はじめに
本記事は、E資格受験を得るためのレポート記事になります。
プログラム名は、ラビットチャレンジ。そして今回は、深層学習編(day3,day4)です。
再帰型ニューラルネットワークの概念
・RNN
時系列データに対応可能なニューラルネットワーク。
基本的なモデル(入力層→出力層)は変わらないが、中間層に特徴がある。
※時系列 →音声データ、テキストデータ等
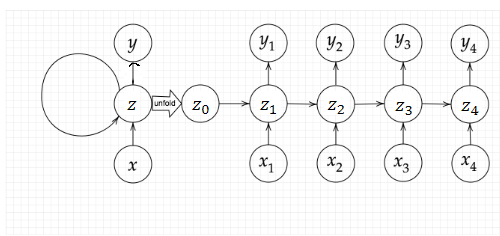
時系列モデルを扱うために初期の状態と過去の時間t-1の状態を保持し、そこから次の時間でのtを再帰的に求める再帰構造が必要になる。
・確認テスト
RNNのネットワークには大きくわけて3つの重みがある。1つは入力から現在の中間層を定義する際にかけられる重み、1つは中間層から出力を定義する際にかけられる重みである。残り1つの重みについて説明せよ。
[回答]
前の中間層の重み。
・実装演習
# 時系列ループ
for t in range(binary_dim):
# 入力値
X = np.array([a_bin[ - t - 1], b_bin[ - t - 1]]).reshape(1, -1)
# 時刻tにおける正解データ
dd = np.array([d_bin[binary_dim - t - 1]])
u[:,t+1] = np.dot(X, W_in) + np.dot(z[:,t].reshape(1, -1), W)
z[:,t+1] = functions.sigmoid(u[:,t+1])
y[:,t] = functions.sigmoid(np.dot(z[:,t+1].reshape(1, -1), W_out))
#誤差
loss = functions.mean_squared_error(dd, y[:,t])
delta_out[:,t] = functions.d_mean_squared_error(dd, y[:,t]) * functions.d_sigmoid(y[:,t])
all_loss += loss
out_bin[binary_dim - t - 1] = np.round(y[:,t])
・BPTT
誤差が時間をさかのぼって逆伝搬する誤差逆伝搬のひとつ。
・確認テスト

[回答]
\frac{dz}{dx} =\frac{dz}{dt}・\frac{dt}{dx} \\
\frac{dz}{dx} =2t\\
\frac{dz}{dx} =2(x+y)\\
LSTM
正式名称は、Long short Term Memory(長・短期記憶)ネットワーク。
長期的な依存関係を学習できるRNNの1種。
強みは、時系列データの学習や予測(回帰・分類)にあり、感情分析、言語モデリング、音声認識、
動画解析の分野において応用されている技術です。
※RNNの課題として以下の課題が存在する。
→時系列を戻れば戻るほど、勾配が消失していく。このことにより、長い時系列の学習が難しくなっていく。
→解決策としてLSTMがあげられる。
・LSTMの全体図
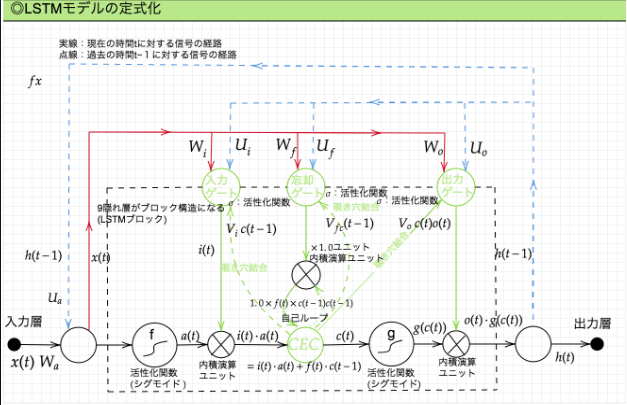
黒線:中間層全体を指す。
青線:上にあげたRNN図のループの部分を指す。
・CEC
→記憶機能しかないのでニューラルネットワークの学習性がない。
なので、CECの周りに入力ゲートと出力ゲートを配置させる。
入力ゲート:CECに記憶を覚えさせる方法を導く
出力ゲート:CECに記憶を使う方法を導く
☆入力・出力ゲートを追加することでゲートへの入力値の重みを重み行列W、Uで可変可能とする。
・忘却ゲート
→過去の情報が要らなくなったとき、削除できないので情報が存在し続ける。この課題解決のため忘却データがある。
・覗き穴結合:CECの判断材料
・確認テスト
