はじめに
この記事はZeals Advent Calendar 2020の15日目の記事です。
ZealsでMLエンジニアをやっている三宅です。ZealsではPythonを使って主にCV予測の開発に携わっています。
本日のAdvent Calendarでは、World Happiness Reportにおいて毎年行われている世界幸福度調査を統計学的手法を用いて分析をしていきたいと思います。
背景
2020年になってFacebookのユーザー数が27億人を超え、今や世界中の人々がSNSを日々利用して友人や家族とオンラインで交流をしている。「我々が普段利用しているSNSが、現在どれだけ世界において"幸せ"につながっているのか?」を考えるために分析を始めた。
データコレクション
・世界幸福度調査 (2015年 - 2019年) : Kaggle『World Happiness Report』
・国別Facebook利用者数 (2020年) : Facebook Users by Country 2020
・世界各国の特徴 (2017年) : Kaggle『Countries of the World』
import
import matplotlib.pyplot as plt
import seaborn as sns
import os
import geopandas as gpd
import json
from bokeh.io import output_notebook, show, output_file
from bokeh.plotting import figure
from bokeh.models import GeoJSONDataSource, LinearColorMapper, ColorBar
from bokeh.palettes import brewer
import statsmodels.regression.linear_model as sm
データ前処理
データセットによって国名がバラバラ('USA'だったり'United States of America'だったり...)なので、Pythonのパッケージであるcountry-converterを使用してデータセットを統一。
world_facebook_users_list = world_facebook_users_df["Country"].tolist()
world_facebook_users_list = cc.convert(names = world_facebook_users_list, to = 'name_short')
