以前、Custom Vision Serviceを使ってみたという記事を書きました。そのCustom Vision ServiceがUpdateされて写真のタグ付けだけでなく、写真の中のObject Detection(物体検出)もできるようになったのでまたまた使ってみました。
注:Object Detectionは2018/09/28時点でプレビュー
Custom Vision Serviceとは
Custom Vision Serviceの概要については以下の記事に書いています。
Custom Vision Serviceを使ってみた
実際にやってみる
前回は写真に写っている犬の犬種を当てるというようなモデルを作成したので、今回も同じテーマでモデルを作って見たいと思います。
[NEW PROJECT]から新しいプロジェクトを作成します。

必要な情報を入れて[Project Types]は[Object Detection]を選択します。

空のプロジェクトができるのでトレーニング用の写真を登録します。[Add images]を選択します。
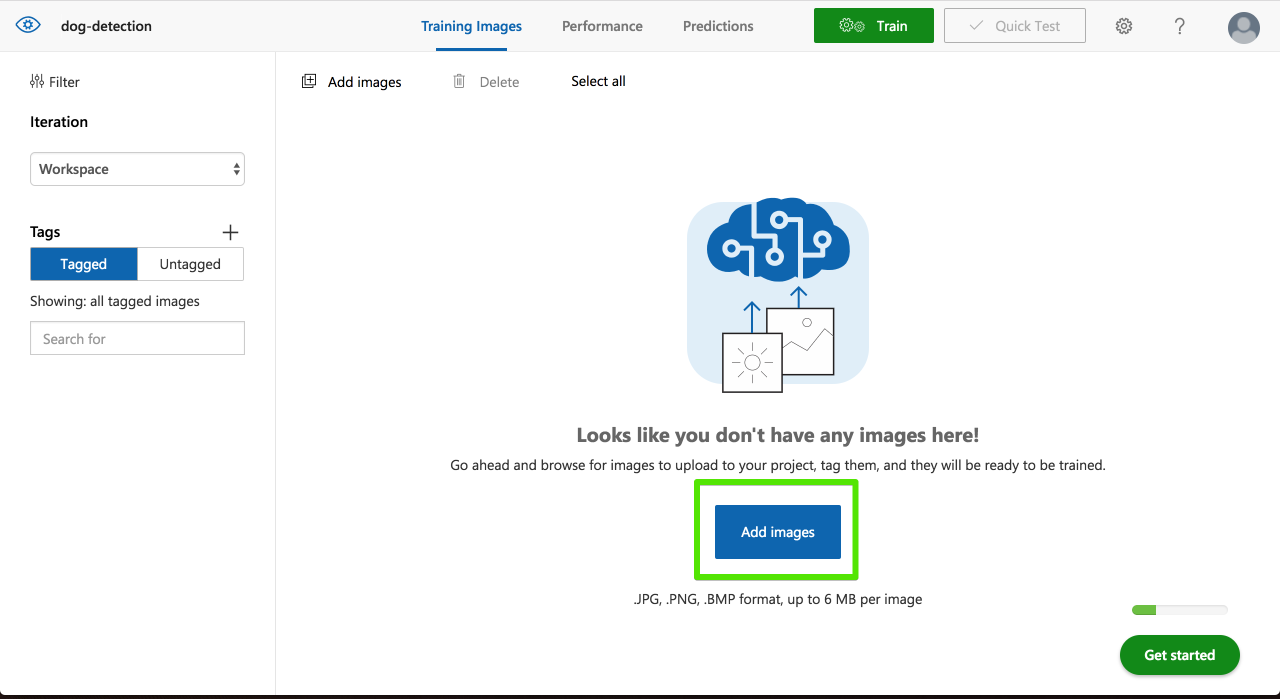
訓練データを選択して[Upload XX files]を選択。
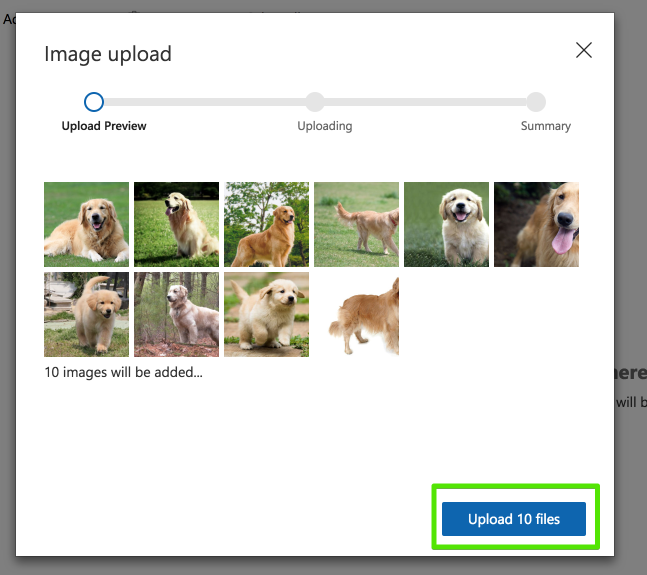
アップロードが完了したら[Done]

