動機
ソラコムでは毎年7月に年間最大のイベント「Discovery」というのが開かれていまして、僕も参加したり見に行ったりしているのですが、そのキーノート発表の中で**「Agnostic」**っていう聞き慣れない言葉が出てくるんですよね。
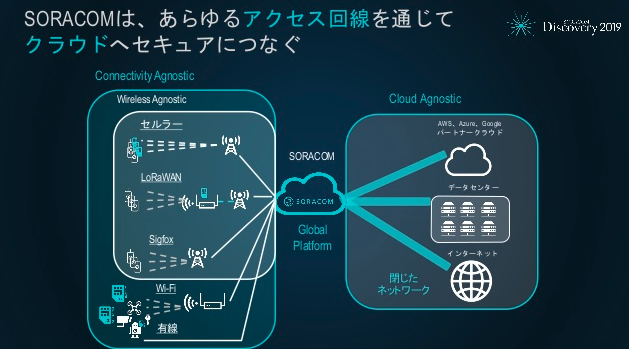
なんかもう当然のように毎回出てくるんですよ、この謎の言葉。2017年も2018年も2019年も。よほど大事な言葉らしい。でも分からない。どうしよう。僕は深刻なITオンチなのかもしれない。
で分からないからググるじゃないですか。そうすると「不可知論者」って出てくるんですよね。は?余計分からん、IoTエンジニアは哲学の知識さえ必要なのか?ってなります。まあ内容的にいろんな通信方式に対応しますよ(Connectivity Agnostic)、いろんなクラウドに対応しますよ(Cloud Agnostic)、と言ってることくらいはわかります。
なんか難しい言葉使われちゃって困るぜ、って思ってたのですが、最近Agnosticの意味するところがようやく分かってきましたので、この言葉の意味するところを僕なりにまとめてみました。
(ソラコムさんの解釈とは違うかも知れません。あくまでも個人の所感です)
知っている = 依存している
Agnosticはそもそもの意味は、例えばWikipediaではこのように説明されています。
不可知論(ふかちろん、英: agnosticism)は、ものごとの本質は人には認識することが不可能である、とする立場のこと。
この場合は、人が物事の本質を知ることができない、ということで、何かを「知っているかどうか」ということが問題を問題にしています。この「知っている」ということは基本的には良いことと考えられているのですが、ソフトウェア界隈ではそうでもなく、独特の意味を持ちます。それは「知っている」ということは「依存している」ということです。
たとえばプログラムがセンサーのデータをデータベースのセンサーテーブルに保存するという場合、プログラムはデータベースのセンサーというテーブルがどのように定義されているかを知っている必要があります。
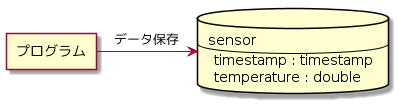
このようになっている場合、データベースにはsensorというテーブルがあり、カラムとしてtimestampがtimestamp型で、temperatureがdouble型で定義されていることを知らなければ保存できません。これが分かった上で、例えば以下のようなSQLが書けます。
INSERT INTO sensor (timestamp, temperature) VALUES ('2019-12-21 17:01:23', 23.12)
このように、あるソフトウェア要素Aが他の要素Bのことをなんらかの形で知っている場合(例えば変数として参照していたり、メソッドを呼び出していたり、ライブラリとしてインポートしているなど)、AはBに依存していると言います。
依存している場合、依存対象が変更されると依存元にも影響があり、場合によっては依存元も修正しなければなりません。例えば上の例でセンサーから温度だけではなく湿度も取得しなければならなくなったとします。すると以下のようにセンサーの種類をテーブル定義に追加することになるでしょう。
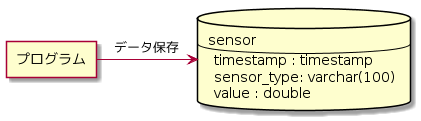
そうすると、プログラムで元々使っていたSQLは修正が必要になります。例えば以下のようになるでしょう。
INSERT INTO sensor (timestamp, sensor_type, value) VALUES ('2019-12-21 17:01:23', 'temperature', 23.12)