world_facebook_users_df['Country'] = pd.DataFrame(world_facebook_users_list)
また、各国のFacebookのユーザー数も、国によって人口が違うため「使用率(ユーザー数/人口)」のカラムを追加。
world_facebook_users_df['pop2020'] = world_facebook_users_df['pop2020']*1000
world_facebook_users_df['facebook_user_rate'] = world_facebook_users_df['facebookUsers'] / world_facebook_users_df['pop2020']
データセットによってmissing valueがあったため、手動で補完。
country_region_missing_values_df = pd.DataFrame({"Country":['Puerto Rico', 'Belize', 'Somalia', 'Somaliland Region', 'Namibia', 'South Sudan', 'Taiwan Province of China',
'Hong Kong S.A.R., China', 'Trinidad & Tobago', 'Northern Cyprus', 'North Macedonia', 'Gambia'],
"Region":['Latin America and Caribbean', 'Latin America and Caribbean', 'Sub-Saharan Africa', 'Sub-Saharan Africa', 'Sub-Saharan Africa', 'Sub-Saharan Africa', 'Eastern Asia',
'Eastern Asia', 'Latin America and Caribbean', 'Western Europe', 'Western Europe', 'Sub-Saharan Africa']})
country_region_df = country_region_df.append(country_region_missing_values_df)
データセット紹介
world_happiness_df
世界幸福度調査のデータセット。今回の分析ではメインで使用するため、各カラムを説明する。
# 最初の5行だけ表示
world_happiness_df.head()

- カラム
- Country : 国名