以下の文章をLSTMに入力し空欄に当てはまる単語を予測したいとする。文中の「とても」という言葉は空欄の予測においてなくなっても影響を及ぼさないと考えられる。このような場合、どのゲートが作用すると考えられるか。
「映画おもしろかったね。ところで、とてもお腹が空いたから何か____。」
[回答]
忘却ゲート
GRU
日本語名は、ゲート付き回帰型ユニット。
回帰型ニューラルネットワーク(RNN)におけるゲート機構である。
LSTMの改良版でありGRUは、出力ゲートを欠けるたけLSTMよりパラメーターが少ない特徴を持つ。
・全体図

☆リセットゲートと更新ゲートを持つ
1)リセットゲート:隠れ層をどのように保存していくか
2)更新ゲート:今回、前回の出力値を元にどのような出力値を出すか
・確認テスト
LSTMとCECが抱える課題について、それぞれ簡潔に述べよ。
[回答]
パラメータが非常に多く計算負荷が高い
・確認テスト
LSTMとGRUの違いを簡潔に述べよ
[回答]
LSTM:入力・出力・忘却ゲート、CECをもつ。また計算負荷が高い
GRU:リセット・更新ゲートを持つ。計算負荷が低い
・実装演習
# RNN のセルを定義する。RNN Cell の他に LSTM のセルや GRU のセルなどが利用できる。
cell = tf.nn.rnn_cell.BasicRNNCell(self.hidden_layer_size)
outputs, states = tf.nn.static_rnn(cell, input_data, initial_state=initial_state)
双方向RNN
→過去の情報だけではなく未来の情報も紙することで精度を向上させるためのモデル。
中間層の出力を未来への順伝播と過去への逆伝播の両方に伝播するネットワークである。学習時に過去と未来の情報の入力を必要とすることから運用時も過去から未来までのすべての情報を入力してはじめて予測できるようになる。事例としては、機械翻訳があげられる。
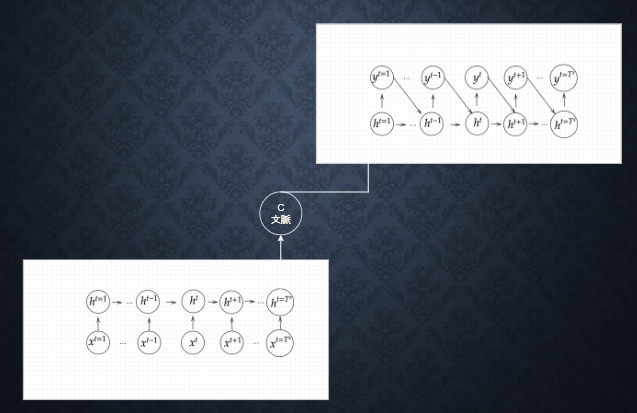
Seq2Seq
正式名称は、sequence to sequenceである。
seq2seqは、Encorder-Decorderモデルとも呼ばれます。Encorderは、入力データをエンコードし、Decorderはエンコードされたデータをデコードします。
エンコード(符号化)とは、情報をある規則に基づいて変換することを指す。
例えば、Aという文字を1000001に変換することを指し、一方デコード(復号)とは、エンコードされた情報を基に戻すことを指す。
・全体図
・確認テスト
下記の選択肢から、seq2seqについて説明しているものを選べ。
(1)時刻に関して順方向と逆方向のRNNを構成し、それら2つの中間層表現を特徴量として利用するものである。
(2)RNNを用いたEncoder-Decoderモデルの一種であり、機械翻訳などのモデルに使われる。
(3)構文木などの木構造に対して、隣接単語から表現ベクトル(フレーズ)を作るという演算を再帰的に行い(重みは共通)、文全体の表現ベクトルを得るニューラルネットワークである。
(4)RNNの一種であり、単純なRNNにおいて問題となる勾配消失問題をCECとゲートの概念を導入することで解決したものである。
[回答]
(2)
・確認テスト
VAEに関する下記の説明文中の空欄に当てはまる言葉を答えよ。自己符号化器の潜在変数に____を導入したもの。
[回答]
確率分布
word2vec
自然言語処理の一つ。単語のような文字列をベクトル表現する処理を指す。
自然言語処理において、単語の分散表現を使う場合、「カウントベースの手法」、「推論ベースの手法」が存在する。今回のWord2becは推論ベースの手法が該当する。
ex)you ? goodbye and I say.
