3章 教師なし学習と前処理
教師なし学習の難しさ
教師なし学習では、アルゴリズムに何を正解とするかを「教える」方法がないので、
アルゴリズムを評価するには、人間が結果を確かめる必要がある。
教師なし学習は単体で運用するよりも、
教師あり学習の前処理段階で使われることが多い。
さまざまな前処理
StandardScaler
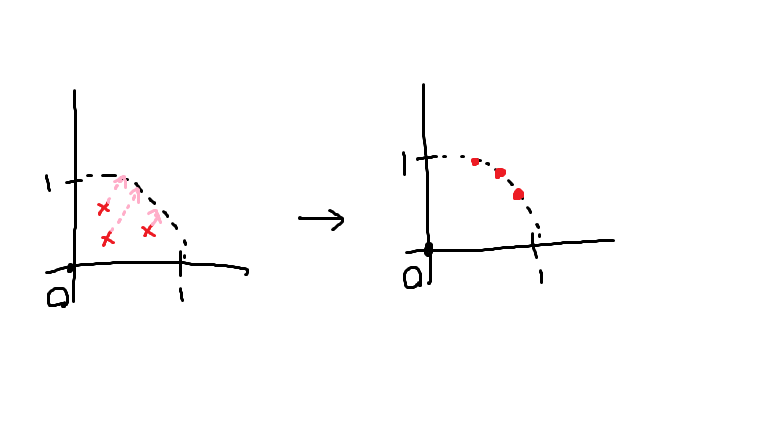
原点から離れた距離にあるデータ群を原点の近くに移動させるために
StandardScalerを使う。
RobustScaler
StandardScalerだと、原点から極端に離れたデータは原点から遠いままである。
なるべく原点に近づけるように全体を縮小するのがRobustScalerである。
MinMaxScaler
