tl;dr
学部4年になり忙しくなるので、よりすべてを「自動化」しようと思いました。
記事が長くなってしまうので詳細はブログでご覧ください。
最近自分が考案した 宣言的継続的デリバリー(Declartive Continuous Delivery) を紹介させていただきます。
従来の継続的デリバリーにDeploy戦略も含めて宣言的に書くソフトウェア手法を考えました。
記事のざっくりとして内容は
- マイクロサービスを継続的デリバリーことができるspinnakerを宣言的に構築する
- まるでCircleCIの設定ファイルのような
config.ymlを配置するだけでspinnakerのパイプラインを走らせることができる。- 既存の環境への親和性が高い
- 「それぞれの設定がそれぞれのアプリケーションへ帰属」というわかりやすさ
- templateは一括でrepoでモジュール化して管理しよう
- 組織の財産となる
- templateとアプリケーションを分離することで管理しやすい
- 再利用性
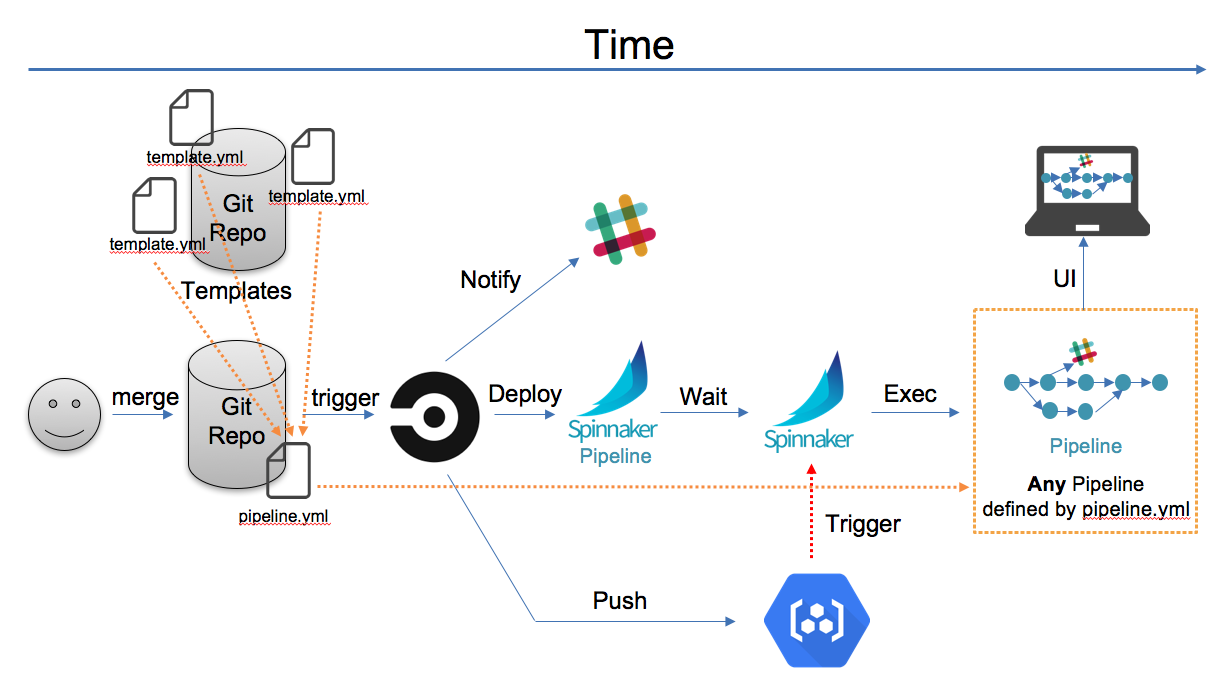
です。設計したDCDフローは以下の通りです。
解説は記事を読んでください。
設計思想や「宣言的とは何か」などもブログでは取り上げています。
対象とする読者
- デプロイが大きな負担となっているひと
- 自動化が大好きな人
- Kubernetesなどでマイクロサービスを運用していて、さらにDeployサイクルをあげたい人
- カナリアデプロイ、ブルー・グリーンデプロイを自動的にやりたい人
解決する問題
1.kubernetesのDeploy問題
kubernetesは非常に機能が多く、マイクロサービスを導入しやすくして、よりアジャイルな開発へのパラダイムシフトを促したソフトです。
manifestファイルと呼ばれる、どのロードバランサーに何を繋げて、どのくらいのVMで、、、といったようなことがすべて宣言的に書けて、Deployするにはapplyコマンドを叩くだけです。

