はじめに
Linux上でファイルやブロックデバイスへのread/writeは基本的にはRAM上のページキャッシュを経由して行われます。
RAMへのアクセスに対してブロックデバイスへのアクセスはかなり遅いため、ページキャッシュはファイルへのアクセス速度向上に重要な役割を果たしています。
ページより小さいブロックデータ単位でデータにアクセスするためにbuffer_head型があります。また、Linuxではページキャッシュとinodeとを関連付けるデータ型としてaddress_spaceが存在します。
本記事では主に以下の観点でこれらついて説明を行いたいと思います。
参照しているLinuxカーネルのバージョンは4.19です。ソースコード中の日本語は私が追加したコメントとなります。
- ページキャッシュの単位について:ページキャッシュとbuffer_headとの関係
- ページキャッシュとaddress_spaceとの関係
- ページキャッシュの動作を具体例(sb_breadのコード)をもとに調査
ページキャッシュの単位について:ページとbuffer_headとの関係
ページキャッシュは名前の通りページ単位のキャッシュです。ページサイズは通常は4KBや8KB単位のため、ページキャッシュもこれらの単位で管理されます。
一方、ブロックデバイスやファイルシステムのブロックサイズはページサイズと同じかそれより小さい大きさです。(ブロックサイズはデバイスやファイルシステムごとに異なる)
ページキャッシュをより小さい単位でアクセスするためにbuffer_head型を使います。
buffer_headは昔はページキャッシュとは独立して存在していたそうですが、Linux2.6でページキャッシュと統合されたようです。
現在でもページキャッシュとは独立した形で使用するケースがあるようですが、今回ではページキャッシュとの関係についてのみ触れます。
ページとbuffer_headとの関係を簡単に以下に図にしました。以下図ではページは4KB、ブロックデバイスのブロックサイズは1KBとしています。
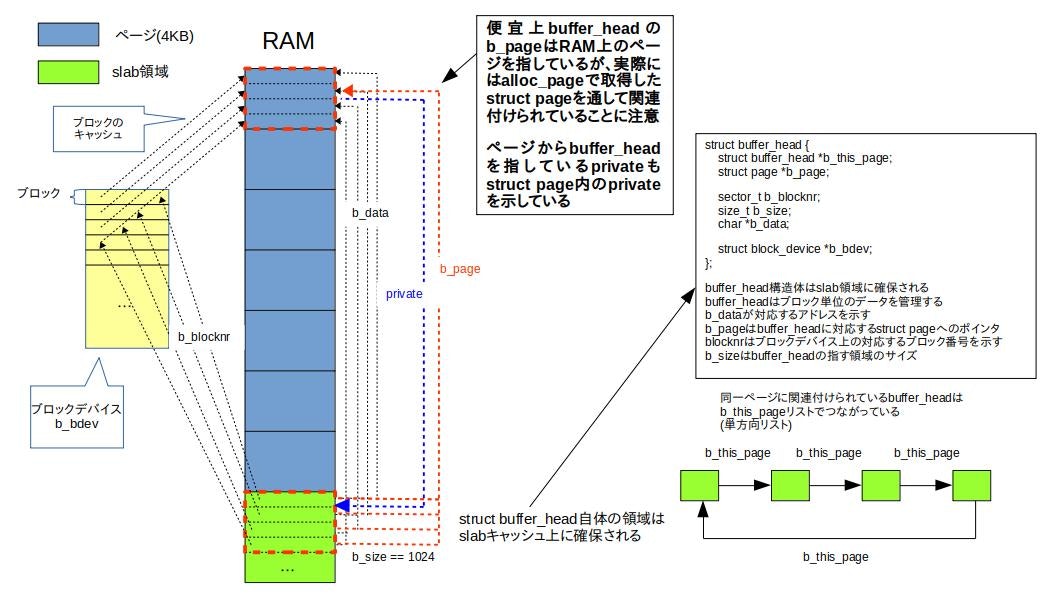
buffer_headはページキャッシュを物理的に分割するわけではありません。つまり、ページにbuffer_headを関連付けても関連先のページのデータ自体は変更されません。
関連づける前と同様にstruct pageでページ単位のアクセスが可能です。
struct buffer_headは以下のような構造体です。buffer_headは関連付けられたページとは別に存在するため、メモリ上に別途領域を確保する必要があります。
上図の黄緑の四角で示したとおり、buffer_headはslabアロケータで領域を確保します。
struct buffer_head {
unsigned long b_state; /* buffer state bitmap (see above) */
struct buffer_head *b_this_page;/* circular list of page's buffers */
struct page *b_page; /* the page this bh is mapped to */
sector_t b_blocknr; /* start block number */
size_t b_size; /* size of mapping */
char *b_data; /* pointer to data within the page */
struct block_device *b_bdev;
bh_end_io_t *b_end_io; /* I/O completion */
void *b_private; /* reserved for b_end_io */
struct list_head b_assoc_buffers; /* associated with another mapping */
struct address_space *b_assoc_map; /* mapping this buffer is
associated with */
atomic_t b_count; /* users using this buffer_head */
};
buffer_headはslabで確保されているため、bufer_headの使用量は/proc/slabinfoで見ることができます。
buffer_head1つにつき104バイト使っています。
$ sudo cat /proc/slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
...
