Deep Learning Advent Calendar 2016の20日目の記事です。
ConvNetの歴史とResNet亜種、ベストプラクティスに関連スライドがあります(追記)
背景
府大生が趣味で世界一の認識精度を持つニューラルネットワークを開発してしまったようです。
府大のプレスリリース [一般物体認識分野で、府大生が世界一の認識精度を持つニューラルネットワークを開発](http://www.osakafu-u.ac.jp/news/publicity-release/pr20161209/) 黄瀬先生の研究室の学生さんだそうです。凄いですね!M2の学生が趣味でやっていたCIFAR10とCIFAR100の認識タスクで,現時点での世界最高性能の結果を出したそうだ…趣味でっていうのが…https://t.co/HKFLXTMbzx
— ニーシェス (@lachesis1120) 2016年12月7日
ちょうどResNet系に興味があったので、読んでみます。この論文を理解するには、ResNet, (Wide ResNet,) PyramidNet, stochastic depthといった手法を理解する必要がある(逆にそれらを理解すれば主張はシンプル)ので、順に解説したいと思います。
Residual Networks
Residual Networks (ResNet) [1] は、大規模画像認識のコンペティションであるILSVRC'15で1位を勝ち取ったMSRAが提案した畳み込みニューラルネットワークのアーキテクチャです。
これまでネットワークを深くすることで表現能力を向上させ、認識精度を改善することが行われてきましたが、あまりにも深いネットワークは最適化が非常に難しいことが実験的に示されています。興味深いのは、過学習をしてテストエラーが大きくなるのではなく、訓練時のロスですら下がらなくなるということです。
これに対しResNetでは、通常のネットワークのように、何かしらの処理ブロックによる変換F(x)を単純に次の層に渡していくのではなく、その処理ブロックへの入力xをショートカットし、F(x)+xを次の処理ブロックに渡すことが行われます。この処理単位はresidual unit (or building block) と呼ばれます。
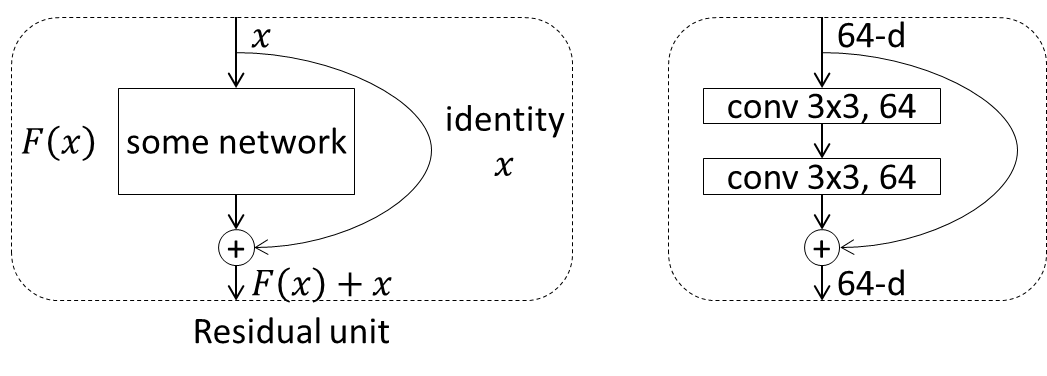