しかしながら、Deployが毎日数回など行われるときにapplyコマンドを叩くのは面倒です。
現状として、Botを使ってSlack越しでDeployしたり、CIに任せて要るケースがほとんどです。
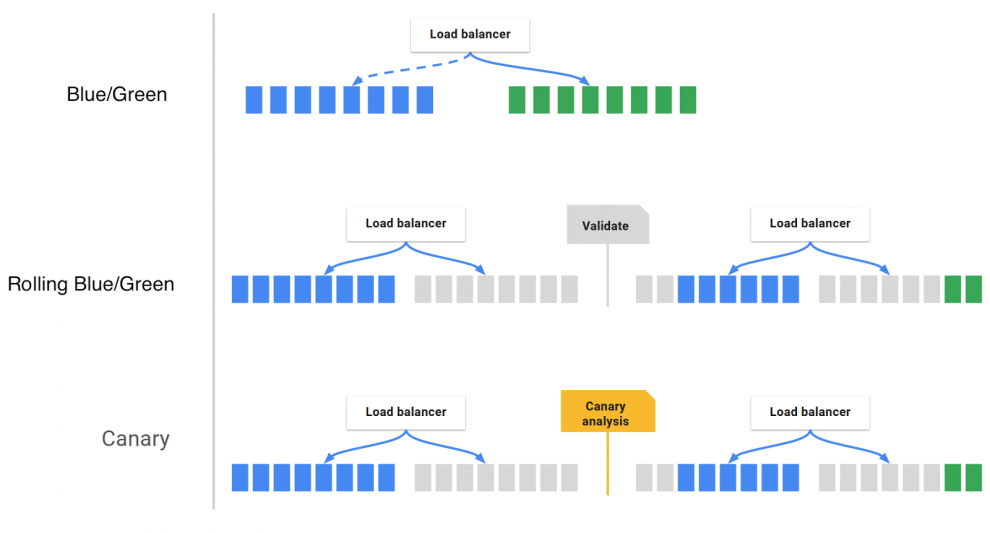
2.Deploy戦略の難しさ
Deployとは単純な作業ではなくて、実際にはデプロイ後に変な挙動をしていないか、他のマイクロサービスとうまく連携が取れて要るかなど、確認することが膨大にあります。
- Blue/Green Deployment
- Canary Deployment
- Rollbackが安全にできるか
- ビジネスモデルとの連携
- ...
これらをメンテしていくのは難しく、よくチームに「インフラエンジニア」や「SRE」などと肩書きがつくエンジニアが面倒見たりしています。
3.インフラエンジニアを導入する盲点
インフラに関するタスクがヘビーならインフラ専門のエンジニアをおけばいいじゃん!
って考えるかもしれません。
確かにインフラには専門的な知識や経験が必要で、膨大なドキュメントを読まないといけません。
https://www.youtube.com/watch?v=LVgP63BkhKQ
確かにインフラにマジつよエンジニアがいればその人に任せることができます。
実際、どの会社もそのような形態を取っていることが多く、採用でもコースが分かれているほどです。
しかしながら、一人に任せるのにはデメリットがあり、
