Aidemy 2020/10/30
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は自然言語処理の3つ目の投稿になります。どうぞよろしくお願いします。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・
・
単語の連続性の前準備
単語辞書の作成
・「単語の連続性の分析」を行うために、その前準備として、単語データを数値化する。
・データセットを分かち書きした後、単語ごとにIDを付与して数値化するために、まずはIDを設定した__単語辞書(リスト)__を作成する。このうち、単語の出現数の多い順に連番を付けたいので、単語の出現数をカウントして降順に並べ替える。
・単語の出現数のカウントは__Counter()__と__itertools.chain()__を使って行う。
Counter(itertools.chain(*カウントする単語データのリスト))
・Counter()は要素の個数を数えるが、結果が多次元で返ってくるので、各要素に個別にアクセスできない。これを、__itertools.chain()を使うことで一次元に戻す、ということを行っている。このitertools.chain()に渡す多次元リストには「*」__をつける。
・降順に並べ替えるのは、__most_common(n)__を使う。nを指定すると、大きい順からその個数分のタプルを返す。
・ここまで行ったら、並べ替えた出現数リストの一つ一つにIDを付与して空の辞書に格納することで単語辞書が作れる。
・コード
単語データを数値データに変換する
・辞書を作成したら、目的であった__「データセットを数値化する」__ということを行う。
・前項で作った単語辞書のID部分を参照して、発話データセット「wakatiO」を数値データのみの「wakatiO_n」という新しい配列に変換する。
・そのコードが以下のようになる。
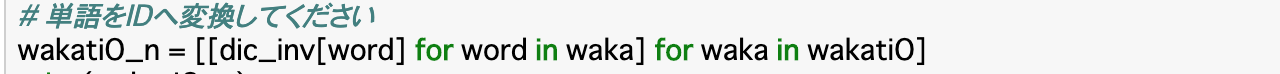
・このコードは後ろから見ていくとわかりやすい。まず__「for waka in wakatiO」の部分は、データセット「wakatiO」の各単語リスト(一文ずつで分かれている)をwakaに格納したことを示す。次に「for word in waka」はその単語リストを各単語に分け、wordに格納したことを表す。
・そして、その各単語について「dic_inv[word]」__で辞書のIDを参照して「wakatiO_n」に格納していることを表している。
単語の連続性から特徴抽出
N-gram
・__N-gram__は、テキストからトピックを抽出するときに使われるモデルのことであり、テキストを連続したN個の文字に分割する__という方法を使う。
・N個の分割について、「あいうえお」という文字列があるとすると、N=1の「1-gram」なら「あ|い|う|え|お」と分割され、「2-gram」なら「あい|いう|うえ|えお」と分割される。
・「自然言語処理2」で出てきた「単語文書行列」でもトピックを抽出するということを行ったが、あちらが「単語の共起性(同じ文中に出現するか)」を表すのに対し、N-gramは「単語の連続性(どの順番で出現するか)」__を表す。
・N-gramの作成にはメソッドがあるわけではないので、文字列のリストに対して、繰り返し処理で空のリストに分割したものを格納するという手法をとる。
list = []
word = ['いい','天気','です','ね','。']
# 3-gramモデルの作成
for i range(len(word)-2):
list.append([word[i],word[i+1],word[i+2]])
print(list)
# [['いい','天気','です']['天気','です','ね']['です','ね','。']]
・__「len(word)-2」__の部分は、その下の「i+2」がwordの長さを超えないように同じ数字を指定する。
2-gramリストの作成
・上記N-gramについて、「wakatiO_n」から、2-gramリストを作成することで、二つのノードの出現回数(重み)を計算する。
・作成方法は、まず「wakatiO_n」に2-gramモデルを適用して2-gram配列「bigramO」を作成する。それを__DataFrameに変換__(df_bigramO)して「'node1'と'node2'」(連続値を算出する二つのノード)でグループ化(groupby())し、最後に「sum()」で出現数を合計して完成。
・コード

※groupby()の__「as_index=False」__は、__キーをindexでなくcolumnに出力する__ということを指定している。つまり、何も指定しないと、キーであるnode1はindexとして出力されてしまうため、columnであるnode2と同じように出力されない。これを回避するために、このように指定している。
・出力結果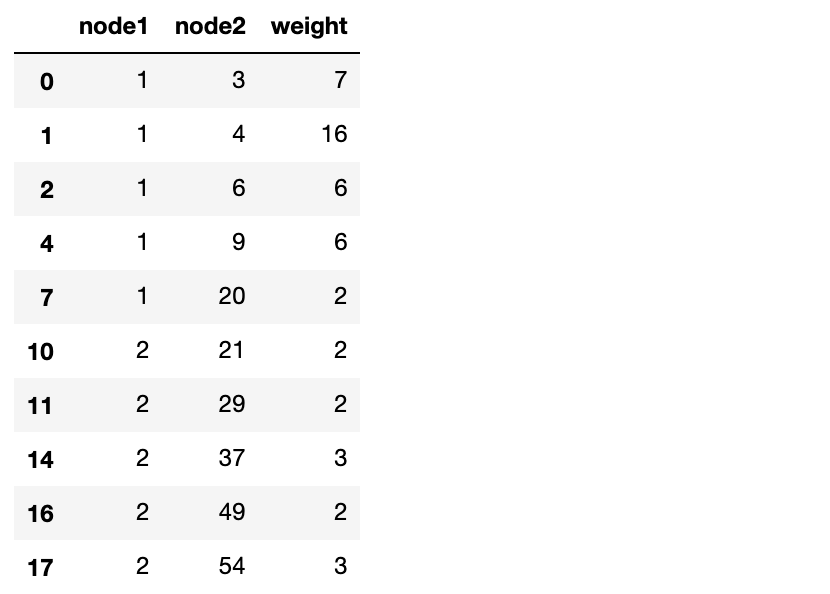
2-gramネットワークの作成
・Chapter2では単語の類似度をエッジ(重み)として無向グラフを作成した。今回は、単語ペアの出現回数をエッジ(重み)として有向グラフを作成する。作成元のデータは、前項で作ったdf_bigramOである。
・有向グラフとは、__エッジに「向き」の概念があるもの__を指す。単語ペアの出現回数については、「出現順」つまり「どちらの単語が先か」という情報にも意味があるのが有向グラフである。
・作成方法は無向グラフの時と全く同じで、__nx.from_pandas_edgelist()の引数に「nx.DiGraph」__と指定するだけで良い。
・コード

