はじめに
フューチャー Advent Calendar 2022の11日目の記事です。
2022年4月にフューチャーに入社し、現在は物流系のPJでシステム設計を行っている、新人エンジニアです。
仕事を行う中で、Excelファイルを大量に扱うときってたまにありますよね。
Excelファイル単体に目を向けると、数式で使用できるExcel関数やVBAを利用してマクロを組むことで割と色々なことができます。
しかし、大量のExcelファイルに対して、一括して処理を行ったり特定のキーワードを検索したりとなるとちょっと面倒だなってなります。
実際の業務でそのようなシーンがあり、その時にPythonを使ってそのタスクをこなしていきました。
特にPythonを使用した理由はありませんが、ちょっとした処理を書く際にはとても便利です。
PythonでExcelを扱うライブラリは複数ありますが、それらを上手く利用してタスクを進める必要がありました。
複数のライブラリを扱うなかで、それぞれの特徴を感じる時があったので、本記事を執筆しています。
今回はExcelの各セルの値を抽出するという処理に注目して、各ライブラリの比較を行っていきたいと思います。
対象ライブラリ
以下の5つのライブラリの比較を行いました。
| 説明 | |
|---|---|
| OpenPyXL |
Python Excelで検索して一番最初に辿り着くライブラリだと思います。Excelファイルを直接編集するため、LinuxなどOfficeが入っていない環境でも動かせます。文献も多いので扱いやすいです。 |
| xlwings |
OpenPyXLと比較されがちなライブラリです。実際にExcelを起動してプロセス間通信でデータを扱うライブラリなので、Excelでできることはほぼ出来ます。しかしExcelを開くためオープン/クローズに時間がかかります。 |
| pylightxl | 2020年にリリースされた新しめなライブラリです。こちらは名前にもある通り軽量なことが売りみたいです。またOpenPyXLやxlwingsは外部のライブラリが必要ですが、こちらは単体でも動作できるような設計らしいです。 |
| Pandas | pandasのread_excelというメソッドを使用してexcelファイルを読み込む方法です。読み込まれたデータはDataFrameとして扱えるので、データ分析に特化しています 。(読み込みなどは中でopenpyxlが動いている) |
|
lxml (XMLファイルが 読み込めるライブラリ) |
XMLファイルを扱うライブラリで、これだけちょっと毛色が違います。Excelファイルの中身を見ると実はxml形式でデータが記載されています。そこでそのXMLファイルを直接読み込んじゃおうという作戦です。標準ライブラリにもxmlを読み込めるライブラリがありますがlxmlの方が扱いやすいのでこちらを使用しています。 |
結論
- 単純に値の抽出だけを行いたい場合はExcelファイルをXMLデータとして扱って処理する(今回で言う
lxmlを使用する方法)が一番早いです。 -
Pandasを利用してDataframeに落とし込むことで高速にデータ抽出ができます。後々データ処理などを行いたい場合はこちらを利用すると良いかもです。 -
OpenPyXLとxlwingsではOpenPyXLが基本的に早く処理できます。しかしファイルサイズが大きくなるとファイル読み込みのオーバーヘッドが短くなりxlwingsの方が高速に動作します。 -
pylightxlはライブラリが軽量な分、処理は少し重たいです。
※今回はデータの抽出に注目していますが、Excelを読み込んで何らかの処理(書式の変更/セル間の結合など)を行って書き戻すといったことを行おうとするとlxmlやPandasでは難しいと思います。その時はOpenPyXLやxlwingsを使ってExcelライクに処理した方が良いと考えます。
調査
方法
- ランダムな値が記載されたExcelファイルを用意します。今回はファイル1(サイズ:0.05MB, データ数:100行x100列) とファイル2(サイズ:5MB,データ数:1000行1000列) の2つのファイルを用意しました。
- それぞれのライブラリで、ファイルを読み込んで全データを探索するプログラムを作成し、実行時間を比較しました(
DataFrameでは数値や文字列を高速に検索できたりしますが今回はあえてforでぶん回しています)。
| 容量 [MB] | データ数[個] | |
|---|---|---|
| ファイル1 (test_file_1.xlsx) | 0.05 | 1,0000 |