RobustScalerの場合、全体を縮小しても外れ値が存在する。
外れ値が出ないように、すべてを半径1の円に収めるように変換するのが
MinMaxScalerである。
Normalizer
データをベクトルとして見た際に、
長さではなく角度のみを見る時にNormalizerを使う。
次元削減、特徴量抽出、多様体学習
主成分分析(PCA)
PCA(Principal Component Analysis)とは、
早い話が回転である。
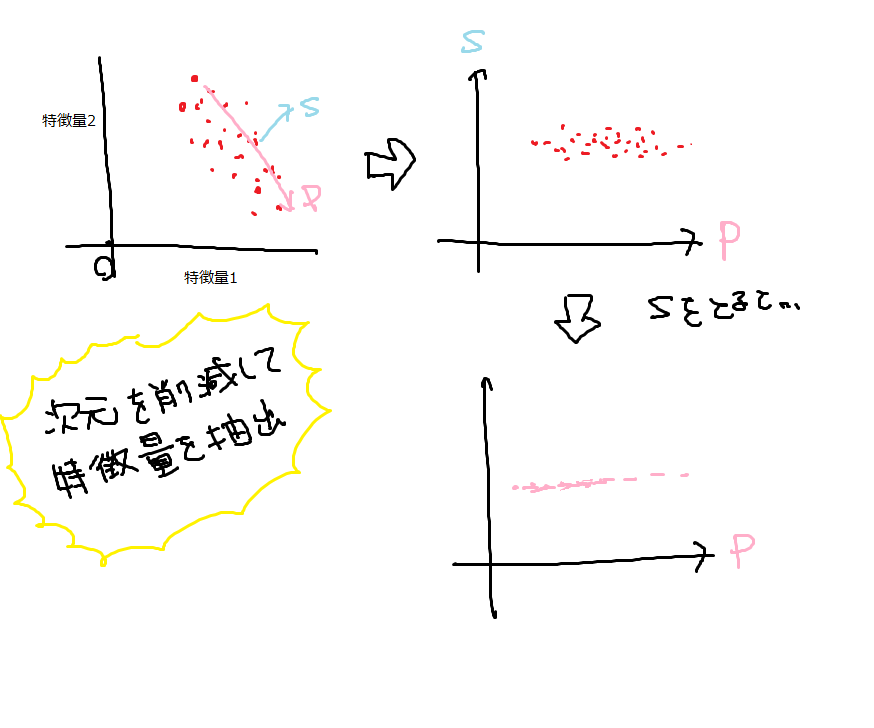
特徴量1と特徴量2が互いに直交しているデータを回転し、
主となる特徴量1のみを見るために、特徴量2の成分をそぎ落とす。
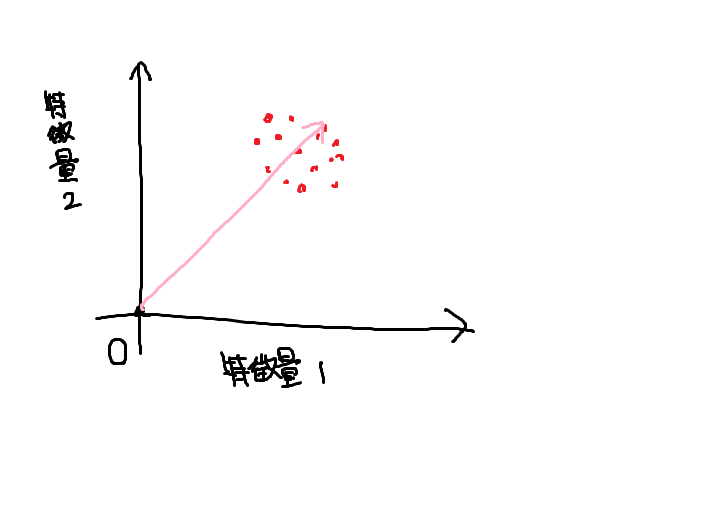
非負値行列因子分解(NMF)
