本記事は Python Advent Calendar 2024 シリーズ2 における11日目の記事になります.
はじめに
MNISTデータセットでMLPの学習をしていたところ,GPU使用率が全然上がっていないことに気づきました.ボトルネックと思われるものを発見したので共有します.
環境
- Ryzen 5 5600X
- RTX 3060Ti
- Python 3.12.7
- torch 2.5.1+cu118
- CUDA 11.8
- cuDNN 8.7.0
状況の確認
とりあえず以下の典型的なプログラムで実行時間を確認します.
main.py
import torch
import torch.nn as nn
from torch.optim import Adam
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.nn.functional import relu
# ハイパーパラメータの設定
batch_size = 4096
learning_rate = 0.01
num_epochs = 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# データの前処理とデータローダーの作成
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root='./downloads', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./downloads', train=False, transform=transform, download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
# 3層のMLPモデルを定義
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.lin1 = nn.Linear(28*28, 256) # 入力層から中間層(256ユニット)
self.lin2 = nn.Linear(256, 128) # 中間層からもう一つの中間層(128ユニット)
self.lin3 = nn.Linear(128, 10) # 出力層(10クラス)
def forward(self, x):
x = x.view(-1, 28*28) # 2次元画像を1次元ベクトルに変換
x = self.lin1(x)
x = relu(x)
x = self.lin2(x)
x = relu(x)
x = self.lin3(x)
return x
model = MLP().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=learning_rate)
# モデルのトレーニング
for epoch in range(num_epochs):
model.train()
for data, target in train_loader:
data = data.to(device)
target = target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print(f"train loss: {loss:.4f}")
# モデルの評価
model.eval()
correct = 0
test_loss = 0
with torch.no_grad():
for data, target in test_loader:
data = data.to(device)
target = target.to(device)
pred = model(data)
test_loss += criterion(pred, target).item()
correct += (pred.argmax(1) == target).type(torch.float).sum().item()
test_loss /= len(test_loader)
correct /= len(test_loader.dataset)
print(f"test loss: {test_loss:.4f}, acc: {correct}, {epoch+1}/{num_epochs}")
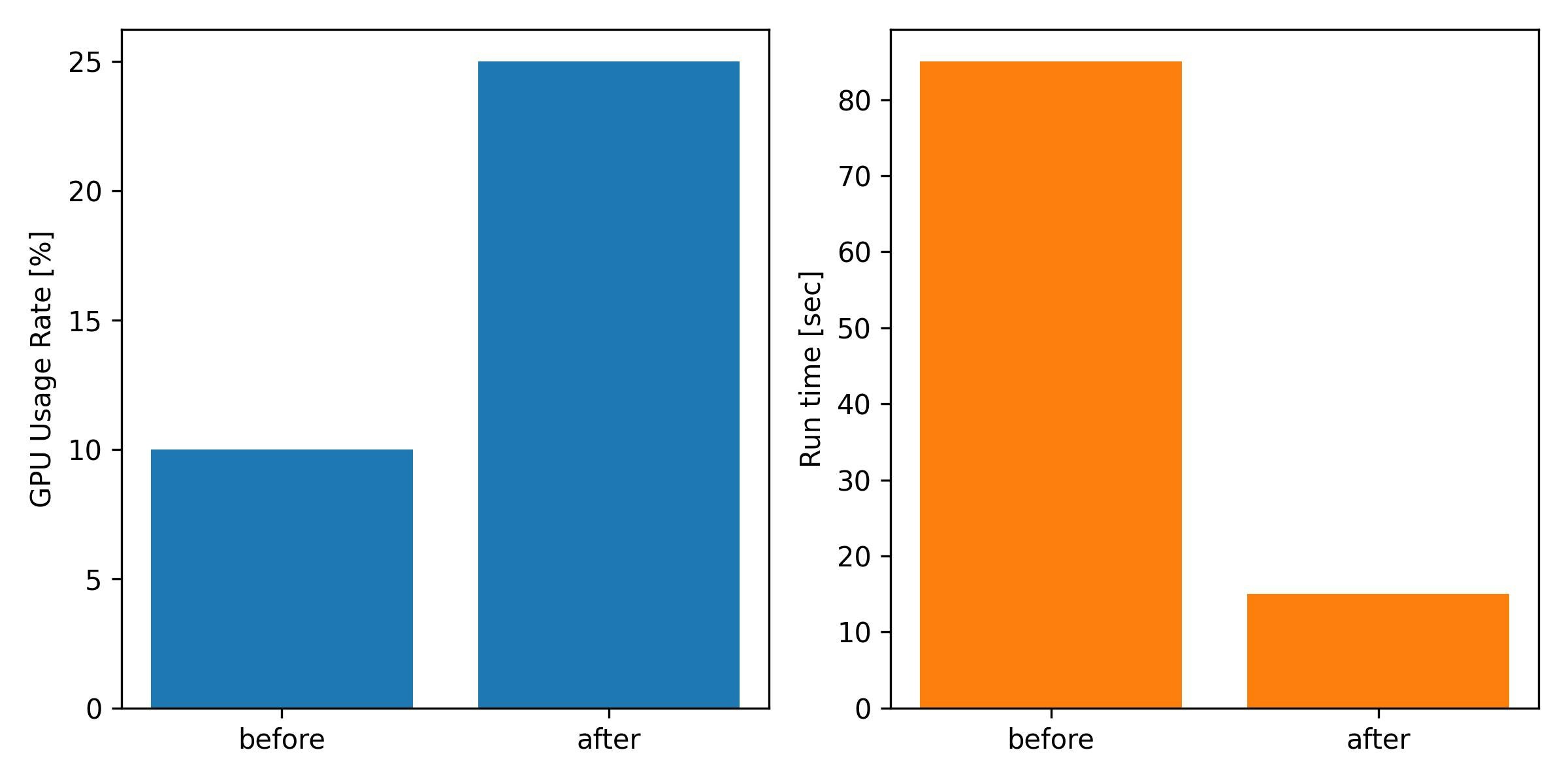
10 エポックの学習を行ったところ,おおよそ実行時間は85秒くらいになりました.
GPUの使用率は10%以下で全然使用できていません.
遅さの原因
明らかにGPU以外でボトルネックが存在します.
今回の調査では torchvision.datasets.MNIST の __getitem__ メソッドで,Tensor 配列の img を numpy 配列 → PIL Image → Tensor 配列 にする変換を挟んで出力していることがわかりました.

上記の変換を __getitem__ メソッドではなく __init__ メソッドでやってしまい,すべてのデータを一気にGPUへ転送した方が早そうです.