このようにある要素が他の要素のことを知っているということはその要素に依存しているということであり、逆に知らないということは依存していないということになります。このため、ソフトウェアの世界においては、Agnosticは「非依存」と訳されることもあるようです。依存されるものが多ければ多いほど、それが変更になった時に影響が広くなります。逆に依存関係をできるだけ少なくわかりやすくすることで変更の影響を小さく把握可能なものにします。知らなくてもいいものは知らないようにしておいた方がいいんですね。
そのため、ソフトウェア設計ではどのように依存関係を作ればよいのかが研究されており、その結果いくつかの指針や手法が生み出されました。しばらくソフトウェア設計の基本的な話が続きますので、飛ばしたい方はこちらにどうぞ。また僕も勉強中であるため、完全に正しい理解は出来ていないかも知れませんがご了承ください。
カプセル化
まずはカプセル化です。カプセル化とは特定の処理に関する詳細を一つのソフトウェア要素にまとめて外部には公開せず、外部からは指定した方法でのみ利用させることを言います。カプセル化によってそれを利用する要素は詳細に対する依存がなくなります。例を挙げましょう。以下のように温度を測定して、サーバーにWebAPIで送信するプログラムを考えます。この場合素朴な構成はこうなります。
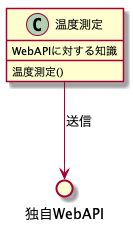
測定して、測定結果をWebAPIに対して送信します。受け取ったWebAPIはデータを保存するなり加工して通知するなりするでしょう(がここではとりあえず気にしません)。当然温度測定のクラスはどのようにWebAPIに送信すればよいかといった知識を持っている必要があります。
では温度の他に湿度や明るさなども測定することになったら?とりあえずこうでしょうか。
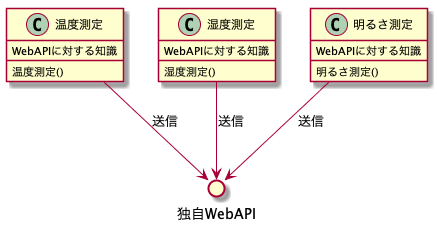
温度測定と同じように、湿度や明るさを測定し、WebAPIに送信するプログラムをそれぞれ作成しました。当然これでも動作します。動作するんですが、3つの測定クラスはそれぞれWebAPIに対する知識を持っている=WebAPIに依存しているため、WebAPIの接続情報(URLなど)やパラメータ、あるいはWebAPIに対する認証情報などが変化した場合、3つとも修正しなければなりません。これは修正間違いや修正漏れなどの事故が起こりそうですね。(ちなみにこのくらいのプログラムの重複はうっかりしてると普通に発生します)
この場合WebAPIに対する接続や送信を司るクラスを作成して測定クラスから分離し、測定クラスはそのクラスにデータ送信を委譲します。
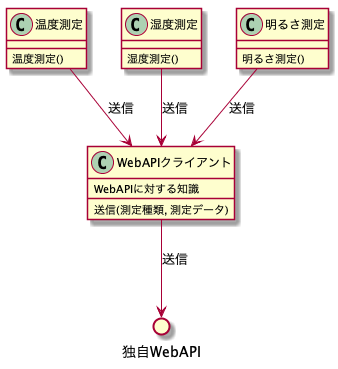
このようにすると、WebAPIに対する知識はWebAPIクライアントクラスの1つに集まるため、WebAPIに変更があった場合に修正しなければならないのはWebAPIクライアントクラス1つだけです。他の測定クラスはそもそもWebAPIのことを知らないので、修正しようがありません。つまり測定クラスはWebAPIに対する依存がなくなっていると言えます。測定クラスは「WebAPIクライアント」というクラスがあり、それに対して「送信」すればよいということだけ知っていれば良いです。
このように実装の詳細を内部に隠蔽し、他のクラスからはその詳細を知らなくても使えるようにすることを「カプセル化」といい、オブジェクト指向設計の基本の1つとされています。(これ自体はオブジェクト指向だけの考え方ではないのですが)
ポリモーフィズム
次はポリモーフィズムです。ポリモーフィズムは色々な解釈がされますが、僕は「同じ呼び出しで多様な振る舞いをさせること」だと理解しています。また例を挙げましょう。先ほどの例のプログラムで、設定によってデータの送信先を独自WebAPI、AWS、Azureと変更できるようにしたい、という要求が出たとします。
どうしましょうか。どこに送信するかを測定クラスが切り替えるとするとこう?
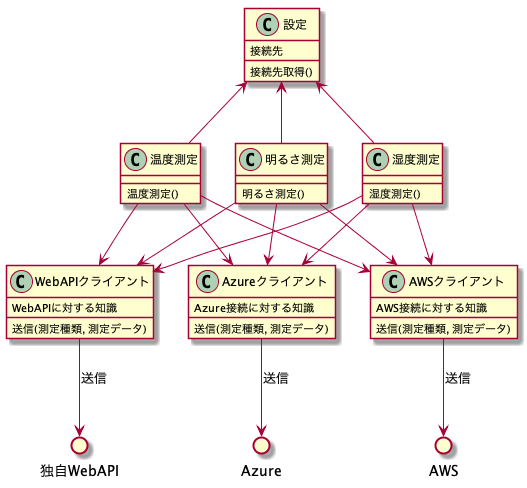