- Happiness Score :幸福度の指標
- GDP : GDPの指標
- Family : 家族の指標
- Health : 寿命の指標
- Freedom : 自由の指標
- Corruption : 政府の安定性の指標(値が高いほど政府が安定している)
- Generosity : 寛大さ(優しさ)の指標
- Dystopia Residual : ディストピアとの乖離*の指標
- Year : 年
- Region : 地域
*ディストピアとの乖離:World Happiness Reportは、「(想像上の)最悪の国」と各国の乖離を数値で表すため、"Dystopia Residual"をカラムの1つとして加えた。Happiness Scoreが低ければ、ディストピアとの乖離が少ないため'Dystopia Residual'は低い。
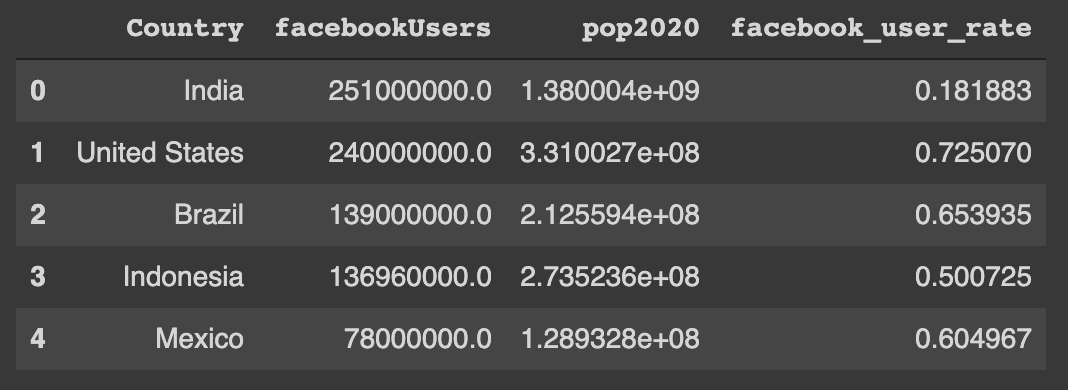
world_facebook_users_df
各国のFacebookユーザー数のデータセット。上記でも説明したが、分析で主に使用するのは「ユーザー数」ではなく「使用率(facebook_user_rate)」だ。
world_facebook_users_df.head()
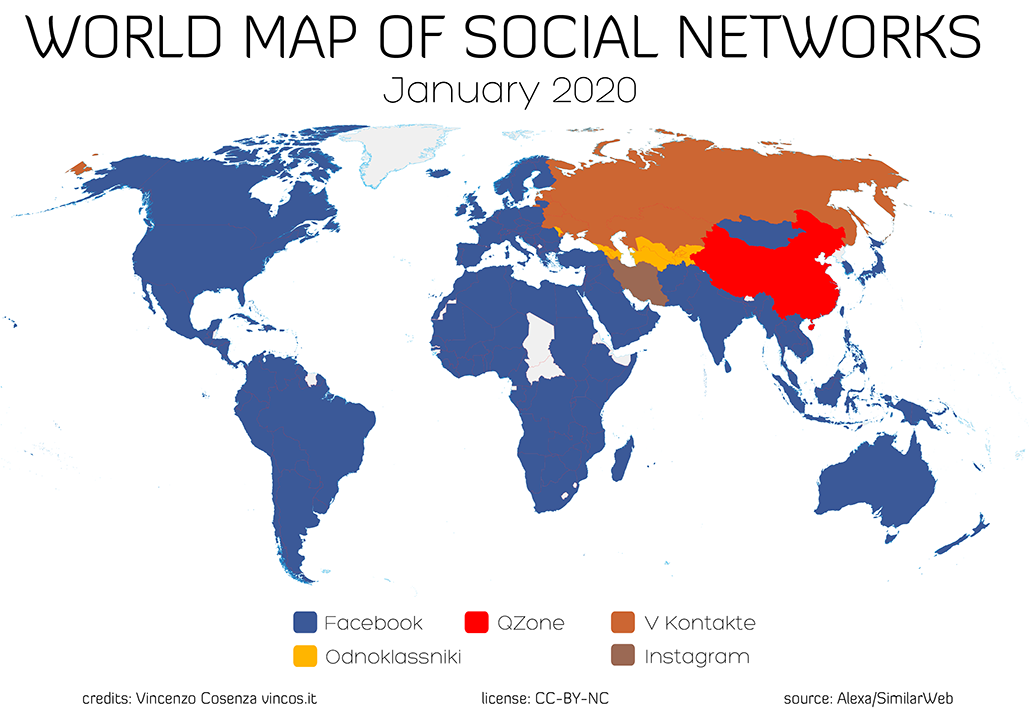
下図は、各国において一番利用されているSNSをマッピングしたものであり、Facebookは2020年においてほとんどの国で利用者数(アクティブユーザー数)が最多であることが分かる。従って、"SNSの普及率"という指標にピッタリだ。
world_country_features_df
各国の特徴を含むデータセット。気候や農業などの特徴量が入っている。
world_country_features_df.head()

分析
世界幸福度指標マッピング
geosource = GeoJSONDataSource(geojson = json_data)
palette = brewer['YlGnBu'][8]
color_mapper = LinearColorMapper(palette = palette, low = 2, high = 8)
tick_labels = {'2':'2', '3':'3', '4':'4', '5':'5', '6':'6','7':'7', '8': '>8'}
color_bar = ColorBar(color_mapper=color_mapper, label_standoff=8,width = 500, height = 20,