- インフラで起きることのフィードバックをその他のエンジニアに還元できない
- 責任がインフラエンジニアだけに生じる
- 本来の企業としての価値は生んでいない
- ...
のようなことが挙げられます。
Spinnakerとは
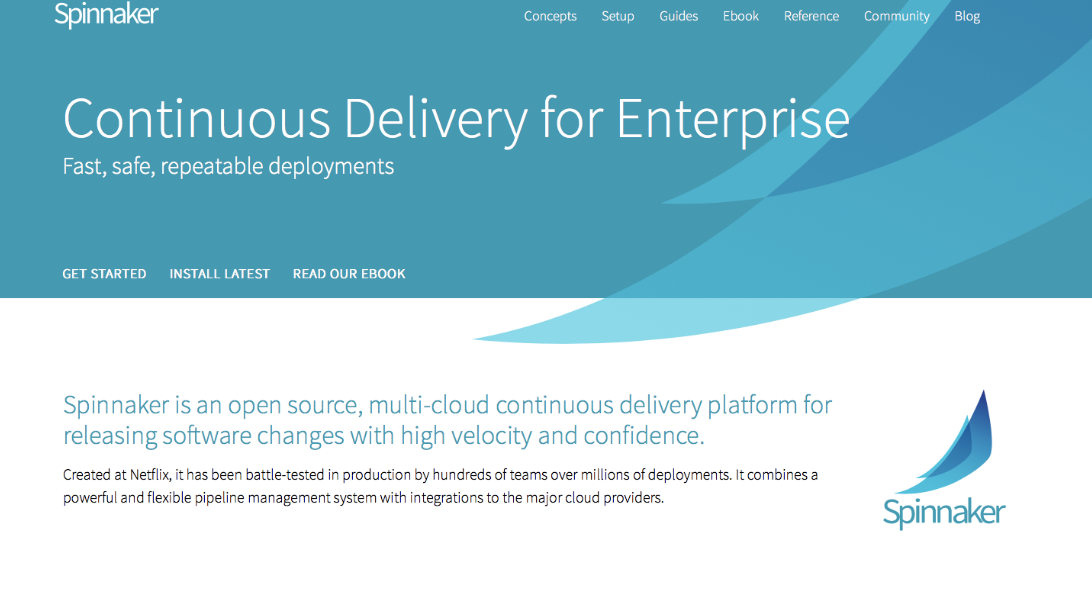
Spinnakerとは継続的デリバリーを容易に導入しやくするソフトウェアで
- 高度なUIで設定、フィードバック
- 自動デプロイ機能を搭載している
- ヘキサゴナルアーキテクチャ(GCP,AWSなどに関わらす使える)
- Immutable Infrastructureを強制できる
のような特徴があり、現在のDeploy問題を解決します。
以下のようなメリットをもたらします。
- UIや通知でエンジニアにフィードバック
- ソースを更新したエンジニアに直接還元
- PodやServiceなども監視することができる
- プロジェクト単位で管理できる
しかしGUIでぽちぽちするのでMutableなのです。
新米エンジニアが設定するときにうたた寝をしてしまい、レプリカ数を1000にしてしまうかもしれません。
つまり宣言的にしないといけないのです。
宣言的Spinnakerの導入
コンセプト
重要なコンテプトとして以下のようなことを設計思想にいれました。
- 一つのアプリにはひとつの設定を
- 初期設定以外は何も意識しなくていい世界
- 一般的なCI、CDをいじらなくて済むように
- 直感的にわかりやすいもの
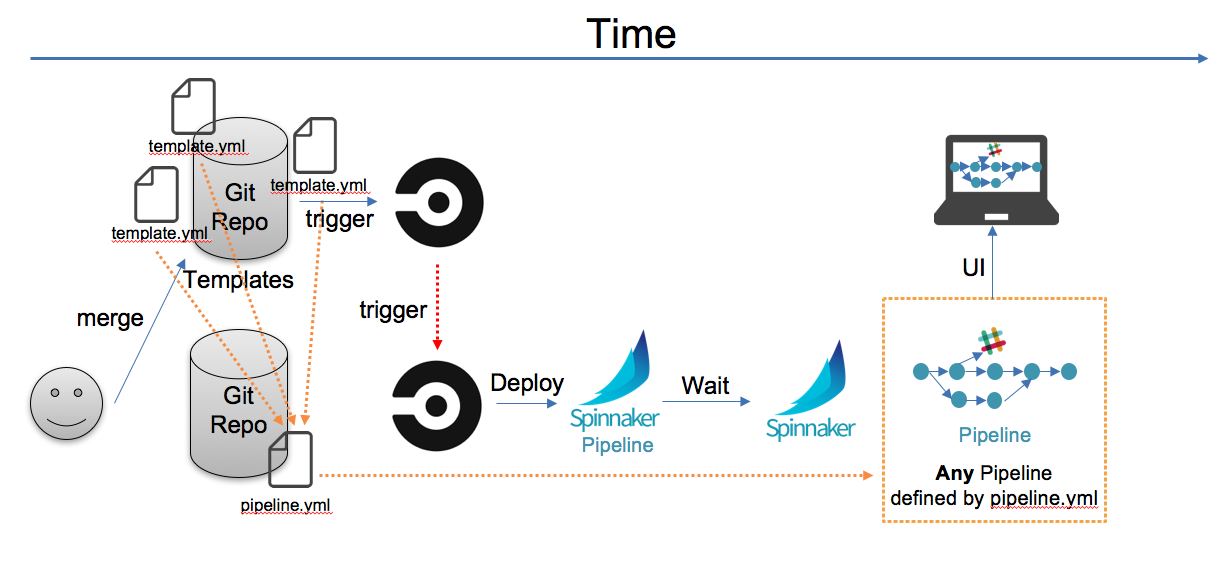