それぞれのエンドポイント(独自WebAPI、AWS、Azure)に対する知識は各クライアントクラスへ、接続先の設定は設定クラスへそれぞれカプセル化しています。(こうしておかないと何かが変更されるたびに3つの測定クラスを全て変更しなければならなくなるので)
これでも動作はするのですが、かなり複雑になってしまっていますし、GCPなどの新しいエンドポイントを増やす際にやはり3つの測定プログラムを間違いなく、漏れなく修正するのが大変そうです。このような場合の取れる設計方法がポリモーフィズムです。
この例で言えば以下のような形が適用できます。
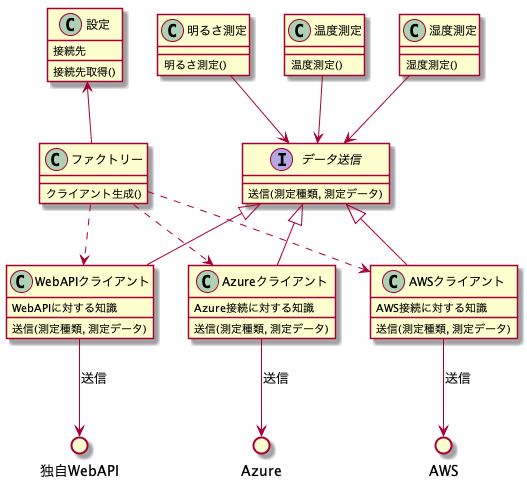
ちょっと複雑に見えますが、役割分担がハッキリしているので役割を抑えておけば難しくないです。
まず個別のクライアントがそれぞれのエンドポイントに対する送信という役割を担っているのは同じです。これら3つは行き先や送信方法こそ違うものの、「データを送信する」という処理は同じです。この「データを送信する」という処理を抽象化してインターフェースとして定義し、各測定クラスはこのインターフェースに対してデータを送信するようにします。
各々の具体的な送信クライアントはこのインターフェースを実装します。(インターフェースを実装するとは、その処理の具体的な内容を記述するということです)そしてインターフェースが呼び出されると、実際にはいずれかの具体的なクライアントが呼び出され、その内容が実行されることになります。
ではインターフェースが実際どのクラスになるのかはどう決定されるのでしょうか?色々な方法がありますが、一番分かりやすいのは具体的なクラスを生成する役割を持つクラス(ファクトリーと言われることが多い)を定義して、そのファクトリークラスに設定を与えて具体的なクラスを生成させる方法です。また、最近ではDI(Dependency Injection: 依存性注入)といって、設定ファイルなどを読み込ませることによってインターフェースをどの具体的なクラスとして生成するのかを決める方法も取られています。
このような構成を取ることにより、測定クラスは実際にどこにどのように送られるのかは知らなくても、データを送信するという処理をさせることができます。
オープン・クローズドの原則
このカプセル化、ポリモーフィズムのメリットはソフトウェアの拡張性にあります。例えばインターフェース適用前の構成で対応エンドポイントにGCPを加える場合はこうなります。
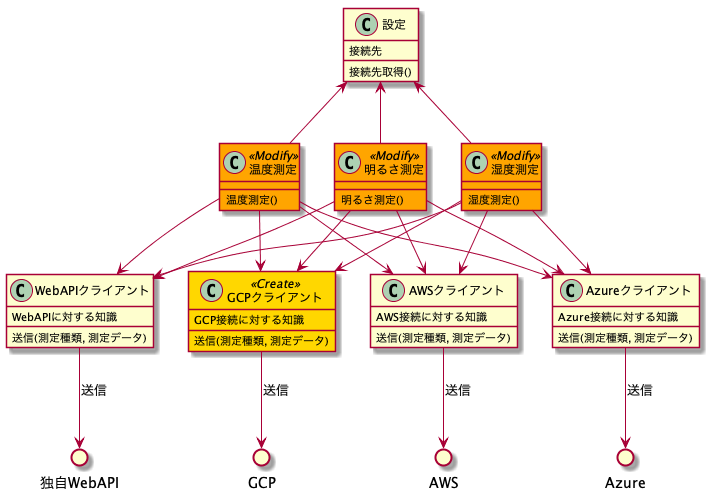
この場合GCPクライアントクラスを追加しなければならないのは勿論なのですが、それを利用する必要のある全ての測定クラスに修正が必要です。測定クラスが多ければその分を全て漏れなく修正しなければならなくなります。これでは拡張するのが大変です。これがポリモーフィズムを適用するとこのようになります。
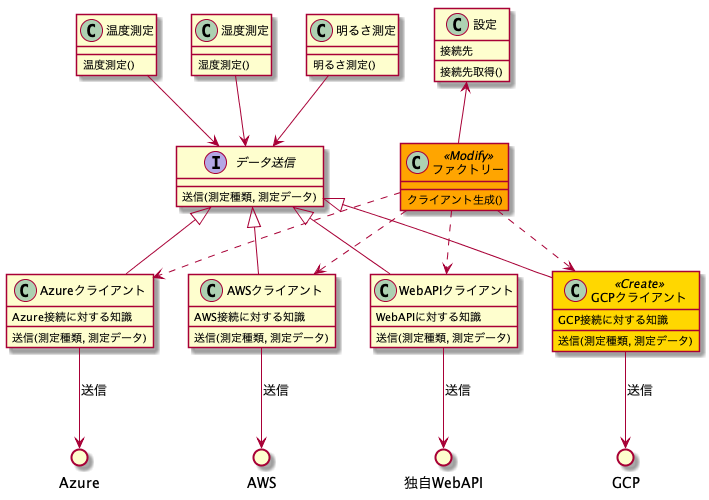
GCPのクライアントは追加要件なので当然追加になりますが、それ以外で修正が必要になる箇所はファクトリークラスのみであり、ファクトリークラスはそもそも接続先の切り替えに対応するためのクラスなので影響するのは仕方ないでしょう(DIを使っている場合はDI用の設定ファイルだけになります)それ以外の測定クラスなどの既存クラスには一切影響を与えていません。これはそもそも測定クラスは測定クラスはただ、「データ送信」というインターフェースのみに依存しており、具体的なクライアントクラスには依存していないためです。この形だと、既存クラスに影響を与えず拡張することができますね。
このように既存クラスに影響を与えずに機能拡張ができるようにしておきましょう、という設計原則を「オープン・クローズドの原則」といいます。これはSOLIDと呼ばれるソフトウェアの設計原則の1つとして数えられています。ソフトウェアは「ソフト」、つまり「柔らかい」=「変更が容易」であるべきなので、このように拡張しやすい形を持っておくのは大事ですね。