左ペインの[Tags]の[Untagged]の中にアップロードした画像は入ります。
表示されている画像のどれかを選択します。
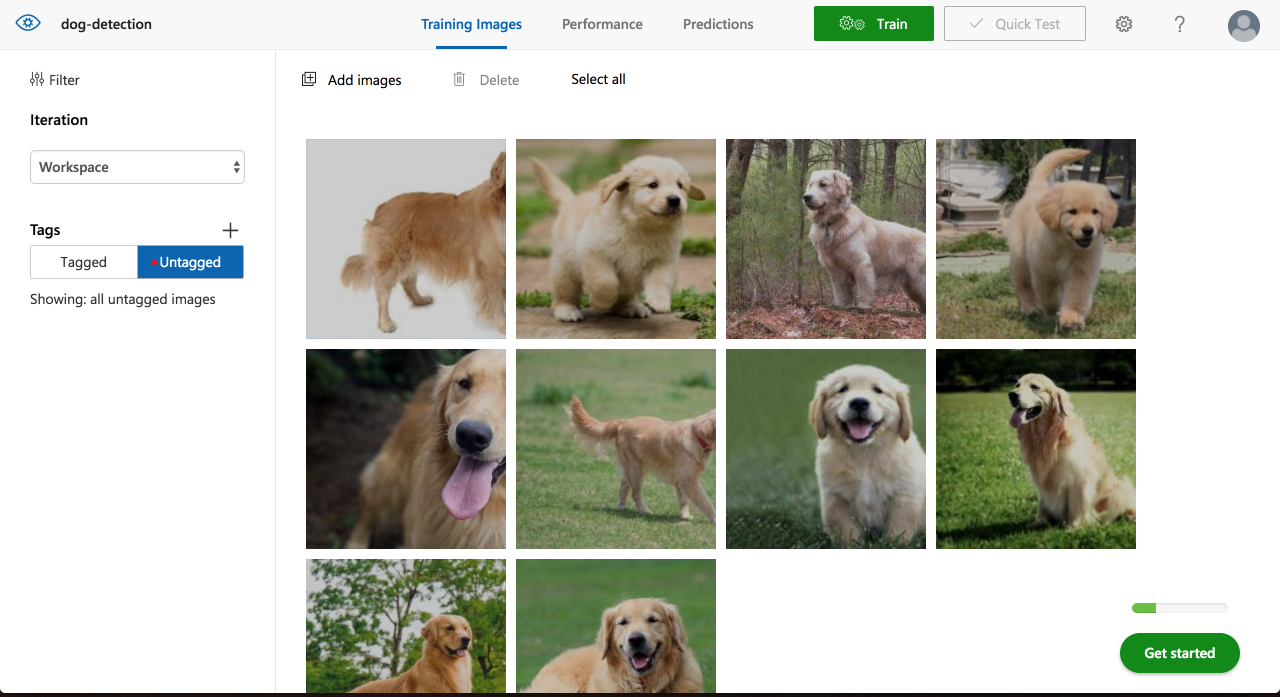
写真をタグで分けるのであればまとめてタグ付けなどができるのですが、Object Detectionは画像内での物体の位置の情報が必要になるのでここからは1枚1枚の操作になります。
画像を選択するとプレビューが表示されるので、対象が写っているエリアをマウスドラッグで選択しタグを入力します。

