概要
- FortranはC++等に比べて出来ることが限られていて変なプログラムを書きづらいのが美点。
- 個人的に色々不満はあるが、一番は連想配列が無いこと。
- C++でいう
std::map, Pythonでいうdictみたいなやつ。
- C++でいう
- 仕事上Fortranを避けては通れないし、仕方がないので自分で書いた。
設計
実用的な連想配列の実装は大きく分けて二通り1、平衡二分木とハッシュテーブルが候補に挙がる。それぞれの特徴を比較するとこんな感じだ。
| 平衡二分木 | ハッシュテーブル | |
|---|---|---|
| 概要 | 高さが要素数の対数程度になるような木を作る | キーにハッシュ関数を適用したものをインデックスとして配列にアクセス |
| 挿入、削除、探索 | O(log N) やや速い | O(1) 速い |
| k番目のキーにアクセス | できる | できない |
| 留意点 | 単純な実装だとメモリ上非連続 | キーが長い時はハッシュ関数が遅い2 |
| その他 | 好き | あまり好きじゃない3 |
私のユースケースでは順序でアクセスする必要は低そうだが、本能に従って実装は平衡二分木を採用した。
木の選定と実装
あまり実装が重い木は正しく実装する自信が無いので、秋葉大先生の資料に倣ってtreapを採用した。親子関係はheap、左右関係は二分探索木になっていて、ランダムに優先度を割り振ることで確率的に平衡が保たれる。
複数のキーや値の型を使いたい。最近のFortranはポリモーフィズムにも対応しているらしいが、実装が複雑になりそう4なのでプリプロセッサで対応した。
測定
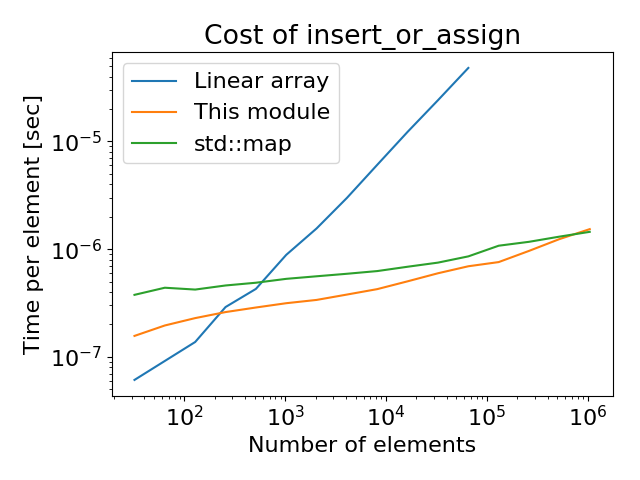
- マイクロベンチマークでは、要素数200以上で線形探索より速かった。
- 大体
std::mapと同程度。 - 線形探索が案外速い。Treapは毎ノード挿入時にメモリ確保が必要なので、その辺が遅そう。
- 趣味に走らずハッシュテーブルで実装したらもう少し速かったかもしれない、という後悔が残った。
- (追記) 後日ハッシュテーブルで実装したら2-3倍速い。大体
std::mapとstd::unordered_mapの違いくらいだ。- fnv-1a (32bit)だと、ハッシュ計算が全体の約半分を占めるのでxxhashやmurmurのような速いハッシュで書いたらもっと速くなりそうだ。
- 大体
補遺
連想配列を使える競プロの問題例
- k番目要素の操作 https://atcoder.jp/contests/arc033/submissions/4270463
- 座標圧縮
- 数え上げ https://atcoder.jp/contests/abc091/submissions/4350818