border_line_color=None,location = (0,0), orientation = 'horizontal', major_label_overrides = tick_labels)
p = figure(title = 'Happiness Among Countries', plot_height = 600 , plot_width = 950, toolbar_location = None)
p.xgrid.grid_line_color = None
p.ygrid.grid_line_color = None
p.patches('xs','ys', source = geosource,fill_color = {'field' :'Happiness Score', 'transform' : color_mapper},
line_color = 'black', line_width = 0.25, fill_alpha = 1)
p.add_layout(color_bar, 'below')
output_notebook()
show(p)
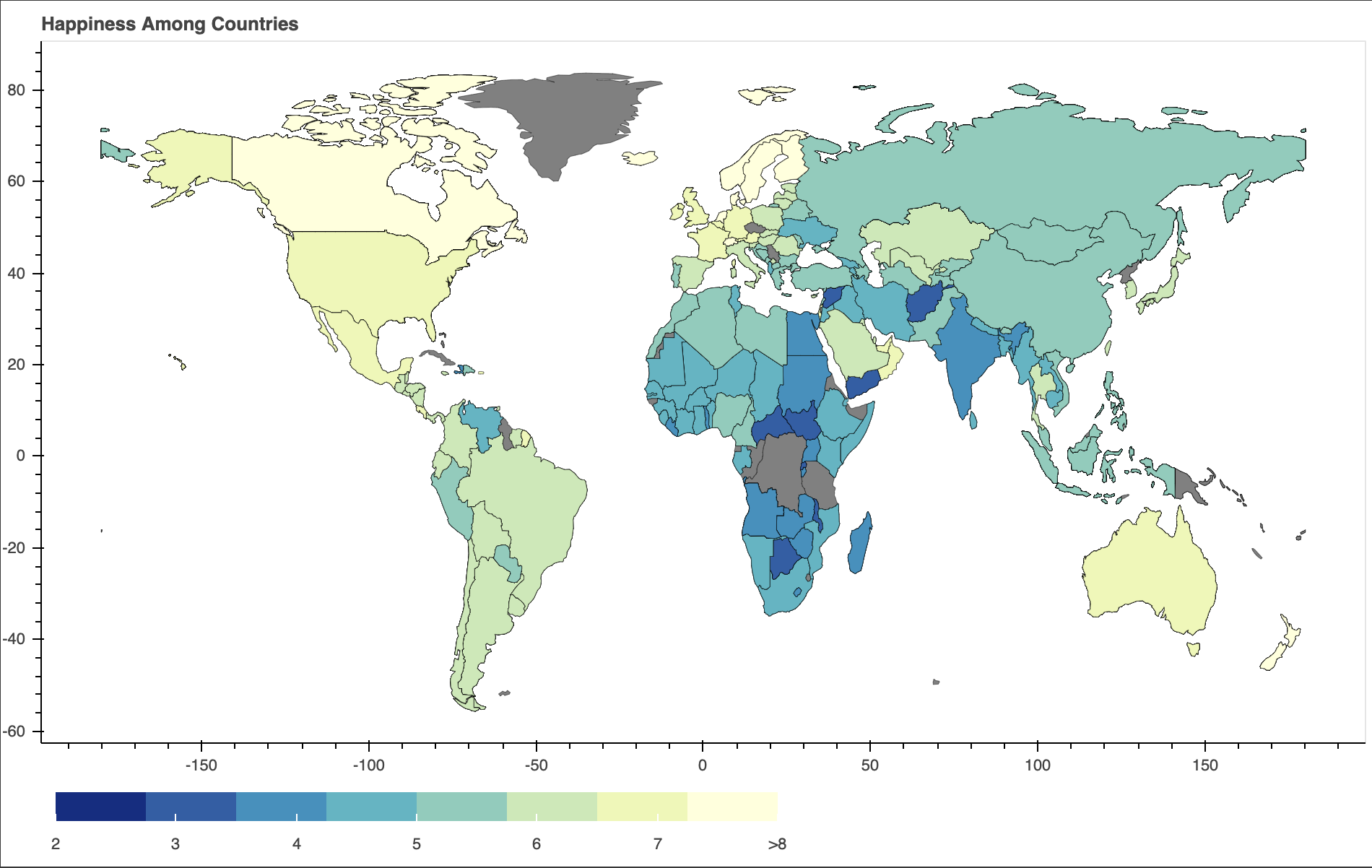
色が明るいほどHappiness Scoreが高い。アフリカ諸国や中東諸国はHappiness Scoreは低く、北米やオセアニア諸国は高いことが分かる。
world_happiness_df 分析
Spearman相関係数マトリックス
では、どのような要素が各国のHappiness Scoreに影響を与えているのであろうか?
これを考えるために、Spearman相関係数マトリックスを用いて、各要素の関係図(相関係数による行列)を描く。
import matplotlib.pyplot as plt
import seaborn as sns
test_cormatrix_df = world_happiness_2017_df.drop(['Year', 'Dystopia Residual'], axis = 1)
spearman_cormatrix= test_cormatrix_df.corr(method='spearman')
fig, ax = plt.subplots(ncols=2,figsize=(24, 8))
sns.heatmap(spearman_cormatrix, vmin=-1, vmax=1, ax=ax[0], center=0, cmap="viridis", annot=True)