設計したフロー
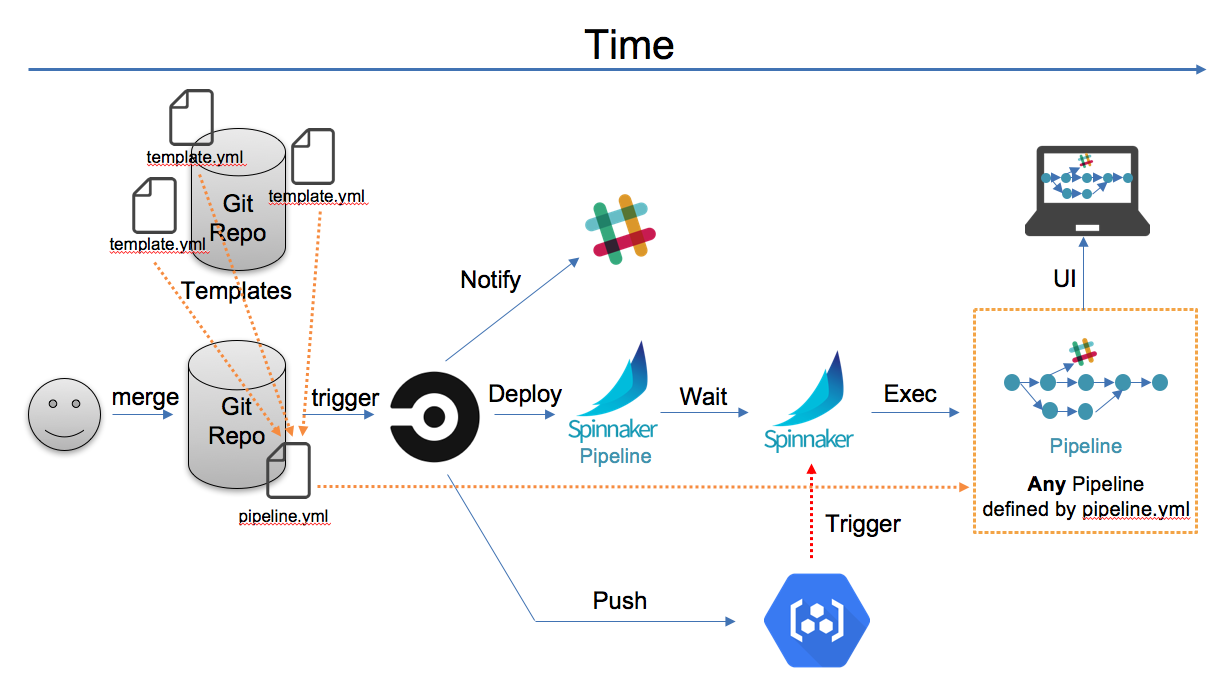
簡単に説明すると
- アプリ固有のパイプライン設定ファイルを配置
- mergeされるとパイプライン設定ファイルと、使用するテンプレートを参照しspinnakerにデプロイ
- GCRにアプリのコンテナpush
- パイプラインがトリガーされて、パイプラインが走る
- カナリアデプロイができて、デプロイ環境は設定ファイルから読み取る
メリット
- アプリに書いた設定(例:
.spinnaker/config.yml)が宣言的であり、それ以外はいじれない - 宣言的継続的デリバリーの中では直感的にわかりやすい
- 従来のプロジェクトとの親和性
- CIはそのまま、パイプラインデプロイ(curl経由で可能)、GCRプッシュくらい
- もう取り入れて要る可能性が高い
- それ以外はいじらなくていい
- CIはそのまま、パイプラインデプロイ(curl経由で可能)、GCRプッシュくらい
今回作るもの
ngnixサーバーを更新すると、CircleCIがテストをして、カナリアデプロイして、SlackにWebhookを送るパイプライン
実際のプロジェクト
githubリポジトリをアプリケーションとテンプレートの二つに分けています。
- テンプレート側
テンプレートを保存してあるリポジトリのファイル構成です。
$ tree keke-template/
.
└── templates
└── AtomicCanaryWithoutWebhook
└── template.yml
template.ymlにSpinnakerのUIに1対1対応するように記述します。
- アプリケーション側
実際のRailsやGolang Serverなどのアプリケーションのファイル構成です。
余計なもの(READMEやgitignoreなど)は省略させていただいてます。
$ tree keke-app/
.
├── .circleci
│ └── config.yml
├── .spinnaker
│ └── value.yml
├── app
├── Dockerfile
└── default.conf
今回、Spinnakerの設定ファイルは.spinnaker/value.ymlに定義し、以下のようになっています。
schema: "1"
pipeline:
application: Demo
name: Atomic Canary Deployment
template:
source: [YOUR_TEMPLATE_PATH]
variables:
replicas: 2
loadbalancer: nginx-keke
slackWebhookURL: [YOUR_SLACK_URL]
Demo
1. アプリケーションを更新したとき
nginxを更新するとCircleCIが走ります。
Jobはこのようになっています。
- test
- pipelineをデプロイ
-
nginx/Dockerfileでイメージを作ってGCRにpushする

