はじめに
こんにちは、RetailAIの@long10langです。さて、advent calendar今年は何書こう?というわけで、あれこれ考えた結果、あまり理解が進んでいなかったRWKVについてちゃんと調べてみようと思い立ちまして、それなら単にRWKVの説明をしたところで面白くないので、juliaでいっちょやってみっかということで、やって行きたいと思います。
目次
RWKVについて
やはり、今年はなんと言ってもChatGPT元年ということで、いろんなことがありました。もうすっかり市民権を獲得したと言っても過言ではないtransformerですが、その根幹をなすSelf-Attentionという仕組みは、もちろん画期的な発明ではありましたが、学習量がすんごいことになるため、一般人がそう簡単に手出しできるような代物ではありませんよね。
とはいえ、RNNベースのモデルだと、メモリと計算要件の面で線形にスケールするものの、並列化と拡張性の制限からtransformerと同等の性能を達成できるかといえばそれもまた困難です。
そこで,transformerの効率的な並列学習と、RNNの効率的な推論の両方を兼ね備えたモデルとしてRWKV(Receptance Weighted Key Value)という新たなモデルアーキテクチャーが提案されました。
詳しくは論文を参照して頂ければと思うのですが、ざっくり言ってしまえば、このモデルは、数百億のパラメータまでスケールする初の非Transformerアーキテクチャでありながら、同じサイズのTransformerと同等の性能を発揮することが論文内で示されています。
そんなわけで、現在GPTをはじめとしたtransformerベースのモデルよりも、高速に推論可能(?)なモデルとして注目されている、というわけです。
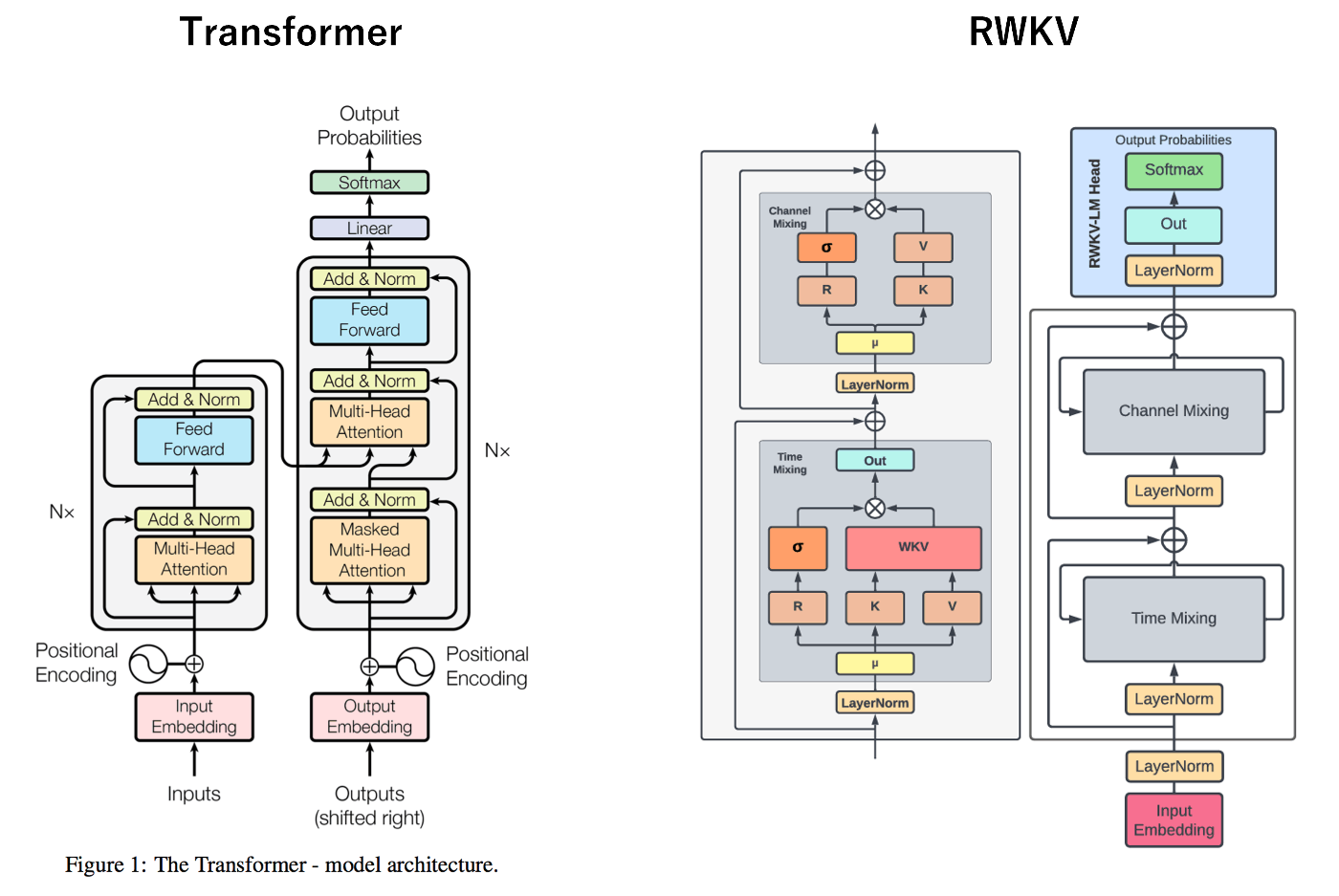
左がtransformerで、右がRWKVです。Channel MixingとTime Mixingが大きく異なる点ですが、そこに登場するモデル要素にちなんで、RWKVと呼ばれています。
- R:過去の情報の受容度を表現するReceptanceベクトル。
- W:位置の重み減衰ベクトル。訓練可能なモデルパラメータ。
- K:一般的な注意機構におけるK(Key)に類似のベクトル。
- V:一般的な注意機構におけるV(Value)に類似のベクトル。
めちゃくちゃざっくりと言ってしまえば、tranformerもRWKVも、どちらも計算上で、文章などの情報を理解する方法という点では一緒なのですが、tranformerはSelf-Attention、つまり文章のすべての部分に注意を払い、複雑な内容も理解できる反面たくさんの計算が必要になる。一方、RWKVはよりシンプルで、少ない計算で済むためサクサク動作します。というわけで、長い文章を扱うときRWKVの方が効率的ですが、transformerの方がより深く内容を理解できる、乱暴ですがそんな理解です。
実装あれこれ
それでは、四の五の言わず、juliaで実装を見ていきましょう。まずは、ネットワークから。
1.Layer Normalization (LN) 構造体と関数:層正規化を行うカスタム構造体とその動作を定義しています。
struct LN
γ
β
ϵ
dims
end
