動機
外資系のAmazonが展開している電子書籍Kindleでは比較的洋書の取り扱いが多いです。
Kindle Unlimitedに登録されている書籍も多く、Springerなんかも含まれているので活用しない手はありません。
そこでkindle-translatorをつくりました。
https://github.com/1plus1is3/kindle-translator
これで一冊50万字あるKindleの洋書を1分で日本語PDFに変換できます。
キーボードの矢印キーでページ送りができるならKindleに限らずあらゆる電子書籍リーダおよびPDFビューワで使え、DeepLが対応している言語であれば英語以外の言語でも翻訳できます(仏→日とか)。
未経験からPythonエンジニアになって3ヶ月(うち1ヶ月は研修)が経ち、色々作れるようになった時点でつくったツールなので、改良すべき点もまだまだあります。
この記事ではkindle-translatorの使い方を紹介し、最後に改善したい課題に触れます。
これがこうなる
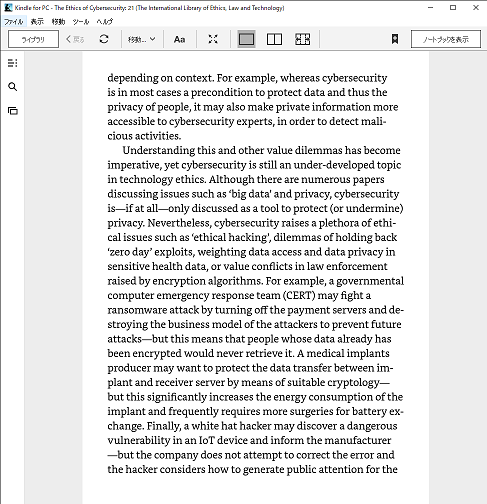
これが1分で
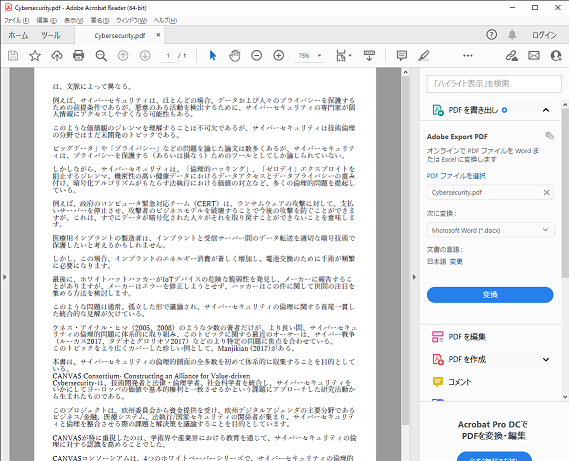
こうなります。
(引用 **The Ethics of Cybersecurity (The International Library of Ethics, Law and Technology Book 21) by by Markus Christen, Bert Gordijn, et al. Feb 10, 2020)
(この本の著作権範囲はCC: BYです)
(CC:BYとは?→https://creativecommons.org/licenses/by/4.0/deed.ja)
想定している使い方
- 学術書または論文PDFにざっと目を通したいとき
あくまでざっとです。
DeepLがクォーテーションを認識するのが苦手らしく、訳した後の文でカギカッコが閉じていないなどの失敗が多々あり、会話文の多い文章はあまり向かないという印象です。
また、小説では地の文のですます調やである調、一人称のぶれなどがあり、あまり実用的ではない文章になってしまいました。
そしてこれは大きな課題なのですが、図や表を都度認識して日本語PDFにコピーすることは難しく、現時点では文章のみの翻訳PDF出力となっています。
準備(一度やれば次からはしなくていい)
1. pipまたはcondaが使えるPythonの実行環境
本ツールはpythonで書かれています。必要なライブラリをrequirements.txtおよびvenv.yamlに出力してあるので、pipを使う場合はrequirements.txtを、condaを使う場合はvenv.yamlをそれぞれ使用して仮想環境を整えてください。
2. DeepL APIの登録
以下からAPI版DeepLに登録してください。(無料版であってもクレジットカードの登録が必要です)
https://www.deepl.com/ja/pro#developer
無料版で構いませんが、その場合はtranslator.pyの48行目のURLをapi.deepl.comからapi-free.deepl.comに変更しておく必要があります。
登録が済んだら、translator.pyの29行目に発行されたAPIキーを入力してください。
3. Tesseractのインストール
導入だけで短い記事が一本書けそうだったので、潔く良記事に頼ることにします…。
わかりやすく描かれているひつじ工房様のサイトを参考に、OCRに必要なTesseractをインストールしてください。
https://hituji-ws.com/code/python/tesseract-ocr/
インストールが終わったら、ocr.pyの36行目と40行目を自分の環境に適したパスへと変更してください。
4. フォルダパスの設定
画像保存用フォルダとテキストファイル(とできたPDFファイル)を保存するフォルダを準備し、capture.pyの86行目とocr.pyの47行目を適宜変更してください。
使い方
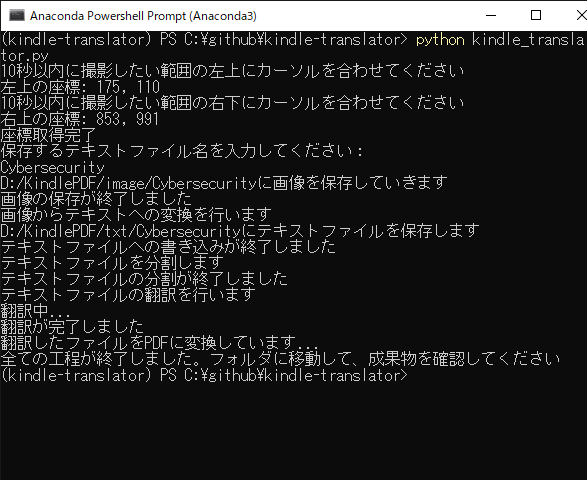
電子書籍を読み取る箇所以外はすべてコンソールで完結します。
0. 準備
kindke-translator実行前にはあらかじめ訳したい電子書籍を開いておくとスムーズにいきます。
1. 実行
GitHubからcloneしてきたファイル一式を任意のフォルダに置き、
python kindle_translator.py
で走らせるだけでOKです。
その後は電子書籍リーダをクリックしてアクティブにした上で左上にカーソルをあてて10秒待ち、また右下にカーソルをあてて10秒待ちます。