buffer_head 113217 113217 104 39 1 : tunables 0 0 0 : slabdata 2903 2903 0
上図中でも説明していますが、以下にいくつかのメンバ変数について簡単に説明します。
b_this_pageは同一ページに関連付けられたbuffer_headの単方向のリストです。
b_pageは関連付けられたページへのポインタです。また、この場合、対応するページのprivateメンバに関連付けられたbuffer_headへのアドレスが格納されます。buffer_headをページと関連づけないで独立して使用する場合はb_pageにはNULLが格納されます。
b_dataにはbuffer_headに対応する領域のアドレスが格納されます。以下が使用例ですが、kmallocで取得したアドレスのようにアクセスできます。
static int minix_fill_super(struct super_block *s, void *data, int silent)
{
struct buffer_head *bh;
/* 省略 */
if (!(bh = sb_bread(s, 1)))
goto out_bad_sb;
ms = (struct minix_super_block *) bh->b_data;
sbi->s_ms = ms;
sbi->s_sbh = bh;
sbi->s_mount_state = ms->s_state;
ページキャッシュとaddress_spaceとの関係
address_spaceは、名前だけ見るとプロセスのアドレス空間の管理に関係しそうですが、実際にはinodeとページキャッシュとを結びつけるデータ型です。
以下にaddress_spaceの定義を抜粋します(一部メンバは削除しています)。
struct address_space {
struct inode *host; /* owner: inode, block_device */
struct radix_tree_root i_pages; /* cached pages */
unsigned long nrpages; /* number of total pages */
const struct address_space_operations *a_ops; /* methods */
} __attribute__((aligned(sizeof(long)))) __randomize_layout;
hostは対応するinodeへのポインタです。
i_pagesはページキャッシュの実体のradix treeへのポインタです(後述します)。
a_opsはaddress_spaceを操作するための関数群へのポインタで、各ファイルシステムが用意します。ファイルのreadやwrite時等のファイルシステムを意識する処理で使用されるようです。本記事ではa_opについては触れません。
以下にaddress_spaceとinodeとの関係を図示します。
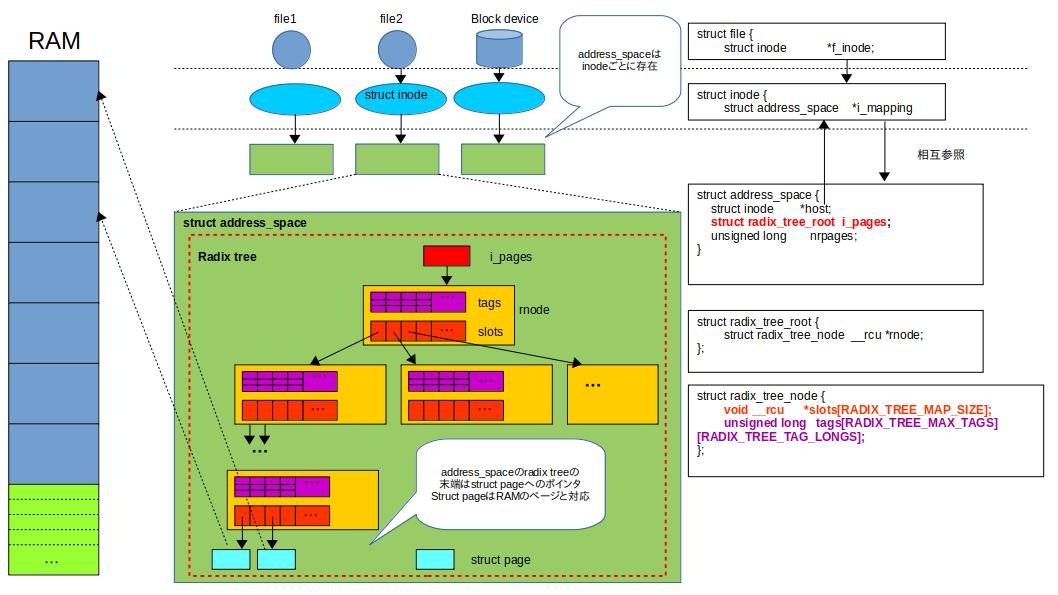
address_spaceは各inodeごとに存在しており、inodeのi_mappingがaddress_spaceへのポインタとなっています。
また、address_spaceのhostは対応するinodeへのポインタとなっており、inodeとaddress_spaceは相互に参照できるようになっています。
address_spaceのメンバの中で重要なのはi_pagesです。ページキャッシュはradix treeとして実装されており、i_pagesはradix treeのrootとなります。
radix treeはキーと値を結びつけるためのデータ構造です。ページキャッシュで使用しているradix treeは以下のような特徴を持ちます。
- キーとデータが一意に結びつく
- 各ノードはslotsという配列を持っている
- slotsの各要素はノードへのポインタかstruct pageへのポインタかNULLである
- tagsはslotsの指す先の状態を示す
ページキャッシュの探索時はファイルのオフセット(ファイルのアクセス時)やブロックデバイスのブロック番号(ブロックデバイスアクセス時)からキーを算出します。
radix treeのデータ型は以下のようになっています。
# define RADIX_TREE_MAX_TAGS 3
# ifndef RADIX_TREE_MAP_SHIFT
# define RADIX_TREE_MAP_SHIFT (CONFIG_BASE_SMALL ? 4 : 6)
# endif
# define RADIX_TREE_MAP_SIZE (1UL << RADIX_TREE_MAP_SHIFT)
# define RADIX_TREE_MAP_MASK (RADIX_TREE_MAP_SIZE-1)
# define RADIX_TREE_TAG_LONGS \
((RADIX_TREE_MAP_SIZE + BITS_PER_LONG - 1) / BITS_PER_LONG)