左が抽象的なresidual unitの構成で、右が具体的によく使われるresidual unitの例で、フィルタサイズ3x3、フィルタ数64の畳み込み層が2つ配置されています。本来はこの中にbatch normalizationとReLU層が配置されますが、その並べ方は様々なため省略しています。
このショートカットにより、各residual unitは入力と最適な出力に対する残差を学習する形となり、最適化が効率的に行われます(個人的にはbackpropagation時にショートカットを介して勾配が下層に伝わりやすくなることのほうが大きいのではという気がしていますが)。
ResNetでは、上記のresidual unitを最小単位として、それらを重ね合わせることで1つのネットワークを構築します。例えば上の図の右のresidual unitを [conv 3x3, 64] のように記載すると、ResNetのネットワークの1例は下記のようなものになります。

Residual unitの重ね合わせに決まりがあるわけではありませんが、一般的に同一のフィルタ数を持つunitを一定数積み重ね、画像サイズを半分にしつつフィルタ数を2倍にすることを繰り返すネットワークが利用されます。気になるポイントとしては、画像サイズを半分にするダウンサンプリングではmax poolingではなく、(2, 2)-strideのconvolutionにより行われること、ネットワークの最後はglobal average pooling [2] が利用されることが挙げられます。
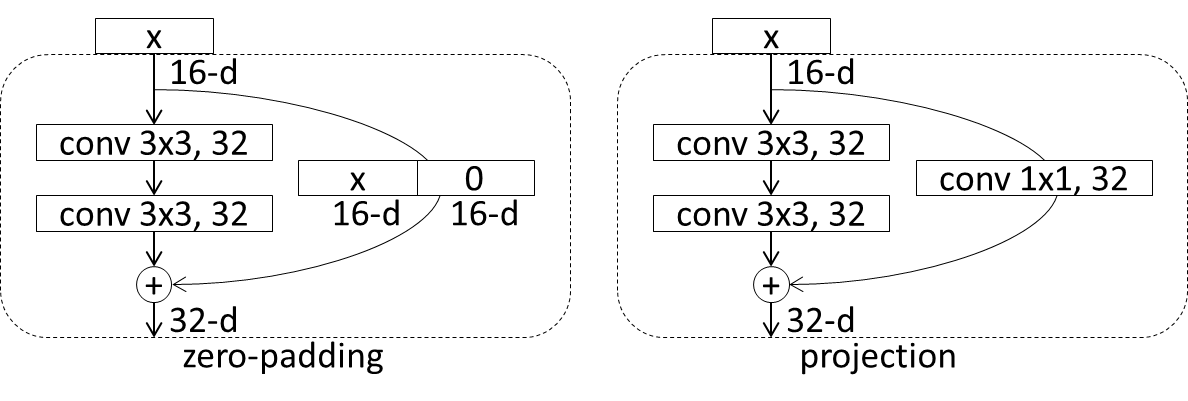
ショートカットは基本的にはidentity functionが利用されますが、入力次元と出力次元が違う(通常出力次元が大きい)場合はいくつかオプションがあります。例えば上の図の※部分では、入力が16次元で出力が32次元のresidual unitがあり、単純なidentity functionが利用できません。このケースでは、①入力次元分だけをそのまま流して足りない次元を0で埋めるzero-paddingと、②[conv 1x1, 出力次元数]のconvolutionにより次元を水増しするprojectionの2パターンのショートカットが利用されます。Zero-paddingのアプローチのほうが、パラメータを増加させないことから良いとされます。
