はじめに
前回までで画像認識について勉強してきたので、次のステップとしてこちらを参考に画像の物体検出に取り組んでみた。まだYOLOの触り部分なので随時更新するとして、とりあえず物体検出を体験するのと、自前データを使った学習からの検出が成功したので備忘録までに。
物体検出
物体検出とは、取り込んだ画像の中から「物体の位置、種類、個数」を特定する技術のこと。言い換えれば、物体の種類だけを特定する画像分類に、さらに位置と個数を検出する能力が備わったものである。こちらのサイトで物体検出から使われるディープラーニングモデルまで詳しく説明されていてとても分かりやすかった。
YOLO
YOLOは検出と識別という2つの処理を同時に行うため、他のモデルに比べて処理速度が速いのが特徴である。YOLOと一言に言ってもその種類は色々あるが、今回はYOLOv5sを使って自前データの学習と検出を行った。
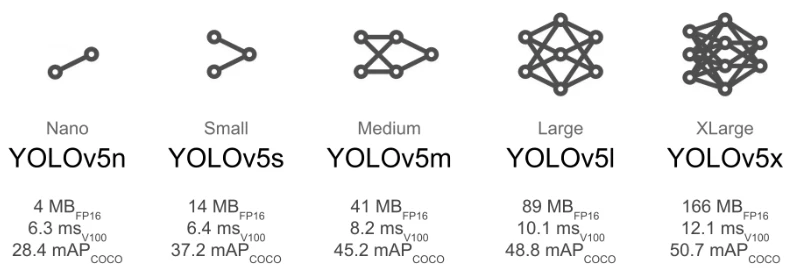
YOLOV5より引用
データの用意
今回は既存のモデルで物体検出をするだけでなく、自前データで学習させてみたかった。そこで、YOLOで識別できるデフォルトの80クラス以外のクラスとして、大型船舶のアノテーション付き画像データを30枚(train:20枚, valid:5枚, test:5枚)作成した。画像を探して保存してアノテーション付けて、というこの作業が割と手間がかかってめんどくさかった。。。
データの作成にはこちらを参考にして、LabelImgを使った。インストールしたフォルダを解凍すれば中にlabelImgというアプリケーションがあるので、それを起動すればよい。
作成画面、物体が写っている矩形領域を指定して保存する。
パパッと検索して集めたので引き延ばすと画質が悪い()

trainディレクトリの中の船の画像(.jpg)とアノテーションファイル(.txt)
アノテーションファイルの中身はこんな感じ。predefined_classes.txtに書き込んだクラスと矩形領域の四隅の位置情報情報が記載されている。

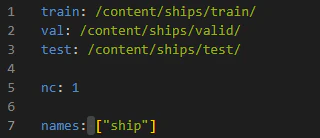
yamlファイルの中はこんな感じ。ゼロからyamlファイルを作るやり方が分からなかったので、YOLOの中にあったyamlファイルをダウンロードして中身と名前を変えるという力業で解決している。「:」の後ろに空白を入れないとエラーが出るので注意。
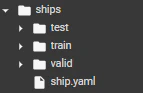
ここまで作ってきたアノテーション付き画像データ(train:20枚, valid:5枚, test:5枚)とyamlファイルは、shipsという名前のディレクトリの中にまとめている。
実装
1.ライブラリをインポート
必要なライブラリを読み込む。
# 描画に使う
import matplotlib.pyplot as plt
%matplotlib inline
# zipファイルを取り扱う
import zipfile
# 画像を読み込む
from PIL import Image
# アップロードに使う
from google.colab import files
2.YOLO v5をGoogle Colabにインストール
YOLO v5のリポジトリをクローンする
# YOLOv5をクローン
!git clone https://github.com/ultralytics/yolov5
次に、クローンしたリポジトリ内にあるrequirements.txt を用いて動作に必要なライブラリをインストールする。
# 設定ファイルrequirements.txtに従ってパッケージが一括でインストールされる。
%cd /content/yolov5/
!pip install -r requirements.txt
3.YOLO v5で物体検出
まずはテキトーな画像で物体検出
なんでもいいので画像をアップロードしてみる。今回は「sample.jpg」という名前の画像をアップロードした。(以下その前提で進める)
# 検出したい画像をアップロード
files.upload()
アップロードしたら、YOLOに流して物体検出してみる。
クローンしたリポジトリである yolov5 ディレクトリに移動して、コマンドを実行する。(↑から順当に実行していれば既にyolov5 ディレクトリ直下にいるので、そのまま実行できるはず。)
# source:画像のフォルダ、または画像のパスを指定。→ /content/sample.jpg
# weights:事前学習済みモデルの重みファイルを指定。
# conf:指定した値以下の確率値は表示しない。
# name:ディレクトリ名 → sample
# %cd /content/yolov5/
!python detect.py --source /content/yolov5/sample.jpg --weights yolov5s.pt --conf 0.3 --name sample --exist-ok
colabファイルに置いているデータのパスは右クリックで取得できる。
コマンドを実行すると「/runs/detect/sample」というディレクトリが作成され、そこに物体検出された画像が出力される。
物体検出された画像を見てみる。
img = Image.open("/content/yolov5/runs/detect/sample/sample.jpg")
plt.imshow(img)
plt.show()

