こんにちはリヒトです。
環境研究所で販売されている日本語文字認識データセットを入手したので、データセットを活用したDeepLearning初学者のためのチュートリアルを公開します。
日本語の文字認識エンジンの開発にトライします。
以下の画像を見てもわかる様に、ゲシュタルト崩壊請け合いなチュートリアルですが、めげずに頑張っていきたいと思います。

なおこの記事は
・DeepLearningをはじめたい!
・mnistの数字認識以外のチュートリアルをやりたい!
・DeepLearning関連技術について学びたい!
・自分で日本語OCRの開発をしたい!
という方々に向けて書いています。
以下のアウトラインで説明します。
| 章 | タイトル |
|---|---|
| 1章 | chainerをベースにしたDeepLearning環境の構築 |
| 2章 | 機械学習によるDeepLearning予測モデルの作成 |
| 3章 | モデルを利用した文字認識 |
| 4章 | データ拡大による認識精度の改善 |
| 5章 | ニューラルネット入門とソースコードの解説 |
| 6章 | Optimizerの選択による学習効率の改善 |
| 7章 | TTA, BatchNormalizationによる学習効率の改善 |
DeepLearningは完全に初めて、という方はとにかく動く物を見て欲しいので4章目までトライして下さい。
5章以下はDeepLearningについてもう一歩詳しく知りたいという人向けです。
はじめに
なぜchainer?
chainerは国産OSSです。何より使いやすいし、理解しやすいしGoogle Groupでchainerに関する質問をしてもすぐに無料でレスポンスしてくれるなど最高。
環境
本編はMacを前提にお話しますが、随時Windowsに合わせてそれぞれ説明(違いは環境準備だけですが)します。
・マシンスペック:メモリ4GB以上
・Python2.7系, pipがインストールされていること
環境準備(Mac)
ターミナルで
sudo pip install chainer
を入力し、chainer1.6.0, filelock2.0.5, nose1.3.7, numpy1.10.4, protobuf2.6.1を一括インストールします。