# define RADIX_TREE_INDEX_BITS (8 /* CHAR_BIT */ * sizeof(unsigned long))
# define RADIX_TREE_MAX_PATH (DIV_ROUND_UP(RADIX_TREE_INDEX_BITS, \
RADIX_TREE_MAP_SHIFT))
struct radix_tree_node {
unsigned char shift; /* Bits remaining in each slot */
unsigned char offset; /* Slot offset in parent */
unsigned char count; /* Total entry count */
unsigned char exceptional; /* Exceptional entry count */
struct radix_tree_node *parent; /* Used when ascending tree */
struct radix_tree_root *root; /* The tree we belong to */
union {
struct list_head private_list; /* For tree user */
struct rcu_head rcu_head; /* Used when freeing node */
};
void __rcu *slots[RADIX_TREE_MAP_SIZE];
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
};
struct radix_tree_root {
spinlock_t xa_lock;
gfp_t gfp_mask;
struct radix_tree_node __rcu *rnode;
};
radix_tree_node内のslotsのサイズはRADIX_TREE_MAP_SIZEで固定となっています。
この値は(1UL << RADIX_TREE_MAP_SHIFT)と定義されており、RADIX_TREE_MAP_SHIFTはカーネルのコンフィグオプションで指定しなければ6となります。
よってradix_tree_nodeのslotsは64個の要素を持ちます。
tagsの各ビットはslotsの各要素に対応します。
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
RADIX_TREE_MAX_TAGSはtagsの種類の数です。
RADIX_TREE_TAG_LONGS個のunsigned long == slots数分のビットを確保します。
slots配下に1つでも条件に該当する要素があれば、tagsの対応するビットがセットされます。
例えば、ページキャッシュをwrite backする際に、dirtyなページを見つけるためにページキャッシュの全ページを1つずつ確認するのは手間がかかります。
このような場合に、全ページを走査するのではなく、対応するtagsのビットがセットされているslotsのみを走査することで、処理を高速化するために使用するようです。
(dirtyチェックの用途以外については未確認です)
ページキャッシュのradix treeの実装詳細についてはここでは取り上げませんので、詳細については
https://lwn.net/Articles/175432/
等を参照ください。
具体例(sb_breadのコード)を追っていく
次にページキャッシュを使っている実際のコードを見ていきます。
以下の理由から、sb_breadのコードを参照します。
- ファイルのread/writeを追っていくとファイルシステム固有の処理に突き当たり、説明が複雑になる
- ブロックデバイスへのread/writeもファイルと同様にページキャッシュを経由する
- ファイルのread/writeもsb_breadもページキャッシュへのアクセス方法は大きくは変わらない
- 説明を簡単にするために、read処理に観点を絞る
sb_breadはスーパーブロックの読み出し使用される関数です。
ブロック単位のデータを読み出すので、リターンするデータ型はbuffer_headへのポインタとなります。
static inline struct buffer_head *
sb_bread(struct super_block *sb, sector_t block)
{
return __bread_gfp(sb->s_bdev, block, sb->s_blocksize, __GFP_MOVABLE);
}
sb_breadの実体は__bread_gfpです。
__bread_gfpは指定したブロック番号に対応するデータをブロックデバイスから読み出す関数です。
__bread_gfpの実装は以下のようになっており、__getblk_gfpと__bread_slowを呼び出しています。
struct buffer_head *