LN(γ, β) = LN(γ, β, 1e-5, 1)
LN(n::Integer) = LN(ones(Float32, n), zeros(Float32, n))
@Flux.functor LN
Flux.trainable(m::LN) = (γ=m.γ, β=m.β)
function (m::LN)(x::AbstractArray{T,N}) where {T,N}
μ = mean(x, dims=m.dims)
σ² = var(x, dims=m.dims)
(T).(m.γ .* (x .- μ) ./ (σ² .+ m.ϵ).^0.5 .+ m.β)
end
2.次に、ユーティリティ関数:時間の混合、二乗ReLU、指数混合などの関数を定義していきます。
time_mix(x, x_prev, mix) = @. x * mix + x_prev * (1 - mix)
square_relu(x::T) where T = max(zero(T), x)^2
function exp_mix(v1::AbstractArray{T}, v2::AbstractArray{T}, p1::AbstractArray{T}, p2::AbstractArray{T}) where T
p = max.(p1, p2)
(@. exp(p1 - p) * v1 + exp(p2 - p) * v2, p)
end
function exp_selfadj(v1, v2, p)
p_new = @. max(min(abs(asinh(v1)), p), min(abs(asinh(v2)), p))
factor = @. exp(p - p_new)
@. (v1*factor, v2*factor, p_new)
end
3.State構造体:ネットワークの状態を保持するための構造体を定義します。
mutable struct State
x_tm # token mixing
x_cm # channel mixing
a # numerator
b # denominator
p # largest exponent seen
end
State(n_embed::Integer, n_layer::Integer) = begin
dim = (n_embed, n_layer)
State(zeros(Float32, dim), zeros(Float32, dim), zeros(Float32, dim), zeros(Float32, dim), zeros(Float32, dim))
end
@Flux.functor State
4.TokenMixing と ChannelMixing 構造体:トークンとチャネルの混合を行うための層を定義しています。
function recur_step(left::Vector, right::Vector; w)
a_prev, b_prev, p_prev = left
expkv, expk, p = right
a_new, p_new = exp_mix(a_prev, expkv, p_prev .+ w, p)
b_new, _ = exp_mix(b_prev, expk, p_prev .+ w, p)
[a_new, b_new, p_new]
end
