環境
Chip: Macbook M1
OS: Ventura 13.2.1 (22D68)
環境: Unity 2021.3.16f1
合成音声に喋らせる
コードの全体を載せておきます。詳細は後から解説します
using System;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Audio;
using System.Threading.Tasks;
public class TextToSpeechService
{
static string speechKey = "YOUR_API_KYE";
static string serviceRegion = "YOUR_INSTANCE";
static Uri endpoint = new Uri("YOUR_ENDPOINT");
SpeechConfig config;
private SpeechSynthesizer synthesizer;
private void Init()
{
config = SpeechConfig.FromEndpoint(endpoint, speechKey);
config.SpeechRecognitionLanguage = "ja-JP";
config.SpeechSynthesisLanguage = "ja-JP";
config.SpeechSynthesisVoiceName = "ja-JP-NanamiNeural";
config.SetSpeechSynthesisOutputFormat(SpeechSynthesisOutputFormat.Riff24Khz16BitMonoPcm);
synthesizer = new SpeechSynthesizer(config, null);
synthesizer.SynthesisCanceled += (s, e) =>
{
var cancellation = SpeechSynthesisCancellationDetails.FromResult(e.Result);
Debug.LogError(
$"CANCELED:\nReason=[{cancellation.Reason}]\nErrorDetails=[{cancellation.ErrorDetails}]\nDid you update the subscription info?");
};
}
public async void Speak(string text)
{
using var result = await synthesizer.SpeakTextAsync(text);
if (result.Reason == ResultReason.SynthesizingAudioCompleted)
{
Debug.Log("Synthesis completed.");
var audioDataStream = AudioDataStream.FromResult(result);
// var filePath = Application.dataPath + "/Audio/" + speechText + ".wav";
// await audioDataStream.SaveToWaveFileAsync(filePath);
// Debug.Log($"Audio file was saved to {filePath}.");
}
else if (result.Reason == ResultReason.Canceled)
{
var cancellation = SpeechSynthesisCancellationDetails.FromResult(result);
Debug.Log($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Debug.Log($" ErrorCode={cancellation.ErrorCode}");
Debug.Log($" ErrorDetails={cancellation.ErrorDetails}");
}
}
else
{
Debug.Log("Unknown error occurred.");
}
}
}
Unityでのコード
```c#
using System;
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using Microsoft.CognitiveServices.Speech;
using System.Threading.Tasks;
using System.Threading;
using UnityEngine.Events;
public class TextToSpeechService : MonoBehaviour
{
public AudioSource audioSource;
static string speechKey = "YOUR_API_KYE";
static string serviceRegion = "YOUR_INSTANCE";
static Uri endpoint = new Uri("YOUR_ENDPOINT");
private const int SampleRate = 24000;
SpeechConfig config;
private SpeechSynthesizer synthesizer;
