0. 初めに(対象読者など)
釣りタイトルです。すみません。
本当は、過去1世紀の間に日本で出回ったすべての 「699 テレビ・ラジオ」に分類される本のデータベースを作ります。
また、 国会国立図書館のサーバへの自動アクセスを大量に行うこととなるので、くれぐれも自己責任でお願いします。
対象読者
- 国会国立図書館サーチを(API使わずに)自動で行いたい人
- javaがある程度できる人
- privateメソッドで怒らない人
- 自己責任を理解できる、精神的に大人の方(極稀に、これに残念ながら該当しない社会ガク者の方がいます)
1. 実験
国会国立図書館サーチで詳細検索し、分類記号「699」だけを条件に検索すると、
1925年~2020年の、テレビやラジオに関する本をすべて検索することができる。
しかし、誠に残念ながら、一回の検索で見ることができるのは、上位500件の結果のみである。(501件目以降は、そもそも検索結果に表示されない)
また、出版年で絞り込み検索を行うことができるが、1925年~2020年のどの年においても、(1年で)結果が500件を超えることはなかった。
そこで、すべての年ごとに、検索をかけて、その結果をとってくれば、手間はかかるが、すべての結果を見ることを試みよう。
1-1. 実験1 ndlクローラの設計
クローラとは、webから情報を集めてくるプログラムのことである。
国会国立図書館サーチから情報を集めてくるプログラムを「ndlクローラ」と呼ぶことにして、これを設計していこう。
次のような手順で設計できる。
- ブラウザから国会国立図書館サーチを利用
- 詳細検索における各項目をすべて英数字で入力し、検索を実行
- getパラメータと比較することで、どの項目がどのパラメータに対応しているか確認
- 3までで得られたヒントをもとに、プログラムを設計
1-1-1. 手順1~3
まず、図1.1.1.1 の条件で検索したところ、検索結果(サムネイル表示)のurlは次のようになった。
https://iss.ndl.go.jp/books?datefrom=1234&place=place&rft.isbn=isbn&rft.title=title&dateto=5678&rft.au=author&subject=subject&do_remote_search=true&rft.pub=publisher&display=thumbnail&ndc=genre&search_mode=advanced
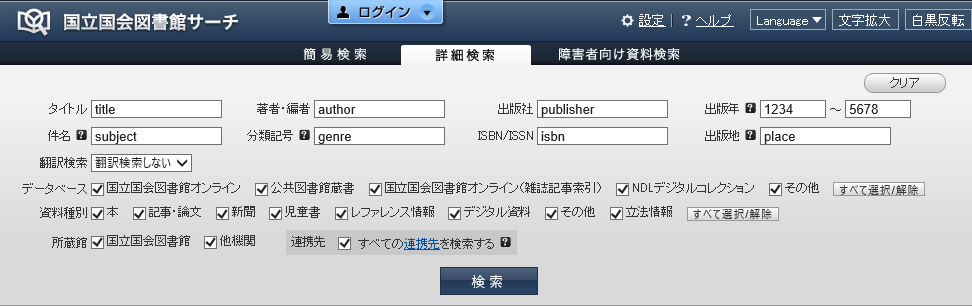
図1.1.1.1 urlパラメータ観察用の検索条件
比較すると、表1.1.1.1の通りのことが分かる。(但し、「結果のページ番号」だけは、別の試行で確認した。)
表1.1.1.1 国会国立図書館サーチのurlパラメータ
| 項目 | パラメータ | 値 |
|---|---|---|
| タイトル | rft.title | |
| 著者・編者 | rft.au | |
| 出版社 | rft.pub | |
| 出版年区間始点 | datefrom | |
| 出版年区間終点 | dateto | |
| 件名 | subject | |
| 分類記号 | ndc | |
| ISBN/ISSN | rft.isbn | |
| 出版地 | place | |
| 結果のページ番号 | page | |
| 結果をサムネイル表示 | display | thumbnail |
| そのほか一応つけておく1/2 | do_remote_search | true |
| そのほか一応つけておく2/2 | search_mode | advance |
1-1-2. 手順4(クローラの設計)
javaパッケージndlを作り、その中に次のようなNDLCrawler.javaを作る。
(コード中に出てくるParserクラスについては1-1-3節で述べる。
簡潔に述べると、コンストラクタに渡された結果ページの内容をparse()メソッドでcsvに成型する。
has15()メソッドは、結果が15件であるかの真偽値を返す。)
(コード中に出てくるWebGetterクラスは、getメソッドでインターネット上からhtmlソースをとってくるだけのものである)
package ndl;
import java.io.*;
import java.net.*;
public class NDLCrawler
{
private String url = "https://iss.ndl.go.jp/books?",
title="", author="", publisher="", yearfrom="",yearto="", subject="", bunrui="", isbn_issn="", place="";
public void setTitle(String str){title=str;} public void setAuthor(String str){author=str;} public void setPublisher(String str){publisher=str;} public void setYearfrom(String str){yearfrom=str;} public void setYearto(String str){yearto=str;} public void setSubject(String str){subject=str;} public void setBunrui(String str){bunrui=str;} public void setIsbn_issn(String str){isbn_issn=str;} public void setPlace(String str){place=str;}
public String crawle()
{
System.out.println(" クローラ起動");
String csv="";
String urlWithGet = url+ "rft.title=" + title + "&rft.au=" + author + "&rft.pub=" + publisher + "&datefrom=" + yearfrom + "&dateto=" + yearto + "&subject=" + subject + "&ndc=" + bunrui + "&rft.isbn=" + isbn_issn + "&place=" + place;
