個人開発でサービスを作り始めて、気がついたら2年も経っていました。
気軽な気持ちで作り始めたのですが、思いの外色々なことに手を出してしまったので、
利用した技術などをまとめてみます。
作ったもの
YouTubeのライブ配信風の画面に向かって話しかけると、
音声を認識してAIがスーパーチャットを送ってくれる、
その名も「AIスパチャ」です。
良かったら遊んでみてください。
作るきっかけ
YouTubeでひろゆき氏の配信を見ていた時に、
「私もひろゆきさんみたいに質問回答の配信をやってみたいです。
けれどいざ配信をしてみても視聴者が少なく、質問なんて全くきません」
といった質問がありました。
確かに、ひろゆき氏のように、何千人も視聴者がいて、ガンガンとスパチャが送られてきたらそりゃ楽しいですが、
普通の人はまずスパチャなんて送られません。
そもそも実際にYouTubeライブをやることのハードルが高すぎます。
ということで、
誰でも気軽にYouTubeライブっぽいことができて、
ダミーでもいいからスパチャをもらえる体験ができたら面白いんじゃないかと思い、
このサービスを作ってみました。
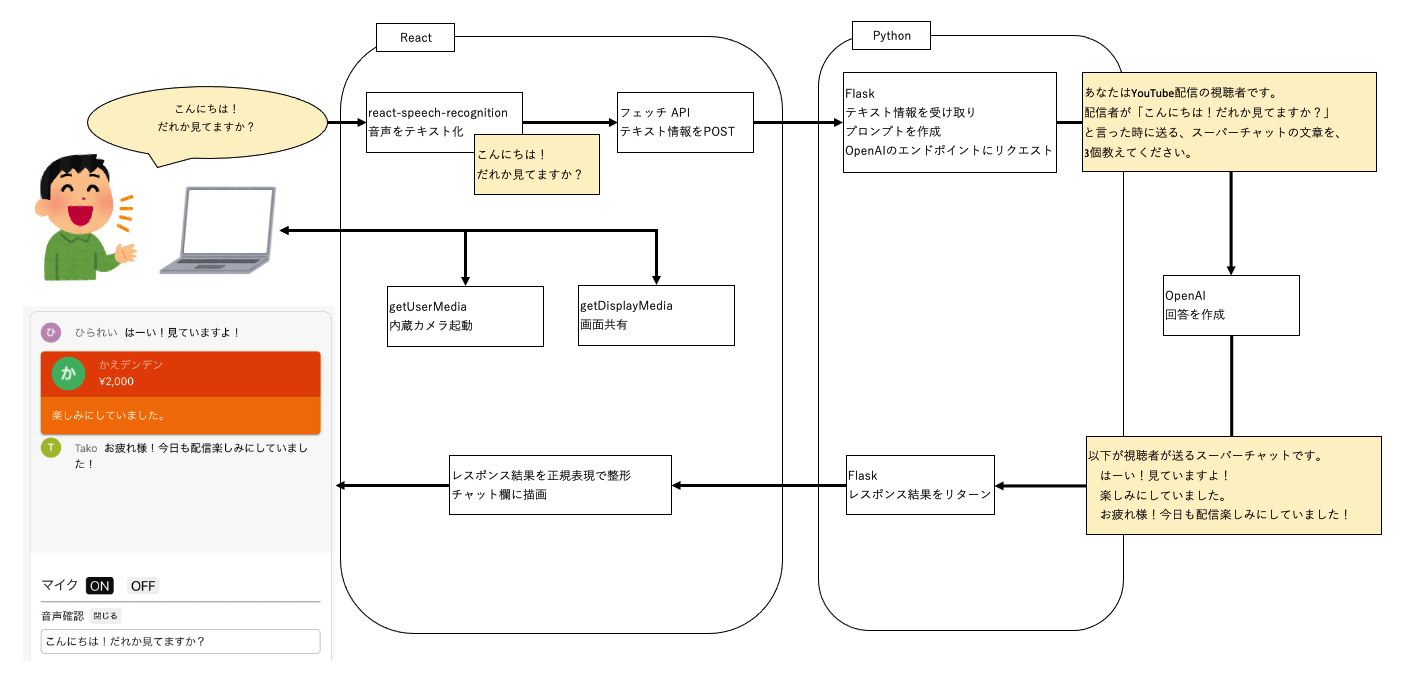
システム全容
フロントエンドはReact、バックエンドはPythonを使っています。
React
YouTubeライブ風の画面を作っています。
内蔵カメラの起動や、画面共有ができるようになっています。
チャット欄とスーパーチャットの描画がやっかいでした。
また音声認識ライブラリで音声をテキスト化しAPIでPOSTする、といった実装もしています。
Pyhton
APIで送られてきたテキストから、OpenAIのAPIに渡すプロンプトを作成。
返ってきた回答をフロントエンドに渡しています。
図にするとこんな感じです。
使ったもの
実際に使った技術の詳細です。
内蔵カメラ
MediaDevices.getUserMedia()メソッドを使用して、内蔵カメラを起動します。
これで顔出し配信ができるようになりました。
https://developer.mozilla.org/ja/docs/Web/API/MediaDevices/getUserMedia

画面共有
MediaDevices.getDisplayMedia()を使うとディスプレイのキャプチャを表示することができます。
これでゲーム実況もできるし、ライブコーディングなんかもできますね。
https://developer.mozilla.org/ja/docs/Web/API/MediaDevices/getDisplayMedia

音声認識
音声をテキストに変換する必要があるので、
react-speech-recognitionという音声認識ライブラリを使用しました。
とてもいい精度です。
https://www.npmjs.com/package/react-speech-recognition

Flask
簡単なAPIを作るのに向いているとのことだったので、
バックエンドはPythonのFlaskフレームワークを使用しています。
https://flask.palletsprojects.com/en/2.3.x/
OpenAI
生成AIの種類もだいぶ増えてきましたが、今回はOpenAIのAPIを使用しています。
この開発を始めた頃は、まだChatGPTなんてなくて、
とりあえずYouTubeライブ風の画面をReactで実装するところから始めました。
肝心の「AIがスパチャを送る」という機能をどうしようか…?
一から機械学習の勉強をするべきか…?
などと考えていたら、いつの間にかChatGPTなるサービスが生まれました。
そしてAPIも提供されたので、もうこのためにあるとしか考えられず、即座に導入しました。
https://openai.com/
終わりに
今回はざっくりとシステムの全容をまとめてみました。
また気が向いたら、実装の細かいところや、ハマったポイントなど記事にしていこうと思います。
気になることがあったらコメントで教えてください!