Self-attentionをざっくりいうと
論文はこちら
モチベーション:GANの性能の向上
何をやっているか:画像の大域的な依存関係を抽出している
成果:ImageNetのデータセットに対してIS:36.8→52.2、FID:27.62→18.65にスコアを伸ばした。
具体的な話
CNNは局所的な受容域を持つため、大域的な依存関係を学習するためには層を重ねる必要性が出てくる。しかし、層を重ねるにはコストがかかる。
またCNNの局所的な受容域が原因で奇妙な画像が生成されるといった問題も発生する。
(ex. 馬の写真を学習し生成するGANを訓練したときに、CNNの局所的な受容域が影響で、画像の全体的な頭の数が数えられず、頭が複数あるような馬の画像を生成してしまうような問題が発生している。)
そこで、画像全体の大局的な特徴量を加味しよう!
計算式を順に追っていこう
 ↑こちらがself-attention機構の全体図
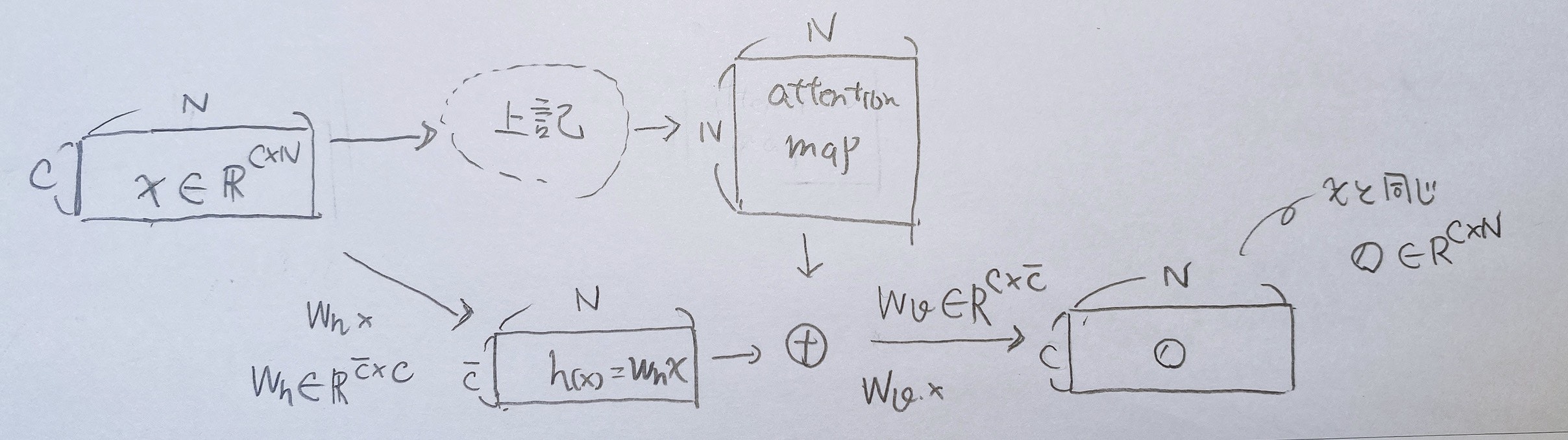
そして、attention map(上の図の白黒の図)までの計算式が以下。
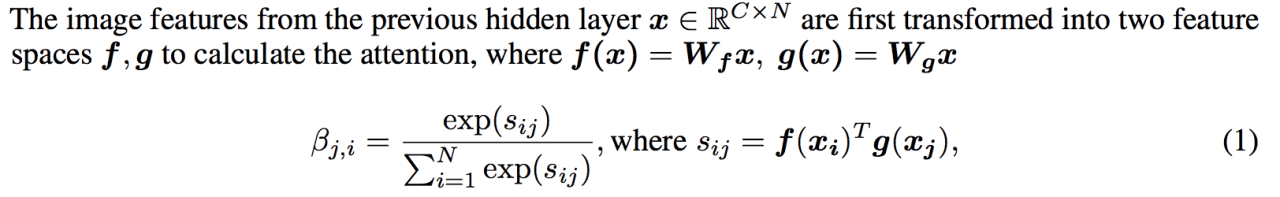
ここまでの計算をわかりやすく行列の図に表しました。
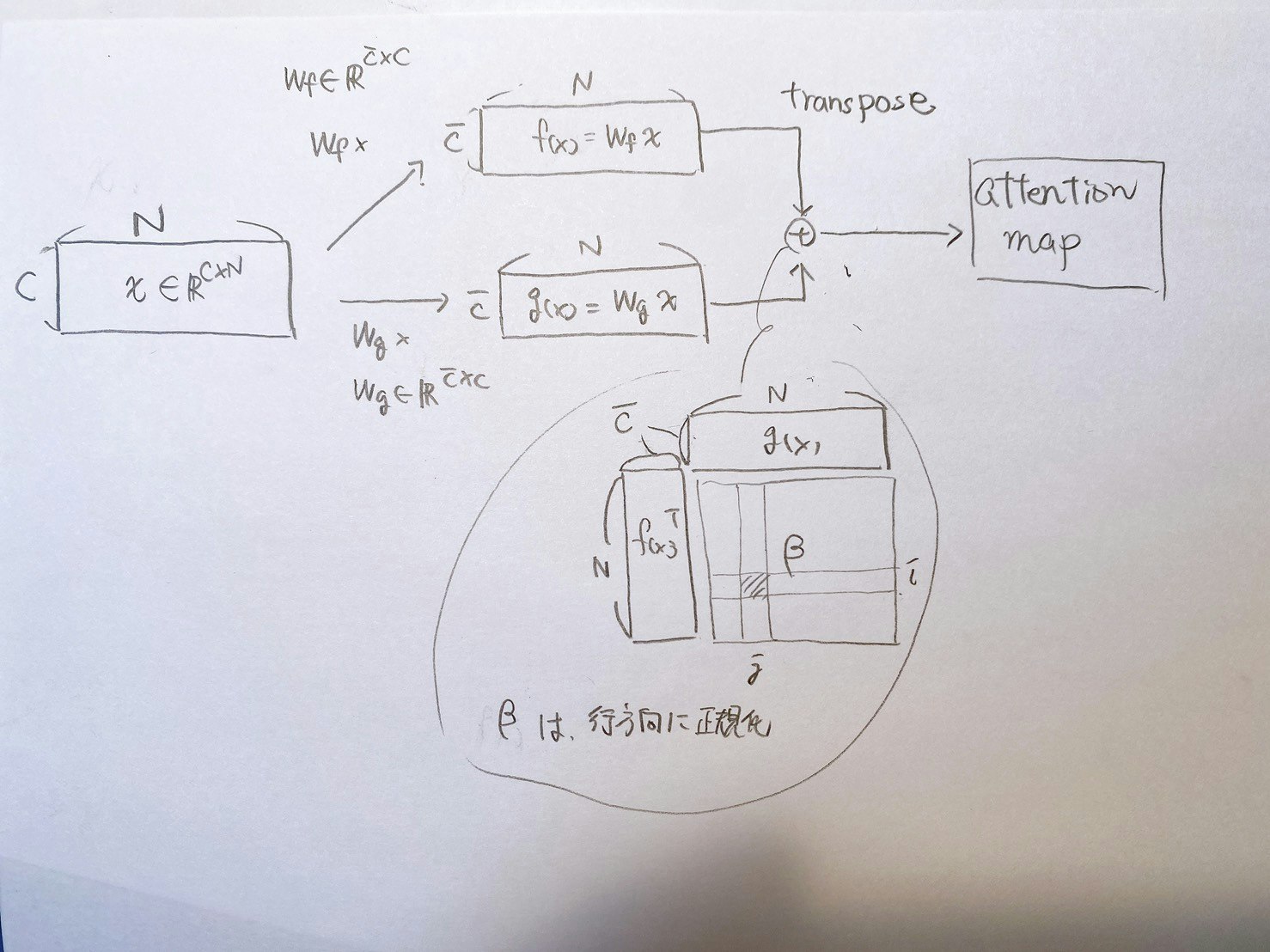
↓self-attention mapまでの行列計算を図で表すとは以下
↑こちらがself-attention機構の全体図
そして、attention map(上の図の白黒の図)までの計算式が以下。
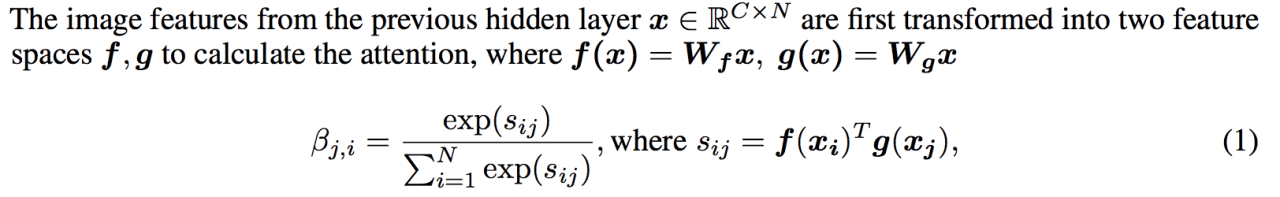
ここまでの計算をわかりやすく行列の図に表しました。
↓self-attention mapまでの行列計算を図で表すとは以下
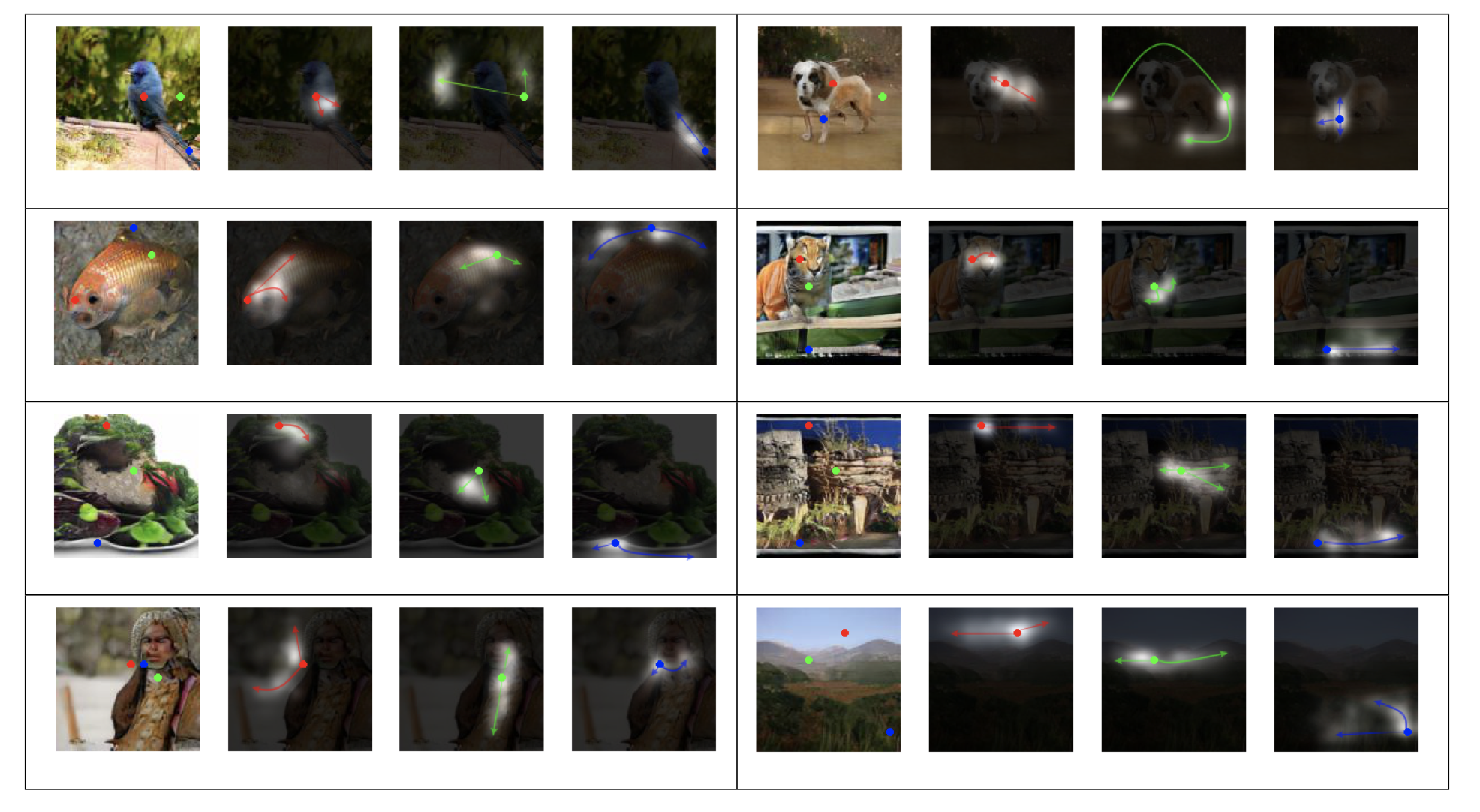