すると座標が取得でき、保存するファイル名・フォルダ名を聞かれるので入力しましょう。拡張子はいりません。
あとは自動でフォルダが作られ、翻訳され、できたPDFがフォルダに格納されます。
万能かと思うじゃん?
APIの使用は割と高くつきました。
2022年11月時点で、基本料金の月額630円のほか、アルファベット50万字程度を日本語に訳すので1300円ほどかかります(DeepL API有料版は料金上限を設定できるので超過する心配はありませんが)。
悲しいことですが、経費などで落ちない限り、DLしただけで読んだ気になっている海外論文PDFや積読を気軽にバカスカ訳せるシロモノではないでしょう。
そこで次で説明する使い方にシフトするのもアリかと思います。
脱線した使い方
DeepLで月額1200円の個人のStarterプランに入ろう。
オンラインとアプリの両方でテキストの翻訳文字数が無制限になるので、kindle_translator.pyの29行目から33行目までをコメントアウトし、文字起こししただけの英文テキストファイルだけが残る状態にしておくと、手動ながらもDeepLでの料金は気にしなくて良くなります。
この場合、PDFconverter.pyだけを呼び出して翻訳したテキストファイルを渡すとPDFに変換できます。
やってはいけないこと
Kindleにおいては私的利用の範囲におけるスクリーンショットの撮影はOKという見解がありますが(https://news.line.me/detail/oa-bengo4com/0qvnrf33lknd)、スクリーンショットやテキストファイル、PDFの他者への販売・譲渡は違法となるようです。
kindle-translatorは私的利用の範囲に留めてください。
また、kindle-translatorの使用によって生じた如何なる損害についても制作者は責任を持ちません。
開発の話
ここからは開発の話を少しします。
以下はkindle-translatorのメイン(コントローラ)部であるkindle_translator.pyです。
"""
kindle-translator
"""
from capture import Capture
from ocr import OCR
from translator import Translate
from PDFconverter import PDFConverter
class Main:
"""
kindle_translatorを実行するMainクラス
"""
capture = Capture()
ocr = OCR()
translator = Translate()
convert = PDFConverter()
# スクリーンショットを撮影する範囲の座標を取得
x_1, y_1, x_2, y_2 = capture.window_manager()
# ページごとにスクリーンショットを撮影(png形式で保存)
page_number, file_name, img_file_path = capture.window_capture(x_1, y_1, x_2, y_2)
# 取得した画像から文字を抽出してひとつのtxtファイルに保存
file_name_txt, txt_file_path = ocr.extract_characters(page_number, file_name, img_file_path)
# DeepLに投げられるようにファイルを100キロバイトごとに分割して保存
file_list = ocr.divide_file(file_name, file_name_txt)
# テキストファイルをDeepLに投げる
translator.translate_with_deepl(file_list, file_name)
# 翻訳されたテキストファイルをPDF形式に変換
# 出力先はテキストファイルと同じフォルダ
convert.text_to_pdf(file_name)
すべて英語で書くか迷いましたが、英語を読みたくなくて翻訳する人が多いと思うので読みやすさを優先し、docstringを含め、表示される文章やコード中のコメントなどできる部分はすべて日本語で書きました。
Pythonに親しみがない人でも挙動がわかりやすいように、鬱陶しいぐらいのコメントをつけています。
コードは気軽に改変して使ってください。
今後の課題(ほぼメモ)
- 電子書籍を読み込むとき10秒ずつ待たなくてもいい方法(クリックで済むようにするなど)
- 電子書籍リーダをアクティブにし忘れることがあるので対策
- GUI化
- 多言語対応
- 図表をコピーしつつ文章は訳す(論文の訳に徹したツールをつくってみてもいいかもしれない)