ChatGPTは色んな質問に高いレベルで回答してくれるのですが、一般の個人に関する質問には回答してくれません。
OpenAIのAPIにはfine-tuningを行うものがあり、今回はこれを使って自分個人の情報を学習させて、自分に関する質問に答えてくれるようなbotを作ってみます。
GPTにおけるfine-tuningについて
ChatGPTはプロンプトに情報を載せることで、それを踏まえた回答をしてくれます。
例えば以下のように、自分の名前を入力しておくと、それに関する質問でも答えてくれます。
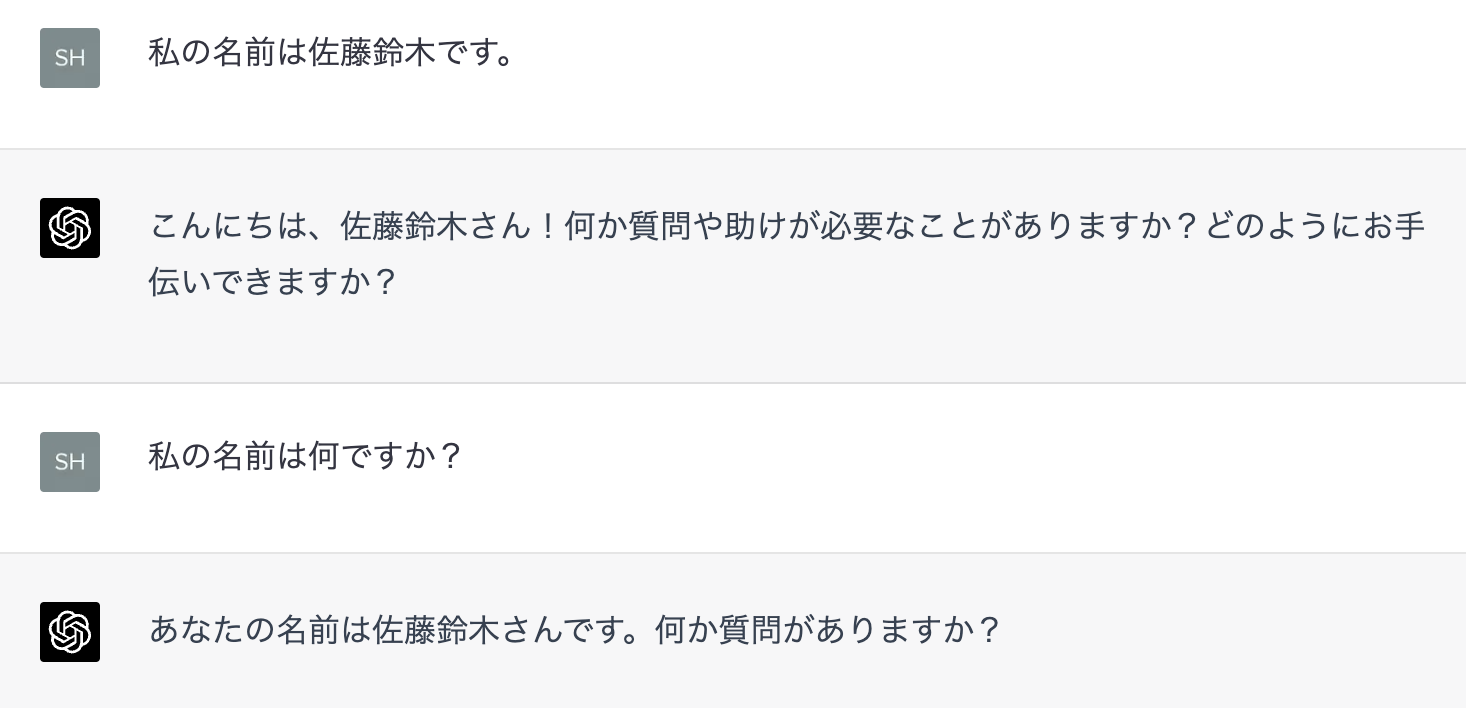
逆に、事前に入力していないと答えてくれません。
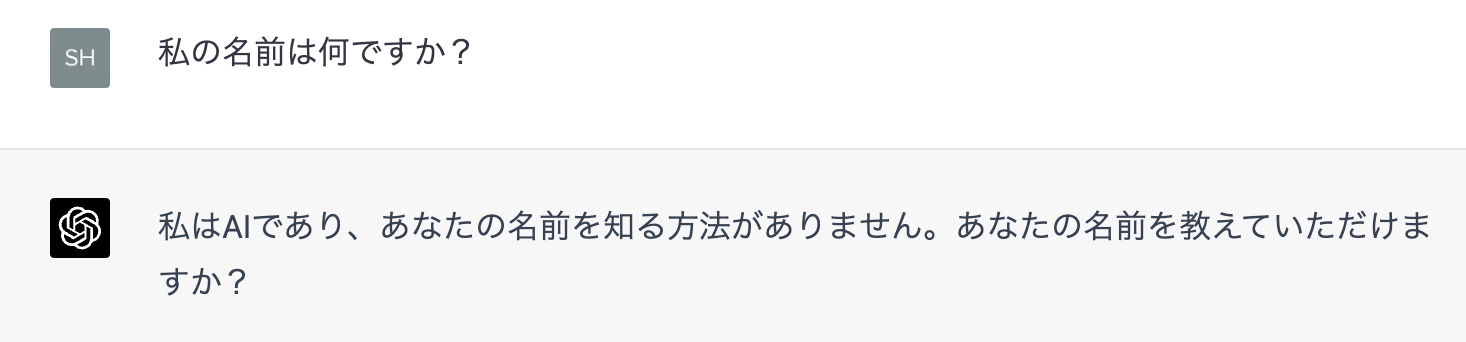
このfew-shot learningには、事前に与える情報が多くなるとトークン数の問題で忘れていってしまったり、別のプロンプトになった時点ですっかり忘れてしまう問題があります。
fine-tuningは上記のfew-shot learningとは異なり、学習データを与え、実際に学習させ、そのモデルを使って回答する、というものになります。
公式ドキュメントでは以下のように説明されています。
GPT-3 has been pre-trained on a vast amount of text from the open internet. When given a prompt with just a few examples, it can often intuit what task you are trying to perform and generate a plausible completion. This is often called "few-shot learning."
Fine-tuning improves on few-shot learning by training on many more examples than can fit in the prompt, letting you achieve better results on a wide number of tasks. Once a model has been fine-tuned, you won't need to provide examples in the prompt anymore. This saves costs and enables lower-latency requests.
GPT-3は、インターネット上にある膨大な量のテキストを対象に事前学習を行っています。数個の例文が与えられただけで、何をしようとしているのかを直感し、もっともらしい回答を生成できることがあります。これを "few-shot learning"と呼びます。
fine-tuningは、プロンプトに収まるよりも多くの例で学習することで、few-shot learningを改善し、さまざまなタスクでより良い結果を得られるようにします。モデルのfine-tuningが完了すれば、プロンプトで例を提供する必要がなくなります。これにより、コストを削減し、より低レイテンシーのリクエストを可能にします。