urlWithGet = urlWithGet + "&do_remote_search=true&display=thumbnail&search_mode=advanced";
System.out.println(" url:"+urlWithGet+"&page=(ページ番号)");
WebGetter wg = new WebGetter();
try {
for(int page=1; page<=34; page++)
{
System.out.println(" "+page+"ページ目");
String source = wg.get(urlWithGet+"&page="+page);
Parser p = new Parser(source, false);
csv = csv + p.parse().replaceFirst("^(\r\n|\r|\n)", "");
if(!p.has15()) break;
}
System.out.println(" クローラ終了");
return csv;
} catch (IOException e) {e.printStackTrace();return null;}
}
}
WebGetterクラスは次のようになる。(NDLCrawler.javaの後ろに追記する)
/**
*
* 参考サイト:https://www.javalife.jp/2018/04/25/java-%E3%82%A4%E3%83%B3%E3%82%BF%E3%83%BC%E3%83%8D%E3%83%83%E3%83%88%E3%81%AE%E3%82%B5%E3%82%A4%E3%83%88%E3%81%8B%E3%82%89html%E3%82%92%E5%8F%96%E5%BE%97%E3%81%99%E3%82%8B/
*
*/
class WebGetter
{
String get(String url) throws MalformedURLException, IOException
{
InputStream is = null; InputStreamReader isr = null; BufferedReader br = null;
try {
URLConnection conn = new URL(url).openConnection();
is = conn.getInputStream();
isr = new InputStreamReader(is);
br = new BufferedReader(isr);
String line, source="";
while((line = br.readLine()) != null)
source=source+line+"\r\n";
return source;
}finally {br.close();isr.close();is.close();}
}
}
1-1-3. 手順4(結果ページのソース(html)からcsvを作る)
「国会国立図書館サーチ」における検索結果のhtmlソースについて、次のような法則を発見した。
-
<a href="https://iss.ndl.go.jp/books/(英数字とハイフンから成る書籍のID)">(文字列1)の直後には必ず書籍のタイトルが来る。逆も各書籍について最低1回は成立する。 - 各書籍について最低一回は、タイトルの直後に
</a>(改行)(ホワイトスペース)+</h3>(改行)(ホワイトスペース)+<p>(改行)(ホワイトスペース)+が来る。これを文字列2と呼ぼう。 - 「文字列1、書籍のタイトル、文字列2」の直後には必ず
(著者名)/.*(,(著者名)/.*)*(文字列3)が来る。 - 「文字列1、書籍のタイトル、文字列2~3」の最終行の2行後に出版者名、3行後に発行年、4行後にシリーズ名が来る。欠損情報がある場合は空値が入り、行が飛ばされることはない。
この法則(および若干の例外)に則って書籍のタイトルを並べたcsvファイルを作るjavaプログラムを作ると次のようになる。
(htmlソースをcsvに変換する処理をParseと呼ぶことにしている。)
package ndl;
public class Parser
{
private boolean has15;
private String csv;
Parser(String source, boolean needHeader)
{
this.csv=needHeader?"国立国会図書館リンク,タイトル,著者,出版者,年,シリーズ\n":"\n";
String[] books = divide(source);//「<a href="https://iss.ndl.go.jp/books/」で区切る
books = remove0(books);//先頭だけ無意味なデータなので切り落とす
has15 = books.length==15;//デフォルトで、検索結果の件数は1ページあたり15件
String link, title, publisher, year, series;
String[] authors;
for(String book : books)//それぞれの書籍について
{
book = book.replaceAll("((\r\n)|\r|\n)( |\t)*<span style=\"font-weight:normal;\">[^<]+</span>","");//シリーズもので番号が振られている場合、その情報をカットすることで「法則」に当てはめることができる。
link = getLink(book).replaceAll(",", "、");
title = getTitle(book).replaceAll(",", "、");
authors = getAuthors(book);
publisher = getPublisher(book).replaceAll(",", "、");
year = getYear(book).replaceAll(",", "、");
series = getSeries(book).replaceAll(",", "、");//詳細情報を抽出して
for(String author : authors)//csvに変換
csv = csv + link+","+title+","+author.replaceAll(",", "、")+","+publisher+","+year+","+series+"\n";