| ファイル2 (test_file_2.xlsx) | 5 | 1,000,000 |
↓検証に使用したExcelファイルの例
コード
全容はGitHubにアップロードしたので、ここでは各ライブラリ用の調査関数について軽く説明します。
OpenPyXL
def read_test_openpyxl():
wb = openpyxl.load_workbook(test_file_name)
sheet = wb[test_sheet_name]
tmp_list = []
for col in sheet.iter_cols():
for raw_value in col:
tmp_list.append(raw_value.value)
wb.close()
iter_cols()を使用して、列ごとに処理しています。
この関数を使用することで列ごとにPythonのジェネレーターを返してくれるので、セル1つ1つにアクセスするよりも高速に動きます。
xlwings
def read_test_xlwings():
xlwings.App(visible=False)
wb = xlwings.Book(test_file_name)
sheet = wb.sheets[test_sheet_name]
rng = sheet.used_range
tmp_list = []
for c in rng.columns:
for v in c.value:
tmp_list.append(v)
wb.close()
xlwingsでも同様に使用されている列をすべて抽出し、そこから値を取り出します。
もっと早そうな方法がありそうな気がしますが、いくつか比較した中で一番早かったロジックです。
2023/02/08追記
コメントにて、@k_maki さんより、xlwingsを使用した高速な読み込み方法を記載頂いております。
pylightxl
def read_test_pylightxl():
db = pylightxl.readxl(fn=test_file_name)
tmp_list = []
for col in db.ws(ws=test_sheet_name).cols:
for v in col:
tmp_list.append(v)
pylightxlでも同様に使用されている列をすべて抽出し、そこから値を取り出します。
pandas
def read_test_pandas():
df = pd.read_excel(test_file_name, header=None, index_col=None)
itr = np.nditer(df.values)
tmp_list = []
for v in itr:
tmp_list.append(v)
pandasではread_excel()を使用して、DataFrameに変換します(ちなみに読み込む際にOpenPyXLを使用しています)。
DataFrameのままで各要素にアクセスするととんでもなく遅いので一度numpyのndarrayに変換し、そこから全要素を抽出します。
このあたりはデータによってはpandasのメソッド等を使用することで高速化できるとは思います。
(DataFrameに落とした段階でデータの読み込みは終わっているのでは?とちょっと思いましたが、他関数と合わせて各セルのデータにアクセスするという意味も込めてforで回して抽出しています。)
lxml
def read_test_xml():
with zipfile.ZipFile(test_file_name, 'r') as zip_data:
file_data = zip_data.read('xl/worksheets/sheet1.xml')
root = etree.XML(file_data)
tmp_list = []
for v in root.findall('./{*}sheetData/{*}row/{*}c/{*}v'):
tmp_list.append(v.text)
最後にExcelファイルをXMLとして読み込む方法です。
.xlsxはzipで圧縮されているのでまずそちらを読み込んからlxmlで解析しています。
ExcelのXMLの中身についてはこちらのサイトを参考にしました。
そして読み込んで各要素にアクセスしています。
XPathに指定している{*}は名前空間にワイルドカードを使用しています(参考)。
結果
各調査関数を100回実行して、その実行時間の平均値を求めました。
以下結果です。