上の行列計算によって生成されたattention mapを可視化すると↓下の図のようになる。
写真内のある点に着目した時に、その点の色に近い領域が強く反応している。
(例えば、写真の赤い点に着目した時、その赤い点部分のいろと同じような色を持つ領域がattention mapにおいて白く反応している)
さらに、attention mapからself-attention feature mapを算出する式は以下
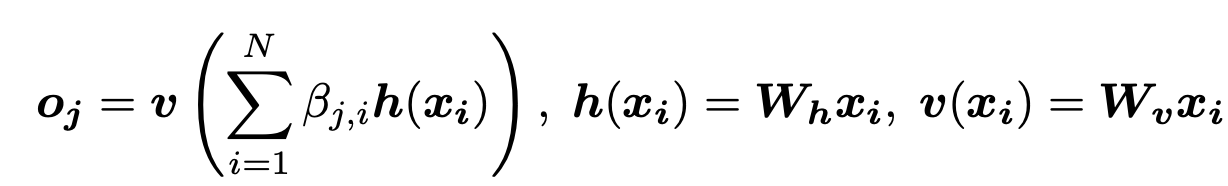
図で表すと、下のようになる。
最後に、算出されたself-attention feature mapにパラメータγを掛け合わせて、入力xに加えてあげる。
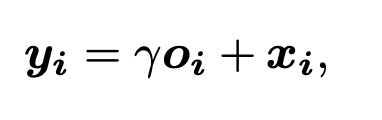
これがself-attention機構の全貌である。
bigGAN
このself-attention GANやスペクトル正規化を用いることで、BigGANは512×512の非常にリアルな画像の生成を、ImageNetの1000クラス全てに対して可能にした。
このBigGANで遊んで見たい方は、こちらのArtbreederというサイトを試してみてください。潜在空間のベクトルを連続的に変化させることで、ある画像が違う画像に徐々に推移していく様子を楽しめます。
参考文献
・http://urusulambda.com/2018/07/15/saganself-attention-generative-adversarial-network%E3%81%AEself-attention%E6%A9%9F%E6%A7%8B%E3%82%92%E3%81%96%E3%81%A3%E3%81%8F%E3%82%8A%E7%90%86%E8%A7%A3%E3%81%97%E3%81%9F/
・https://arxiv.org/pdf/1805.08318.pdf