はじめに
データアナリスト兼データエンジニアをしているかみおかです。
キャリアとしては営業→データアナリスト→データ分析コンサルタントと歩んでおりデータエンジニアも兼ねるようになったのは今の会社に入社してからなのですが、そのきっかけとなったTreasureDataとの戦い及びもし一から導入となった際のベストプラクティスについて5つ記したいと思います。
TreasureDataとは
社内外に散らばるデータをひとまとめにして分析したり、他システムをシームレスに繋いだりすることができる強力なツールです。
非エンジニアでも簡単にできるGUI設定で、MySQLをはじめAmazon S3, BigQuery, Google Analytics, スプレッドシート, Tableau, Looker, Marketo, SalesForceなどWEBサービスに関するツール中心に痒いところに手が届く魅力があります。弊社ではデータ分析基盤としての使用がメインですが、顧客セグメントが容易でマーケティング施策に強いようです。
言語もSQLベースのPrestoなのでとっかかりやすい言語ではあります。また最近ではSQLを書かなくてもGUIで出来るシステムが実装されどこまで進化するのか楽しみです。
まさに分析者に優しいシステムなのですが、学習コストをかけずに出来ることが多すぎるというのは初学者にとっては危険かもしれません...
アンチパターン1 : 無目的にReplace設定しない
私が入社して1ヶ月経たないくらいに、上司から「TreasureDataから容量オーバーの連絡が来ている...」と宣告されました。(ちなみに前任者はすでにおらず、引継ぎの無いままの始まりでした)
TreasureDataの料金は非公開で契約内容によりますが、弊社の契約の料金体系は定額でimport量×データ蓄積量の契約値を越えなければOKです(Queryには課金されない嬉しいシステム)。基本的には利用状況から最大値を予測して料金設定されるはずなのですが、何を想定外に使っているかすべて洗い出したところ、以下の悲惨な現状が見えてきました。
- ほとんどのデータ更新がReplace - daily(毎日全更新)
- そのうち5つのテーブルがReplace - hourly(毎時間全更新)
- 中には全く同じデータでReplace - daily(毎日全更新)、Append - hourly(毎時間差分更新)の2種が存在している
