今まで pandas + matplotlib を利用したプロッティングとしては pandas + matplotlib による多彩なデータプロッティング や matplotlib (+ pandas) によるデータ可視化の方法 といったものを紹介してきました。
抽出および加工したデータを俯瞰するにあたり、可視化までの流れをあらためて整理して追ってみましょう。
データセットを pandas オブジェクトにする
まず pandas の世界にデータセットを持ってくることになりますが、これは主に 2 通りの流れがあります。
- csv ファイルなど外部ファイルから pd.read_csv や pd.read_table といった関数を使って読み込む方法
- 連想配列 (辞書) オブジェクトなどを DataFrame に変換する方法
このうち 1. についてはすでにそのまま使える構造化されたデータが外部のファイルにあるようなときに使います。たとえば iris.csv というファイルがあった場合に次のようにして pandas オブジェクトにします。
df = pd.read_csv("iris.csv")
また 2. については、ある程度 Python のコードで抽出や加工をしたときに生成したデータを pandas で扱いたいときに使います。 pandas には充実したドキュメントがあるのでこれを参照すると良いでしょう。 from_dict 関数は辞書オブジェクトをそのままデータフレームに変換します。またインデックスを明示的に指定したい場合は from_records 関数を利用すると便利です。
df = pd.DataFrame.from_records(my_dic, index=my_array)
転置行列を得る
データセットにおいて、しばしば X と Y の軸は観察者にとって逆の視点であることがあります。このようなときも pandas のデータフレームならば常に .T メソッドで簡単に転置行列を得ることができます。これは非常によく使うので憶えておくと良いでしょう。
dft = df.T
pandas の教科書では df = df.T としていることが多いようですが筆者は上のように非破壊的な変換を好みます。
