こんにちはリヒトです。こちらに続いてDeepLearningチュートリアル2章
機械学習によるDeepLearning予測モデルの生成について説明します。
ニューラルネットが具体的にどの様に機械学習していくかは後の章にまとめて説明するとして、
ここでは実践的な使い方を紹介します。
準備
まずはこちらのGithubからソースコードをダウンロードしてhiraganaNN.py以下全てを先ほどの画像データセットと同じディレクトリに置きます。
2章ではhiraganaNN.py, dataArgs.py, hiragana_unicode.csvを使います。
実行
ターミナル(コマンドプロンプト)でHIRAGANA_NNディレクトリまで移動してから
python hiraganaNN.py
で起動します。
これでDeepLearningによる機械学習がスタートするのですが学習に時間がかかるので待っている間に少し解説をします。
HIRAGANA_NNディレクトリの中には平仮名それぞれにディレクトリ分けされた画像(110*110ピクセル)が格納されています。
例えば305eディレクトリには平仮名の「ぞ」の画像が色んなフォント・手書きで以下の様に登録されています。
機械学習の目的は色んな「ぞ」の画像から「ぞ」って一般的にはどんな形をしたもの?というのを学習しようという試みです。つまりこれらは「ぞ」なのだから(学習)

これは「ぞ」だよね?(識別・予想・認識とか言われる)という事がしたい訳です。
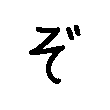
簡単な様に聞こえますが機械は単純なので人間では思いもよらないミスをしたりします。
例えば上を「ぞ」を学習した。だから下は「ぞ」ではない!キッパリ

(なぜなら少し傾いているから)
こういった行き過ぎた学習(上の「ぞ」以外は「ぞ」と認められない)によるミス(汎用性の劣化)を「過学習」と言います。
また文字の色・濃度など認識する上で本来関係の無い所で学習が難しくなっている学習効率の悪化なども性能劣化の原因です。

過学習や学習効率の悪化などの性能劣化を避けるための「前処理」を行います。
前処理は様々ですがデータ拡大(回転・移動・弾性歪み・ノイズなど)(色んな「ぞ」を学習しておけば何が来ても大丈夫!)や、