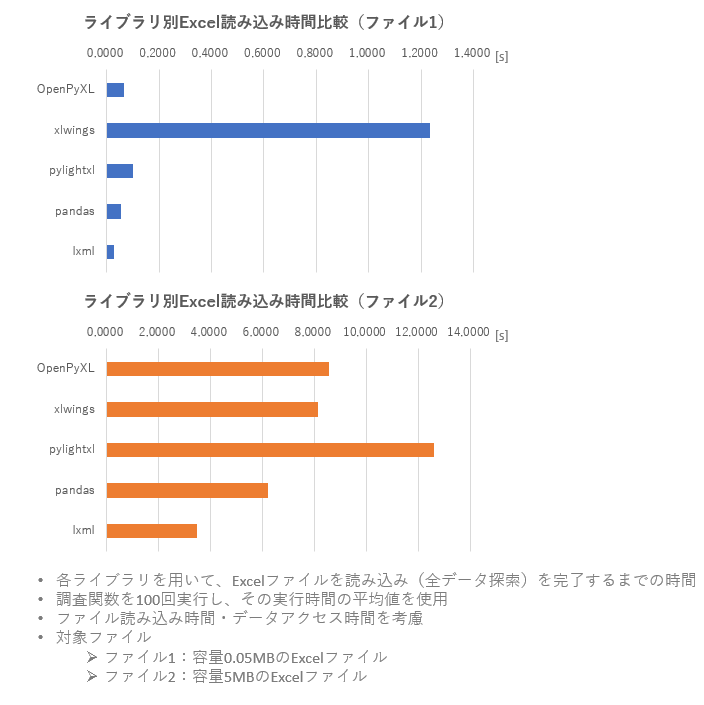
| ライブラリ | ファイル1(0.05MB)[s] | ファイル2(5MB)[s] |
|---|---|---|
| OpenPyXL | 0.065 | 8.550 |
| xlwings | 1.232 | 8.139 |
| pylightxl | 0.101 | 12.651 |
| pandas | 0.053 | 6.219 |
| lxml | 0.027 | 3.485 |
図にすると下のような感じになりました。
それでは簡単にまとめていきます。
ExcelファイルをXMLとして扱うことで高速にデータアクセスが可能。検索するだけならコレ
予想はしていましたが図を見て分かるように、ExcelファイルをXMLとして読み込む方法(lxmlを使用した方法)が、ファイル1・ファイル2の両方で一番早いです。
ExceファイルをExcelファイルとして扱わないことで高速になったと思います。
調査関数を見てもらうと、zipファイルを読み込むところ処理に入っていますがそこを考慮してもこのように高速です。
値の検索や単純な置換を行うだけなら、この方法で良いですかね。
問題点を挙げるとすると、Excelらしい処理が出来ないことです。
もしかしたら図形や数式など、複雑な処理もXMLファイルを解析することで可能になるかもしれませんが、そこまでするなら大人しくOpenPyXLやxlwingsを使った方が良いと思います(高速化にこだわるならアレですが)。
Pandasも高速に動作。しかしデータ処理を行いたい場合向け
lxmlの次点で高速でした。Pandasを使用するメリットとして、読み込んだデータをPandasのDataFrameとして扱えるところが挙げられるます(というかこれしかない…)
DataFrameは統計的な処理だったり、データとしての扱いが簡易に行えるので、そのような目的でExcelファイルを読み込みたい場合などにはとても良いです。
しかし、Excelファイルとして扱いたい場合には不向きです。
一応Excelファイルの出力にも対応していますが、複雑なことはできなさそうです。
OpenPyXLとxlwingsでは軽量ファイルはOpenPyXLが圧倒的に早い。しかしファイルサイズが大きくなるとxlwingsの方が高速に
OpenPyXLとxlwingsはPythonでExcelファイルを扱う代表的なライブラリです。
この2つのライブラリを使用することが多いと思いますが、こちらを比較した際に、ファイルサイズが小さい場合は圧倒的にOpenPyXLが早く、ファイルサイズが大きくなるとxlwingsが逆転するといった結果になりました。
これはファイル読み込みのオーバーヘッドが原因だと考えます。
上でも記載しましたがxlwingsは実際にファイルをExcelで開いて、Excel上で処理を行うため、ファイルのオープンに時間がかかっているようです。
しかし、一度開いてしまえばExcel上で高速に値を探索できるようで、今回のような結果となりました。
速度だけ見るとlxmlを使用した方が倍以上高速ですが、数式や図形を扱ったりなどはlxmlでは難しいです。
そのため、用途に応じてOpenPyXLやxlwingsの使用も選択肢の1つとなります。
むしろPythonでExcelを扱いたい場合ってlxmlでは出来ないことのほうが多いんじゃ...
pylightxlはそこまで早くないが、導入コストが少なく簡単に動かせるところに強み
このライブラリは初めて使用しましたが、高速な検索・Excelファイルとしての操作などには向かないっぽいです。
使い勝手もそこまでOpenPyXLやxlwingsと変わらないので、特に何も無ければ使わなそうです。
こちらのライブラリのメリットはあくまでも軽量とのことなので、場合によっては使う機会も出てくるかもです。
まとめ
仕事の中で扱うことが多いExcelファイルについて、Pythonから高速に値を抽出する方法を比較・調査しました。
予想はしていましたが、Excelファイルとして扱わず、XMLと扱うことで高速に動作することがわかりました。
しかし単純にXMLで読み込めば良い、というわけでなく、ユースケースに応じて適切なライブラリを選択することが重要だと思います。
今回の記事がその選択の助けになればと考えています。
また、特にOpenPyXLとxlwingsですが、今回記載したロジック以外にも値にアクセスする方法がありそうなので、「もっとこうすれば早くなるかも!」などありましたらコメントいただけますと幸いです。
参考URL