private void Start()
{
audioSource = audioSource == null ? GetComponent<AudioSource>() : audioSource;
config = SpeechConfig.FromEndpoint(endpoint, speechKey);
config.SpeechRecognitionLanguage = "ja-JP";
config.SpeechSynthesisLanguage = "ja-JP";
config.SpeechSynthesisVoiceName = "ja-JP-NanamiNeural";
config.SetSpeechSynthesisOutputFormat(SpeechSynthesisOutputFormat.Riff24Khz16BitMonoPcm);
synthesizer = new SpeechSynthesizer(config, null);
synthesizer.SynthesisCanceled += (s, e) =>
{
var cancellation = SpeechSynthesisCancellationDetails.FromResult(e.Result);
Debug.LogError(
$"CANCELED:\nReason=[{cancellation.Reason}]\nErrorDetails=[{cancellation.ErrorDetails}]\nDid you update the subscription info?");
};
}
public async void Speak(string text)
{
try
{
using var result = await synthesizer.SpeakTextAsync(text);
if (result.Reason == ResultReason.SynthesizingAudioCompleted)
{
Debug.Log("Synthesis completed.");
var audioDataStream = AudioDataStream.FromResult(result);
var filePath = Application.dataPath + "/Audio/" + text + ".wav";
await audioDataStream.SaveToWaveFileAsync(filePath);
Debug.Log($"Audio file was saved to {filePath}.");
if (!audioDataStream
.CanReadData(4092 * 2)) // audio clip requires 4096 samples before it's ready to play
{
return;
}
// Audio clipに変換
var audioClip = AudioClip.Create(
"Speech",
SampleRate * 600, // Can speak 10mins audio as maximum
1,
SampleRate,
true,
(float[] audioChunk) =>
{
var chunkSize = audioChunk.Length;
var audioChunkBytes = new byte[chunkSize * 2];
var readBytes = audioDataStream.ReadData(audioChunkBytes);
for (int i = 0; i < chunkSize; ++i)
{
if (i < readBytes / 2)
{
audioChunk[i] = (short)(audioChunkBytes[i * 2 + 1] << 8 | audioChunkBytes[i * 2]) /
32768.0F;
}
else
{
audioChunk[i] = 0.0f;
}
}
if (readBytes == 0)
{
Thread.Sleep(200); // Leave some time for the audioSource to finish playback
audioSourceNeedStop = true;
}
});
audioClip.name = "DynamicClip";
audioSource.clip = audioClip;
audioSource.Play();
}
else if (result.Reason == ResultReason.Canceled)
{
var cancellation = SpeechSynthesisCancellationDetails.FromResult(result);
Debug.Log($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Debug.Log($" ErrorCode={cancellation.ErrorCode}");
Debug.Log($" ErrorDetails={cancellation.ErrorDetails}");
}
}
else
{
Debug.Log("Unknown error occurred.");
}
result.Dispose();
}
catch (Exception e)