IPython で対話的にプロッティングする
matplotlib を使うコードを書くにしても試行錯誤が必要です。このとき IPython 上で素早くデータフレームの図示を描画・確認するステップを繰り返すと効率的です。
ipython -i オプションは引数に Python スクリプトを指定することができ、このスクリプトを実行した状態でインタラクティブシェルを操作することができるようになります。これは大変便利です。
たとえば次のようにクラスがあったとします。
class MyClass:
def __init__(self, args):
self.my_var = args[1]
self.my_array = []
self.my_dic = {}
def my_method(self):
...
ipython -i my_class.py としてシェルを起動すれば MyClass が読み込まれますから次のようにオブジェクトを取り出せます。
my_instance = MyClass()
arr = my_instance.my_array
dic = my_instance.my_dic
my_method で self.my_dic といったインスタンス変数にデータを格納していたなら、上のようにしてこのインスタンス変数からデータを取り出せますし、ここからプロッティングすれば対話的に可視化することができます。
データフレームの代表的な可視化方法
そもそもデータフレームに変換できた時点でいつもの 2 次元のデータなのですから、ここまで説明すればやるべきことはある程度見えてきたと言っても良いでしょう。
まずよく試す可視化方法をいくつか紹介します。
データセットとしては有名な Iris を利用します。
図形の詳細についてはすでに何度も紹介していますから、過去の記事を参照してください。
散布図行列
まずは定番の散布図行列です。
plt.figure() # キャンバスを用意
from pandas.tools.plotting import scatter_matrix
scatter_matrix(df) # 散布図行列を描く