↑は海老名SAの下り側で撮った写真。バイク、車、人を検出できている、すごい。
4.自前データをアップロード
物体検出を体験できたので、本題の自前データで学習をさせてみる。
まずは事前にローカル環境で作っておいたshipsディレクトリをzip形式にして、colab上にアップロードする。
# ships.zipをアップロード
files.upload()
アップロードしたら解凍する。yolov5ディレクトリ内ではないのでパスに注意。
# ships.zipを解凍してディレクトリ直下に置く
with zipfile.ZipFile("/content/yolov5/ships.zip", mode="r") as f:
f.extractall("/content/")
まずは学習させる前のYOLOにtestデータを流した時の結果を見てみる。
# ディレクトリ直下の/content/ships/testを使って物体検出
!python detect.py --source /content/ships/test --weights yolov5s.pt --conf 0.3 --name sample --exist-ok
testディレクトリの中には↓のような名前でtest画像を5枚入れている。
物体検出された画像を見てみる。
for i in range(5):
img = Image.open(f"/content/yolov5/runs/detect/sample/ship{26+i}.jpg")
plt.imshow(img)
plt.show()





testデータを集めているときに、帆船や模型船、宇宙戦艦だとどうなるんだろう?と思ったのでtestデータにはいろいろ入れてみた。
YOLOがデフォルトで識別できるクラスに「boat」があるため、船舶はボートとして検出されている。まぁ、そうだよね笑 逆に言えば、ボートの特徴量をしっかりと学習できているということ。帆船もしっかり帆の部分を含めてボートとして検出していた。学習データにヨットとかがあったのかな、、?ちなみにこれは海技の練習船「海王丸」で、実は乗ったことがあるので持ってきてみた。
コンテナ船の模型船に関しては「train」として検出していた。列車要素は全くないが、コンテナが列車に見えたのだと思う。学習データに貨物列車とかがあると間違えそう。普通のボートにはない特徴なので仕方ない。
最後に遊びで入れた超弩級宇宙戦艦は、まさかの「airplane」として検出された。ある意味間違ってない笑 YOLOのデフォルトの学習データに大型船舶がないため、安定翼とかが翼としての特徴量になったのかも?戦艦とか駆逐艦を学習データに入れたらしっかり検出しそう。コスモゼロだけ飛行機と検出されなかったのは、さすがに現実の飛行機と形がかけ離れ過ぎていたからか。
5.自前データで学習
本題、用意した船舶の画像データで学習させる。
用意するデータ数やbatchサイズによってexpが複数になったりするので注意。
# 学習
!python train.py --img 640 --batch 5 --epochs 200 --data /content/ships/ship.yaml --weights yolov5s.pt