対策をやってみた
面倒なので今回いじるところ以外は継承を使ってしまいます.
__init__ メソッドも元々のものを実行しておきます.その後に付け足したプログラムでデータの前処理をします.
from PIL import Image
class MyDataset(datasets.MNIST):
def __init__(
self,
root,
train = True,
transform = None,
target_transform = None,
download = False,
):
super().__init__(root, train, transform, target_transform, download)
# 変換後のデータを保存する
self.data_transformed = torch.empty_like(self.data, dtype=torch.float)
for index, (img, target) in enumerate(zip(self.data, self.targets)):
target = int(target)
img = Image.fromarray(img.numpy(), mode="L")
if self.transform is not None:
self.data_transformed[index] = self.transform(img)
if self.target_transform is not None:
self.targets[index] = self.target_transform(target)
def __getitem__(self, index):
img, target = self.data_transformed[index], self.targets[index]
return img, target
作成したデータセットに合わせて,プログラムを変更します.
train_dataset = MyDataset(root='./downloads', train=True, transform=transform, download=True)
test_dataset = MyDataset(root='./downloads', train=False, transform=transform, download=True)
train_dataset.data_transformed = train_dataset.data_transformed.to(device)
train_dataset.targets = train_dataset.targets.to(device)
test_dataset.data_transformed = test_dataset.data_transformed.to(device)
test_dataset.targets = test_dataset.targets.to(device)
model = MLP().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=learning_rate)
# モデルのトレーニング
for epoch in range(num_epochs):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# すでにGPUに転送済みなので不要
# data = data.to(device)
# target = target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print(f"train loss: {loss:.4f}")
# モデルの評価
model.eval()
correct = 0
test_loss = 0
with torch.no_grad():
for data, target in test_loader:
data = data.to(device)
target = target.to(device)
pred = model(data)
test_loss += criterion(pred, target).item()
correct += (pred.argmax(1) == target).type(torch.float).sum().item()
test_loss /= len(test_loader)
correct /= len(test_loader.dataset)
print(f"test loss: {test_loss:.4f}, acc: {correct}, {epoch+1}/{num_epochs}")
変更したプログラムでは実行時間が16秒になりました.
GPUの使用率は25%になり,先ほどよりも使用できています.
他にもボトルネックがありそうですが,今回は満足したのでここまで.
結論
-
torchvision.datasets.MNISTの__getitem__メソッドでボトルネックがある - ボトルネックを修正したら実行時間が85秒から16秒に改善