両端のyou と goodbye(両端の単語)をコンテキストとして ? にどのような単語が出現するのか推測を行う。
モデルは、コンテキストを入力として受け取り、各単語の出現する確率を出力する。
その中の枠ぐみの中で、正しい推測ができるようにコーパスを使ってモデルの学習を行い、結果として単語の分散表現を得るのが推論ベースの手法の全体図となっている。
Attention Mecanism
seq2seqでは、長い文章への対応が難しい。そこでAttention Mecanismが開発された。
「入力と出力のどの単語が関連しているのか」の関連度を学習する仕組み。
文章の中で一番重要な単語を自力で見つける機構。
ex)I have a pen.
(私 は ペン を 持っている)
→"a"は、あまり重要でない単語というのが確認できる。
近年発達している自然言語処理は、Attention Mechanismであることが多い。
・確認テスト
RNNとword2vec、seq2seqとAttentionの違いを簡潔に述べよ
[回答]
RNN:時系列データを処理するのに適したニューラルネットワーク
Word2vec:単語の分散表現を得る手法
seq2seq:1つの時系列データから別の時系列データを得る手法
Attention:時系列データの中身にそれぞれ関連性をつける。
強化学習
ある環境内におけるエージェントが現在の状態を見て、取るべき行動を決定する機械学習の一つ。
エージェントは、決定した行動から報酬を得て、一番報酬を得られる方策を学習する。
→行動の結果として与えられる利益(報酬)をもとに、行動を決定する原理を改善していく仕組み
教師あり、教師なし学習との違い
→教師あり、教師なし学習は、データよりパターンを把握し予測する。
対して強化学習はより優れた方策を見つける施策となっている。
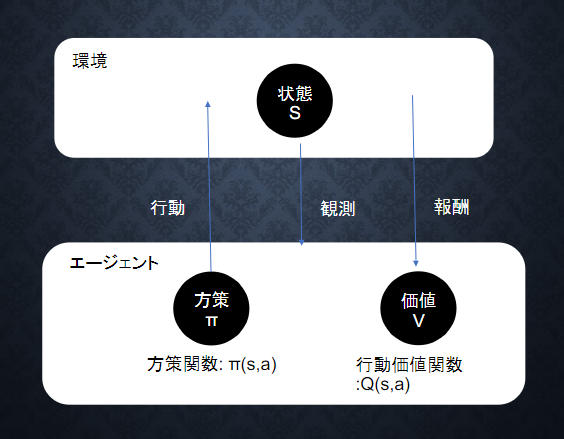
価値関数には、状態価値関数と行動価値関数が存在する。
方策関数 π(s) = a
→ある状態よりどのような行動を採るかの確立を充てる関数
方策に基づきエージェントは行動をとる
π(s,a):V,Qを基にどういう行動をとるか
→経験を活かす、またはチャレンジしていくかどうか
V^π(s):状態関数
Q^π(s,a):状態+行動
→ゴールまで今の方策を続けたときの報酬の予測値が得られる
→やり続けたら最後どうなるか
AlphaGo
GoogleのDeepMindによって開発されたコンピュータープログラムである。
コンピューターが人に打ち勝つのが難しいという囲碁において、人に打ち勝ったことでAIブームに
火をつける大きなきっかけとなった。
AlphaGoLeeとAlphaGoZeroがある。
軽量化・高速技術
高速技術
・分散深層学習
深層学習は、多くの時間を使用するため、高速化技術の開発が日々行われている。
→ex.データ並列化、モデル並列化、GPUなどなど
・データ並列化には、同期型と非同期型がある。
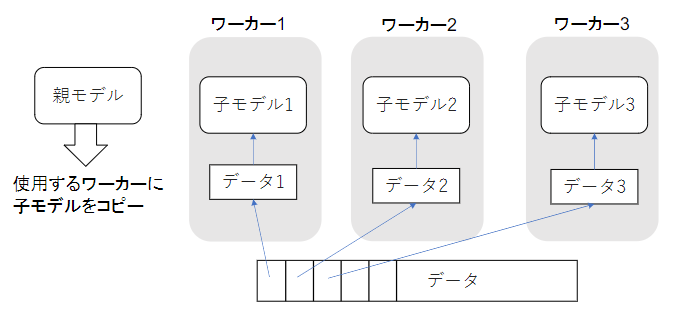
a)同期型