NMF(Non-negative Matrix Factorization)は、
すべてのデータの総和を計算することによって
原点からデータのある方向のベクトルを算出するため、
マイナスが含まれるデータに対しては使えない。
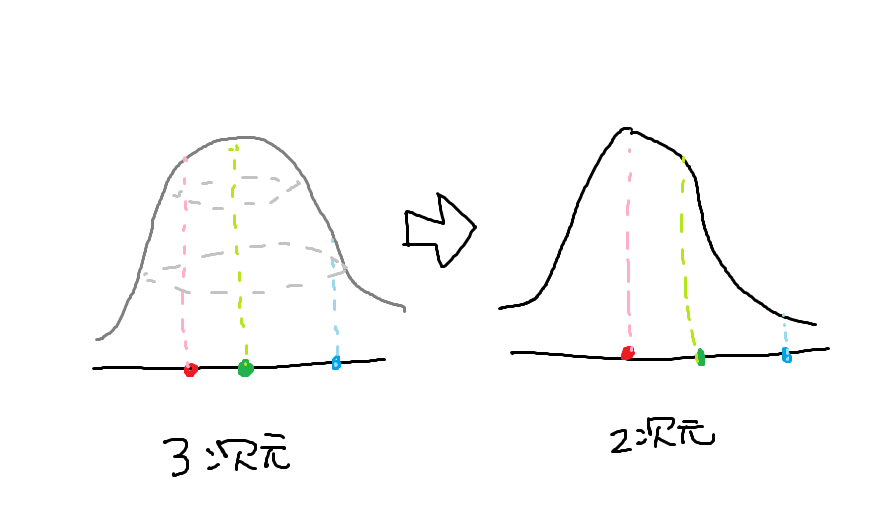
t-SNEを用いた多様体学習
PCAはデータを回転する必要があるため、実際に使える場面は限られてくる。
t-SNEは次元を圧縮し、2点間を確率分布で表現する。
クラスタリング
データを「クラスタ」と呼ばれるグループに分類することを**クラスタリング(clustering)**という。
k-meansクラスタリング
クラスタ重心を見つけて分類するのがk-meansクラスタリングである。
以下の手順に沿って分類していく。