{
Debug.LogError(e.ToString());
throw;
}
}
private void OnDestroy()
{
synthesizer.Dispose();
}
}
```
詳細
APIキーを取得する
APIキーの取得方法はこの記事を参考にしてください。
サービスのOverviewに行くと、KEYやエンドポイントが見れます
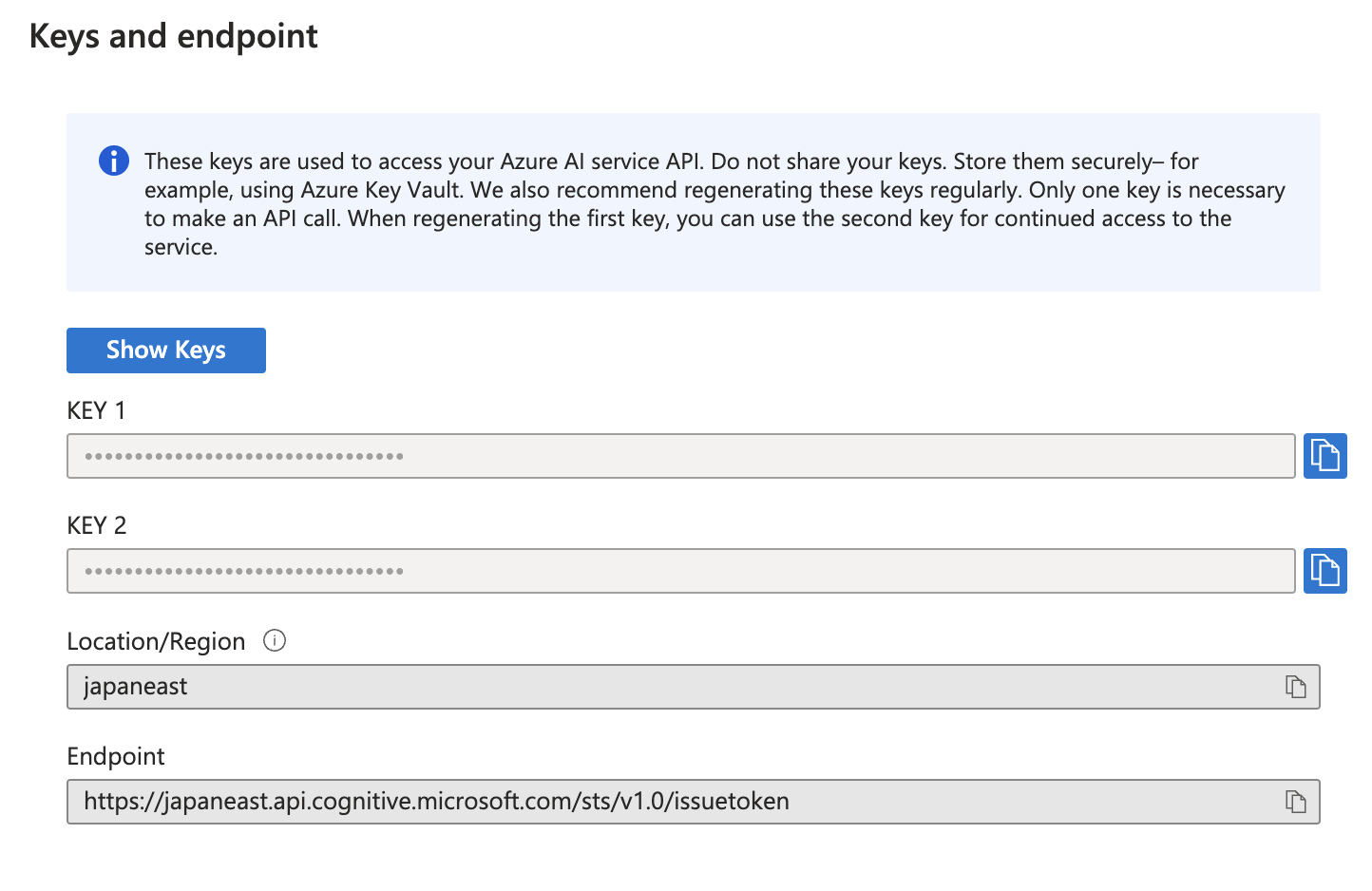
コンフィグを設定
まず、コンフィグを設定します。
SpeechConfig config;
// エンドポイントとサブスクリプションキーをセット
config = SpeechConfig.FromEndpoint(endpoint,speechKey);
// 喋らせたい言語を設定
config.SpeechSynthesisLanguage = "ja-JP";
// 声の種類を設定
config.SpeechSynthesisVoiceName = "ja-JP-NanamiNeural";
// フォーマットを選択
config.SetSpeechSynthesisOutputFormat(SpeechSynthesisOutputFormat.Riff24Khz16BitMonoPcm);
// インスタンス化
synthesizer = new SpeechSynthesizer(config, null);
// エラーハンドリング
synthesizer.SynthesisCanceled += (s, e) =>
{
var cancellation = SpeechSynthesisCancellationDetails.FromResult(e.Result);
Debug.LogError(
$"CANCELED:\nReason=[{cancellation.Reason}]\nErrorDetails=[{cancellation.ErrorDetails}]\nDid you update the subscription info?");
};
声の種類
声の種類は日本語だと、7種類あります。リンクに飛ぶとサンプルが聞けます。
ja-JP-NanamiNeural (Female)
ja-JP-KeitaNeural (Male)
ja-JP-AoiNeural (Female)
ja-JP-DaichiNeural (Male)
ja-JP-MayuNeural (Female)
ja-JP-NaokiNeural (Male)
ja-JP-ShioriNeural (Female)
その他の言語は公式リファレンスを確認してください。これによると、専用のMarkup Languageを使うと、声の調整や感情表現ができるらしいです。
喋らせる
SpeakTextAsyncで音声の変換を開始します。
Result.audiodDataは、byte列での音声データなので、それらを変換して使ってください。今回は、AudioDataStream.FromResultを使い、Byteデータ列をWavファイルに変換して、保存をしてます。
また、Resultには通信の状況も入っているので、それでエラーハンドリングします。
// 音声認識を開始
using var result = await synthesizer.SpeakTextAsync(text);
if (result.Reason == ResultReason.SynthesizingAudioCompleted)
{
Debug.Log("Synthesis completed.");
var audioDataStream = AudioDataStream.FromResult(result);
var filePath = Application.dataPath + "/Audio/" + speechText + ".wav";
await audioDataStream.SaveToWaveFileAsync(filePath);
Debug.Log($"Audio file was saved to {filePath}.");
}
else if (result.Reason == ResultReason.Canceled)
{
var cancellation = SpeechSynthesisCancellationDetails.FromResult(result);
Debug.Log($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Debug.Log($" ErrorCode={cancellation.ErrorCode}");
Debug.Log($" ErrorDetails={cancellation.ErrorDetails}");
}
}
else
{
Debug.Log("Unknown error occurred.");
}
遭遇したエラー
dylibがMacにブロックされて動かない事態が発生しました。
設定→Security & Privacy→セキュリティの欄に未知のアプリがあるが許可するかどうかあるので、許可を選択して実行できるようになります。
公式リファレンス
.NETの名前空間
なお、使い方は載っていないので、どう実装するかはわからない模様
ここには少しばかりのチュートリルが載ってます
もしかしたら、公式のGithubが一番参考になるかも