struct TokenMixing{T}
Tₖ::AbstractArray{T, 1}
Tᵥ::AbstractArray{T, 1}
Tᵣ::AbstractArray{T, 1}
r_proj
k_proj
v_proj
out_proj
time_first::AbstractArray{T, 1}
time_decay::AbstractArray{T, 1} # <-- w
end
@Flux.functor TokenMixing
TokenMixing(n_embed::Integer) = TokenMixing(
zeros(Float32, n_embed), # Tₖ
zeros(Float32, n_embed), # Tᵥ
zeros(Float32, n_embed), # Tᵣ
Dense(n_embed, n_embed, bias=false), # r_proj
Dense(n_embed, n_embed, bias=false), # k_proj
Dense(n_embed, n_embed, bias=false), # v_proj
Dense(n_embed, n_embed, bias=false), # out_proj
zeros(Float32, n_embed), # time first
ones(Float32, n_embed), # time_decay
)
function (m::TokenMixing)(x::AbstractArray{T,2}, state::State; i) where T
n_embed, n_seq = size(x)
x_prev = hcat(@views(state.x_tm[:, i]), @views(x[:, 1:end-1]))
xₖ = time_mix(x, x_prev, m.Tₖ)
xᵥ = time_mix(x, x_prev, m.Tᵥ)
xᵣ = time_mix(x, x_prev, m.Tᵣ)
r = m.r_proj(xᵣ) .|> sigmoid
k = m.k_proj(xₖ)
v = m.v_proj(xᵥ)
p = k
expk = k.*0 .+ 1
expkv = v
step_f = (a, b) -> recur_step(a, b; w=m.time_decay)
a_prev, b_prev, p_prev = @views(state.a[:, i]), @views(state.b[:, i]), @views(state.p[:, i])
substrate = [[@views(expkv[:,i]), @views(expk[:,i]), @views(p[:,i])] for i = 1:n_seq]
abp = accumulate(step_f, substrate; init=[a_prev, b_prev, p_prev])
a_prev = batch([a_prev, [abp[i][1] for i = 1:n_seq-1]...])
b_prev = batch([b_prev, [abp[i][2] for i = 1:n_seq-1]...])
p_prev = batch([p_prev, [abp[i][3] for i = 1:n_seq-1]...])