依存関係逆転の原則とアダプタパターン
また、上のポリモーフィズムの構成はインターフェースを定義し、それを実装する具体的なクラスを生成することにより、測定クラスがエンドポイントの知識を持たずとも、自分が送りたい形でデータを送信できるようになっています。簡単にすると、最初のこの形だと測定クラスがエンドポイントに依存していたため、エンドポイントの仕様が変わると測定クラスを修正しなければなりませんでした。
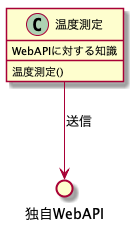
これでは、エンドポイントの仕様が変わりやすかったり、送信クラスが多くなると大変です。これがポリモーフィズムにした形だとこうなっています。
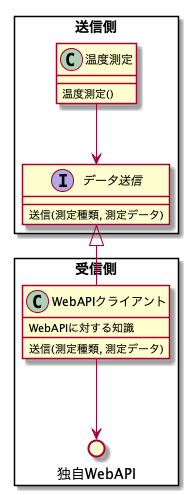
これは測定クラスが「データをこう送りたい」というインターフェースを決めて受信側はそれを従って受信する、という構成です。測定クラス側(エンドポイントを使う側)にエンドポイント側を依存させることができています。
このように自分では変更をコントロールできない外部サービス(この場合はWebAPI)の場合、そのサービスそのものにインタフェースを実装させるのは困難なので、間にインタフェースを実装するクラスを作って対応させています。このような構成は「アダプタパターン」と言われるデザインパターン(ソフトウェア設計のベストプラクティス)の1つです。
ここで大事なことはWebAPIという具体的なサービスに対し、データ送信というインターフェースは変更されにくいということです。これは依存するクラス(この場合は測定クラス)の修正コストが高いほど大事になります。このようにインタフェースなどを用いて依存関係を逆転させ、より安定した方向の依存性を持たせる原則を「依存関係逆転の原則」と言います。(響きがカッコいいのでSOLID原則の中で一番好きです)これにより、修正するのが大変な要素を修正しなくてもよいようにできます。
さて、長くなりましたが、ソフトウェアの前提知識はここまでです。ここからが本題です。
なお、他のSOLID原則についてはここでは詳しく説明はしませんが、興味がある人は「アジャイルソフトウェア開発の奥義」や「クリーンアーキテクチャ」といった書籍を読んでみるとよいでしょう。
Cloud Agnostic
なんの話だったかというとソラコムのAgnosticという言葉の話でした。まずはCloud Agnosticからみていきましょう。Cloud Agnosticでは、SORACOMサービス、例えばSORACOM Funnelを使用することによって、AWSやAzure、GCPといった様々なクラウドサービスに連携することができますよ、というように説明されます。
SORACOM使わない場合はどうなるでしょうか。先ほどの図で説明しますと、
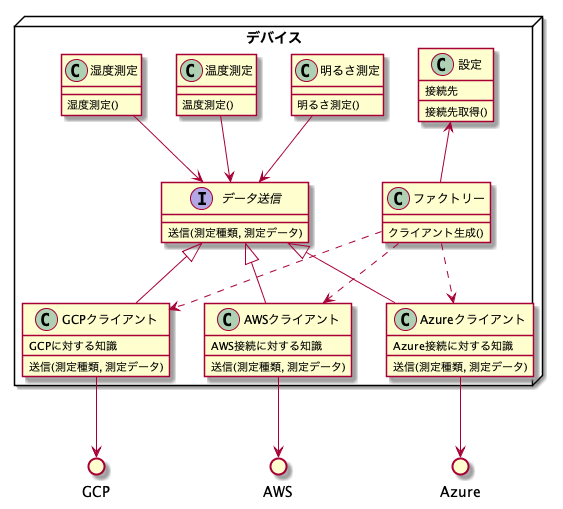
こんな形でデバイス内に色々なクラウドに対応する部分を作って、それに対応することになります。ここまでで説明したように依存関係に気を使って、変化に対応しやすいソフトウェア構成にしています。
WebアプリやPCアプリであれば、これで十分かも知れません。でもこれがIoTデバイスだったらどうでしょうか?IoTデバイスは以下のような特長があります。
- CPUやメモリなどのリソースが貧弱(なことが多い)
- ネットワークが不安定かもしれない(携帯電波がとても弱かったり変動したりする)
- 電源がいつ切れるかわからない(電池で動作してたり太陽光で動作してたりする)
- 人がいなかったり人が操作できるインタフェースがなかったりして人力による復旧ができないことがある
- 代替系とかは基本無い
- 数が多い(万を越えるようなものも普通にある)