・結果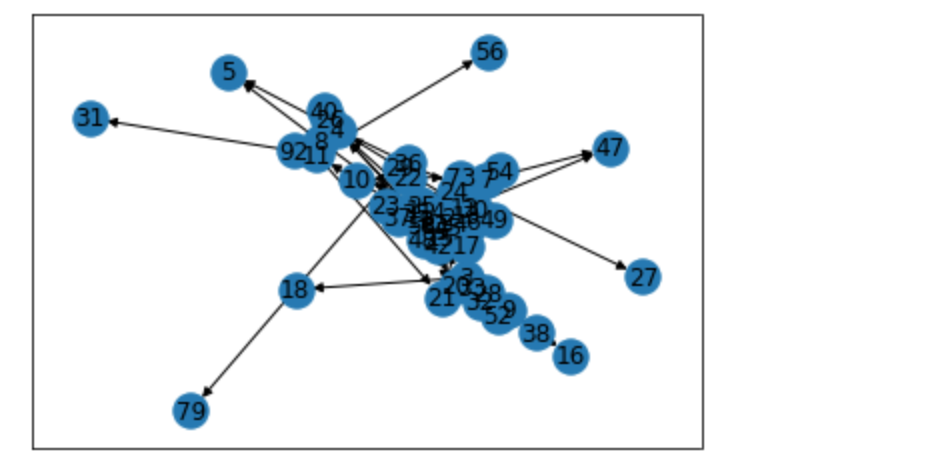
2-gramネットワークの特徴
・前のChapterと同様に、グラフだけを見ても特徴がわかりにくいので、__「平均クラスタ係数」や「媒介中心性」を計算して定量的に特徴を把握する。
・(復習)平均クラスタ係数は__nx.average_clustering()、媒介中心性は__nx.betweenness_centrality()__で求める。
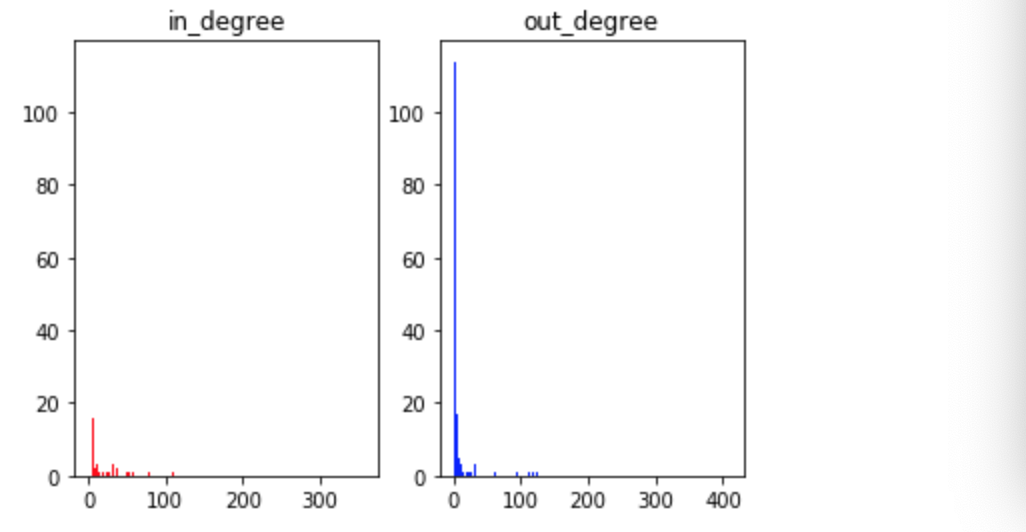
各単語の影響を見る
・各単語がどう影響しあっているかを見るには、__「次数分布」__というものを可視化することで行う。
・有向グラフのときは「他の単語から影響を受ける」__入次数__と「他の単語に影響を与える」__出次数__に分けられる。
・入次数は__in_degree(weight)__メソッドを使って調べる。(node番号,入次数)の形で返ってくる。
・同様に、出次数は__out_degree(weight)__メソッドを使って調べる。
・コード

・結果
まとめ
・単語の連続性__から特徴を把握するには、まず__発話テキストを分かち書き__し、そこから__単語辞書を作成する__ことで、データを数値に変換する。
・数値に変換したデータを__N-gramリストに変換__して各単語の組み合わせの__出現回数を計算__し、そこから__有向グラフを作成する。
・有向グラフのままだと特徴がわかりにくいので、__「平均クラスタ係数」や「媒介中心性」__を計算して定量的に特徴を把握する。
・また、__次数分布__をすることで定量的な特徴を__可視化__できる。
今回は以上です。最後まで読んでいただき、ありがとうございました。