__bread_gfp(struct block_device *bdev, sector_t block,
unsigned size, gfp_t gfp)
{
struct buffer_head *bh = __getblk_gfp(bdev, block, size, gfp);
if (likely(bh) && !buffer_uptodate(bh))
bh = __bread_slow(bh);
return bh;
}
EXPORT_SYMBOL(__bread_gfp);
__getblk_gfpはページキャッシュの探索を行い、該当するブロックのキャッシュを返します。
__bread_slowはbuffer_headがブロックデバイスのデータと同期していない場合に実行され、ブロックデバイスから該当するデータを読み出します。
それぞれについて以下で説明していきます。
__getblk_gfpの実装
struct buffer_head *
__getblk_gfp(struct block_device *bdev, sector_t block,
unsigned size, gfp_t gfp)
{
/* キャッシュを探索する */
struct buffer_head *bh = __find_get_block(bdev, block, size);
might_sleep();
if (bh == NULL)
/* ブロックデバイスからブロックを読み出す */
bh = __getblk_slow(bdev, block, size, gfp);
return bh;
}
EXPORT_SYMBOL(__getblk_gfp);
__getblk_gfpは__find_get_blockと__getblk_slowを呼び出すだけの小さな関数です。
__find_get_blockの実装
__find_get_blockはページキャッシュの探索を行います。
struct buffer_head *
__find_get_block(struct block_device *bdev, sector_t block, unsigned size)
{
struct buffer_head *bh = lookup_bh_lru(bdev, block, size);
if (bh == NULL) {
/* __find_get_block_slow will mark the page accessed */
bh = __find_get_block_slow(bdev, block);
if (bh)
bh_lru_install(bh);
} else
touch_buffer(bh);
return bh;
}
上で説明したとおり、ページキャッシュはradix treeに格納されていますが、それとは別に最近アクセスされたbuffer_headを保存するLRUキャッシュも存在しています。
直近アクセスされたデータは近いうちに再度アクセスされる可能性が高いので、LRUキャッシュを別途用意しておくことで、毎回radix treeを探索する手間が省けます。
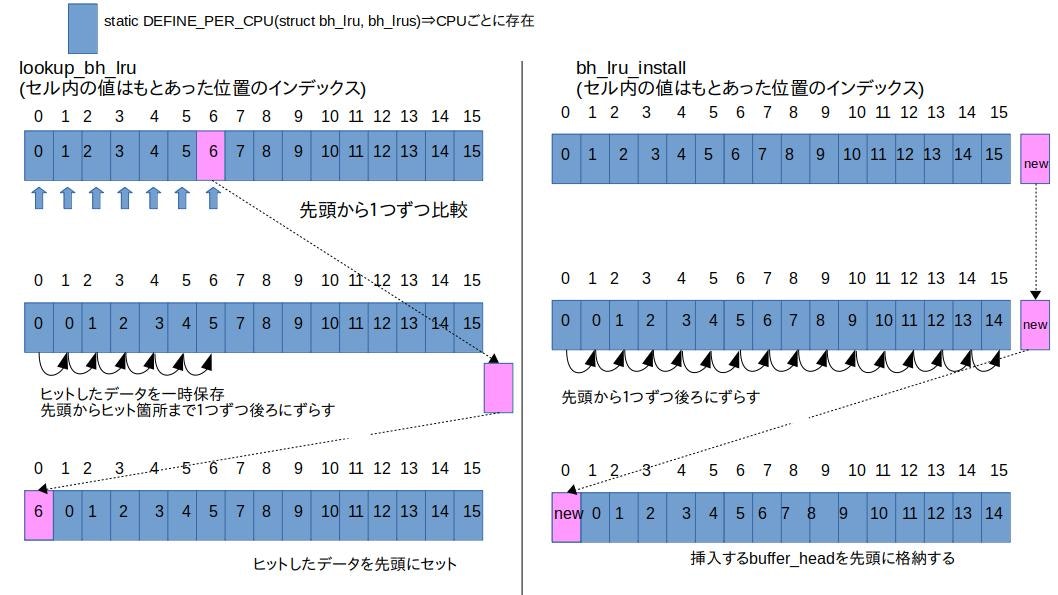
そのため、__find_get_blockはまず最初にlookup_bh_lruを実行してLRUキャッシュを探索します。直近にアクセスされたbuffer_headはLRUキャッシュの先頭にセットされます。
LRUキャッシュの実体は単純な配列となっており、探索(lookup_bh_lru)、セット(bh_lru_install)の操作もシンプルです。
以下は該当箇所のコードと概略図です。
static struct buffer_head *
lookup_bh_lru(struct block_device *bdev, sector_t block, unsigned size)
{
struct buffer_head *ret = NULL;
unsigned int i;
check_irqs_on();
bh_lru_lock();
for (i = 0; i < BH_LRU_SIZE; i++) {
struct buffer_head *bh = __this_cpu_read(bh_lrus.bhs[i]);
if (bh && bh->b_blocknr == block && bh->b_bdev == bdev &&
bh->b_size == size) {
if (i) {
while (i) {
__this_cpu_write(bh_lrus.bhs[i],
__this_cpu_read(bh_lrus.bhs[i - 1]));
i--;
}
__this_cpu_write(bh_lrus.bhs[0], bh);
}
get_bh(bh);
ret = bh;
break;
}
}
bh_lru_unlock();
return ret;
}
static void bh_lru_install(struct buffer_head *bh)
{
struct buffer_head *evictee = bh;
struct bh_lru *b;
int i;