c, _ = exp_mix(a_prev, expkv, p_prev, p .+ m.time_first)
d, _ = exp_mix(b_prev, expk, p_prev, p .+ m.time_first)
rwkv = @. r * c / d
# update state
@views state.x_tm[:, i] .= x[:, end]
@views state.a[:, i] .= abp[end][1]
@views state.b[:, i] .= abp[end][2]
@views state.p[:, i] .= abp[end][3]
m.out_proj(rwkv), state
end
# stateless for training
function (m::TokenMixing)(x::AbstractArray{T,3}) where T
n_embed, n_batch, n_seq = size(x)
@views x_prev = pad_zeros(x, (0,0,0,0,1,0))[:, :, 1:end-1]
xₖ = time_mix(x, x_prev, m.Tₖ)
xᵥ = time_mix(x, x_prev, m.Tᵥ)
xᵣ = time_mix(x, x_prev, m.Tᵣ)
r = m.r_proj(xᵣ) .|> sigmoid
k = m.k_proj(xₖ)
v = m.v_proj(xᵥ)
p = k
expk = zeros_like(k) .+ 1
expkv = v
step_f = (a, b) -> recur_step(a, b; w=m.time_decay)
a_prev = b_prev = p_prev = zeros_like(k, eltype(v), (n_embed, n_batch))
substrate = @views [[expkv[:,:,i], expk[:,:,i], p[:,:,i]] for i = 1:n_seq]
abp = accumulate(step_f, substrate; init=[a_prev, b_prev, p_prev])
a_prev = batch([a_prev, [abp[i][1] for i = 1:n_seq-1]...])
b_prev = batch([b_prev, [abp[i][2] for i = 1:n_seq-1]...])
p_prev = batch([p_prev, [abp[i][3] for i = 1:n_seq-1]...])
c, _ = exp_mix(a_prev, expkv, p_prev, p .+ m.time_first)
d, _ = exp_mix(b_prev, expk, p_prev, p .+ m.time_first)
rwkv = @. r * c / d
m.out_proj(rwkv)
end
struct ChannelMixing{T}
Tₖ::AbstractArray{T, 1} # will be taken out in the future
Tᵣ::AbstractArray{T, 1} # will be taken out in the future
r_proj
k_proj
v_proj
end
@Flux.functor ChannelMixing
ChannelMixing(n_embed::Integer) = ChannelMixing(
zeros(Float32, n_embed), # Tₖ
zeros(Float32, n_embed), # Tᵣ
Dense(n_embed, n_embed, bias=false), # r_proj
Dense(n_embed, n_embed*4, bias=false), # k_proj
Dense(n_embed*4, n_embed, bias=false), # v_proj
)
function (m::ChannelMixing)(x::AbstractArray{T, 2}, state::State; i) where T
n_embed, n_seq = size(x)
x_prev = @views(state.x_cm[:, i])
if size(x, 2) > 1
x_prev = hcat(x_prev, @views(x[:, 1:end-1]))
end
xₖ = time_mix(x, x_prev, m.Tₖ)
xᵣ = time_mix(x, x_prev, m.Tᵣ)
r = m.r_proj(xᵣ) .|> sigmoid
k = m.k_proj(xₖ) .|> square_relu
# update state
@views state.x_cm[:, i] .= x[:, end]
r .* (m.v_proj(k)), state
end
function (m::ChannelMixing)(x::AbstractArray{T, 3}) where T
# n_embed, n_batch, n_seq = size(x)
@views x_prev = pad_zeros(x, (0,0,0,0,1,0))[:, :, 1:end-1]
xₖ = time_mix(x, x_prev, m.Tₖ)
xᵣ = time_mix(x, x_prev, m.Tᵣ)
r = m.r_proj(xᵣ) .|> sigmoid
k = m.k_proj(xₖ) .|> square_relu
r .* (m.v_proj(k))
end
5.Block 構造体:LN、TokenMixing、ChannelMixingを組み合わせたブロック構造体を定義します。
struct Block
ln1
token_mixing
ln2
channel_mixing
end
@Flux.functor Block
Block(n_embed::Integer) = Block(
LN(n_embed),
TokenMixing(n_embed),
LN(n_embed),
ChannelMixing(n_embed),
)
function (m::Block)(x, state::State; i)