ResNetの面白い性質として、ランダムにResNetのresidual unitを削除したとしても、ネットワーク全体の認識精度がほとんど低下しないことが挙げられます[3]。
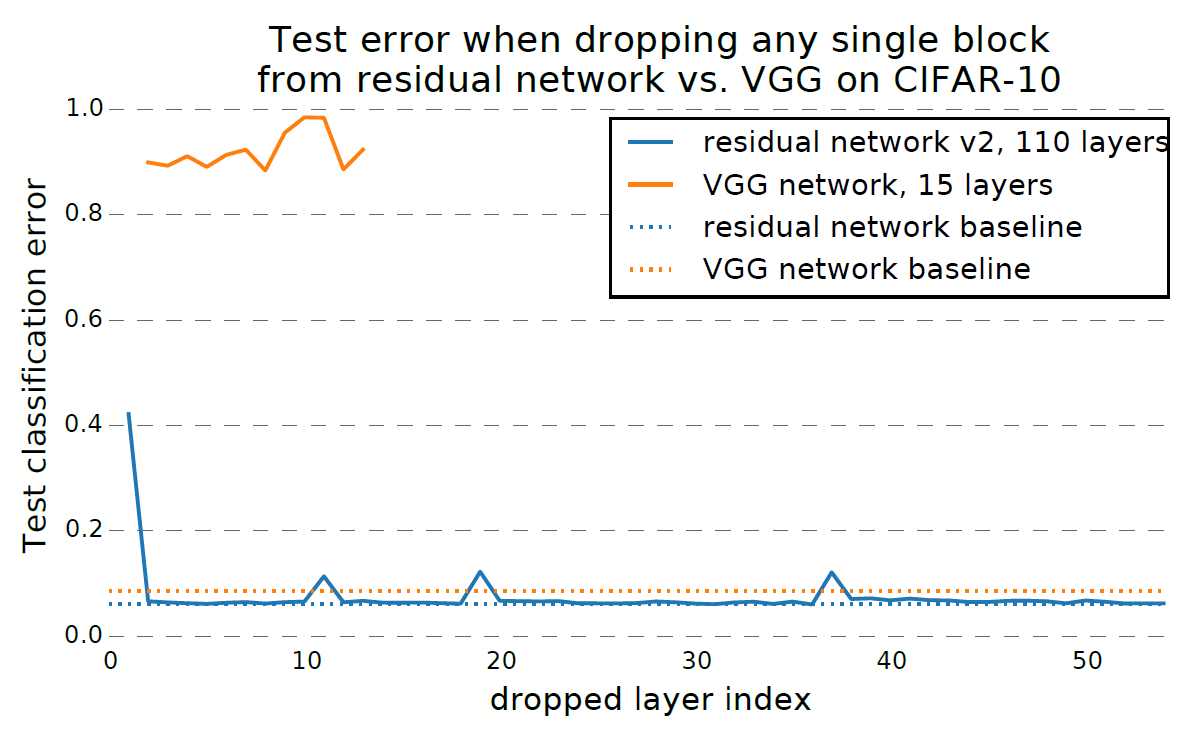
上図([3]より引用)では、VGGとNesNetでそれぞれランダムに1つだけレイヤを削除した場合の認識精度を示しています(VGGはレイヤを削除できるように次元数を揃えている)。VGGは1つでもレイヤを削除すると、認識精度はほぼランダムな認識と同じ程度まで劣化しますが、ResNetの場合は殆ど影響がありません。唯一、上図でダウンサンプリングを行っているresidual unitを削除した場合(上図の山になっている部分)に多少の劣化が発生しています。これはショートカットの存在により、ResNetが浅いネットワークのアンサンブル学習のようなことを行っているためと解釈できます。
ResNetのより詳細な解説記事は下記
http://qiita.com/supersaiakujin/items/935bbc9610d0f87607e8
http://qiita.com/supersaiakujin/items/eaa0fe0460c470c28bd8
Wide Residual Networks
Residual networksは非常に深いネットワークを学習することができましたが、少数のresidual unitのみが認識に有用な表現を学習する一方、多くのunitは情報をほとんど共有せずに、最終的な認識精度への貢献が小さいという問題あります。また、訓練時間が非常に大きくなるのも課題です。
これらの問題を解決するネットワークとしてwide residual networks (Wide ResNet) が提案されています[4]。これは、層を深くする代わりに、各residual unitの次元数(フィルタ数)を増加させたwideなネットワークを利用するというものです。それだけと言えばそれだけなのですが、たしかに学習時間を短縮しつつ、高い精度のネットワークを構成できるので実用的な印象です。
この論文では、別の貢献として、batch normalizationのお陰で必要性が薄れてきたdropoutをresidual unit内の2つのconvolution層の間に入れることも提案しています。
Deep Pyramidal Residual Networks