sudo pip install scipy
を入力し、scipy0.17.0をインストールします。
またこちらの記事を参考にOpencv2.4.X系をインストールして下さい。
環境準備(Windows)
コマンドプロンプトで
pip install chainer
を入力し、chainer1.6.0, filelock2.0.5, nose1.3.7, numpy1.10.4, protobuf2.6.1を一括インストールします。
pip install scipy
を入力し、scipy0.17.0をインストールします。必要に応じてコマンドプロンプトを管理者モードで起動してください。
またこちらの記事を参考にOpencv2.4.X系をインストールして下さい。
データの準備(Mac, Windows)
環境研のウェブサイトから平仮名データセットを購入(1000円)してダウンロードします。
デスクトップに"HIRAGANA_NN"というディレクトリを作成してその中に解凍します。
-DESKTOP
-HIRAGANA_NN
-304a
-304b
・
・
(参考)以下の画像の様になっていればOKです。
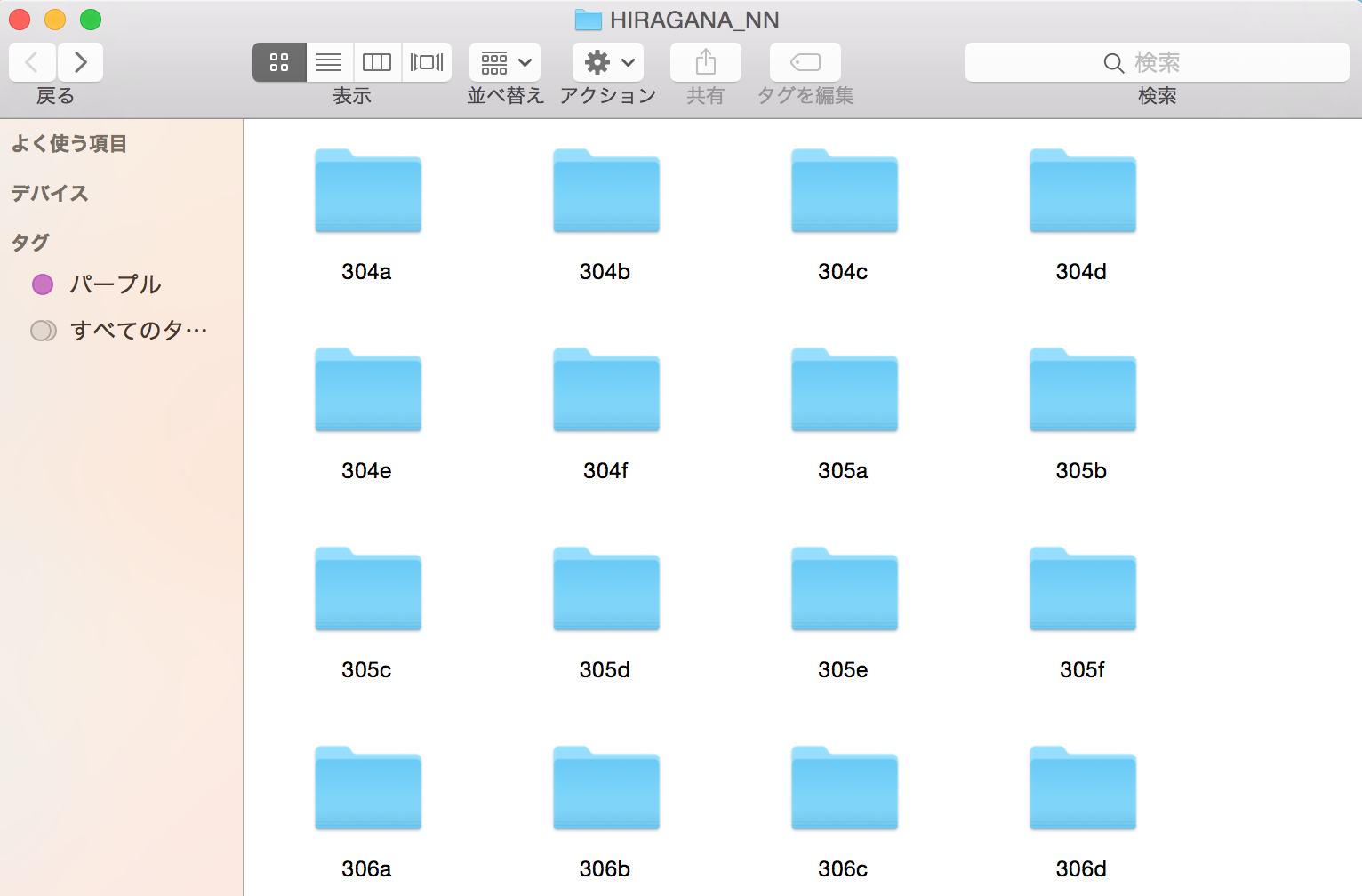
なお304aなどのディレクトリはそれぞれの平仮名のUnicodeを示しており、中身は以下の様になっています
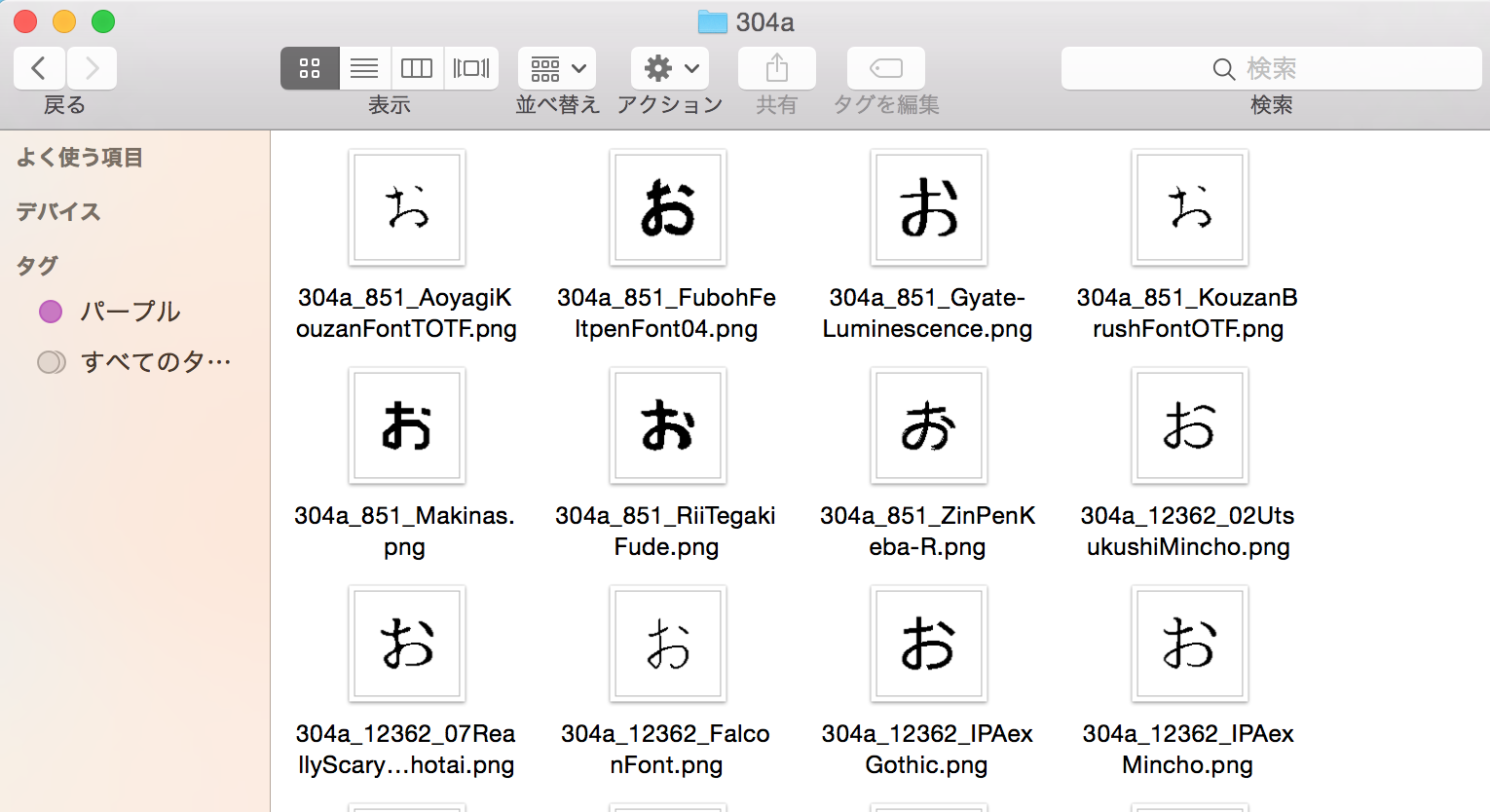
これで準備が完了です。
次2章から機械学習に進んで行きたいと思います!
| 章 | タイトル |
|---|---|
| 1章 | chainerをベースにしたDeepLearning環境の構築 |
| 2章 | 機械学習によるDeepLearning予測モデルの作成 |
| 3章 | モデルを利用した文字認識 |
| 4章 | データ拡大による認識精度の改善 |
| 5章 | ニューラルネット入門とソースコードの解説 |
| 6章 | Optimizerの選択による学習効率の改善 |
| 7章 | TTA, BatchNormalizationによる学習効率の改善 |