結果、4000万レコードが毎日delete & insertされていました。
全更新は必ず最新のデータが入るので楽ですが、ここは惰性に任せず更新時間が入っているテーブルは必ずAppend(差分更新)にしてログ管理しましょう。
設定はsourceからできます。
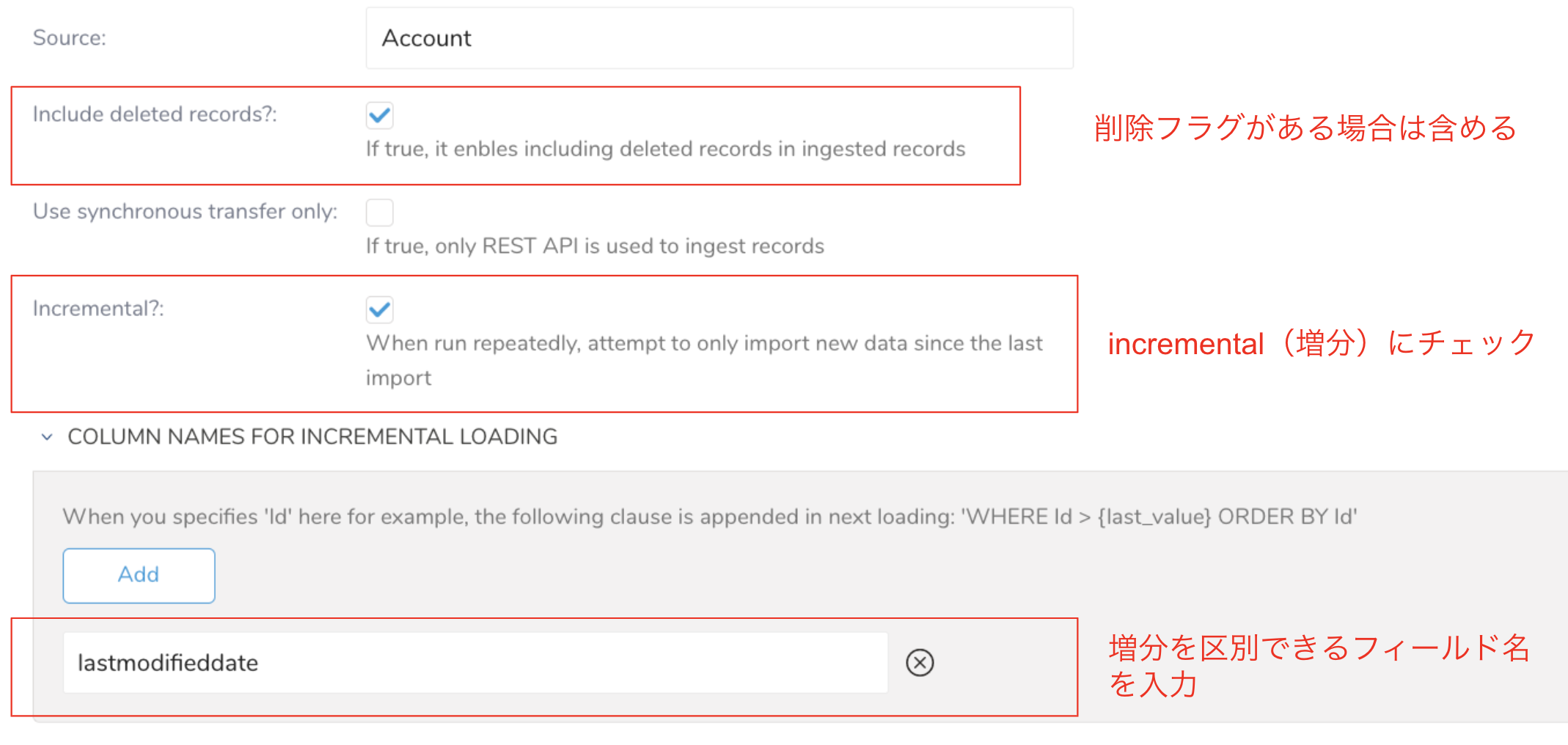
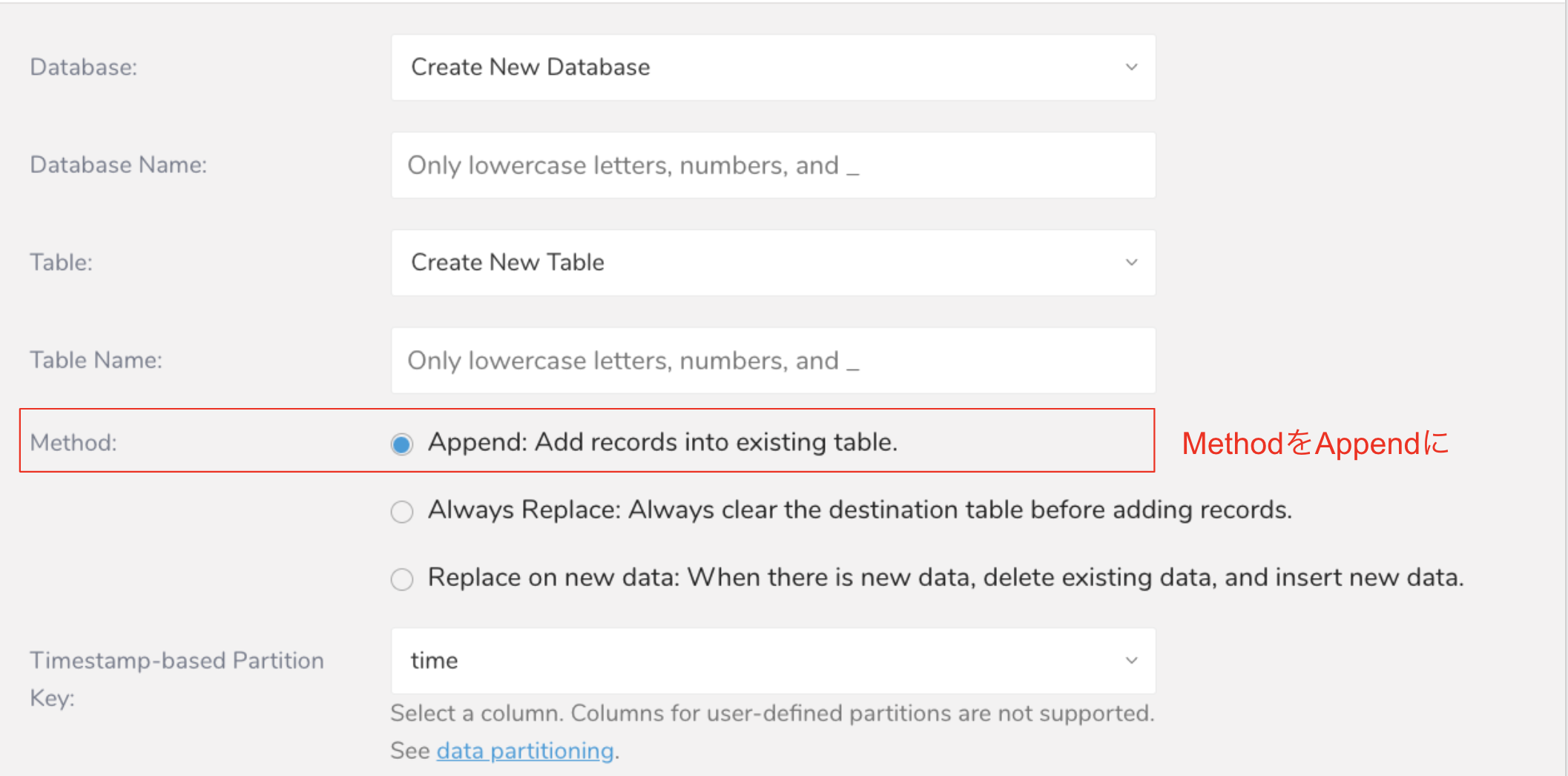
基本的には重複データが入る事故は起こらないとは思いますが、出力結果に不安がある場合は以下のような最新のレコードを持ってくるQueryを書きましょう。
SELECT
id
,MAX_BY(hoge,time) AS hoge
,MAX_BY(fuga,time) AS fuga
FROM
tbl
GROUP BY
id
MAX_BY()使いたくないときはこんなのも
SELECT
id
,ARRAY_AGG(hoge ORDER BY time)[OFFSET(0)] AS hoge
FROM
tbl
GROUP BY
id
サブクエリが増えるので面倒ですが、致し方ない。
こうしてReplaceからAppendに変更した結果、1日4000万レコード→600万レコードまで減らすことができました。
そもそもTBLに更新日時など無い場合は...早くデータベースエンジニアに改善を求めましょう。
当事者として一緒にDBの在り方を考えるのも分析基盤のデータエンジニアの醍醐味です。
アンチパターン2: Timezoneは慎重に設定しよう
TD_TIME_ADD(timestamp,'9h')、DATE_ADD(timestamp, INTERVAL 9 HOUR)というものが各所に存在することに気づきました。9hって何だっけ...と恐る恐る調べ始めました。
TreasureDataに時間型のデータを入れるときの特徴は、デフォルトがUTCでなぜか文字列になります。
SaaSはGMT+9で入っているので、何も考えずに入れてしまうと9時間前のデータに変更されたうえに文字列...
以下で乗り切りましょう。
SELECT
TD_TIME_FORMAT(TD_TIME_PARSE(SUBSTR(timestamp,1,19)),'yyyy-MM-dd HH:mm:ss','JST') AS timestamp
FROM
tbl