→各ワーカーが計算が終了するのを待って、全ワーカーの勾配が際に、勾配の平均を計算。
そして、親モデルのパラメーターを更新する。
b)非同期型
→各ワーカーはお互いの計算を待たずに各子モデルの計算を行う仕組み。
学習が終わった子モデルは、パラメーターモデルにpushされる。
また、新たに学習を始める際には、パラメーターサーバーからpopしたモデルに対して学習を
行っていく。
☆非同期型の処理が早いが、最新のモデルのパラメーターを利用できないため不安定になりやすい。
また、現在では同期方のほうが主流となっている。
→親モデルを各ワーカーに分割。各々のモデルを学習させすべて学習が終わったら1つのモデルへと
復元。
☆モデルが大きいほど、モデル並列型を使用したほうが効率化が図れる。
軽量化
・量子化
→通常のパラメーターを下位の精度(64bit→32bit)へ落とすことでメモリと演算処理の削減を行う。
→デメリットとして精度が低い
・蒸留
→大雑把に表現すると、規模の大きいモデルの知識を使い、軽いモデルの作成を行う。
→精度の高いモデル(教師モデル)を作り、軽いモデル(生徒モデル)へ継承させる手法。
・プルーニング
→必要なパラメーターだけを残し、必要でない(閾値以下)のパラメーターを削除し軽量化、高速化を行う。
応用モデル
・MobileNet
→画像認識モデル。スマホなどの小型端末にも乗せられる高性能のCNN。
Depthwise(空間方向)にCNNを行った後にPointWise(チャネル方向)にCNNを行う。
(通常のCNNは、空間方向とチャネル方向の畳み込みを同時に行う。)
この手法によって性能を落とすことなく、パラメーターを大幅に減らせる。
・DenseNet
画像認識のネットワーク。Transition Layer で繋いでいるDenseBlokが特徴。
→出力層に前の層の入力を足し合わせていく。
(チャネルがちょっとずつ増えていくイメージ)
Transformer
BERTは、Transformer をユニットにして動いている。
RNNやCNNを使わず、Attentionが使われいるseq2seqモデルである。
→翻訳先の各単語を選択する際に、翻訳元の文中の各単語の隠れ状態を利用している。
並列計算可能なため、RNNに比べて計算が高速な上、Self-Attentionと呼ばれる機構を用いることにより系列内の任意の位置の情報を参照することを可能にしている。
Attensionには、以下の2つがある。
→ソース・ターゲット注意機構
→自己注意機構
物体検知、セグメンテーション
物体検知には、以下のカテゴリが存在する。
・分類(classification)
・物体検知(object Detection)
・意味領域分割(Sematic Segmation)
・個体領域分割(Instance Segmentaion)
代表的データセットには、以下のデータセットが存在する。
物体検出コンペティションで用いられた有名なデータセットは下記の通り。
・VOC12
・ISVRC17 :ImageNetのサブセット
・MS COCO18:物体位置推定に対する新たな評価指標を提案
・OICOD18:OpenImageV4のサブセット