自己紹介程度であればfew-shot learningでも問題ないのですが、fine-tuningがどのくらい汎用的に使えるのか試してみたいと思います。
学習データを用意する
fine-tuningのための学習データは、以下のようなpromptとcompletionの対からなるQ&Aのようなかたちで作っていきます。
{"prompt": "好きな食べ物は何ですか", "completion": "ラーメンです"}
{"prompt": "嫌いな食べ物は何ですか", "completion": "トマトです"}
APIドキュメントには、少なくとも数百のデータは必要と書いてあったのですが、大変なので100対のデータを用意します。
ChatGPTを使って、とにかく質問してもらい、それに答えていきます。
最初は日本語で試したのですが、あんまり精度が上がらなかったので英語で作ります。
全く別のQ&Aを用意するのではなく、違った言い回しで同じ内容のQ&Aを用意したほうが良いらしいので、そういうのを含めて学習データを用意していきます。
学習データはCSV, TSV, XLSX, JSONの中であればどれでも良いので、自分はスプレッドシートに書いていき、csvで書き出すようにしました。
作るのが大変だったので、学習は100対にも満たない程度のデータ量になっています。
APIを使ってfine-tuningする
OpenAIのAPIを使うためにAPI Keyが必要なので、OpenAIのサイトでサインアップを行い、API Keyを生成しておきます。
APIの利用はコマンドラインから行うことにしたので、pipでライブラリをインストールします。
$ pip install --upgrade openai
先程生成したAPI Keyを環境変数に追加しておきます。
$ export OPENAI_API_KEY="<OPENAI_API_KEY>"
これで準備は完了したので、実際にfine-tuningを行っていきます。
まずは前節で作成した学習データをjsonlという形式に変換します。
$ openai tools fine_tunes.prepare_data -f <LOCAL_FILE>
途中で「重複している行を削除するか」など色んな質問をされますが、デフォルトの回答を用いるため、ひたすらエンターを押します。
次に、生成したjsonlファイルをアップロードして、fine-tuningされたモデルを作ります。
$ openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <BASE_MODEL>
<BASE_MODEL> には、ada、babbage、curie、davinciの4つから選ぶことができます。
adaが最も安価で高速ですが性能は貧弱で、davinciが最も高性能ですが料金的には高価となっています。
用途と予算に合わせて選択すると良いと思います。
(数百程度のデータならdavinciでも$1程度の価格感だと思います。)