- 動作の責任はサービス提供者側(の場合が多い気がする。デバイスはユーザーが所有しているのに)
書いてるだけで頭痛くなってきましたね。。このデバイスの設定やプログラムを修正するのはとても大変です。ネットワークや電源はいつ切れるか分からず、失敗した時の復帰も難しく、対象も多い。つまりソフトウェアとしては変更容易でも、デプロイが大変すぎてそう頻繁に変更するわけにもいかないんですよね。できるだけデバイス側のプログラムは変更せず、でもクラウドの激しい変化にはついていきたい、いろんな新しいサービス使いたい。そんな僕たちを救ってくれるのがSORACOMです。例えばSORACOM Funnelを使えばこうなります。
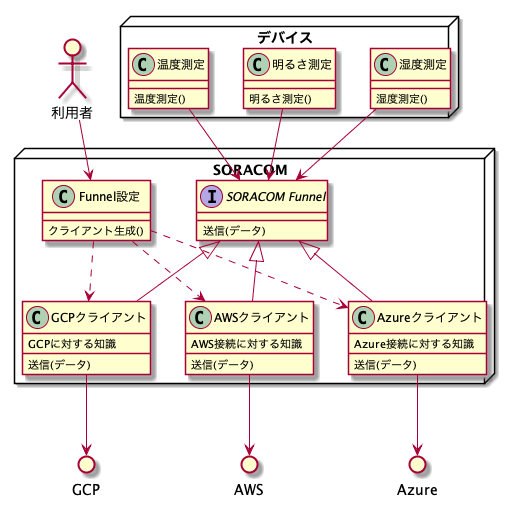
SORACOMサービスの内部を先ほどの図の構成に当てはめています。(実際の構成とはおそらく違いますが、概念的なものだと思っていただければ)
SORACOM FunnelはエンドポイントにHTTP、TCP、UDPのいずれかで送信したデータを、利用者が設定した転送先に向けて転送してくれます。その際接続に必要な認証情報や付加情報なども持たせることができます。
このSORACOM Funnelを使う構成の素晴らしい点は、デバイスは「SORACOM Funnelにデータを送信する」以上のことは何も知らなくていいということです。何も知らなくていい、ということは何にも依存していないということであり、さらに機能追加の際にも何も変更しなくていいということです。これは、、デバイス側としてはありがたすぎて涙が出ますね。
そのため、僕は「Cloud Agnostic」というのは、「色々なクラウドに対応していますよ」というよりはむしろ、「色々なクラウドに対応するんだけどデバイスはそんなの知らなくていいんですよ」ということと受け取りました。実は「Cloud Agnostic」というのはデバイス側のメリットなんですよ。「Cloud」って書いてるからそう思えないけども。
デバイスが見えている世界はこうなります。
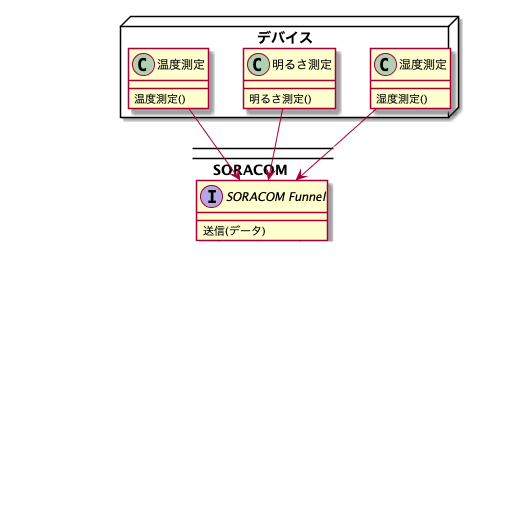
Funnelだけ知っていればいい。他は知らなくていい。まさにAgnostic=「不可知」という感じがしませんか?実際デバイスにはクラウドサービスを全て把握することなんて無理なんですよね。開発段階においてはまだ分かるかも知れませんが、そのあとどんなサービスが出てくるかわからない。実際Funnelが出た後にも色々なサービスに対応していますし。そんなデバイスには知るよしもない多様なクラウドサービス、未来のクラウドサービスにさえ、Funnelにデータを送信しているだけで対応したことになるのです。
AWSに対応したい? - Funnelで対応できます。デバイスは何も変更しなくていいです。
GCPに対応したい? - Funnelで対応できます。デバイスは何も変更しなくていいです。
あのソラコムパートナーのサービスが使いたい? - Funnelで対応できます。デバイスは何も変更しなくていいです。
AWS、Azure、GCPに続く第4のメガクラウドが現れた? - Funnelで対応できます。多分。デバイスは何も変更しなくていいです。
オンプレにデータを送りたい? - FunnelでAWSなどのサービスを介してデータを送ってもいいですし、Unified Endpointにデータを送信して、Beam経由でデータを直接送信してもいいですね。これはちょっとデバイスを変更する必要がありますが、送信先エンドポイントをUnified Endpointに変えるだけです。むしろ最初からUnified Endpointに送って送信先をFunnelにしておけばその後はデバイス側の変更しなくてよくなります。Unified Endpointを使った場合はちょっと複雑ですが多分こんな感じ。
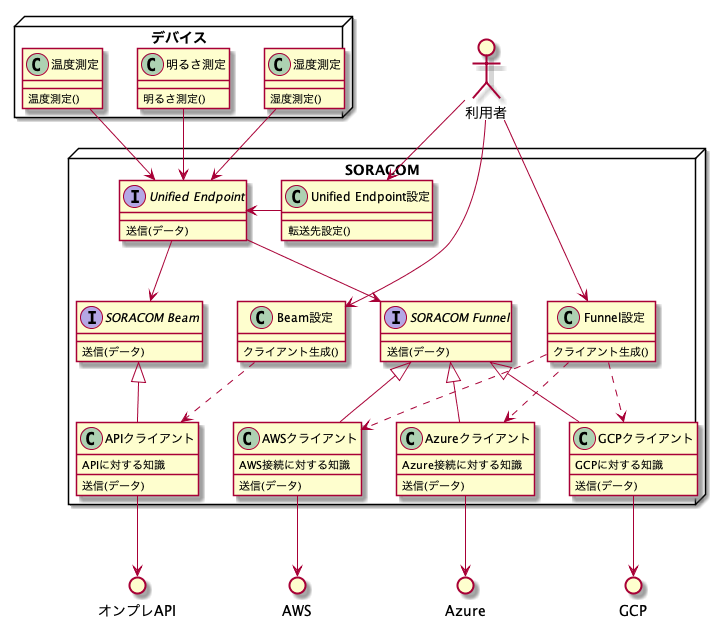