アップロードした写真に対してどんどん同じ操作をします。
画面右にある[>]を選択することで次の訓練データを表示することができます。
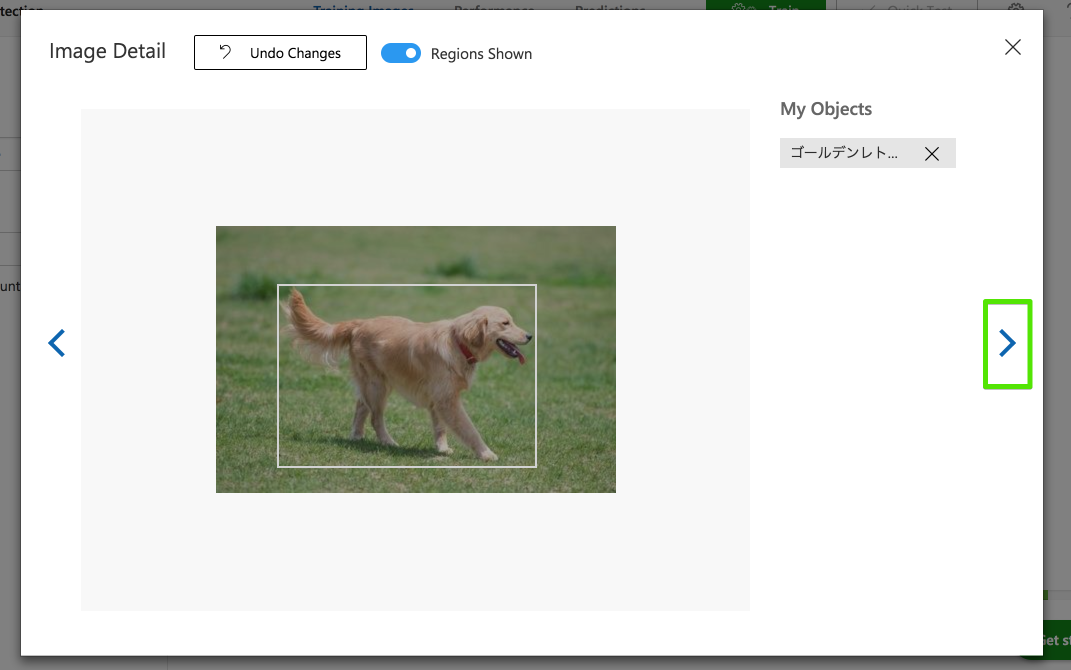
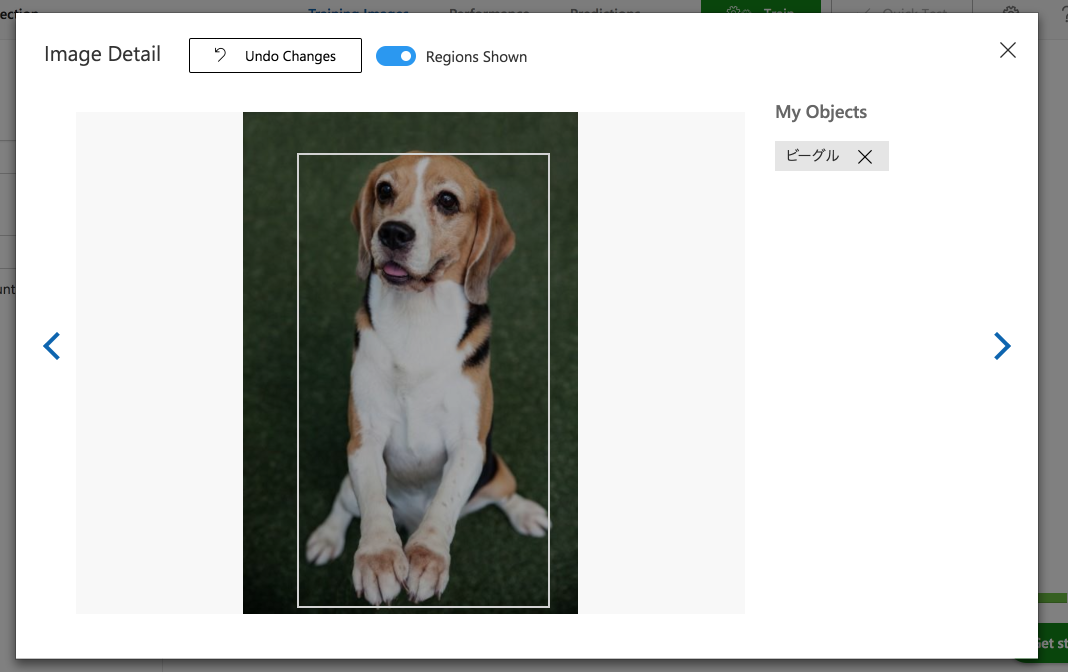
同じようにビーグルもタグ付け
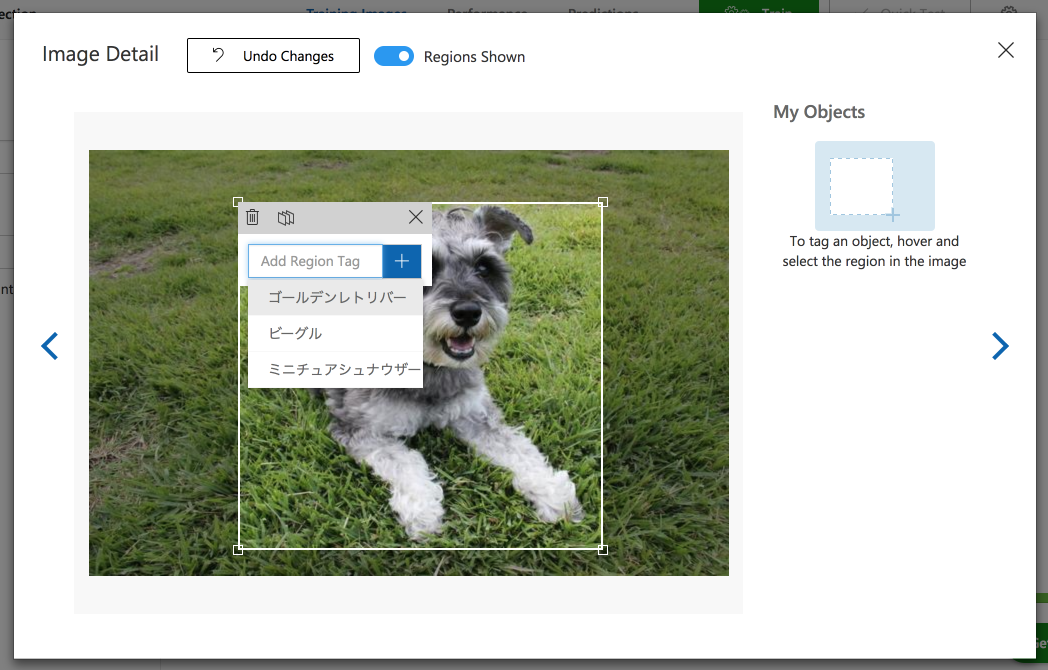
ミニチュアシュナウザーもタグ付け
2頭写っている写真もそれぞれタグ付けします。