本来の時間(日本時間 JST)をtimestamp = '2022-12-12 00:00:00'としたときにUTC変換されるとTreasureDataには次のデータが入ります
timestamp = '2022-12-11 15:00:00.000'
9時間前のデータです。しかも文字列型で。
このままparseしてしまうと時間として認識されません。ですのでまずは余分な'.000'を除外するためにSUBSTR()を使います
SUBSTR(timestamp,1,19) > '2022-12-11 15:00:00'
ここから一気にデータ型を時間に変更したいところですが、TD_TIME_FORMAT()はunixtimeしか受け付けないのでparseします。
TD_TIME_PARSE(SUBSTR(timestamp,1,19))
この時点でJSTにうっかり変更してしまうとフォーマット変更の際におかしなことになるので要注意です。JSTは必ず最後の関数に付けましょう
◯ TD_TIME_FORMAT(TD_TIME_PARSE(SUBSTR(timestamp,1,19)),'yyyy-MM-dd HH:mm:ss','JST')
> 2022-12-12 00:00:00 JST
※TD_TIME_ADD()を使っても可。但し可読性が下がるしJSTじゃないから気持ち悪い
◯ TD_TIME_FORMAT(TD_TIME_ADD(TD_TIME_PARSE(SUBSTR(timestamp,1,19)),'9h') ,'yyyy-MM-dd HH:mm:ss')
> 2022-12-12 00:00:00 UTC
× TD_TIME_FORMAT(TD_TIME_PARSE(SUBSTR(timestamp,1,19),'JST'),'yyyy-MM-dd HH:mm:ss')
> 2022-12-11 06:00:00 timestamp
アンチパターン3: クエリをコピペすることになったら早くデータマート化を始めよう
色々な人が似たようなクエリを書き、微妙に結果が違うデータがたくさんあることに気づきました。
どうやら前任者は最低でも3名おり、それぞれのクエリをコピーして新しいデータを作っていたようです。
同じ処理をしつつ微妙に違う出力結果を出すことはその後のアナリスト自身を苦しめます。少数でやることの多いデータチームは効率化・省力化を早々に検討すべきです。