sns.heatmap(spearman_cormatrix, vmin=-.25, vmax=1, ax=ax[1], center=0, cmap="Accent", annot=True)
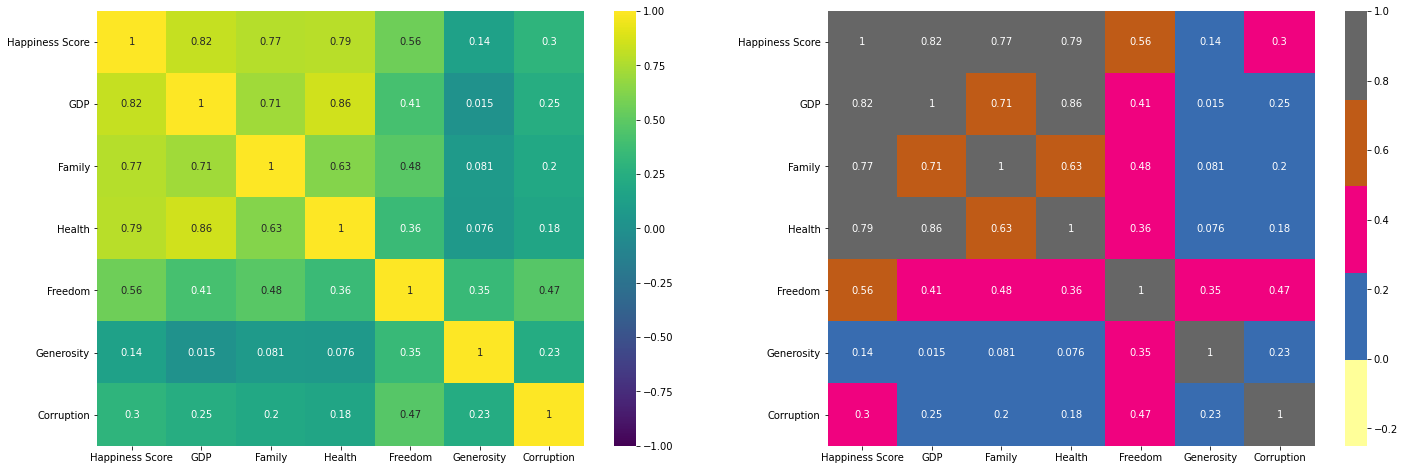
この図を見る限り、GDP・Family・Healthの3つが特にHappiness Scoreに正の相関であることがわかる。逆に、CorruptionやGenerosityはあまりHappiness Scoreに起因していない。ここでは相関係数で判断したが、次はp値で判断していく。
ステップワイズ法
次に、ステップワイズ法を用いる。ステップワイズ法とは、
説明変数の候補がたくさんあれば、『とりあえずすべての説明変数を重回帰分析にかけてp値が小さく、t値の絶対値が大きいものを探索する』というやり方をステップワイズ法と言います。
というものである。説明変数に各指標を指定し、Happiness Scoreを被説明変数とする。そして、p値が全て0.05(場合によって0.1)以下のもの以外を説明変数から取り除く。
import statsmodels.regression.linear_model as sm
world_happiness_regression_df = pd.concat([world_happiness_2015_df, world_happiness_2016_df, world_happiness_2017_df], ignore_index=True)
world_happiness_stepwise_regression_df = world_happiness_regression_df
world_happiness_stepwise_regression_df = world_happiness_stepwise_regression_df.dropna()
world_happiness_stepwise_regression_df = world_happiness_stepwise_regression_df.drop(['Country', 'Year', 'Dystopia Residual'], axis=1)
x = world_happiness_stepwise_regression_df.drop(["Happiness Score"], axis=1)
y = world_happiness_stepwise_regression_df["Happiness Score"]
model = sm.OLS(y, x)
result = model.fit()