全てのデータのラベリングをしたら先ほどの左ペインの[Tags]の[Tagged]の中に全ての訓練データが入ります。
ここではまだ学習は終了していません。画面右上の[Train]を選択して学習を開始します。

【備考】タグあたりの写真の枚数が15枚未満だと学習を行うことができません。
公式ドキュメントの前提条件には
A series of images to train your classifier (with a minimum of 30 images per tag).
とあるのですが、なぜここに差があるのかは不明です。

正常に学習が完了すると以下のような画面に遷移します。
とりあえずモデルをテストしたいので画面右の[Quick Test]を選択します。

評価データは画像のURLまたはローカルから選択することができます。

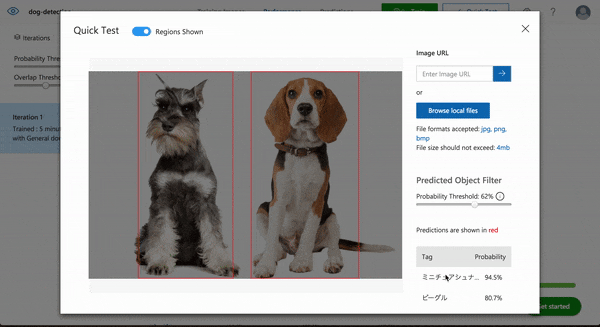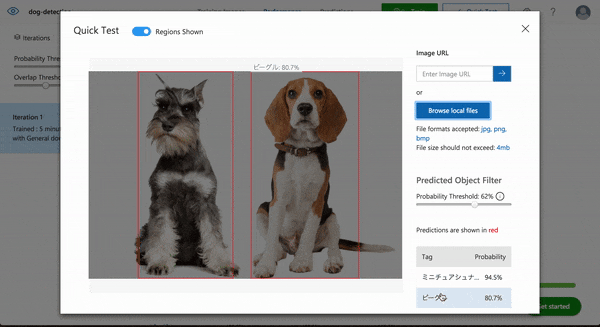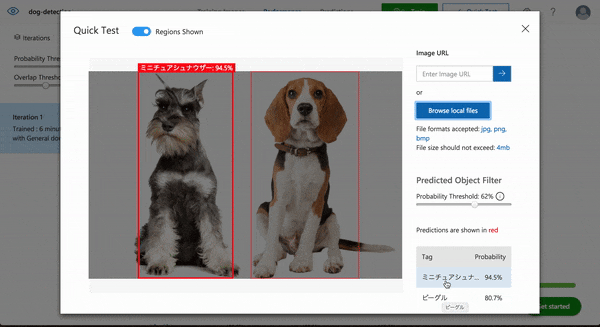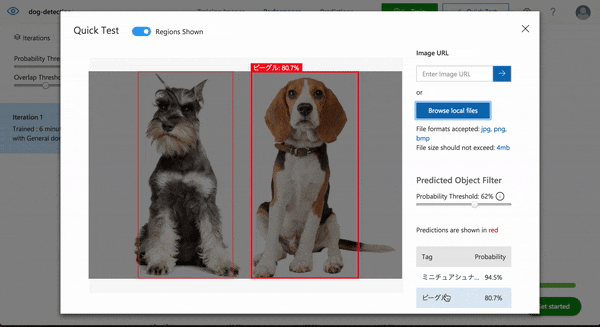
まずはビーグル1頭の写真を評価してみます。