}
}
public boolean has15(){return has15;}
public String parse() {return csv;}
//本当はよくないprivateメソッドたち
private String[] divide(String source){return source.split("<a href=\"https://iss\\.ndl\\.go\\.jp/books/", -1);}
private String[] remove0(String[] before)
{
String[] after = new String[before.length-1];
for(int i=1; i<before.length; i++)after[i-1]=before[i];
return after;
}
private String getLink(String book){return "https://iss.ndl.go.jp/books/"+book.split("\"")[0];}//「"」で区切った0番目を返せばよい
private String getTitle(String book){return book.split("<|>")[1];}//「<」または「>」で区切った1番目を返せばよい
private String[] getAuthors(String book){return book.split("(\r\n)|\r|\n")[3].replaceFirst("( |\t)*", "").split("/([^,])+,?");}
private String getPublisher(String book){return book.split("(\r\n)|\r|\n")[5].replaceFirst("( |\t)*", "");}
private String getYear(String book){return book.split("(\r\n)|\r|\n")[6].replaceFirst("( |\t)*", "");}
private String getSeries(String book){return book.split("(\r\n)|\r|\n")[7].replaceFirst("( |\t)*", "");}
}
1-1-4. 手順4(クローラの制御)
1-1-2節で国会国立図書館サーチへアクセスするクローラのクラスを設計し、
1-1-3節でクローラのとってきた情報をもとにcsvを生成するクラスを実装した。
1-1-4節では、これらのクラスを利用してクローラを実際に制御するクラスを設計しよう。
制御内容としては、for文にて1925年~2020年それぞれを指定して、また分類番号は699を指定して、クローラを動作させ、出来上がったcsvをファイルに書き込めばよい。また、年数情報が分からないものについては「1900年」と扱われているようなので、これも考慮する。
package ndl;
import java.io.*;
public class Main
{
public static void main(String...args)
{
String header = "国立国会図書館リンク,タイトル,著者,出版者,年,シリーズ,図書館\n";
NDLCrawler c = new NDLCrawler();
c.setBunrui("699");
generateCsv(c);
}
private static void generateCsv(NDLCrawler c)
{
System.out.println(1900);
c.setYearfrom("1900");
c.setYearto("1900");
output(c.crawle());//末尾追記で書き込み
for(int year=1925; year<=2020; year++)
{
System.out.println(" "+year);
c.setYearfrom(""+year);
c.setYearto(""+year);
output(c.crawle());//末尾追記で書き込み
}
}
private static void output(String csv)
{
String path = "D:\\all699.csv";//パスは任意に変更のこと
System.out.println("出力"+csv);
try{
FileWriter fw = new FileWriter(path, true);//第2引数trueで末尾追記モード
fw.write(csv);
fw.close();
} catch (IOException e) {e.printStackTrace();}
}
}
2.結果
実験環境および条件は表2-1の通り
表2-1. 実験環境および条件
| 項目 | 値 |
|---|---|
| OS | windows10 |
| ソフト | Eclipse IDE for Enterprise Java Developers(4.11.0) |
| プロバイダおよび接続元 | Jupiter Telecommunication Co. Ltd (210.194.32.203) |
| プログラム起動日時(日本時間) | 2020年1月17日20時44分00秒 |
| プログラム停止時刻および動作期間,停止理由 | 2020年1月17日21時39分44秒 (約56分、正常終了) |
出力されたファイルall699.csv(githubへアップロードした)は12145行に及んだ。
また、実験後、ブラウザで国会国立図書館サーチへアクセスし、同じ条件で検索した結果における件数情報をみると12633件とあった。
件数に矛盾があるため、調べたところ、出版年情報として1900年及び、1925~2020年が与えられている書籍の合計は12030件であることが分かった。
これは12145件と比べて若干少ないが、「著者情報が複数ある時、行を分けて一人一行を割り当てる」としたParser.getAuthorsメソッドの仕様のためであると考えられる。
3.今後の展望
国会国立図書館サーチでは、国会国立図書館以外にも幾つかの地方図書館等の蔵書を検索することができる。
これを利用して、「どこにでも置いてある本」と「そうでない本」を分類するような研究にも応用できるのではないか興味があるので、これをやってみたい。