check_irqs_on();
bh_lru_lock();
b = this_cpu_ptr(&bh_lrus);
for (i = 0; i < BH_LRU_SIZE; i++) {
swap(evictee, b->bhs[i]);
if (evictee == bh) {
bh_lru_unlock();
return;
}
}
get_bh(bh);
bh_lru_unlock();
brelse(evictee);
}
次に__find_get_block_slowです。ブロックに該当するbuffer_headへのポインタを返します。
static struct buffer_head *
__find_get_block_slow(struct block_device *bdev, sector_t block)
{
/*ブロックデバイスのinode, adress_spaceを取得 */
struct inode *bd_inode = bdev->bd_inode;
struct address_space *bd_mapping = bd_inode->i_mapping;
struct buffer_head *ret = NULL;
pgoff_t index;
struct buffer_head *bh;
struct buffer_head *head;
struct page *page;
int all_mapped = 1;
/*
指定されたblock番号から該当ページ番号を算出する
#define PAGE_SHIFT 12 //pageサイズ==4096バイト
bd_inode->i_blkbits == 10 //ブロックサイズ==1024バイト
*/
index = block >> (PAGE_SHIFT - bd_inode->i_blkbits);
/* radix treeを探索 */
page = find_get_page_flags(bd_mapping, index, FGP_ACCESSED);
/* ページがキャッシュされていない */
if (!page)
goto out;
spin_lock(&bd_mapping->private_lock);
/* ページにbuffer_headが割り当てられていないのでNULLをリターンする
呼び出し元でbuffer_headを別途確保する必要がある */
if (!page_has_buffers(page))
goto out_unlock;
head = page_buffers(page);
bh = head;
do {
/* buffer_headがブロックデバイスと結びついていないので、
別途ブロックのreadが必要 */
if (!buffer_mapped(bh))
all_mapped = 0;
/* ブロックに該当するbuffer_headが見つかった */
else if (bh->b_blocknr == block) {
ret = bh;
get_bh(bh);
goto out_unlock;
}
/* 同一ページに属するbuffer_headを辿る */
bh = bh->b_this_page;
} while (bh != head);
/* buffer_headはブロックデバイスにマッピングされているが、
指定のブロック番号にマッピングされていない */
/* we might be here because some of the buffers on this page are
* not mapped. This is due to various races between
* file io on the block device and getblk. It gets dealt with
* elsewhere, don't buffer_error if we had some unmapped buffers
*/
if (all_mapped) {
printk("__find_get_block_slow() failed. "
"block=%llu, b_blocknr=%llu\n",
(unsigned long long)block,
(unsigned long long)bh->b_blocknr);
printk("b_state=0x%08lx, b_size=%zu\n",
bh->b_state, bh->b_size);
printk("device %pg blocksize: %d\n", bdev,
1 << bd_inode->i_blkbits);
}
out_unlock:
spin_unlock(&bd_mapping->private_lock);
put_page(page);
out:
return ret;
}
最初に__find_get_block_slowはブロックデバイスのinodeからaddress_spaceを取得しています。
次にblock番号からradix treeのキーとなるindexを算出しています。ページキャッシュはの単位はあくまでページなので、ページサイズ単位のオフセットをindexとしています。