Unified Endpointに送信するとソラコムの各種アプリケーションサービスのいずれか、もしくは全てにデバイスからのデータを転送してくれるので、ここに送っておけばSORACOMの全ての対応アプリケーションサービス、およびFunnelやFunkが対応している全てのクラウドサービスに対応したことになります。例えばBeamはデータを指定したHTTPSエンドポイントに送信してくれるので、これを使ってオンプレへのデータ転送もできます。そしてそんなことになっていることをデバイスは一切知らなくていいし何も変更しなくていいのです。デバイスは「Unified Endpointにデータを送信する」以上のことは知らなくていい。これが「Cloud Agnostic」です。僕はこれを「ソラコム挿しときゃなんとかなる」と言っています。
Cloud Agnostic アーキテクチャ考察
アーキテクチャ的にみてみると、まずデバイスが依存することになるSORACOM FunnelやUnified Endpointはかなり安定したインタフェースです。HTTPかTCPかUDPでデータを送信すればよく、データの内容は問わないので、これ以上シンプルで安定したインタフェースは無いといえるくらいです。クラウドサービスの多様なインタフェースに直接デバイスを依存させるのではなく、デバイスが使えるシンプルなインタフェースを用意し、それを各種サービスに対応したクライアントに実装させており、「依存関係逆転の原則」に沿っているものと考えられます。
そしてこれはクラウドサービスへの対応をアダプタとなるクライアントで対応している「アダプタパターン」と考えられます。そういえばSORACOM Funnelのサービス名って「クラウドリソースアダプタ」なんですよね。このような役割をもったサービスとして設計されているんだ、ということがわかります。
また、Funnel(など)は入り口はシンプルなインタフェースですが、利用者の設定によって様々なクラウドサービスに対応するなど、多様な振る舞いをします。そして、新しい機能が追加になり、それを実際に使用するとなっても、デバイスは変更する必要がありません。これはオープン・クローズドの原則に沿っているものと考えられますね。
このようにソラコムはこれまでソフトウェア開発の歴史で営々と築き上げられてきたソフトウェア設計技術の粋を尽くしてサービスが構成されていることが窺えます。
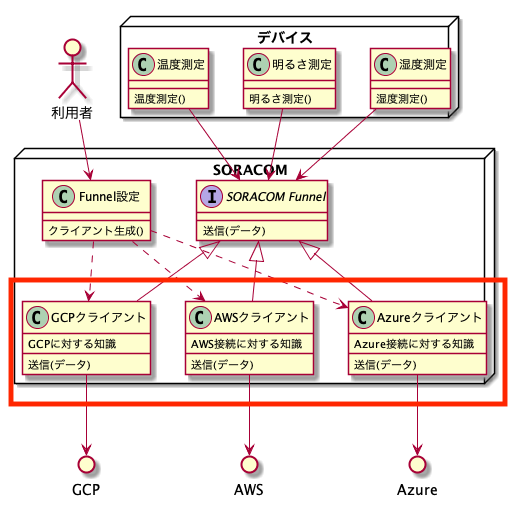
改めて見ると非常に美しくかつ実用的なアーキテクチャですね。変更が難しいデバイス側は極力変更しなくて済み、かつ拡張性が高い。しかもその一番大変な部分をSORACOMが担当してくれています。開発上一番大変な部分はこの赤枠の部分と思われます。この部分は実際に様々なクラウドサービスに対応する部分で、クラウドサービスの仕様を調査し無ければなりませんし、サービス側に変更があれば対応しなければいけないし、増やすとなったらその分作って維持しなければなりません。デバイス側でこれを多数のサービス分やるのは正直やってられません。これをソラコムが地道にやってくれているおかげで、デバイス側はただデータ投げるだけで良くなっているんですね。ありがたい。
また、このようにシンプルなインタフェースの提供は、SORACOMがSIMによる認証と閉域ネットワークによるセキュリティの確保という特長を持っているからできることです。普通はインターネットを通す時は暗号化や認証が必要であるため、その暗号化方式や認証方式に応じてインタフェースが複雑になりがちです。SORACOMはそれをネットワークの安全性そのもので確保しているため、アプリケーションサービスの入り口を思いっきりシンプルにしてもセキュリティが保たれるのですね。自社で回線をコントロールしていないと出来ない技です。