実行すると、学習したパラメータがruns/train/exp/weights/ディレクトリの中に格納される。best.pt が学習中でもっとも精度が高かったもの、last.ptが最後のepocのものになる。
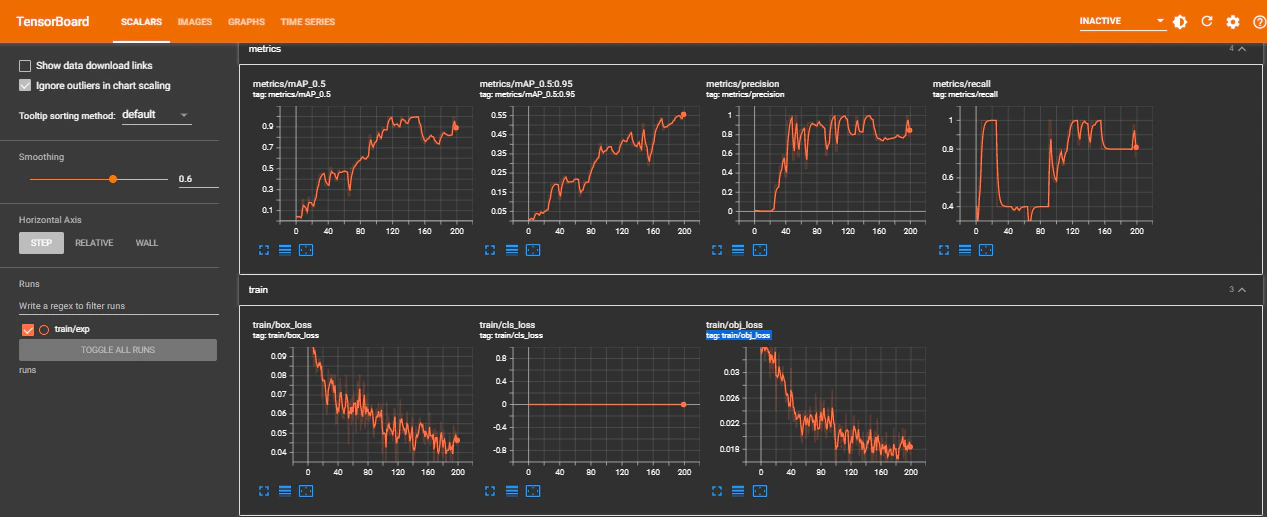
TensorBoardを利用すると学習の様子をグラフで確認できる。機能が色々と多いので紹介だけ。
# tensorboardの表示
%load_ext tensorboard
%tensorboard --logdir runs
それでは学習後の重みを使って物体検出をしてみる。
人によって用意するデータ数やディレクトリ構造次第でパスが変わるので、そこはエラーを見ながら適宜合わせていく必要がある。
# testデータで学習後の物体検出
!python detect.py --source /content/ships/test --weights /content/yolov5/runs/train/exp/weights/best.pt --conf 0.25 --name sample_trained --exist-ok --save-conf
コマンドを実行すると「/runs/detect/sample_trained」というディレクトリを作成し、物体検出された画像を出力する。

検出結果を見てみる。
for i in range(5):
img = Image.open(f"/content/yolov5/runs/detect/sample_trained/ship{26+i}.jpg")
plt.imshow(img)
plt.show()



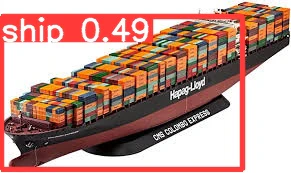

船舶の画像で学習させたことで、「boat」ではなく「ship」として検出できるようにいる。コンテナ船も「train」ではなく「ship」と検出できている。今回学習に使ったのはたった20枚だけだったので、もっと枚数を増やせばより精度は高くなると思う。
ヤマトは「airplane」として検出されなくなった。船舶の特徴量を学んだことで飛行機ではないということには気づいたっぽいが、船だとは認識できていない。まぁこれ船じゃないけど笑 訓練データには船の正面からの画像データもあったので右上の画像を船として検出しないかな?と思っていたが、さすがに無理があったか。(それか単に枚数が少ないせいか)
おわりに
今回は自前データでYOLOを使った物体検出をやってみた。コマンドを実行するだけで簡単に試すことができたが、アノテーション付き画像データを用意するのが本当に手間だった。なにかコンペから探してきてもよかったかもしれない。
ただやはりコマンドだけでやるのは慣れないので、今後はPyTorchなどで色々と中身をいじりながら検出を行う方法も調べていきたいなぁと思う。
参考
YOLO v5で物体検出と学習をする方法 Google Colabで動作
labelImgのインストール方法と使い方
LabelImg
YOLOv5を使った物体検出