find_get_page_flagsはindexをキーとしてradix treeからページを探索します。
該当するページが見つからなかった場合や、ページにbuffer_headが関連付けられていない場合、__find_get_block_slowはNULLを返します。この場合、呼び出し元でページ、buffer_headの確保、関連付けを行います。この処理については別途見ていきます。
find_get_page_flagsの探索がヒットすると、ページがリターンます。
このページに関連付けられたbuffer_headがブロック番号(block)と一致する場合、そのbuffer_headが該当ブロックのキャッシュとしてリターンします。
ここでリターンしたbuffer_headへのポインタがsb_breadのリターン値となります。
(補足:buffer_XXXやset_buffer_XXXはマクロを使って以下のように定義されており、ctagで検索しても見つかりませんでした。)
# define BUFFER_FNS(bit, name) \
static __always_inline void set_buffer_##name(struct buffer_head *bh) \
{ \
if (!test_bit(BH_##bit, &(bh)->b_state)) \
set_bit(BH_##bit, &(bh)->b_state); \
} \
static __always_inline void clear_buffer_##name(struct buffer_head *bh) \
{ \
clear_bit(BH_##bit, &(bh)->b_state); \
} \
static __always_inline int buffer_##name(const struct buffer_head *bh) \
{ \
return test_bit(BH_##bit, &(bh)->b_state); \
}
...
BUFFER_FNS(Mapped, mapped)
__getblk_slowの実装
__find_get_blockの実行結果がNULL(ページキャッシュに該当のページ/buffer_headが存在しない場合)、__getblk_gfpは__getblk_slowを実行します。
static struct buffer_head *
__getblk_slow(struct block_device *bdev, sector_t block,
unsigned size, gfp_t gfp)
{
/* 省略 */
for (;;) {
struct buffer_head *bh;
int ret;
bh = __find_get_block(bdev, block, size);
if (bh)
return bh;
ret = grow_buffers(bdev, block, size, gfp);
if (ret < 0)
return NULL;
}
}
__getblk_slowは指定のブロックに対応するbuffer_headを取得するかエラーが発生するまで、ページキャッシュの探索(__find_get_block)とブロックデバイスの読み出し(grow_buffers)を繰り返します。
ページキャッシュの探索は呼び出し元の__getblk_gfpと同様に__find_get_blockを実行していますが、既に呼び出し元で失敗している関数を再度実行するのは一見するとあまり意味が無さそうに見えます。
ここで、grow_buffersの戻り値はint型であり、buffer_headのポインタではありません。
そのため、grow_buffersから直接buffer_headへのポインタを取得するわけではないので、__find_get_blockを再度実行する必要があります。
簡単な流れとしては、
- grow_buffers内でbuffer_headを確保しページへ関連付け、ページキャッシュへ保存
- __find_get_blockで該当のbuffer_headを取得
となっています。
grow_buffersについて説明します。
static int
grow_buffers(struct block_device *bdev, sector_t block, int size, gfp_t gfp)
{
pgoff_t index;
int sizebits;
sizebits = -1;
do {
sizebits++;
} while ((size << sizebits) < PAGE_SIZE);
index = block >> sizebits;
/* blockが範囲外かチェック */
/*
* Check for a block which wants to lie outside our maximum possible
* pagecache index. (this comparison is done using sector_t types).