最後に最も素晴らしいと思うのは、SORACOMのサービスを普通に使っていると、自然とこのような拡張性の高い構成になることです。高い拡張性にするためのオープン・クローズドの原則などはソフトウェアの勉強をしていて知っている人は多いのですが、なかなかこのような抽象層をソフトウェアに組み込むのはやっていないものです。特に最初のうちはあまり必然性を感じないので、具体的なサービスにあちこちが依存している形になりがちです。
ところがSORACOMはまずデバイスで回線使ったらSORACOMは利用しますし、BeamやFunnelなどを使うと通信量の削減や認証情報をデバイスに持たせなくても良いといったメリットがありますので、自然にそのようなサービスを使います。この時点で拡張する準備ができている。そして必要になった時に、「あれ、これ設定を変更するだけでもあのサービスに対応できるじゃん。デバイスを変更しなくても」ということになります。アフターケアまで事前にされてしまっています。なぜか。
ということで僕の言いたいことは、IoT、特にデバイスの開発者はSORACOMのUnified Endpointを使ってみることをお勧めするよ、ということだけですのでそこのところよろしくお願いします。
Connectivity Agnostic
さて、次はConnectivity Agnostic(Wireless Agnostic)です。(実のところ僕はどちらかというとデバイス側のため、こちらは若干薄くなってしまいます)
Connectivity Agnosticも、色々な通信方式(3G、LTE、LTE-M、LoRaWAN、Sigfox、SMS、USSDなど+インターネット回線)に対応しますよ、ということを言われているのですが、これも、「色々な通信方式に対応しますよ」というよりはむしろ「色々な通信方式は使えるんだけどクラウド側はその詳細を知る必要はありませんよ」ということと思います。
普通のクラウドサービスではTCP/IPで、HTTPSのWebAPIで、データフォーマットはJSONで送信されてくる、というのが多いですよね。ところがIoTの場合はデバイス側の制約、価格や消費電力の制約で、聞いたことも無いような通信方式でデータを送りたい、って言われてしまうことがあります。
ユーザー「SMSでデータを送信しても良いですか?」
事業者「多分大丈夫です(SMSのデータ受信ってどうやるんだっけ?)」
ユーザー「LTE-Mでデータを送信しても良いですか?」
事業者「多分大丈夫です(LTE-MってLTEとなんか違うんだっけ?)」
ユーザー「Sigfoxでデータを送信しても良いですか?」
事業者「多分大丈夫です(Sigfoxってなんか申請がいるんだっけ?)」
ユーザー「どのくらいの開発費になりそうですか?」
事業者「通信方式の調査からやるので1千万はまあ。。」
ユーザー「」
みたいな感じになりそう。調査からなら1千万どころではないですかね。正直良く分からなくてまず見積もりを出すための調査のための見積もりが必要そう。
これがSORACOM FunnelやSORACOM Beamを通すと、普通のWebAPIに変換した上で送信してくれます。どんな通信方式が来ようと、クラウド側はSORACOMだけ相手にしていればよく、SORACOMからの通信に対応しただけで全ての通信方式に対応したことになるんですよね。
ユーザー「SMSでデータを送信しても良いですか?」
事業者「SORACOM Beamに送ってくれれば大丈夫です」
ユーザー「LTE-Mでデータを送信しても良いですか?」
事業者「SORACOM Beamに送ってくれれば大丈夫です」
ユーザー「Sigfoxでデータを送信しても良いですか?」
事業者「SORACOM Beamに送ってくれれば大丈夫です」
ユーザー「どのくらいの開発費になりそうですか?」
事業者「すでにできてますよ」
ユーザー「すげえ」
みたいな感じになります。(実際はデバイスを識別する情報などが違うので完全に同じというわけにはいきませんが)
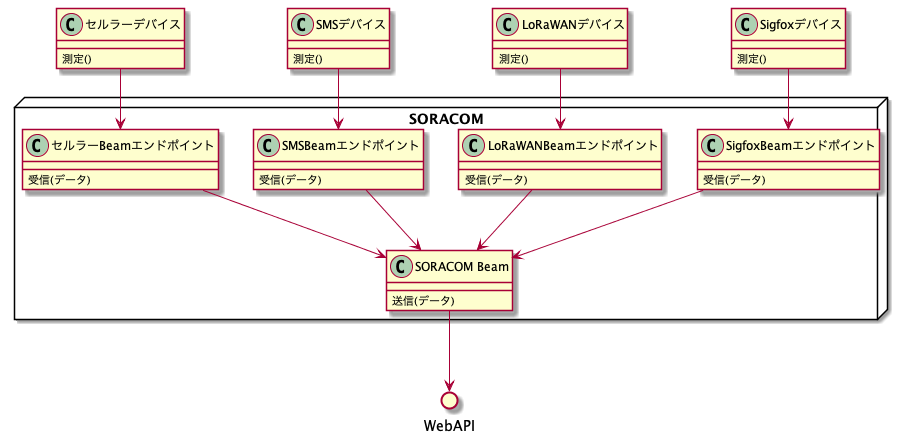