xp, state = m.token_mixing(m.ln1(x), state; i=i)
x = x + xp
xp, state = m.channel_mixing(m.ln2(x), state; i=i)
x = x + xp
x, state
end
function (m::Block)(x)
xp = m.token_mixing(m.ln1(x))
x = x + xp
xp = m.channel_mixing(m.ln2(x))
x = x + xp
x
end
6.RWKVモデル:言語モデルのメイン構造体で、埋め込み層、LN層、複数のブロック、最終LN層、言語モデルのヘッドを含んでいます。
struct RWKV
ln_init
embedding
blocks
ln_final
lm_head
end
@Flux.functor RWKV
RWKV(n_embed::Integer, n_blocks::Integer, n_vocab::Integer) = RWKV(
Embedding(n_vocab, n_embed),
LN(n_embed),
[Block(n_embed) for _ in 1:n_blocks],
LN(n_embed),
Embedding(n_embed, n_vocab)
)
7.モデルのフォワードパス:状態を持つか持たないかに基づいて、モデルのフォワードパスを定義しています。
(m::RWKV)(x::AbstractArray{T, 1}, state::State) where T = begin
x = m.embedding(x)
x = m.ln_init(x)
for i in 1:length(m.blocks)
x, state = m.blocks[i](x, state; i=i)
end
x = m.ln_final(x)
# x: [n_embed, n_seq]
x = m.lm_head.weight' * x
x, state
end
(m::RWKV)(x::Integer, state::State) = begin
out, state = m([x], state)
out[:, end], state
end
(m::RWKV)(x::AbstractArray{T, 2}) where T = begin
x = m.embedding(x)
# better performance
x = permutedims(x, (1, 3, 2))
x = m.ln_init(x)
for i in 1:length(m.blocks)
x = m.blocks[i](x)
end
x = m.ln_final(x)
# better performance
x = permutedims(x, (1, 3, 2))
# x: [n_embed, n_seq, n_batch]
batched_mul(m.lm_head.weight', x)
end
以上で、RWKVのネットワーク実装が終わりました。では、早速このネットワークを用いてトレーニングをしていきましょう。
include("data.jl") # <- データ
include("rwkv.jl") # <- 上で定義したネットワーク
include("utils.jl") # <- 下で定義するユーティリティ関数
using Flux.Losses
using OneHotArrays
using Dates, Logging
using CUDA
using BSON: @save
using Optimisers
function save_model(model, path)
model = model |> cpu
@save path model
end
cfg = (
learning_rate = 3e-4,
epochs = 5,
dataset = "sample.jsonl",
use_cuda = true,
ctx_len = 256,
batch_size = 8,
log_per_nbatch = 5,
save_per_nbatch = 1000,
n_vocab = 50277,
n_layer = 12,
n_head = 12
)
data_file = cfg.dataset
tokenizer = get_tokenizer()
ts = TextSplitter(cfg.ctx_len+1, 16, tokenizer)
function loss_func(y_pred, y; n_vocab=cfg.n_vocab)
return logitcrossentropy(y_pred, onehotbatch(y, 1:n_vocab))
end
if cfg.use_cuda && CUDA.functional()
CUDA.allowscalar(false)
@info "Using CUDA"
device = gpu
else
@info "Using CPU"
device = identity
end
Flux.trainable(m::RWKV) = (blocks=m.blocks,)
Flux.trainable(m::Block) = (token_mixing=m.token_mixing,)
# device = identity # debug
model = rwkv_from_pth("RWKV-4-Pile-169M-20220807-8023.pth"; cfg.n_layer) |> f32
model = model |> device
# setup optimizer
opt = Optimisers.setup(Optimisers.Adam(cfg.learning_rate), model)
i_batch = 1
for epoch in 1:cfg.epochs
global i_batch
batches = jsonl_reader(data_file) |> ch->batch_sampler(ch, ts; batch_size=cfg.batch_size)
for (x, y) in batches
x = x |> device
y = y |> device