二番目の手順であるpipelineのデプロイはSpinnakerで確認できます。
三番目のジョブはGCRにプッシュすることです。
pipelineはできていました。
GCRにpushされるとパイプラインが実行されてカナリアデプロイの完了です。
これを実際にやってみます。
まず、アプリケーションは作ったものの、何もpipelineが定義されていない状態からスタートです。
コードを更新して、githubにpushします

そしてPull requestを作成してmergeをするとします。
するとCircleCIでworkflowが走ります。
testジョブが走りましたが、何も変化がありません。

testが無事に終わって、Spinnakerにpipelineをデプロイさせるジョブが走っています。

完了しました。

成功しました。するとSpinnaker上では
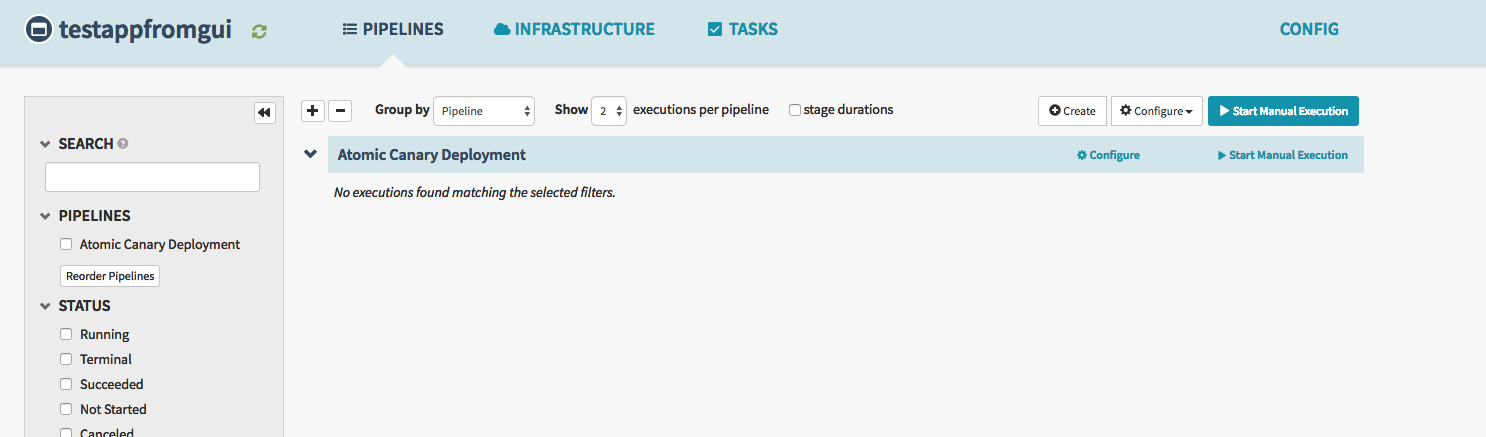
とpipelineができており、もちろん宣言的に書いたので一切いじれないパイプラインができています。
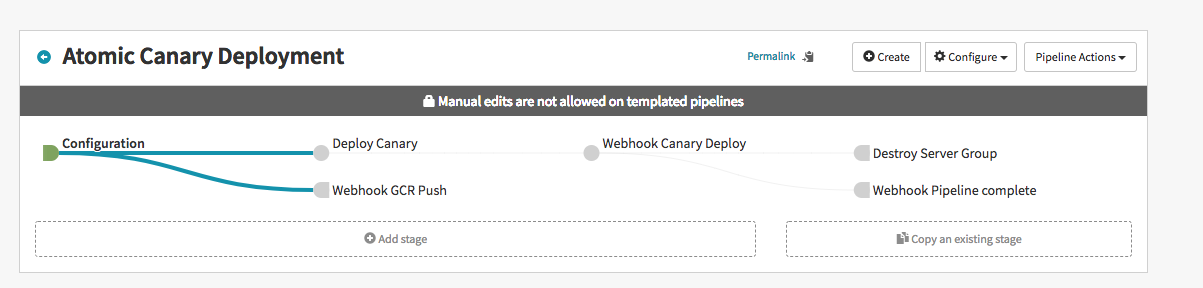
あとはGCRにイメージがpushされて、パイプラインが実行されるといういつも通りです。

1.1 まとめ
アプリケーション(Rails、Golang,Node.jsなど)を更新すると、.spinnaker/config.ymlを定義するだけで宣言的パイプラインで実行することができる。
(注)宣言的Spinnakerの設定ファイルである.spinnaker/config.ymlなどのパスは任意です。
Webhookを設定しているので、Slackには以下のような通知が来ます。

2. tempateが更新されたとき
リポジトリを分けているからtemplateが更新されたときに、どうなるの?
って思う方が要ると思いますが、こちらも対応しています。
具体的にはtemplateがmergeされるとpipelineそのものを新テンプレートで更新しなおす、ということをします。
試しに変数を追加してmergeします。
今回は以下のようなnewVariablesForDemoという変数を追加しました。

CircleCI以下のようなWorkflowになっています。

最初にtestジョブが走って、これ自体はpipeline-template自体をバリデーションしています。
テストが完了すると、publishジョブが実行されテンプレートが更新されます。

次に古いバージョンのテンプレートを使用しているものを新しく更新しないといけません。これを担うのはsyncです。

このジョブが終わるとCircleCI APIを通してアプリケーション側のWorkflowのSpinnakerのPipelineをビルドしなおし、新しいテンプレートを用いてパイプラインをデプロイしなおします。