*/
if (unlikely(index != block >> sizebits)) {
printk(KERN_ERR "%s: requested out-of-range block %llu for "
"device %pg\n",
__func__, (unsigned long long)block,
bdev);
return -EIO;
}
/* Create a page with the proper size buffers.. */
return grow_dev_page(bdev, block, index, size, sizebits, gfp);
}
grow_buffersはblock番号からページキャッシュのindexを作成し、indexが妥当な値の場合にgrow_dev_pageを実行します。
indexは以下のように算出していますが、
index = block >> sizebits;
indexのチェック時に代入元の値と同じblock >> sizebitsと比較しており、一見無駄な判定のように見えます。
if (unlikely(index != block >> sizebits)) {
indexはpgoff_t型、blockはsector_t型ですが、これらの型はそれぞれ以下のように定義されています。
32ビットcpuでCONFIG_LBDAFが有効の場合、index != block >> sizebitsとなりうるため(blockが大きい場合)、念の為にチェックしていると思われます。
# ifdef CONFIG_LBDAF
typedef u64 sector_t;
typedef u64 blkcnt_t;
# else
typedef unsigned long sector_t;
typedef unsigned long blkcnt_t;
# endif
...
# define pgoff_t unsigned long
grow_dev_pageはページの取得、ページとbuffer_headとの関連付けを行います。
static int
grow_dev_page(struct block_device *bdev, sector_t block,
pgoff_t index, int size, int sizebits, gfp_t gfp)
{
struct inode *inode = bdev->bd_inode;
struct page *page;
struct buffer_head *bh;
sector_t end_block;
int ret = 0; /* Will call free_more_memory() */
gfp_t gfp_mask;
gfp_mask = mapping_gfp_constraint(inode->i_mapping, ~__GFP_FS) | gfp;
/*
* XXX: __getblk_slow() can not really deal with failure and
* will endlessly loop on improvised global reclaim. Prefer
* looping in the allocator rather than here, at least that
* code knows what it's doing.
*/
gfp_mask |= __GFP_NOFAIL;
/* ページキャッシュを探索する
該当するページが見つからなければ__page_cache_allocでページを確保する
確保したページはページキャッシュにセットする
*/
page = find_or_create_page(inode->i_mapping, index, gfp_mask);
BUG_ON(!PageLocked(page));
/* ページにbuffer_headが関連付けられている場合 */
if (page_has_buffers(page)) {
bh = page_buffers(page);
if (bh->b_size == size) {
end_block = init_page_buffers(page, bdev,
(sector_t)index << sizebits,
size);
goto done;
}
if (!try_to_free_buffers(page))
goto failed;
}
/*
* Allocate some buffers for this page
*/
bh = alloc_page_buffers(page, size, true);
/*
* Link the page to the buffers and initialise them. Take the
* lock to be atomic wrt __find_get_block(), which does not
* run under the page lock.
*/
spin_lock(&inode->i_mapping->private_lock);
link_dev_buffers(page, bh);
end_block = init_page_buffers(page, bdev, (sector_t)index << sizebits,
size);
spin_unlock(&inode->i_mapping->private_lock);
done:
ret = (block < end_block) ? 1 : -ENXIO;
failed:
unlock_page(page);
put_page(page);
return ret;
}
まずfind_or_create_pageですが、この関数はpagecache_get_pageのラッパ関数です。
以下のようにページキャッシュを探索し、ヒットしなければページの確保を行います。
struct page *pagecache_get_page(struct address_space *mapping, pgoff_t offset,
int fgp_flags, gfp_t gfp_mask)
{
struct page *page;
repeat:
/* ページキャッシュ(radix tree)の探索 */
page = find_get_entry(mapping, offset);
/* 省略 */
no_page:
if (!page && (fgp_flags & FGP_CREAT)) {
/* 省略 */
/* ページキャッシュにヒットしなかったのでページ割り当てる */
page = __page_cache_alloc(gfp_mask);
if (!page)
return NULL;
/* 省略 */
/* 確保したページをページキャッシュへ挿入 */
err = add_to_page_cache_lru(page, mapping, offset, gfp_mask);
if (unlikely(err)) {
put_page(page);
page = NULL;
if (err == -EEXIST)
goto repeat;
}
}
return page;
}
__page_cache_allocで確保したページはadd_to_page_cache_lruでページキャッシュへ挿入します。
具体的には、add_to_page_cache_lruを先に以下の__add_to_page_cache_lockedがありますが、この中でpage_cache_tree_insertでradix treeへの挿入を行っています。
static int __add_to_page_cache_locked(struct page *page,
struct address_space *mapping,