①クラスタ毎に各点の平均値を計算する。
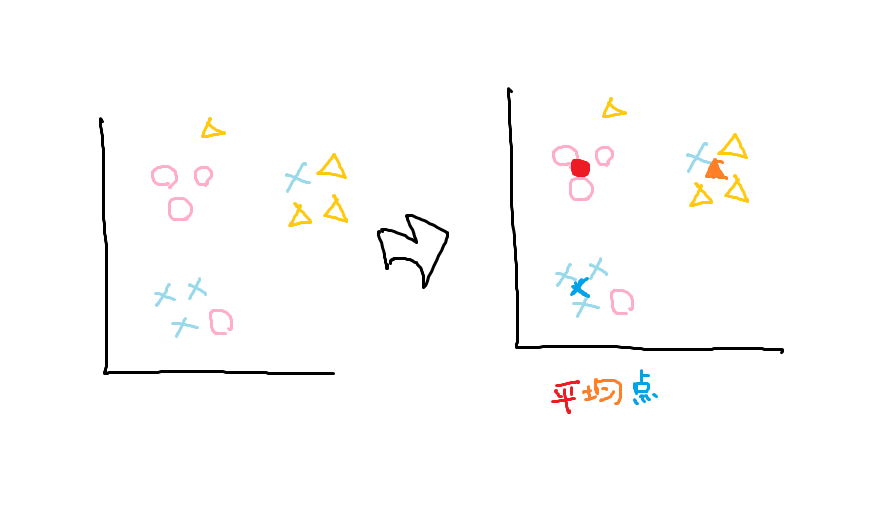
②各データを、一番近いクラスタの平均値のクラスタにする。
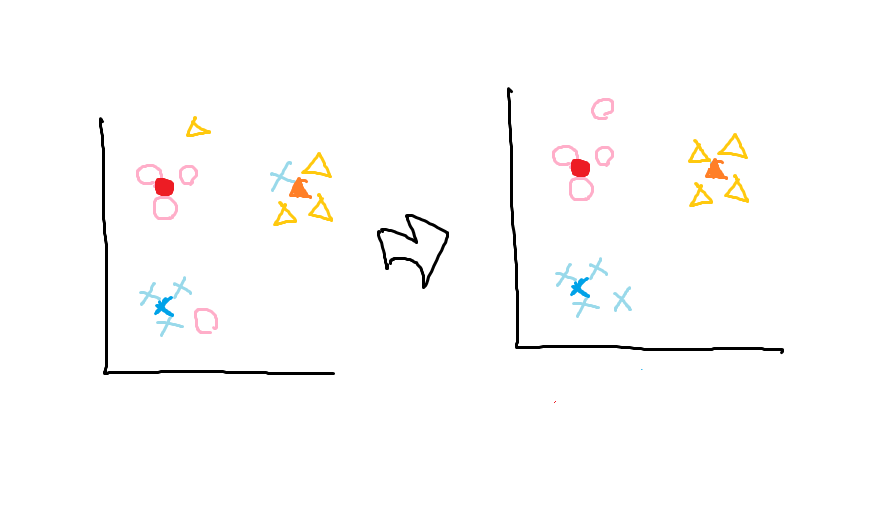
①と②を変化がなくなるまで繰り返す。
凝集型クラスタリング
**凝集型クラスタリング(agglomerative clustering)**は、
「クラスタを2つに分類する」などの終了条件を設定し、
近くにあるデータを同じクラスタとみなす作業を
終了条件を満たすまで繰り返す。
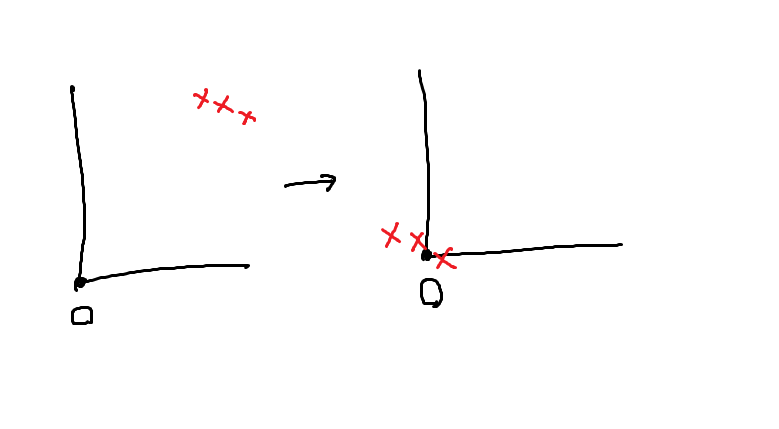
以下に例を示す。
この例では、「クラスタを2つに分類する」ことを終了条件とする。
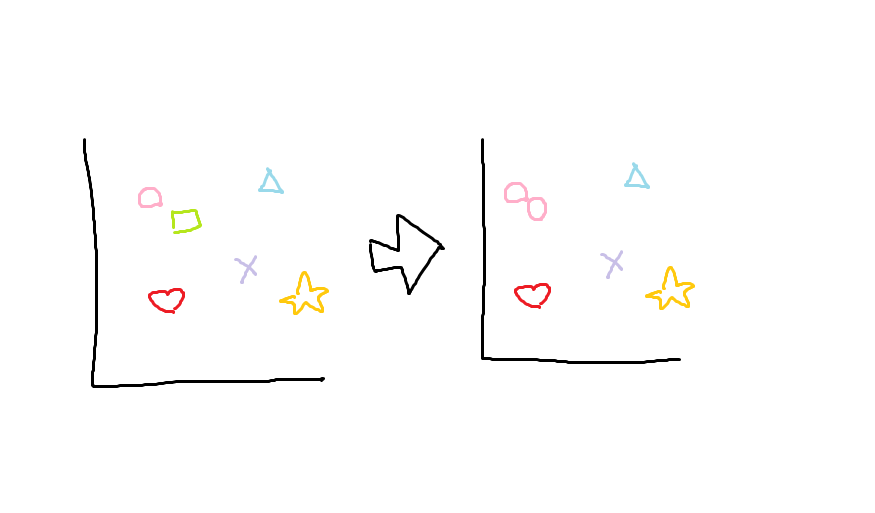