前述の通り、ResNetは浅いネットワークのアンサンブル学習になっているため、ランダムに層を削除しても精度がほとんど低下しませんでしたが、ダウンサンプリングを行っている層は唯一精度が低下していました。これは、ダウンサンプリングを行う層でフィルタ数を倍増させているためであり、ある種その層への依存が強くなってしまっていると言えます。この観点から、ResNetも完全なアンサンブル学習を実現しているとは言えません。
これを解決するネットワークとしてPyramidal Residual Networks (PyramidNet) が提案されています[5]。PyramidNetでは、ダウンサンプリングを行う層のみでフィルタ数を倍増させるのではなく、全てのresidual unitで少しずつフィルタ数を増加させていきます。増加のさせ方として、単調増加させるadditive PyramidNetと指数的に増加させるmultiplicative PyramidNetが提案されています。ResNetではダウンサンプリングする層でのみフィルタ数が増加していましたが、PyramidNetでは全てのresidual unitでフィルタ数が増加するため、全てのresidual unitでzero-paddingのショートカットを利用することになります(projectionはパラメータを持ちoverfitするため利用しない)。
 そのzero-paddingのショートカットは上図の(a)([5]から引用)のようなネットワークとなりますが、これは右の(b)のようなネットワークと解釈することもできます。すなわちPyramidNetははResNet(左側)と通常のConvNet(右側)両方を併せ持ったネットワークと言えます。
そのzero-paddingのショートカットは上図の(a)([5]から引用)のようなネットワークとなりますが、これは右の(b)のようなネットワークと解釈することもできます。すなわちPyramidNetははResNet(左側)と通常のConvNet(右側)両方を併せ持ったネットワークと言えます。
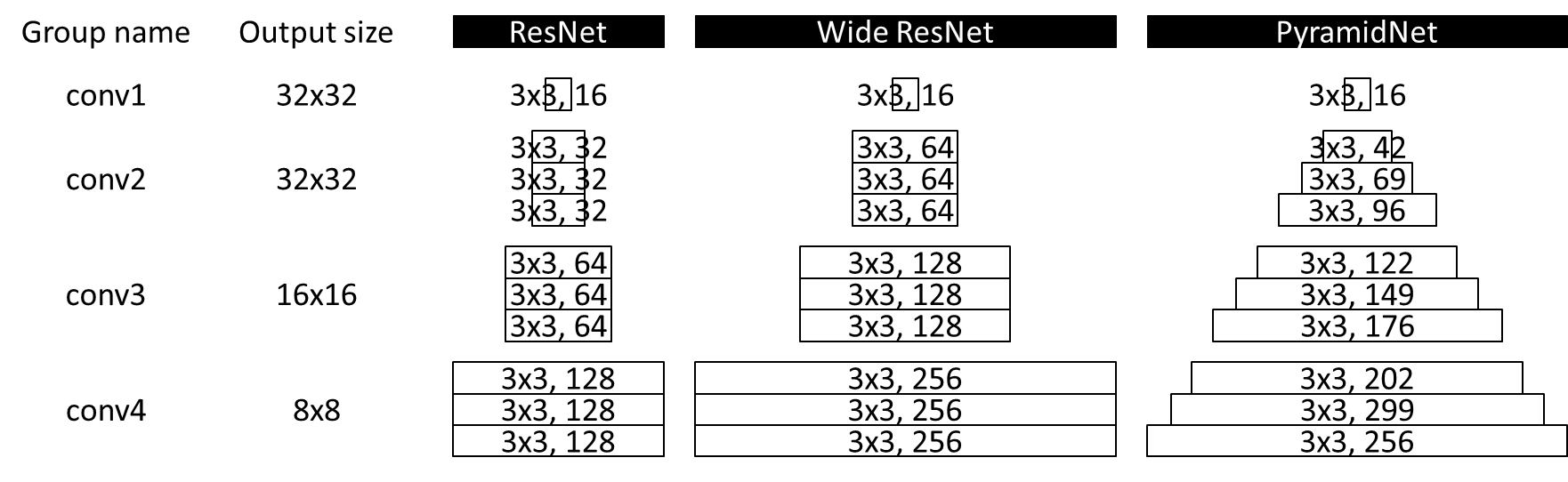
これまで紹介したResNet, Wide ResNet, PyramidNetを視覚的に比較すると下図のようになります(PyramidNetはadditiveなもの)。
Deep Networks with Stochastic Depth