val, grads = Flux.withgradient(model) do m
y_pred = m(x)
loss_func(y_pred, y)
end
Flux.update!(opt, model, grads[1])
if i_batch % cfg.log_per_nbatch == 0
@info "metrics" loss=val
println("Ep $(epoch) Batch $(i_batch) Loss $(val)")
end
if i_batch % cfg.save_per_nbatch == 0
@info "saving model"
save_model(model, "rwkv-169m-$(now()).bson")
end
i_batch += 1
end
end
ユーティリティ関数(utils.jl)がこちら↓
using PyCall
using Flux
using StatsBase
include("rwkv.jl")
torch = pyimport("torch")
function rwkv_from_pth(pth_path="RWKV-4-Pile-169M-20220807-8023.pth"; n_layer=12)
data = torch.load(pth_path, "cpu")
ln_init = LN(
data["blocks.0.ln0.weight"].float().numpy(),
data["blocks.0.ln0.bias"].float().numpy(),
)
ln_final = LN(
data["ln_out.weight"].float().numpy(),
data["ln_out.bias"].float().numpy()
)
embedding = Embedding(
data["emb.weight"].float().numpy()'
)
lm_head = Embedding(
data["head.weight"].float().numpy()'
)
blocks = []
for i = 0:n_layer-1
ln1 = LN(
data["blocks.$i.ln1.weight"].float().numpy(),
data["blocks.$i.ln1.bias"].float().numpy(),
)
ln2 = LN(
data["blocks.$i.ln2.weight"].float().numpy(),
data["blocks.$i.ln2.bias"].float().numpy(),
)
time_first = data["blocks.$i.att.time_first"].float().numpy()
time_decay = -exp.(data["blocks.$i.att.time_decay"].float().numpy())
token_mixing = TokenMixing(
dropdims(data["blocks.$i.att.time_mix_k"].float().numpy(), dims=(1,2)),
dropdims(data["blocks.$i.att.time_mix_v"].float().numpy(), dims=(1,2)),
dropdims(data["blocks.$i.att.time_mix_r"].float().numpy(), dims=(1,2)),
Dense(
data["blocks.$i.att.receptance.weight"].float().numpy(),
false
), # r_proj
Dense(
data["blocks.$i.att.key.weight"].float().numpy(),
false
), # k_proj
Dense(
data["blocks.$i.att.value.weight"].float().numpy(),
false
), # v_proj
Dense(
data["blocks.$i.att.output.weight"].float().numpy(),
false
), # out_proj
time_first,
time_decay,
)
channel_mixing = ChannelMixing(
dropdims(data["blocks.$i.ffn.time_mix_k"].float().numpy(), dims=(1,2)),
dropdims(data["blocks.$i.ffn.time_mix_r"].float().numpy(), dims=(1,2)),
Dense(
data["blocks.$i.ffn.receptance.weight"].float().numpy(),
false
), # r_proj
Dense(
data["blocks.$i.ffn.key.weight"].float().numpy(),
false
), # k_proj
Dense(
data["blocks.$i.ffn.value.weight"].float().numpy(),
false
), # v_proj
)
push!(blocks, Block(
ln1,
token_mixing,
ln2,
channel_mixing
))
end
RWKV(
ln_init,
embedding,
blocks,
ln_final,
lm_head
)
end
function get_tokenizer()
py"""
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_file('20B_tokenizer.json')
"""
py"tokenizer"
end
function sample_logits(logits; temperature=1.0, top_p=0.9, use_argmax=false)
if use_argmax
return argmax(logits)
end
probs = softmax(logits; dims=1)
sorted_probs = sort(probs; rev=true)