様々なデバイス、通信方式用のエンドポイントが用意されており、それぞれの方法でデバイスからの通信を受信しますが、それらは(ほぼ)共通の方法で、外部のHTTPSエンドポイントにアクセスします。このため、WebAPI側としては、どのような通信方式であっても、SORACOM Beamからの通信のみ受け取れるようになっていれば良いです。
WebAPIから見える世界はこう。
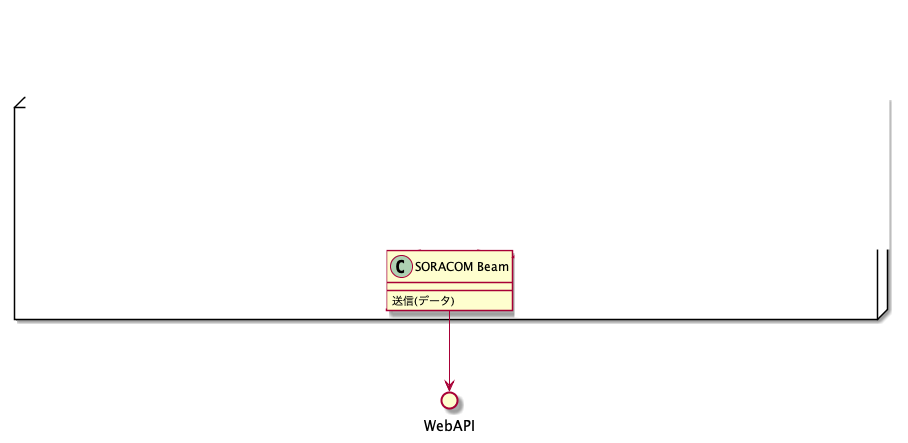
面倒な通信方式ごとの受信の違いなどはソラコムが吸収してくれるため、届いたデータをどのように処理するかに専念することができます。
これはデバイス側とクラウド側の分業ということを考えるといいことで、デバイスは何らかの方法でSORACOMにデータを送信すること、クラウドはSORACOMからデータを受信することだけ考えていればよく、クラウドはデバイスのことを、デバイスはクラウドのことを知らなくても開発を進めることが出来ます。(デバイス側の人はSORACOM Harvestにデータを送信すればどのデータが送られているかを対応クラウドがまだ出来ていない状態でも確認できます)
また、リソース制約の強いデバイスはデータをJSONにすることも大変で、バイナリのままデータを送信してきますが、クラウドサービス側は基本的にはバイナリを扱いません。そのギャップを埋めるため、バイナリパーサーを用いてバイナリをJSONに変換してクラウドサービスに送信させることができます。またバイナリパーサーには、データのキーをデバイスではなくクラウド側で確定させられるというメリットがあり、デバイス側はクラウドに送るデータフォーマットを決めなくてもデータを送信することができ、クラウド側はそれを受け取りたい形式に変換して受け取ることができます(バイナリパーサーはそこそこ難しい機能なので善し悪しですが、フォーマット変換がクラウド側でできるのは強力だと思います)
このように、「通信方式によらず同じようにデータを受け取ることができる」ので、「SORACOMからの通信を受け付けられるようにしておくだけで多様な通信方法に対応したことになる」「すでにSORACOMからの通信に対応している一般的なクラウドサービスはすでに色んな通信方法に対応できていることになる」というのが「Connectivity Agnostic」ですね。
まとめ
ソラコムがインターフェースとなりデバイスとクラウドを分離することによって、
デバイスはクラウドを知らなくてもSORACOMだけ知っていれば、
クラウドはデバイスを知らなくてもSORACOMだけ知っていれば、
開発を進めることができるし機能を実現することもできます。
そして片方が増えると、他方は何も変更しなくてもその追加に対応することができます。デバイスから見るとSORACOMに対応するだけでSORACOMに対応している全てのサービスに対応していることになる(Cloud Agnostic)、クラウドから見るとSORACOMに対応するだけでSORACOMに対応している全てのデバイスに対応していることになる(Connectivity Agnostic)。これを実現しているということが、ソラコムの提唱する**「Agnostic」**であると考えています。
参加するクラウドサービスが増えるほど、デバイス側が利用できるサービスの幅が広がりますし、
利用できるデバイスが増えるほど、クラウドサービスは様々なデバイスからデータを受け取れるようになります。
お互いに負担をかけずに、でも参加者が増えるほどお互いのメリットが大きくなる。
まさに「IoTプラットフォーム」という感じがしませんか?
とりあえずデバイス側はUnified Endpointにデータを送信することを、
クラウド側はSORACOM BeamやFunnelからデータを受信できることから始めて、
様々なデバイスやサービスがSORACOMを通して連携できるようになれば、
IoTをもっと活性化、スピードアップできるのではないかなと思います。
お互いIoTを盛り上げていきましょう!