上記のWide ResNetやPyramidNetで解決しようとしていた課題に対する別のアプローチがstochastic depth [6] です。実際にはこちらの論文が先で、その問題設定を[4, 5]が参照しているのですが、本記事では説明の都合上こちらを後回しにしています。
この論文のポイントは、ResNetは非常にdeepであることが学習を難しくしているので、訓練時は「期待値で見たときの深さ」を浅くしてあげようというアプローチを取っている点にあります。具体的には、バッチ毎にresidual unitをランダムにdropするということを行います(ショートカットは残す)。そのdropする確率は層の出力に近いほど高くなるように線形に増加させます(最後の層は確率pLでdrop)。これにより、期待値で見たときのネットワークの深さが小さくなり、学習がスムーズに進みます。
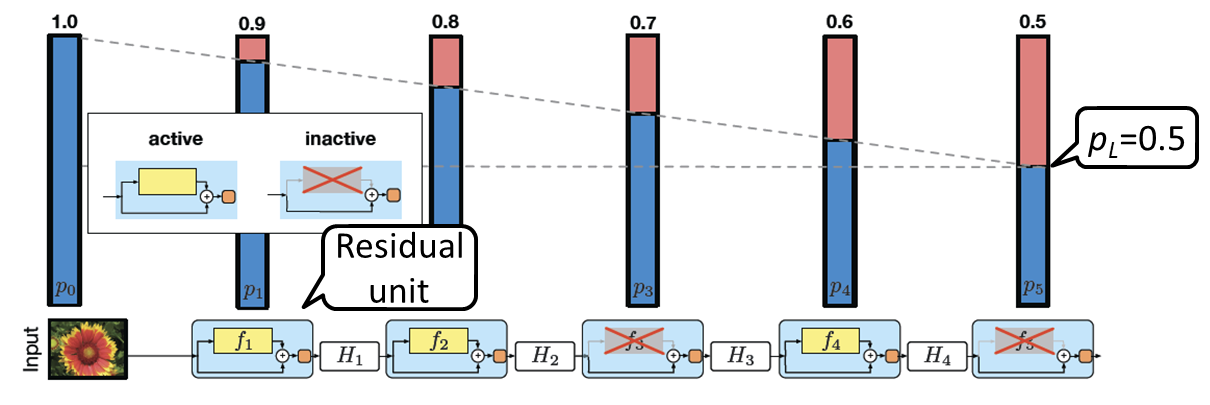
テスト時には、dropoutと同様にdropする確率の逆数を出力にかけてあげます。これはいわばresidual unitに対するdropoutと言えます。
Stochastic Depthのより詳細な解説記事は下記
http://qiita.com/supersaiakujin/items/eb0553a1ef1d46bd03fa
Deep Pyramidal Residual Networks with Separated Stochastic Depth
やっと本題の論文[7]です。ここまで来ればこの論文の主張はスムーズに理解できます。すなわち、名前の通りPyramidNetにStochastic Depthを適用したもの、です。但し、separetedとあるように、単純な組み合わせではありません。
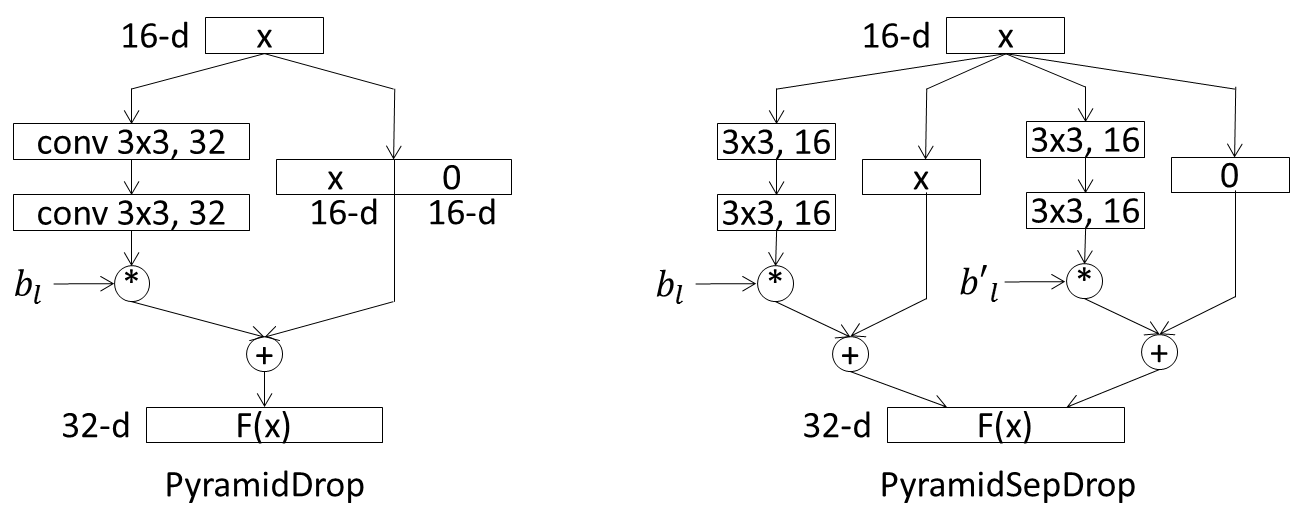
単純な組み合わせ (PyramidDrop) では、上図の左のようなネットワーク構成となります。ここでblはl番目のresidual unitに対応するdrop率に従ってdropを行うかどうかを制御するベルヌーイ変数です。これに対し、本論文で提案されているPyramidSepDropは、上の図の右のように、入力xの次元に対応するconv層の出力と、残りの次元に対応するconv層の出力それぞれに対し、異なるベルヌーイ変数bl, b'lを利用して、独立にdropを制御します。