pgoff_t offset, gfp_t gfp_mask,
void **shadowp)
{
/* 省略 */
get_page(page);
page->mapping = mapping;
page->index = offset;
xa_lock_irq(&mapping->i_pages);
/* ページキャッシュ(radix tree)へページを挿入
error = page_cache_tree_insert(mapping, page, shadowp);
/* 省略 */
}
この時点でページキャッシュにページが存在する状態となっています。
grow_dev_pageに戻ります。
find_or_create_pageで新たにページを確保した場合、find_or_create_pageから抜けた時点ではページとbuffer_headとは関連付けられていません。そのため、以下のブロックは実行されません。
if (page_has_buffers(page)) {
bh = page_buffers(page);
if (bh->b_size == size) {
end_block = init_page_buffers(page, bdev,
(sector_t)index << sizebits,
size);
goto done;
}
if (!try_to_free_buffers(page))
goto failed;
}
ページに関連付けられているbuffer_headが今回指定されたサイズと異なる場合、try_to_free_bufferでbuffer_headをfreeします。その後にalloc_page_buffersで再度buffer_headの確保を行います。
struct buffer_head *alloc_page_buffers(struct page *page, unsigned long size,
bool retry)
{
struct buffer_head *bh, *head;
/* 省略 */
head = NULL;
offset = PAGE_SIZE;
while ((offset -= size) >= 0) {
/* struct buffer_headの領域を確保 */
bh = alloc_buffer_head(gfp);
if (!bh)
goto no_grow;
/* b_this_pageは同一ページに属するbuffer_headのリスト */
bh->b_this_page = head;
bh->b_blocknr = -1;
head = bh;
bh->b_size = size;
/* bh->b_dataにアドレスを設定 */
/* Link the buffer to its page */
set_bh_page(bh, page, offset);
}
/* 省略 */
}
ページとbufer_headとの関係で説明したとおり、buffer_headのb_this_pageメンバは同一ページに関連付けられているbuffer_headのリストです。b_this_pageに確保したbuffer_headをつなげていきます。
また、set_bh_pageはbuffer_headのb_pageにページへのポインタ、b_dataに対応する領域のアドレスをそれぞれセットします。
void set_bh_page(struct buffer_head *bh,
struct page *page, unsigned long offset)
{
bh->b_page = page;
/* 省略 */
bh->b_data = page_address(page) + offset;
}
この時点ではまだページからbuffer_headへの関連付けがされていません。
link_dev_buffersではページからbuffer_headへの関連付けを行います。また、buffer_headのb_this_pageの末尾と先頭とを連結し、循環リストにしています。
static inline void
link_dev_buffers(struct page *page, struct buffer_head *head)
{
struct buffer_head *bh, *tail;
bh = head;
do {
tail = bh;
bh = bh->b_this_page;
} while (bh);
tail->b_this_page = head;
attach_page_buffers(page, head);
}
grow_dev_pageの最後にinit_page_buffersを実行し、ブロックデバイスの設定等、buffer_headのその他の初期化を行います。
static sector_t
init_page_buffers(struct page *page, struct block_device *bdev,
sector_t block, int size)
{
struct buffer_head *head = page_buffers(page);
struct buffer_head *bh = head;
int uptodate = PageUptodate(page);
sector_t end_block = blkdev_max_block(I_BDEV(bdev->bd_inode), size);
do {
if (!buffer_mapped(bh)) {
bh->b_end_io = NULL;
bh->b_private = NULL;
bh->b_bdev = bdev;
bh->b_blocknr = block;
if (uptodate)
set_buffer_uptodate(bh);
if (block < end_block)
set_buffer_mapped(bh);
}
block++;
bh = bh->b_this_page;
} while (bh != head);
/*
* Caller needs to validate requested block against end of device.
*/
return end_block;
}
ここまでの処理によって、__getblk_slowからbuffer_headへのポインタが取得できるようになりました。
__bread_slowの実装
__bread_gfpは__getblk_gfpで取得したbuffer_headがブロックデバイスと同期されていない(!buffer_uptodate(bh))場合に__bread_slowを実行します。
__bread_slowは以下の通り、ブロックデバイスからデータを読み出します。
submit_bhでread要求をキューに格納し、wait_on_bufferでread完了を待ちます。ブロックデバイスのreadの詳細については割愛します。
static struct buffer_head *__bread_slow(struct buffer_head *bh)
{
lock_buffer(bh);
if (buffer_uptodate(bh)) {
unlock_buffer(bh);
return bh;
} else {
/* ブロックデバイスからデータを読み出す */
get_bh(bh);
bh->b_end_io = end_buffer_read_sync;
submit_bh(REQ_OP_READ, 0, bh);
wait_on_buffer(bh);
if (buffer_uptodate(bh))
return bh;
}
brelse(bh);
return NULL;
}
おわりに
本記事ではページキャッシュとそれに関連するデータ型について調べてみました。
誤っている点など多々あると思いますので、ご指摘いただけたら幸いです。