result.summary()
 Corruptionのp値を見ると、0.1以上であるため説明変数から取り除く。
Corruptionのp値を見ると、0.1以上であるため説明変数から取り除く。
相関係数とp値で見た際、やはりどちらもCorruptionはHappiness Scoreに大きな影響を与えず、GDP・Family・Healthは重要な指標なようだ。
world_countries_features_df
次に、world_countries_features_dfと、Happiness Scoreのカラムをmergeして分析していく。先ほど同様Spearman相関係数マトリックスを用いて考えていく。
world_countries_features_df = world_countries_features_df.merge(world_happiness_df, on = 'Country', how = 'right')
spearman_cormatrix= world_countries_features_df.corr(method='spearman')
fig, ax = plt.subplots(ncols=2,figsize=(24, 8))
sns.heatmap(spearman_cormatrix, vmin=-1, vmax=1, ax=ax[0], center=0, cmap="viridis", annot=True)
sns.heatmap(spearman_cormatrix, vmin=-.25, vmax=1, ax=ax[1], center=0, cmap="Accent", annot=True)
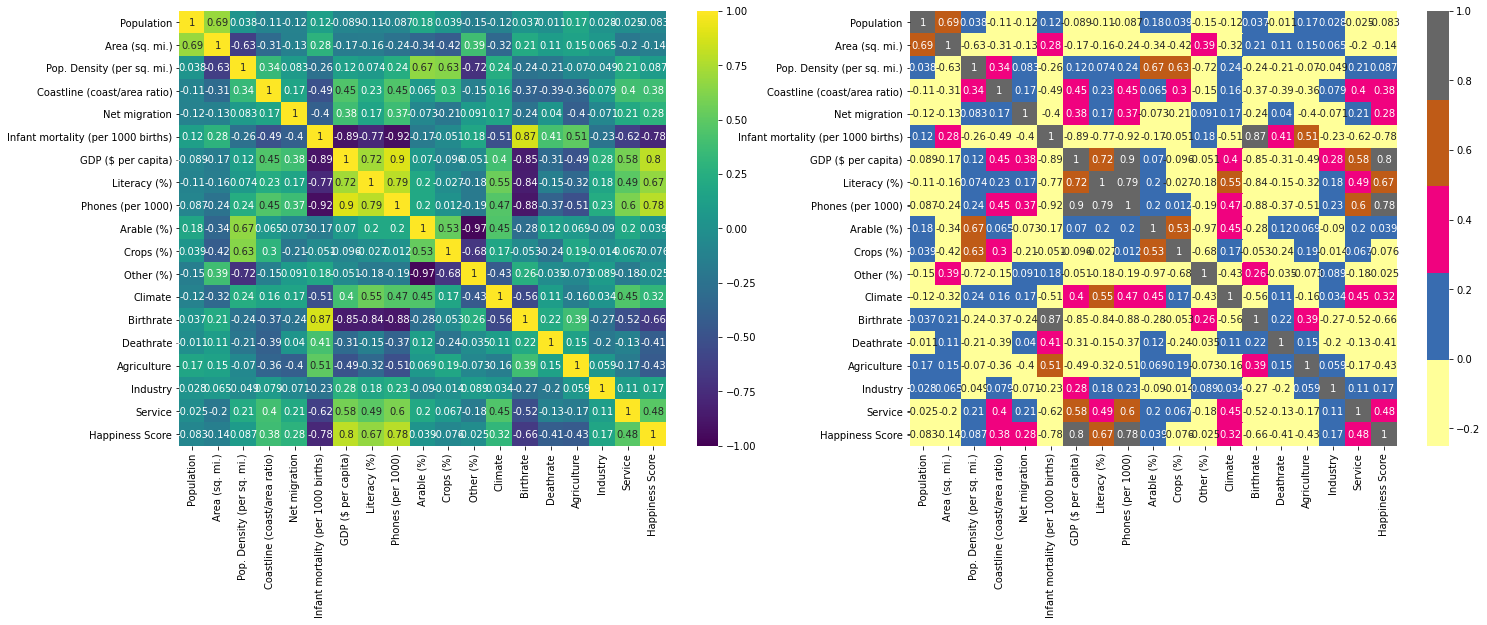
上図から、Happiness Scoreに相関しているのはGDP・Literacy(識字率)・Phones(携帯保有率)であることが分かる。
SNSとHappiness Score
上の分析から判明した重要な指標と、world_facebook_users_dfを結合し、Happiness Scoreとの相関係数を可視化する。
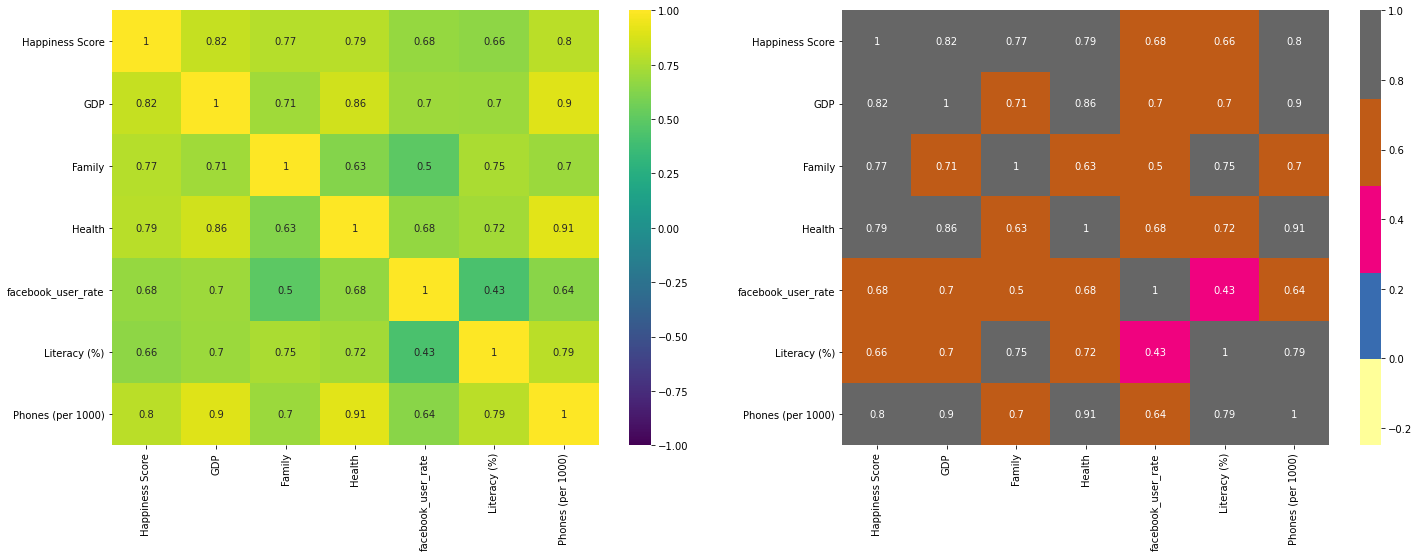
Facebookの利用率がHappiness Scoreに正の相関を持っていることだけでなく、各指標が相互に影響し合っていることが分かる。
結論