結果は98.6%の確率で赤枠の部分がビーグルであると判定されました。

では次にビーグルとミニチュアシュナウザーそれぞれ1頭ずつの画像ではどうでしょうか。

Well done!!
それぞれの位置がとタグ付けがほぼ完璧にできていますね。
しかも複数の犬種が混ざった写真は学習させていないのに1枚の写真に写った複数の犬種を検出することができました。
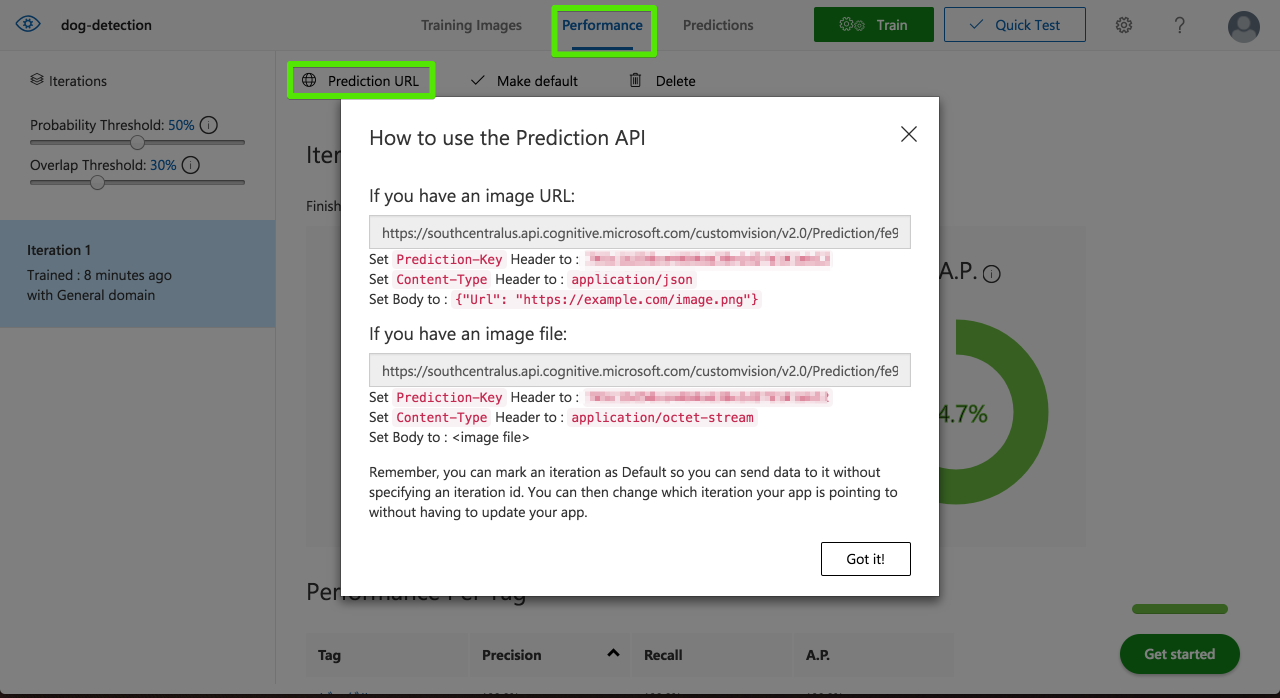
作成したモデルは今までのCustom Vision Serviceと同じようにWeb API経由で使用することができます。
[Performance]から[Prediction URL]を選択して接続情報を入手できます。
モデルのExportはまだできない
Classificationのプロジェクトタイプで可能なTensor Flow, CoreML, ONNXファイルへのExport機能は2018/09/28時点ではまだ使用できないようです。
さいごに
この機能のリリースが2017年後半だったと記憶しているのでだいぶ時間が経ってしまいましたがCustom Vision Serviceの進化を実感しました!