plt.show() # 対話的に画像を表示する場合
plt.savefig("1.png") # 画像ファイルに出力する場合
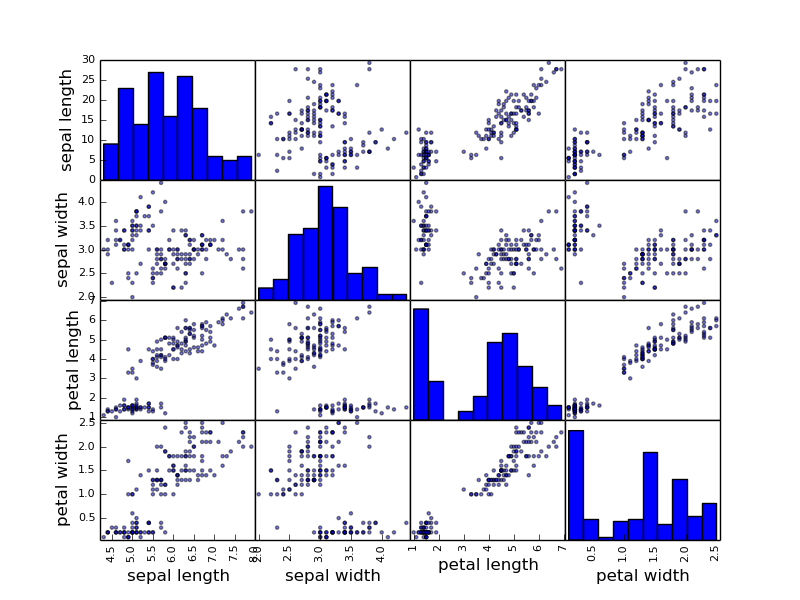
これは各列と各行の相関を一気に俯瞰することができるスグレモノです。散布図行列を見ることで精神の安定をはかれるようになればだいぶ慣れたものですね。
単純なプロット
以降、キャンバスを用意するステップと画像を出力するステップは省きます。
df.plot(legend=True)
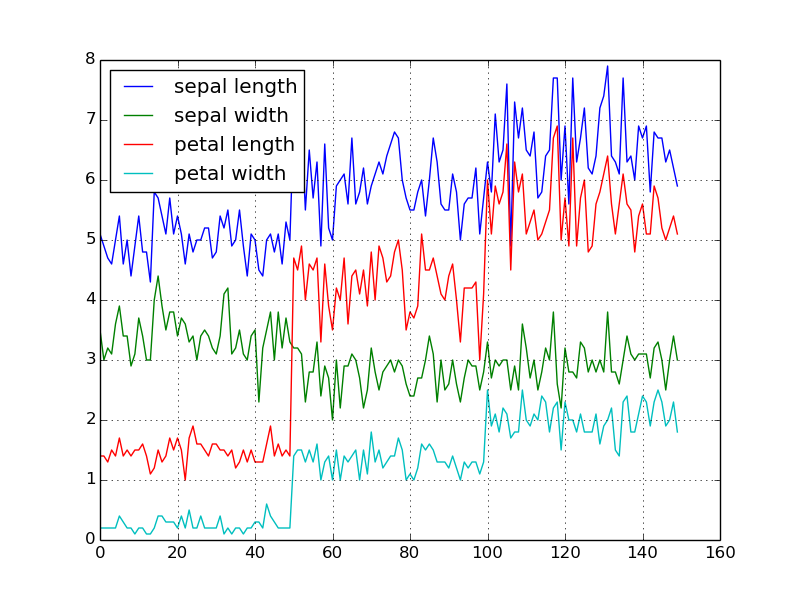
すでに何度も紹介した通り pandas では legend が既定で True になります。説明のせいで図がよく見えないという場合は legend=False にすれば良いです。
積み上げ棒グラフ
ためしにデータフレームの先頭 10 件をプロッティングするとこうなります。
df10 = df.head(10)
df10.plot(kind='barh', stacked=True, alpha=0.5, legend=True)
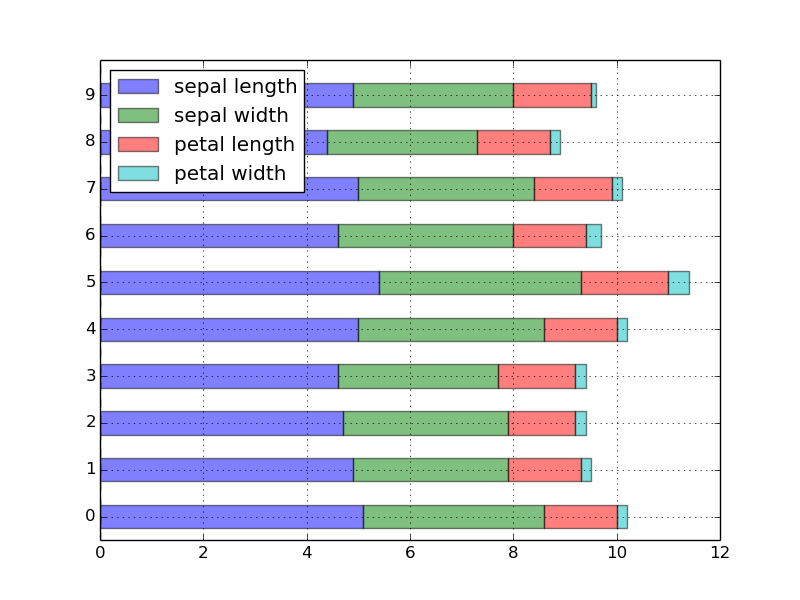
棒グラフ
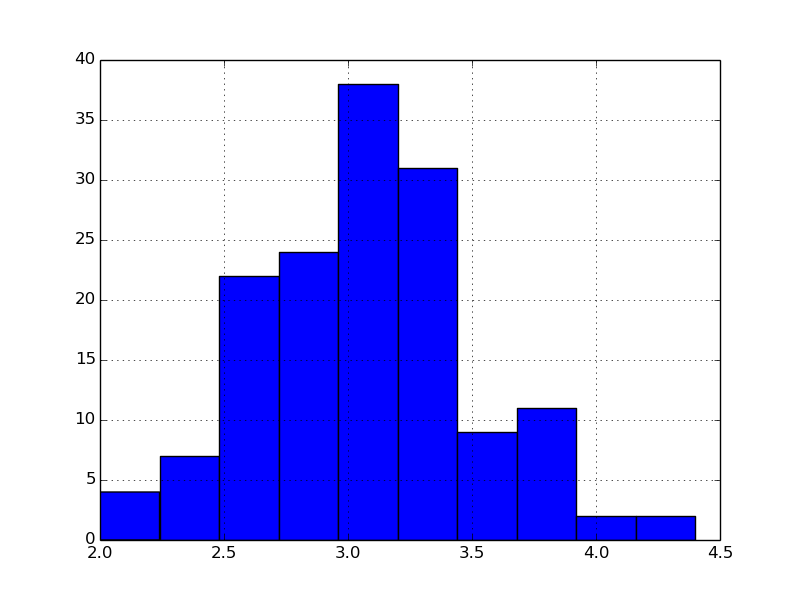
1 次元のベクトル空間に絞りこんで可視化するなら棒グラフが便利です。
df['sepal width'].hist()
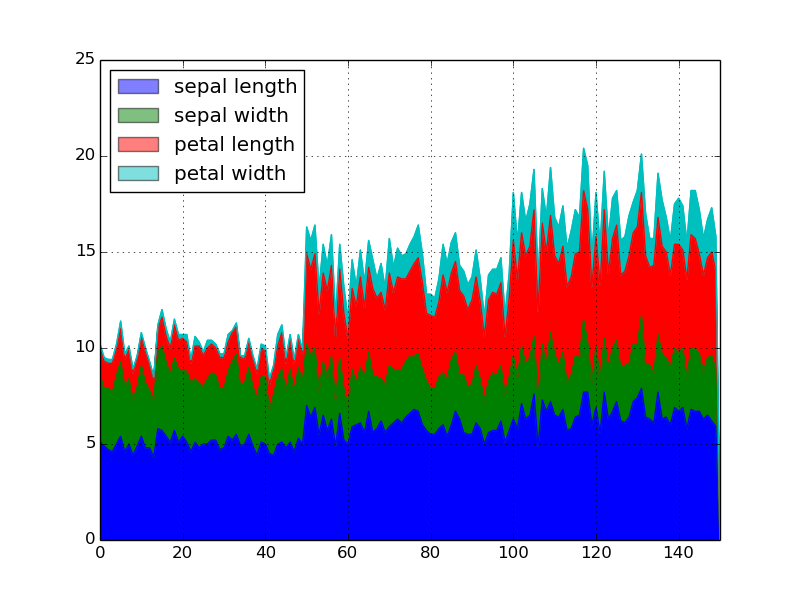
エリアチャート
時間ごとの経過における複数データの変化を追うときに便利です。
df.plot(kind='area', legend=True)
まとめ
いかがでしょう。次第に慣れてくると、データに向き合った際に無意識のうちにインタラクティブシェルを利用してプロッティングするようになるかと思います。試行錯誤がすばやく行える IPython と、シームレスに Python で使える pandas + matplotlib がいかに生産的なツールであるかその威力がよく理解できるかと思います。