SNSは我々の「幸せ」に大きな影響を与えていることが分かった。また、各指標は相互に影響し合い「幸せ」を形成している。Phones(携帯の保有率指標)やfacebook_user_rateが重要指標に入っていることから、テクノロジーが我々の「幸せ」に密接に関わっていることを意味する。今後のSNSの拡大化・テクノロジーの進展が楽しみだ。
One more thing
つい先日、Netflixシリーズの "the social dilemma"を見た(とても面白かったのでおすすめする)。このドキュメンタリーは、SNSが若者間のイジメやうつ病を促進し、近年自殺率を上げていると主張している。そこで、私もここで少し分析を行ってみようと思う。

まず、国別自殺率のデータセットを用意し、world_facebook_users_dfとmergeする。ここで相関係数を見ていく。
x = world_suicide_sns_df['facebook_user_rate']
y = world_suicide_sns_df['total_suicide_rate']
correlation = x.corr(y)
print(correlation)
# 0.01890382448911069
pyplot.scatter(x, y)
pyplot.show()
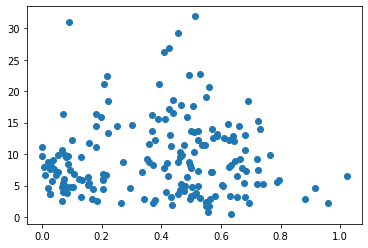
相関係数を見ても、グラフを見ても、ほとんど相関がないことが分かる。これだけの分析で一概に関係ないとは言えないが、この関係については既に研究が行われたみたい( New York Times 『Panicking About Your Kids’ Phones? New Research Says Don’t』)だ。「SNSの利用は自殺率に関連しない」ことが研究によって分かったという。
参考
- https://s3.amazonaws.com/happiness-report/2019/WHR19_Ch5.pdf
- http://www.sthda.com/english/wiki/correlation-matrix-a-quick-start-guide-to-analyze-format-and-visualize-a-correlation-matrix-using-r-software
- https://seaborn.pydata.org/examples/many_pairwise_correlations.html
- https://tanuhack.com/statsmodels-multiple-lra/
- https://pypi.org/project/geojson/
- https://pypi.org/project/country-converter/