前回、前々回に引き続き Hadoop による全数走査の話です。
Hadoop Streaming ジョブの連結をする
MapReduce プログラミングは前述したように単独で複雑な計算をするのに向いているわけではありません。たとえば TF-IDF 値の算出のような少し難しい数式を解きたい場合、ジョブを 2 つも 3 つも連結させる必要がある場合があります。
これは前回紹介したフレームワークの内部でもそうしている通り、出力ディレクトリに _SUCCESS ファイルが存在しているかどうかで判断をするのがひとつの方法です。
hadoop fs -get $HDFS_OUT/_SUCCESS>>$JOBLOG 2>&1
test -f _SUCCESS && 成功時処理
ジョブの直列実行としては単純にシェルスクリプトで連続的に実行すれば良いでしょう。
$JOB1/bin/run>>$JOB1/log/job.log 2>&1
$JOB2/bin/run>>$JOB2/log/job.log 2>&1
$JOB3/bin/run>>$JOB3/log/job.log 2>&1
このとき JOB1 の出力となる HDFS ディレクトリを JOB2 の入力ディレクトリとするようにすればデータを渡すことができます。
Hadoop Streaming で外部ファイルを読み込む
外部のファイルを読み込みたい場合は実行時の -file オプションにファイルを指定することで可能です。
-file EXTERNAL_JOB/log/result.log
フレームワークを利用している場合は script/run を編集すれば OK です。
-file オプションで指定したファイルは次のようにコード内で普通に読み込むことができます。
# -file に指定したファイル名を直接記述する
@external_file = "result.log"
def read_from_external
# open でそのまま開くことができる
open(@external_file) do |file|
file.each do |line|
# 全行をインスタンス変数に格納し、あとで使う
@external_data << line
end
end
end
-file に指定したファイルはそのまま実行ノード上のカレントディレクトリに展開されます。巨大なデータではないが何らかの処理のために参照したいデータがある場合にこの手は使えるでしょう。
Hadoop Streaming でのコード例
平均単語長を算出するコードを例として、処理記述の方法を解説します。
Mapper
Mapper ではとにかく全行を読み込んで単語の長さをひたすら出力します。行が単語とその長さに写像が取られるわけです。
class Mapper
def self.map(stdin)
# 全行を逐次読み込む
stdin.each_line {|line|
words = line.split(" ")
words.each {|word|
len = word.length
# アルファベットかどうかを判定
if /\A[A-Za-z]/ =~ word
# 単語ごとに頭文字とその文字数を出力する
text = "#{word[0]}\t#{len}"
puts text unless text.nil?
end
}
}
end
end
Reducer
Reducer では Mapper の出力を統合して簡約します。
class Reducer
def self.reduce(stdin)
# 変数の準備
key = ""
wordcount = 0.0
lettercount = 0
# ソートされた Mapper の出力を逐次読み込む
stdin.each_line {|line|
newkey, wordlen = line.strip.split
# キーが変更となるごとに集計結果を出力する
if newkey.length > 0
unless key == newkey
# 文字数の合計を頻度で除算し、平均を求める
count = lettercount / wordcount
puts "#{key}\t#{count}\n" unless count.nan?
key = newkey
wordcount = 0.0
lettercount = 0
end
wordcount += 1.0
lettercount += wordlen.to_i
end
}
# 最後の 1 行のために
unless key.nil?
count = lettercount / wordcount
puts "#{key}\t#{count}\n" unless count.nan?