□を〇とみなし、
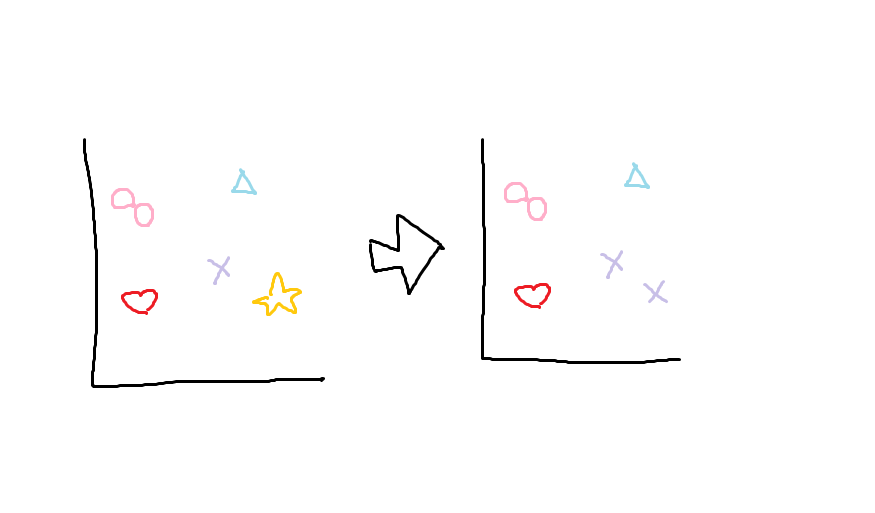
☆を×とみなし、
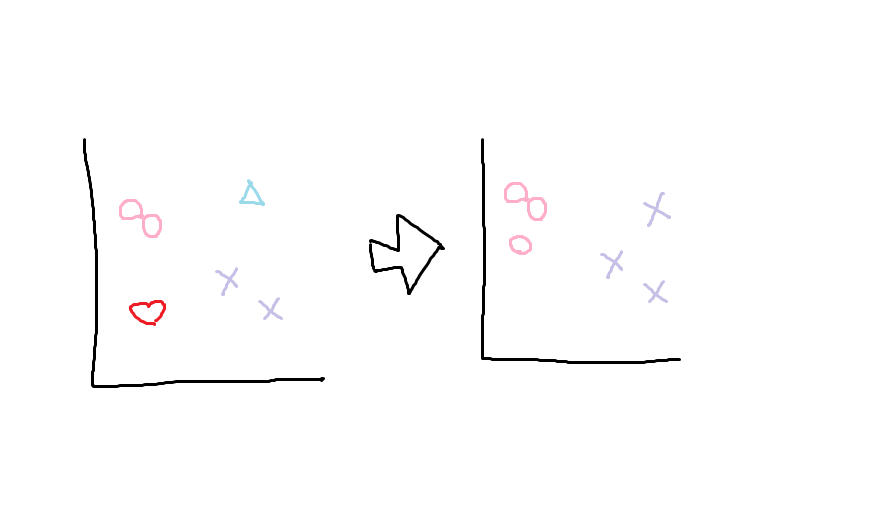
残りも〇と×に分類され、
クラスタは2つに分類された。
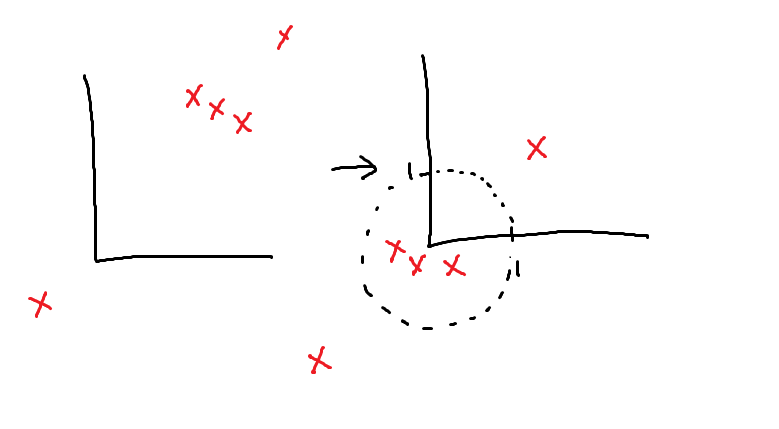
DBSCAN
**DBSCAN(Density-Based Spatial Clustering of Application with Noise)**とは、
密度をもとに、データをノイズかそうでないかを判断するアルゴリズムである。
パラメータとして、半径eps、最低サンプル数min_samplesを設定する。
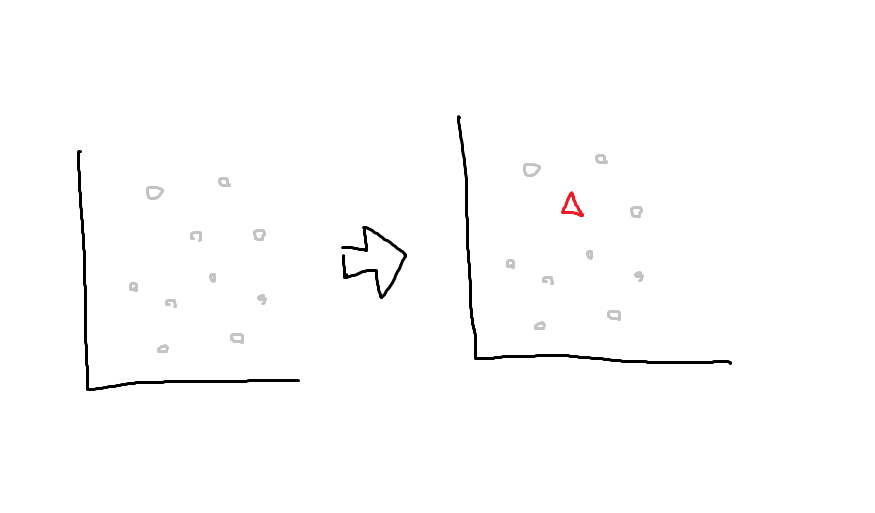