完了しました。するとアプリケーション側でまたビルドが走っているのです。

これによって最新テンプレートがすぐ反映されることになります。
確認用にGUIからtemplateを利用してみると
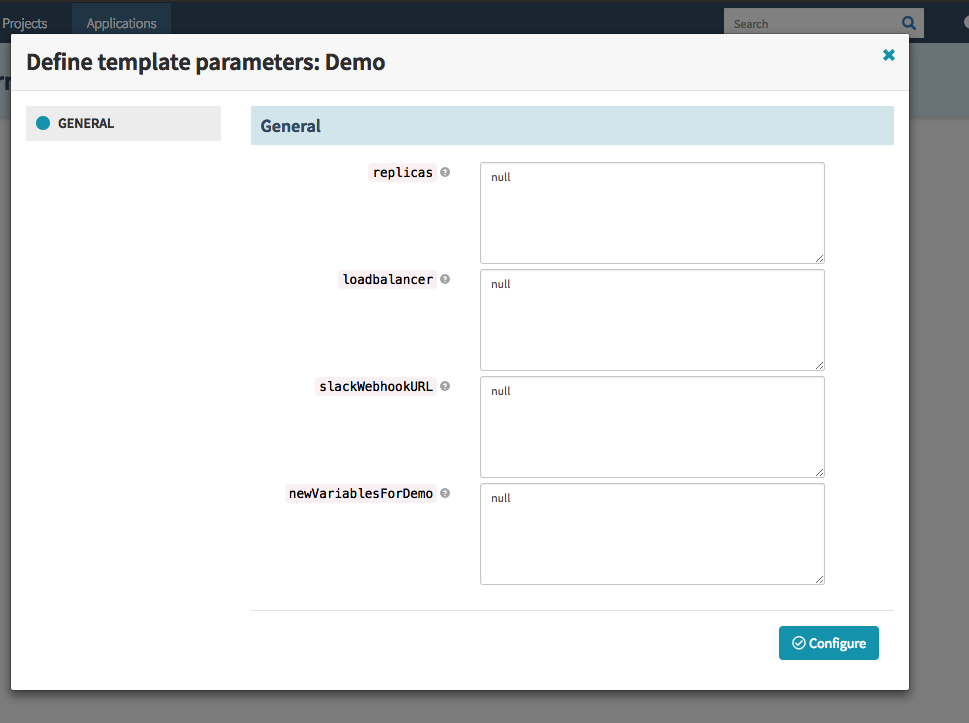
と新しいtemplateができていることがわかります。
もちろん、これをしなくてもアプリケーション自体の更新があれば新しいテンプレートは反映されますが、template merge時とアプリで使っているテンプレートが異なるということは、カオスな環境をうむので即座に反映させようと思いました。
2.1 まとめ
別repositoryで管理しているtemplate自体もうまくすればアプリケーション側と連携を取ることができ、すぐ反映することができます。
これによってテンプレート自体も、エンジニアにフィードバックをもたらすことができます。
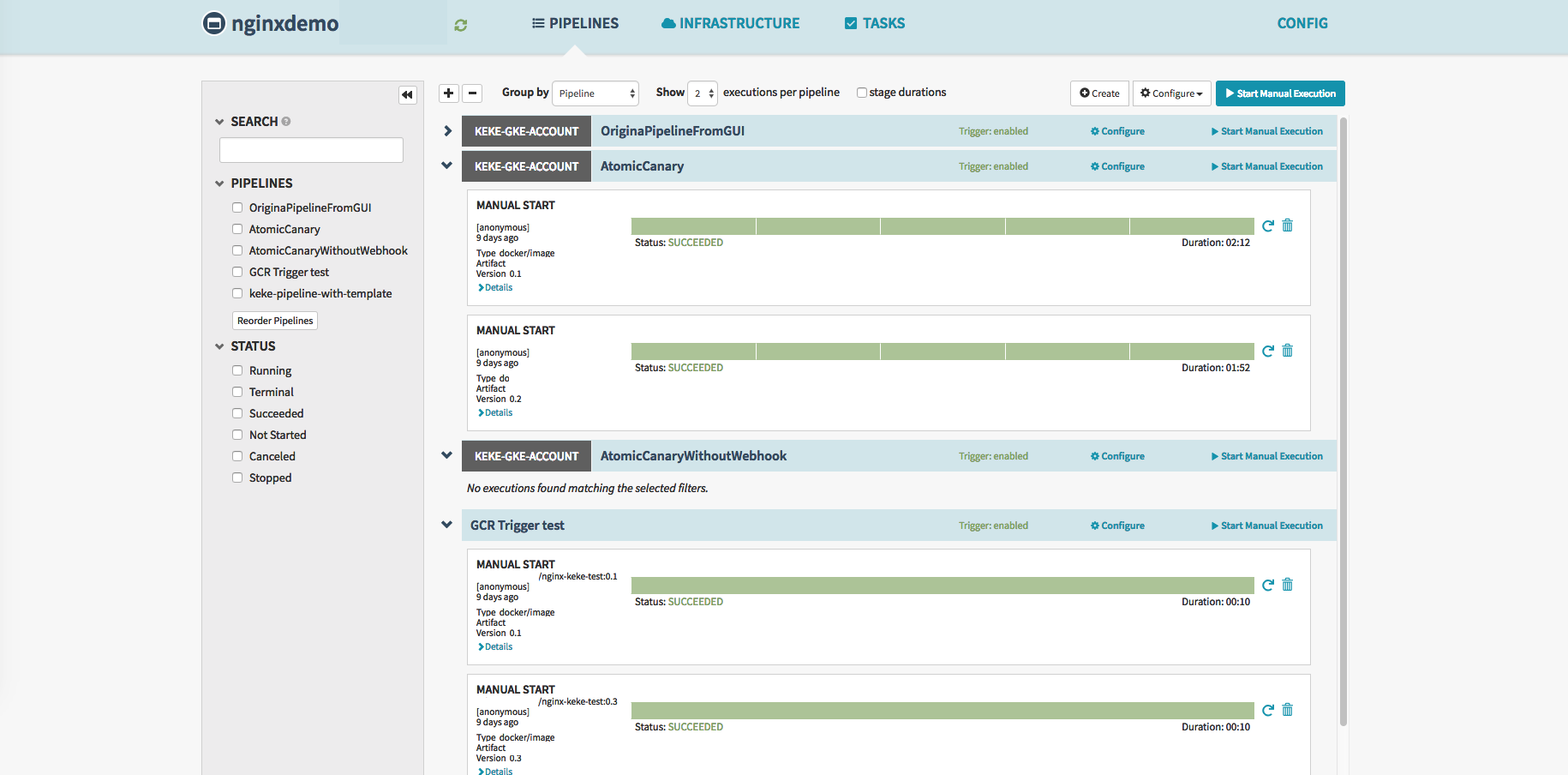
3. フィードバックも豊富です
サーバーサイドエンジニアなどでも容易に「どのようなパイプラインでデプロイされたのか」や「カナリアデプロイがなんで失敗したか」などを知ることができます。
追記
Circle CIがWorkflowでAuto Cancelling Redundant Buildをサポートしました。 これによって、よりパイプラインや、DCDを含むアプリケーションがデプロイしやすくなります。

最後に
これまでは宣言的継続的デリバリー(DCD)を実現すると理論的にはハッピーと周知されているものの、どのようすればよいのかが明白ではなかったです。
しかし、Spinnakerやkubernetesなどが登場し、継続的デリバリーが容易にできるようになった今、それを宣言的にするというパラダイムが到来することは自明でした。
今回挑戦してみて、CircleCIやTravis、JenkinsなどのCI手法を参考にしつつ、かなりよいDCDを考えつくことができたのではないかと思っています。
コメントやコメントなど質問・雑談・感想お待ちしています。
各種フォローよろしくお願いします!