はじめに
最近,ニューラルネットライブラリ界隈でPyTochがにわかに盛り上がり始めたので触ってみました.ただ,触ってみるだけでは面白くないのでChainerと比較しつつ,DeepPose: Human Pose Estimation via Deep Neural Networksを実装してみました.
なお,PyTorch自身の概要などはpytorch超入門がわかりいいです.
実装
では,早速DeepPoseをChainer(1.19.0)とPyTorch(0.1.10)で実装してみたいと思います.
- Model
- Loss Function
- Train
の順でChainerとPyTorchを比較しつつ実装していきます.
Model
ChainerとPyTorchでほぼ同じコードで書けます.強いて言えば,PyTorchでは Convolutional Layer の出力を Fully Connected Layer に入力するにあたり,明示的に view で変換する必要があることくらいでしょうか.
Chainer
# -*- coding: utf-8 -*-
""" AlexNet implementation. """
import chainer
import chainer.functions as F
import chainer.links as L
from modules.functions.chainer import mean_squared_error
class AlexNet(chainer.Chain):
""" The AlexNet :
'A. Krizhevsky, I. Sutskever, and G. Hinton.
Imagenet clas-sification with deep convolutional neural networks. InNIPS , 2012'
Args:
Nj (int): Size of joints.
use_visibility (bool): When it is ``True``,
the function uses visibility to compute mean squared error.
"""
def __init__(self, Nj, use_visibility=False):
super(AlexNet, self).__init__(
conv1=L.Convolution2D(None, 96, 11, stride=4),
conv2=L.Convolution2D(None, 256, 5, pad=2),
conv3=L.Convolution2D(None, 384, 3, pad=1),
conv4=L.Convolution2D(None, 384, 3, pad=1),
conv5=L.Convolution2D(None, 256, 3, pad=1),
fc6=L.Linear(None, 4096),
fc7=L.Linear(None, 4096),
fc8=L.Linear(None, Nj*2),
)
self.Nj = Nj
self.use_visibility = use_visibility
self.train = True
def predict(self, x):
""" Predict 2D pose from image. """
# layer1
h = F.relu(self.conv1(x))
h = F.max_pooling_2d(h, 3, stride=2)
# layer2
h = F.relu(self.conv2(h))
h = F.max_pooling_2d(h, 3, stride=2)
# layer3-5
h = F.relu(self.conv3(h))
h = F.relu(self.conv4(h))
h = F.relu(self.conv5(h))
h = F.max_pooling_2d(h, 3, stride=2)
# layer6-8
h = F.dropout(F.relu(self.fc6(h)), train=self.train)
h = F.dropout(F.relu(self.fc7(h)), train=self.train)
h = self.fc8(h)
return F.reshape(h, (-1, self.Nj, 2))
def __call__(self, image, x, v):
y = self.predict(image)
loss = mean_squared_error(y, x, v, use_visibility=self.use_visibility)
chainer.report({'loss': loss}, self)
return loss
PyTorch
# -*- coding: utf-8 -*-
""" AlexNet implementation. """
import torch.nn as nn
import torch.nn.functional as F
class AlexNet(nn.Module):
""" The AlexNet :
'A. Krizhevsky, I. Sutskever, and G. Hinton.
Imagenet clas-sification with deep convolutional neural networks. InNIPS , 2012'
Args:
Nj (int): Size of joints.
"""
def __init__(self, Nj):
super(AlexNet, self).__init__()
self.conv1 = nn.Conv2d(3, 96, 11, stride=4)
self.conv2 = nn.Conv2d(96, 256, 5, padding=2)
self.conv3 = nn.Conv2d(256, 384, 3, padding=1)
self.conv4 = nn.Conv2d(384, 384, 3, padding=1)
self.conv5 = nn.Conv2d(384, 256, 3, padding=1)
self.fc6 = nn.Linear(256*6*6, 4096)
self.fc7 = nn.Linear(4096, 4096)
self.fc8 = nn.Linear(4096, Nj*2)
self.Nj = Nj
def forward(self, x):
# layer1
h = F.relu(self.conv1(x))
h = F.max_pool2d(h, 3, stride=2)
# layer2
h = F.relu(self.conv2(h))
h = F.max_pool2d(h, 3, stride=2)
# layer3-5
h = F.relu(self.conv3(h))
h = F.relu(self.conv4(h))
h = F.relu(self.conv5(h))
h = F.max_pool2d(h, 3, stride=2)
h = h.view(-1, 256*6*6)
# layer6-8
h = F.dropout(F.relu(self.fc6(h)), training=self.training)
h = F.dropout(F.relu(self.fc7(h)), training=self.training)
h = self.fc8(h)
return h.view(-1, self.Nj, 2)
Loss Function
Loss Function に関してもほぼ同様に書くことが出来そうです.違いとしては,PyTorchの方は計算をTorchで実装する必要があるため,やや勉強が必要です.(Torchの勉強はこちらが参考になります.)
一方で, backward 計算を明示的に実装しなくても良さそうなのは嬉しい点です.(Chainerでも場合によっては, backward は不要かも分かりません.)