以下の例では、min_samplesを3とする。
まず、ランダムに1つの点を選ぶ。
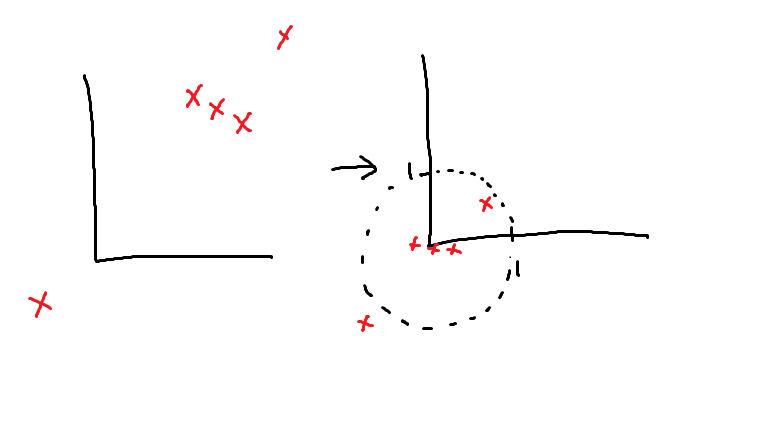
その点から半径eps内にデータがmin_samples個以上あれば、
その点はコアサンプルとなる。
なければ、ノイズ扱いとなる。
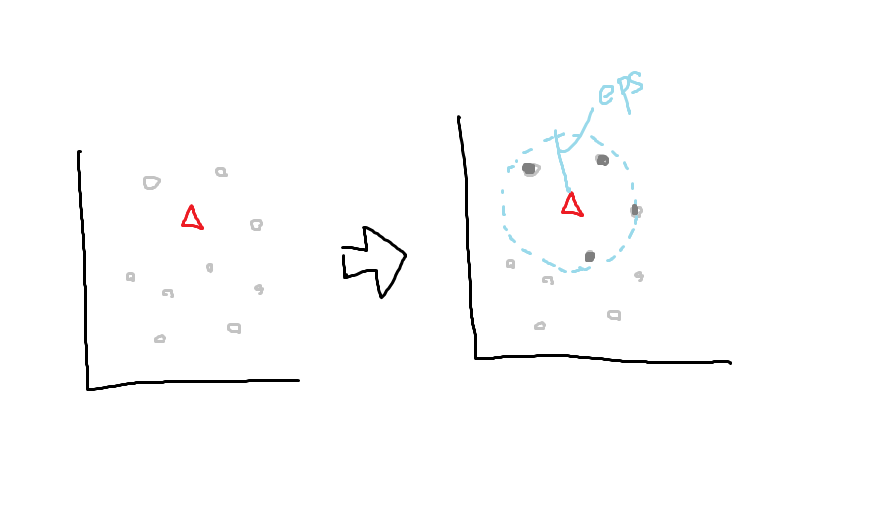
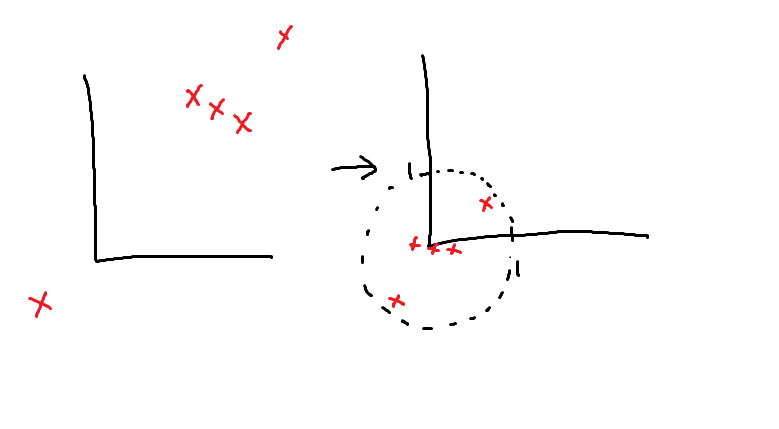
半径eps内にあるデータは、境界ポイントとして扱う。
各境界ポイントに対しても同様の処理を行う。
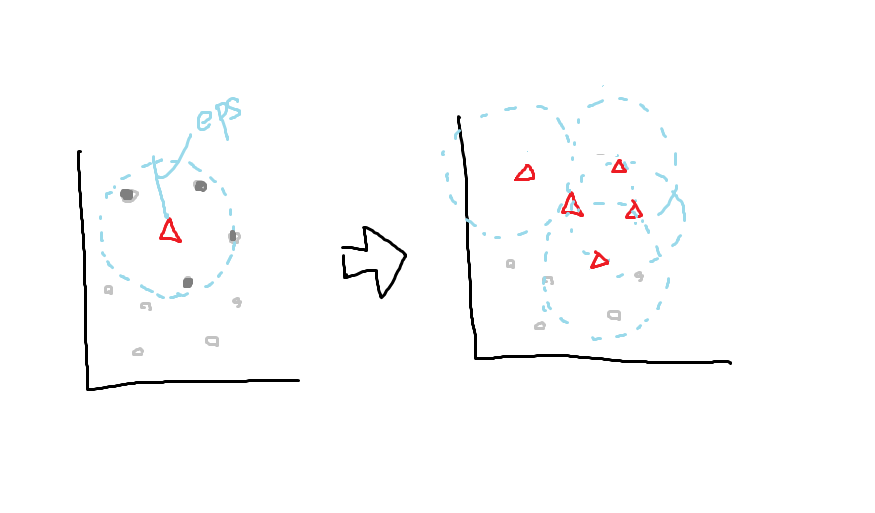
最終的に、データはコアサンプル、境界ポイント、ノイズの3種類に分類される。