問題を単純にして学習効率をアップさせるデータ正規化(グレースケール化、白色化、バッチ正規化など)などがその一例です。
ソースコードの概要
1行目から順に
unicode2number = {}
import csv
train_f = open('./hiragana_unicode.csv', 'rb')
train_reader = csv.reader(train_f)
train_row = train_reader
hiragana_unicode_list = []
counter = 0
for row in train_reader:
for e in row:
unicode2number[e] = counter
counter = counter + 1
ここでは各平仮名に番号付けをしています。unicodeが304a(お)のものは0番、304b(か)のものは1番という具合です。
次に
files = os.listdir('./')
for file in files:
if len(file) == 4:
# 平仮名ディレクトリ
_unicode = file
imgs = os.listdir('./' + _unicode + '/')
counter = 0
for img in imgs:
if img.find('.png') > -1:
if len(imgs) - counter != 1:
...
ここでは入力データ(学習データ)としての画像を読み込んでいます。各ディレクトリの一番最後の画像だけテスト用に読み込みます。
読み込み時には
x_train.append(src)
y_train.append(unicode2number[_unicode])
という風にx_train(x_test)には画像データ、y_train(y_test)には正解のラベル(0-83)を格納して行きます。
1枚の入力データの画像に対してデータ拡大を施して行くのが以下の部分で
for x in xrange(1, 10):
dst = dargs.argumentation([2, 3])
ret, dst = cv2.threshold(
dst, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
x_train.append(dst)
y_train.append(unicode2number[_unicode])
ここではランダムに移動と回転を施して10枚に拡大しています。
dargs.argumentation([2, 3])の2, 3は凄まじく分かり辛いですが順に2:回転(3次元的な奥行きを持った回転)と3:移動で、回転処理を施した後に移動処理を施しています。
各ディレクトリの
次は
x_train = np.array(x_train).astype(np.float32).reshape(
(len(x_train), 1, IMGSIZE, IMGSIZE)) / 255
y_train = np.array(y_train).astype(np.int32)
グレースケールの画像は0-255の画素値を持っていますがこれを255で割る事で0-1の値に正規化しています。この処理によって学習効率が向上します。
以上は学習データ用(x_train, y_train)の準備でしたがテスト用(x_test, y_test)の準備も同様に行います。
ここでは各ディレクトリにある最後の1枚をテスト用として読み込んで機械学習しているモデルの精度を検証します。
テスト用の画像も拡大して読み込んでいますが、ここら辺の理由は7章あたりに書きます。
以降はDeepLearningの具体的な構造についてなので後々の章に説明をまとめます。
学習結果
そうこうしている内にターミナルに機械学習の進捗が出てきました。
('epoch', 1)
COMPUTING...
train mean loss=3.53368299341, accuracy=0.161205981514
test mean loss=1.92266467359, accuracy=0.506097565337
('epoch', 2)
COMPUTING...
train mean loss=1.66657279936, accuracy=0.518463188454
test mean loss=1.0855880198, accuracy=0.701219529277
.
.(warningとかも出てきますが取り敢えず無視でOK)
('epoch', 16)
COMPUTING...
train mean loss=0.198548029516, accuracy=0.932177149753
test mean loss=0.526535278777, accuracy=0.844512195849
.
.
('epoch', 23)
COMPUTING...
train mean loss=0.135178960405, accuracy=0.954375654268
test mean loss=0.686121761981, accuracy=0.814024389154
lossというのはDeepLearningよって予測された出力と正解との誤差と思っていて下さい。accuracyは正答率です
機械学習ではtestデータのlossを下げる事が目標です。
学習が進むに連れて、train, testのlossが下がって行きますがepoch16を境にtrainのlossは下がるが
testのlossは増えていく過学習の傾向がみられます。
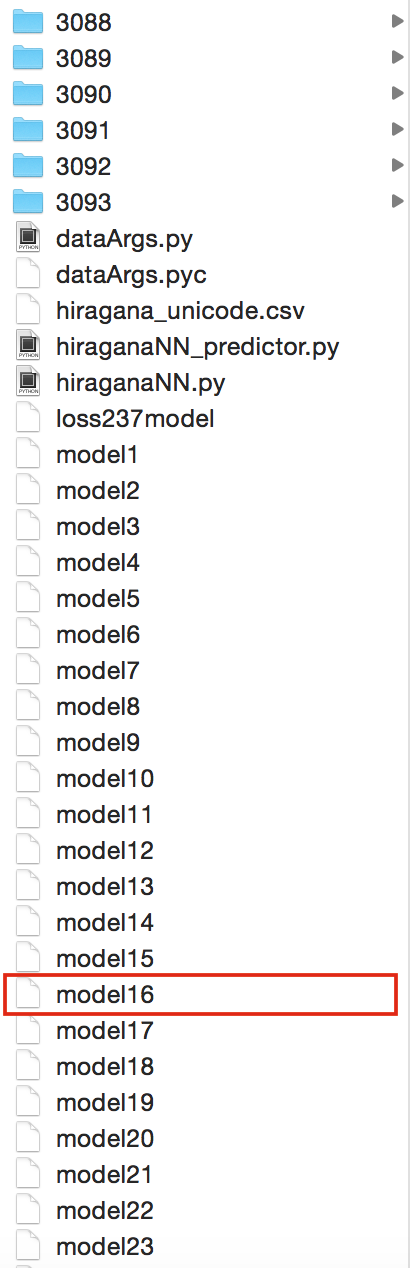
こうなったら学習は限界という事で終了。取り敢えず今回のモデルではepoch16のtest loss=0.526が最も良い結果を出しています。(この精度向上への取り組みは後の章)
ソースコードと同じディレクトリに各epochのDeepLearningの学習結果が保存されているので、
最も結果の良かった'model16'というファイルを取っておいて下さい。(他のモデルファイルは消してもOKです)
次回の第3章はこのモデルを利用した実際の予測を行います。
| 章 | タイトル |
|---|---|
| 1章 | chainerをベースにしたDeepLearning環境の構築 |
| 2章 | 機械学習によるDeepLearning予測モデルの作成 |
| 3章 | モデルを利用した文字認識 |
| 4章 | データ拡大による認識精度の改善 |
| 5章 | ニューラルネット入門とソースコードの解説 |
| 6章 | Optimizerの選択による学習効率の改善 |
| 7章 | TTA, BatchNormalizationによる学習効率の改善 |