end
end
end
Hadoop Streaming 出力結果の統計
Hadoop で全数調査した結果から要約統計量を求めます。
これにより母集団の統計量 (母平均、母分散など) が判明しますから、様々な標本抽出法を適用することができるようになります。また母集団の特徴も明らかになり、母集団分布に色々なモデルを仮定して考えることができるようになります。
ワードカウントのように特徴の頻度を算出したとき、その頻度の分布から統計量を求めてプロッティングをしてみます。今までも説明した通り pandas と matplotlib は Hadoop の出力を分析するにあたっても親和性が高く強力な効果を発揮します。
import sys, os
import json
import pandas as pd
import matplotlib.pyplot as plt
class Summary:
def __init__(self, args):
# 第一引数をファイル名として解釈する
self.filename = args[1]
def calc(self):
# タブ区切りの Hadoop の出力を読み込む
df = pd.read_csv(self.filename, sep='\t').sort_index(by=['0'], ascending=[False]).ix[:, '0']
# 要約統計量を算出
print( df.describe() )
# 値の登場頻度をカウント
print( df.value_counts() )
# 棒グラフで頻度の頻度を描画
self._plot(s)
def _plot(self, s):
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.hist(s, bins=50, alpha=0.6)
plt.xticks([1,2,3,4,5,10,20,30,50,60,70,80])
plt.show()
plt.savefig("image.png")
if __name__=='__main__':
if len(sys.argv) > 1:
summary = Summary(sys.argv)
summary.calc()
else:
print("Invalid arguments")
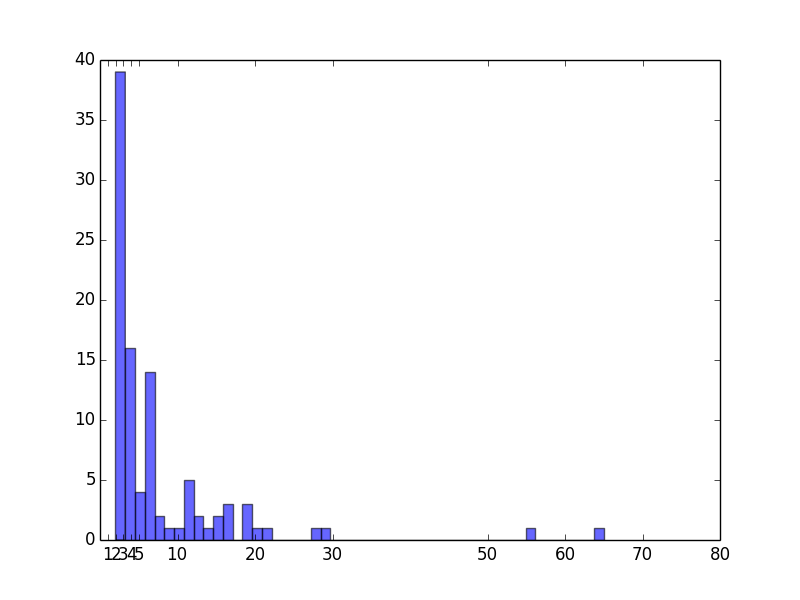
describe() 関数は代表的な要約統計量を求めます。上のコードでたとえば次のように統計量が求まります。
count 99.000000 # 件数
mean 7.818182 # 平均値
std 9.444104 # 標準偏差
min 2.000000 # 最小値
25% 3.000000 # 第一四分位
50% 4.000000 # 第ニ四分位 (中間値)
75% 8.000000 # 第三四分位
max 65.000000 # 最大値
分散は標準偏差の二乗ですから、これだけの情報があれば母集団の統計量としては事足りそうですね。
value_counts() 関数は値の頻度を求めます。ここではワードカウントの結果ですから、特徴の登場頻度の頻度がわかるわけです。
3 38
4 16
6 9
7 5
11 4
5 4
19 3
13 2
16 2
15 2
8 2
9 1
10 1
65 1
12 1
55 1
14 1
17 1
20 1
21 1
28 1
29 1
2 1
これを pandas + matplotlib でプロッティングするとこうなります。
まとめ
Hadoop Streaming の実践にあたり、ジョブ間の連結や外部ファイル読み込み、コードの書き方、さらに出力結果に対する分析について説明しました。母集団を手軽に全数調査できる Hadoop が Ruby で扱うことによって柔軟で実用性の高いツールとなることがおわかりになったかと思います。