Chainer
# -*- coding: utf-8 -*-
""" Mean squared error function. """
import numpy as np
from chainer import function
from chainer.utils import type_check
class MeanSquaredError(function.Function):
""" Mean squared error (a.k.a. Euclidean loss) function. """
def __init__(self, use_visibility=False):
self.use_visibility = use_visibility
self.diff = None
self.N = None
def check_type_forward(self, in_types):
type_check.expect(in_types.size() == 3)
type_check.expect(
in_types[0].dtype == np.float32,
in_types[1].dtype == np.float32,
in_types[2].dtype == np.int32,
in_types[0].shape == in_types[1].shape,
in_types[0].shape[:-1] == in_types[2].shape[:-1]
)
def forward_cpu(self, inputs):
x, t, v = inputs
self.diff = x - t
if self.use_visibility:
self.N = v.sum()/2
self.diff *= v
else:
self.N = self.diff.size/2
diff = self.diff.ravel()
return np.array(diff.dot(diff)/self.N, dtype=diff.dtype),
def forward_gpu(self, inputs):
x, t, v = inputs
self.diff = x - t
if self.use_visibility:
self.N = int(v.sum())/2
self.diff *= v
else:
self.N = self.diff.size/2
diff = self.diff.ravel()
return diff.dot(diff)/diff.dtype.type(self.N),
def backward(self, inputs, gy):
coeff = gy[0]*gy[0].dtype.type(2./self.N)
gx0 = coeff*self.diff
return gx0, -gx0, None
def mean_squared_error(x, t, v, use_visibility=False):
""" Computes mean squared error over the minibatch.
Args:
x (Variable): Variable holding an float32 vector of estimated pose.
t (Variable): Variable holding an float32 vector of ground truth pose.
v (Variable): Variable holding an int32 vector of ground truth pose's visibility.
(0: invisible, 1: visible)
use_visibility (bool): When it is ``True``,
the function uses visibility to compute mean squared error.
Returns:
Variable: A variable holding a scalar of the mean squared error loss.
"""
return MeanSquaredError(use_visibility)(x, t, v)
PyTorch
# -*- coding: utf-8 -*-
""" Mean squared error function. """
import torch.nn as nn
class MeanSquaredError(nn.Module):
""" Mean squared error (a.k.a. Euclidean loss) function. """
def __init__(self, use_visibility=False):
super(MeanSquaredError, self).__init__()
self.use_visibility = use_visibility
def forward(self, *inputs):
x, t, v = inputs
diff = x - t
if self.use_visibility:
N = (v.sum()/2).data[0]
diff = diff*v
else:
N = diff.numel()/2
diff = diff.view(-1)
return diff.dot(diff)/N
def mean_squared_error(x, t, v, use_visibility=False):
""" Computes mean squared error over the minibatch.
Args:
x (Variable): Variable holding an float32 vector of estimated pose.
t (Variable): Variable holding an float32 vector of ground truth pose.
v (Variable): Variable holding an int32 vector of ground truth pose's visibility.
(0: invisible, 1: visible)
use_visibility (bool): When it is ``True``,
the function uses visibility to compute mean squared error.
Returns:
Variable: A variable holding a scalar of the mean squared error loss.
"""
return MeanSquaredError(use_visibility)(x, t, v)
Train
最後は学習のコードです.こちらもほぼ同様なコードで実装することができます.学習については,Chainerの方がややこなれている感がありますが,PyTorchがv0.1.10(2017/3/28時点)であることを鑑みればPyTorchの今後に期待といった感じでしょうか.
Chainer
# -*- coding: utf-8 -*-
""" Train pose net. """
import os
import chainer
from chainer import optimizers
from chainer import training
from chainer.training import extensions
from chainer import serializers
from modules.errors import FileNotFoundError, UnknownOptimizationMethodError
from modules.models.chainer import AlexNet
from modules.dataset_indexing.chainer import PoseDataset
class TestModeEvaluator(extensions.Evaluator):
def evaluate(self):
model = self.get_target('main')
model.train = False
ret = super(TestModeEvaluator, self).evaluate()
model.train = True
return ret
class TrainPoseNet(object):
""" Train pose net of estimating 2D pose from image.
Args:
Nj (int): Number of joints.
use_visibility (bool): Use visibility to compute loss.
epoch (int): Number of epochs to train.
opt (str): Optimization method.
gpu (int): GPU ID (negative value indicates CPU).
train (str): Path to training image-pose list file.
val (str): Path to validation image-pose list file.
batchsize (int): Learning minibatch size.
out (str): Output directory.
resume (str): Initialize the trainer from given file.
The file name is 'epoch-{epoch number}.iter'.
resume_model (str): Load model definition file to use for resuming training
(it\'s necessary when you resume a training).
The file name is 'epoch-{epoch number}.model'.
resume_opt (str): Load optimization states from this file
(it\'s necessary when you resume a training).
The file name is 'epoch-{epoch number}.state'.