目先の依頼をただやるだけでなく、似たクエリを見つけてマージしてデータマートに仕上げましょう。
アンチパターン4: workflowを使ってデータマートを作ろう
「あ、ほとんど空のデータが出力されている...」という事態がありました。
TreasureDataにはdigdagをベースにしたworkflowが搭載されています。
まだ活用するデータが少ないうちはQueryにあるScheduled機能で毎日何時何分に実行すると一個一個やっていくのですが、数が増えすぎるといつどのデータが生成されているかわからなくなります。
さらにデータマートをScheduled機能で作った場合は、いつそのデータの出力が終わるかが読めず、それが終わる前に後続ジョブが走ってしまい、データの欠損やキュー詰まりが発生する可能性もあります。
workflowを使えば一つずつ順番にクエリ発行することが可能です。
早い段階からworkflowで間違いの無いデータを作りましょう。
アンチパターン5: Queryのタイトルと、そこから作られたデータソースのタイトルは統一させよう
弊社Tableauも使っているのですが、Tableauにあるデータソースがどこから作られているのか分からないことが往々にしてありました。
これは実際の設定画面なのですが
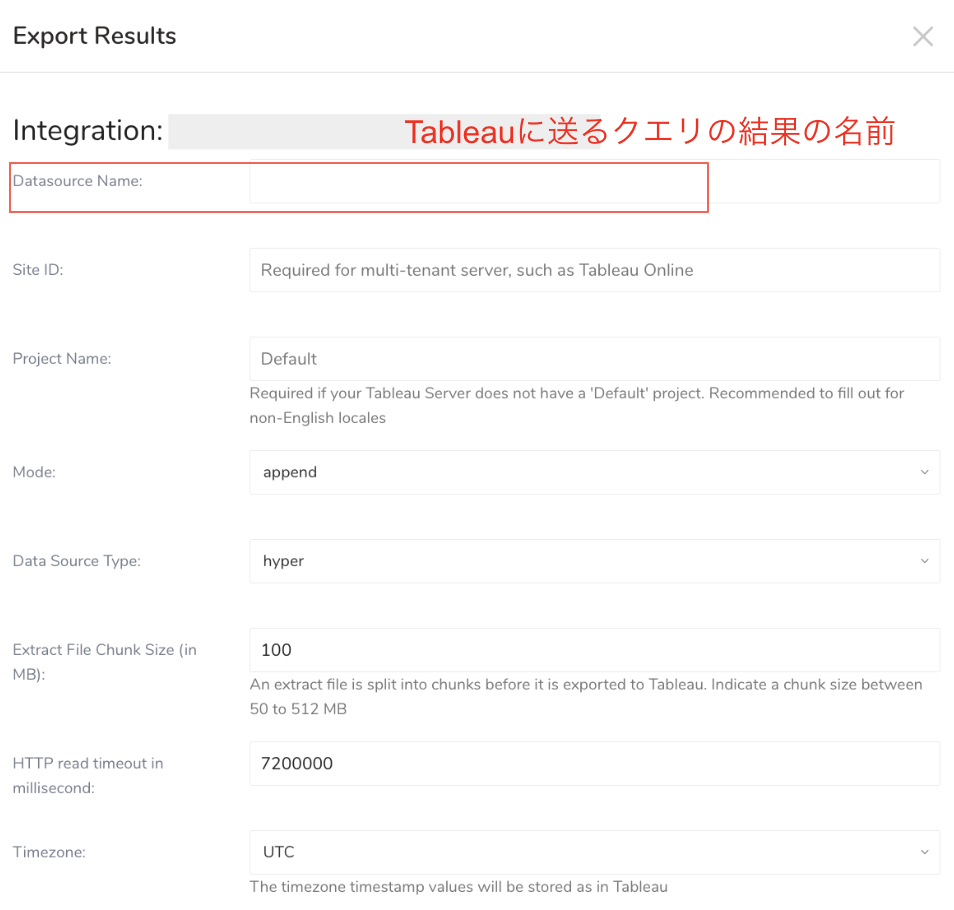
例えば、Queryの名前に「営業部向け商品マスタ」と本人的にはわかりやすく書いたものの、このDatasource Nameはアルファベットしか受け付けません。そのとき仕方なく「service_master」などと入力してしまうと何も知らない第三者はどのクエリとどのTableauのデータソースが対応しているか判別つかなくなります。(もちろん一個一個設定を開けば分かるけど...10クエリ以上になるとため息しか出ません)
もちろんTableauだけでなくて他のexport dataも同じ仕様です。
アルファベットでクエリ名と出力データ名の命名を揃えておくのが無難でしょう。
おわりに
TreasureDataの話を書きましたが、データ分析基盤ではマストで考えないといけないかなってことを並べました。誰かの一助になれば幸いです。他にも色々あったのですが...機会があれば追々...
また今回のアドベントカレンダーに誘っていただいた@Booklinさん、きっかけをいただきありがとうございました!
引き続きよろしくお願いします。