上の図は前述のPyramidNetにおけるネットワークの解釈(ResNetとConvNetの組み合わせ)に合わせてネットワークを分けて描いています。こうしてみると、独立にdropすることは、逆に自然な制御ではないかと思えます。
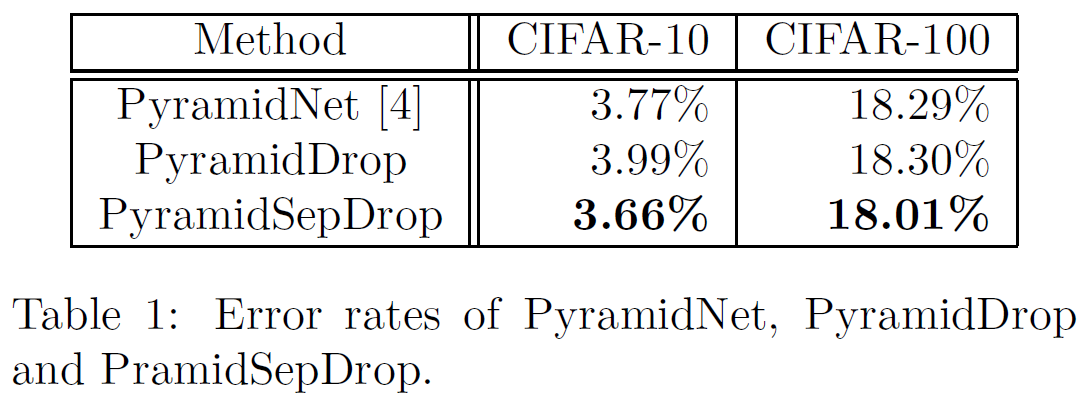
結果は下記のように、単純な組み合わせであるPyramidDropはPyramidNetに対しエラー率が上昇するのに対し、提案手法であるPyramidSepDropはstate-of-the-artのエラー率を達成していることが分かります。
以上、PyramidSepDropの解説でした。
間違い等ありましたらご指摘下さい。
[1] K. He, X. Zhang, S. Ren, and J. Sun, "Deep Residual Learning for Image Recognition," in Proc. of CVPR, 2016.
[2] M. Lin, Q. Chen, and S. Yan, "Network In Network," ICLR, 2014.
[3] A. Veit, M. Wilber, and S. Belongie, "Residual Networks Behave Like Ensembles of Relatively Shallow Networks," NIPS, 2016.
[4] S. Zagoruyko and N. Komodakis, "Wide Residual Networks," in Proc. of BMVC, 2016.
[5] D. Han, J. Kim, and J. Kim, "Deep Pyramidal Residual Networks," arXiv:1610.02915, 2016.
[6] G. Huang, Y. Sun, Z. Liu, D. Sedra, and K. Weinberger, "Deep Networks with Stochastic Depth," in Proc. of ECCV, 2016.
[7] Y. Yamada, M. Iwamura, and K. Kise, "Deep Pyramidal Residual Networks with Separated Stochastic Depth," arXiv:1612.01230, 2016.