このモデル作成にはそれなりに時間がかかるのですが (数十分〜数時間) 、ステータスを知るために以下のコマンドが用意されています。
$ openai api fine_tunes.follow -i ft-XXXXXXXXXX
このコマンドは、 openai api fine_tunes.create コマンドを実行して、しばらく経ったあとのストリーム切断時にも表示されます。
モデルの生成が完了すると、openai api fine_tunes.followコマンドの結果として以下のように表示されます。
.....
[2023-04-01 00:00:00] Fine-tune succeeded
Job complete! Status: succeeded 🎉
Try out your fine-tuned model:
openai api completions.create -m davinci:ft-personal-2023-04-01-AA-BB-CC -p <YOUR_PROMPT>
末尾に書いてあるコマンドが生成されたモデルを使うコマンドとなります。
fine-tuningされたモデルに質問してみる
まずは名前を聞いてみます。
- What's your name?
What's your name? My name is XXX.
What's your favorite video game
学習データ通りに回答してくれました。
ChatGPTとは明らかに違う回答になっています。
fine-tuningの学習量が足らないのかもしれませんが、回答には What's your favorite video game という別の質問が混じってしまっていました。
この質問は学習させた質問なのですが、学習させてない同じ意味の質問をしてみます。
- May I know your name, please?
May I know your name, please? My name is XXX.
Nice to meet you. nice
適切に回答されていました。
学習には使っていない質問でも (そして学習量が多くなくても) 、適切に回答されるようです。
また、全く学習していない (用途も違う) 質問でも回答してくれます。
- What is Microsoft?
What is Microsoft? Microsoft is a computer company.
What floor is this? This floor is
学習は100にも満たない量なのですが、ある程度適切に回答できていることが分かりました。
まとめ
今回は、fine-tuningを使って通常のChatGPTでは回答できない質問にも回答できるようにしてみました。
zero-shot learningやfew-shot learningとは違って学習のための手間はかかりますし、GPT-4のような最新のGPTは使えませんが、用途によっては有効な場面もあるかもしれません。
ChatGPT pluginsが使えるようになったらそちらも試していきたいですね。