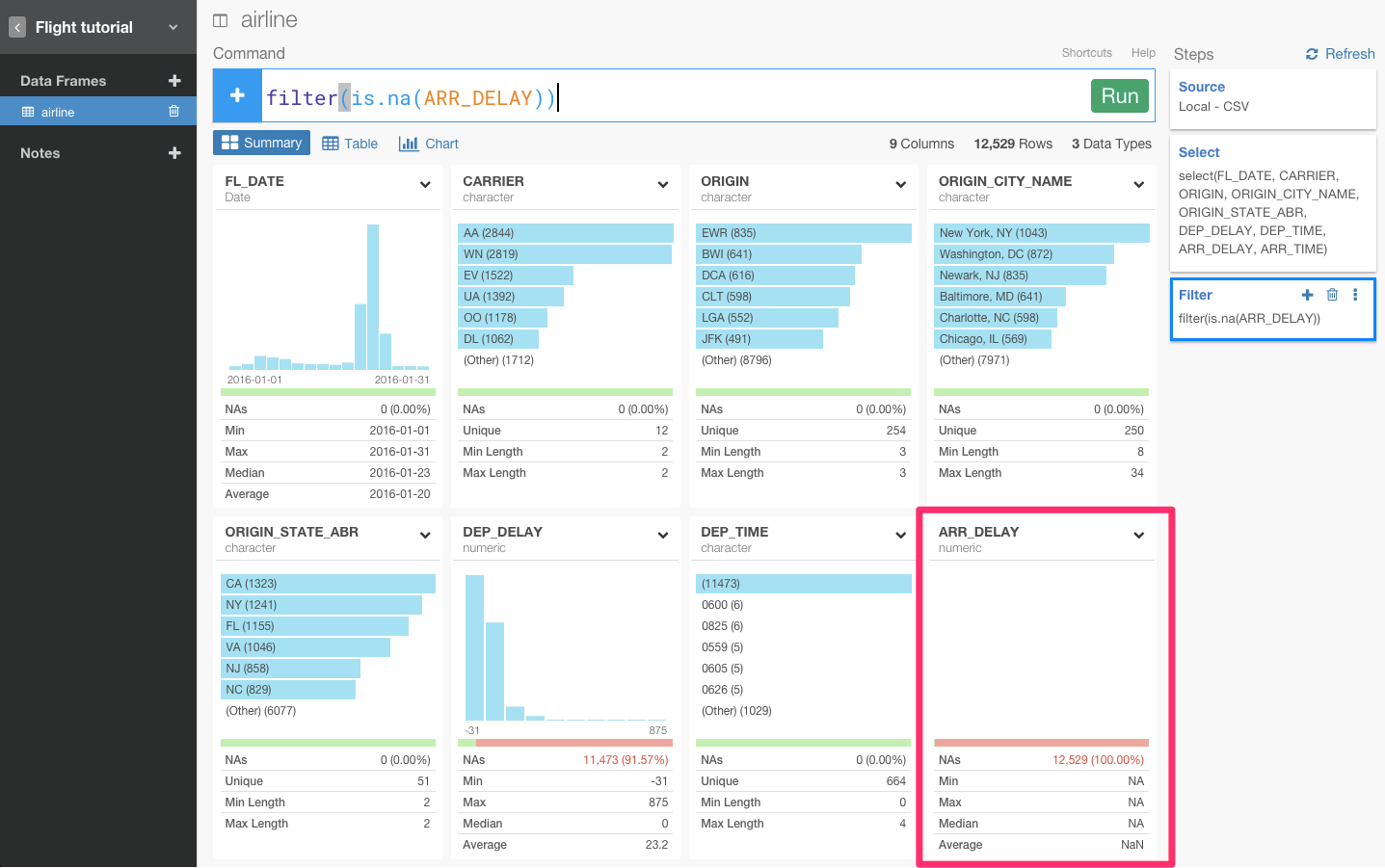
おっと、ARR_DELAYの値がすべてNA値になってしまいましたね。ぼくたちが知りたいデータは全く逆のことなので、条件文に!を足しましょう。
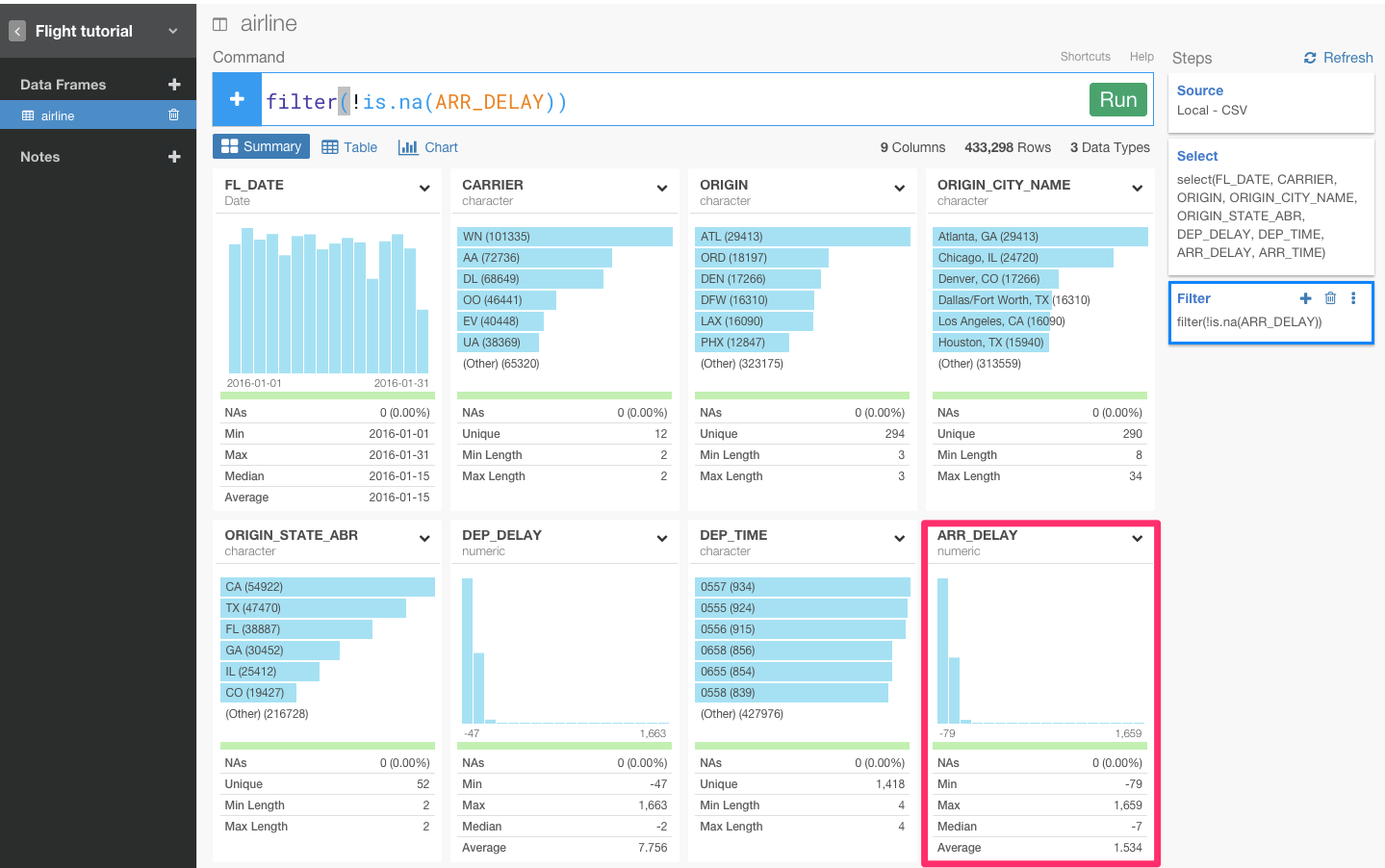
以上が、dplyrでの基本的なフィルタリングに関する操作です。dplyrでは、他にもデータを集計したり、window関数を使ったり、文字列を整形したり、date関数を使ったり、まだまだいろんなことができます。そちらの方はこれから書いていく予定ですので、お楽しみに!
興味を持っていただいた方、実際に触ってみたい方へ
Exploratoryはこちらからβ版の登録ができます。こちらがinviteを完了すると、ダウンロードできるようになります。
Exploratoryの日本ユーザー向けのFacebookグループを作ったのでよろしかったらどうぞ
ExploratoryのTwitterアカウントは、こちらです。
分析してほしいデータがある方や、データ分析のご依頼はhidetaka.koh@gmail.comまでどうぞ