cum_probs = cumsum(sorted_probs)
cutoff = sorted_probs[argmax(cum_probs .> top_p)]
probs = (probs .> cutoff) .* probs
if temperature != 1.0
probs .^= 1/temperature
end
probs = probs / sum(probs)
sample(collect(1:length(probs)), ProbabilityWeights(probs)) |> Int
end
上記をトレーニングをして、推論を実行すると、結果が表示されます。
include("rwkv.jl")
include("utils.jl")
device = gpu
tokenizer = get_tokenizer()
model = rwkv_from_pth("RWKV-4-Pile-430M-20220808-8066.pth"; n_layer=24) |> device
function generate(model, prompt, n_tokens=50; top_p=0.99, temperature=1.0, use_argmax=false, device=identity)
input_ids = tokenizer.encode(prompt).ids .+ 1
state = State(size(model.embedding.weight, 1), length(model.blocks)) |> device
out, state = model(input_ids[1:end-1], state)
println("-------------------------")
println(prompt)
println("-------------------------")
input_id = input_ids[end]
for i = 1:n_tokens
out, state = model(input_id, state)
out_id = sample_logits(out |> cpu; top_p=top_p, temperature=temperature, use_argmax=use_argmax)
print(tokenizer.decode([out_id-1]))
input_id = out_id
end
println()
state
end
prompt = "Japan is an economic powerhouse, but its growth rate is slowing. In the days ahead, Japan will";
generate(model, prompt, 100; top_p=0.999, device=device);
プロンプトとして、「Japan is an economic powerhouse, but its growth rate is slowing. In the days ahead, Japan will(日本は経済大国だが成長率は鈍化している。この先日本は・・・)」と渡してみたところ、返答として「 be dragged down by the decrease in exports and by the fall in the official growth rate to 6% in FY 2011. If the Japanese government continues its policies in this area, growth rates will drop below the previous rate in all of FY 2011( 輸出の減少と、2011年度の公式成長率が6%に低下したことが足を引っ張った。日本政府がこの分野の政策を続ければ、2011年度の成長率はすべて以前の成長率を下回るだろう。)」と、正しいのかよくわかりませんがそれっぽいのが返ってきました。
苦労話
RWKVのネットワーク実装については、RWKV-LMをほぼパクってますので、実態としてはpyCallしまくってます(笑)juliaを使うメリットは、ちょっとjuliaだけでは実装が厳しいとなっても、すぐPythonでなんとかできる点が良い点です。(いざとなればCが呼べるのもの嬉しいですね。)
ただ、PyCallの呼び出しで、実行させたいPythonのバージョンを指定するのに、以下のようにREPLで環境変数を指定してあげた後に、 (@hoge) pkg> build PyCall といった感じでビルドしてあげる必要があります。
_
_ _ _(_)_ | Documentation: https://docs.julialang.org
(_) | (_) (_) |
_ _ _| |_ __ _ | Type "?" for help, "]?" for Pkg help.
| | | | | | |/ _` | |
| | |_| | | | (_| | | Version 1.9.4 (2023-11-14)
_/ |\__'_|_|_|\__'_| | Official https://julialang.org/ release
|__/ |
julia> ENV["PYTHON"]="/home/long/.local/share/virtualenvs/XXXX/bin/python"
個人的には、juliaは、言語としてPythonよりも構文がはっきりと構造的だし、パイプ演算子があることで、状態変化の見通しがつきやすい点で、処理速度が速いというだけでなく、読みやすさという点でも、Pythonより上回ってると感じてます。どんどん使っていきたい。
まとめ
いかがでしたでしょうか?RWKVをより実装レベルで理解するために、Juliaで書き下してみることで、様々な気づきがありました。生成AI関連は来年もきっとすごいことになって行きそうですので、こんな感じで好きなプログラミング言語をあえて使いながら、面白がってキャッチアップしていきたいと思います。
さて明日は、サーバサイドエンジニアの@mizoguchi_ryosukeさんが、「初めてのpython cvxpy」というタイトルで発表します!ぜひ、お楽しみください〜