"""
def __init__(self, **kwargs):
self.Nj = kwargs['Nj']
self.use_visibility = kwargs['use_visibility']
self.epoch = kwargs['epoch']
self.gpu = kwargs['gpu']
self.opt = kwargs['opt']
self.train = kwargs['train']
self.val = kwargs['val']
self.batchsize = kwargs['batchsize']
self.out = kwargs['out']
self.resume = kwargs['resume']
self.resume_model = kwargs['resume_model']
self.resume_opt = kwargs['resume_opt']
# validate arguments.
self._validate_arguments()
def _validate_arguments(self):
for path in (self.train, self.val):
if not os.path.isfile(path):
raise FileNotFoundError('{0} is not found.'.format(path))
if self.opt not in ('MomentumSGD', 'Adam'):
raise UnknownOptimizationMethodError(
'{0} is unknown optimization method.'.format(self.opt))
if self.resume is not None:
for path in (self.resume, self.resume_model, self.resume_opt):
if not os.path.isfile(path):
raise FileNotFoundError('{0} is not found.'.format(path))
def _get_optimizer(self):
if self.opt == 'MomentumSGD':
optimizer = optimizers.MomentumSGD()
elif self.opt == "Adam":
optimizer = optimizers.Adam()
return optimizer
def start(self):
""" Train pose net. """
# initialize model to train.
model = AlexNet(self.Nj, self.use_visibility)
if self.resume_model:
serializers.load_npz(self.resume_model, model)
# prepare gpu.
if self.gpu >= 0:
chainer.cuda.get_device(self.gpu).use()
model.to_gpu()
# load the datasets.
train = PoseDataset(self.train)
val = PoseDataset(self.val, data_augmentation=False)
# training/validation iterators.
train_iter = chainer.iterators.MultiprocessIterator(
train, self.batchsize)
val_iter = chainer.iterators.MultiprocessIterator(
val, self.batchsize, repeat=False, shuffle=False)
# set up an optimizer.
optimizer = self._get_optimizer()
optimizer.setup(model)
if self.resume_opt:
chainer.serializers.load_npz(self.resume_opt, optimizer)
# set up a trainer.
updater = training.StandardUpdater(train_iter, optimizer, device=self.gpu)
trainer = training.Trainer(
updater, (self.epoch, 'epoch'), os.path.join(self.out, 'chainer'))
# standard trainer settings
trainer.extend(extensions.dump_graph('main/loss'))
val_interval = (10, 'epoch')
trainer.extend(TestModeEvaluator(val_iter, model, device=self.gpu), trigger=val_interval)
# save parameters and optimization state per validation step
resume_interval = (self.epoch/10, 'epoch')
trainer.extend(extensions.snapshot_object(
model, "epoch-{.updater.epoch}.model"), trigger=resume_interval)
trainer.extend(extensions.snapshot_object(
optimizer, "epoch-{.updater.epoch}.state"), trigger=resume_interval)
trainer.extend(extensions.snapshot(
filename="epoch-{.updater.epoch}.iter"), trigger=resume_interval)
# show log
log_interval = (10, "iteration")
trainer.extend(extensions.LogReport(trigger=log_interval))
trainer.extend(extensions.observe_lr(), trigger=log_interval)
trainer.extend(extensions.PrintReport(
['epoch', 'main/loss', 'validation/main/loss', 'lr']), trigger=log_interval)
trainer.extend(extensions.ProgressBar(update_interval=10))
# start training
if self.resume:
chainer.serializers.load_npz(self.resume, trainer)
trainer.run()
PyTorch
# -*- coding: utf-8 -*-
""" Train pose net. """
import os
import time
from tqdm import tqdm, trange
import torch
import torch.optim as optim
from torch.autograd import Variable
from torchvision import transforms
from modules.errors import FileNotFoundError, GPUNotFoundError, UnknownOptimizationMethodError
from modules.models.pytorch import AlexNet
from modules.dataset_indexing.pytorch import PoseDataset, Crop, RandomNoise, Scale
from modules.functions.pytorch import mean_squared_error
class TrainLogger(object):
""" Logger of training pose net.
Args:
out (str): Output directory.
"""
def __init__(self, out):
try:
os.makedirs(out)
except OSError:
pass
self.file = open(os.path.join(out, 'log'), 'w')
self.logs = []
def write(self, log):
""" Write log. """
tqdm.write(log)
tqdm.write(log, file=self.file)
self.logs.append(log)
def state_dict(self):
""" Returns the state of the logger. """
return {'logs': self.logs}
def load_state_dict(self, state_dict):
""" Loads the logger state. """
self.logs = state_dict['logs']
# write logs.
tqdm.write(self.logs[-1])
for log in self.logs:
tqdm.write(log, file=self.file)
class TrainPoseNet(object):
""" Train pose net of estimating 2D pose from image.
Args:
Nj (int): Number of joints.
use_visibility (bool): Use visibility to compute loss.
epoch (int): Number of epochs to train.
opt (str): Optimization method.
gpu (bool): Use GPU.
train (str): Path to training image-pose list file.
val (str): Path to validation image-pose list file.
batchsize (int): Learning minibatch size.
out (str): Output directory.
resume (str): Initialize the trainer from given file.
The file name is 'epoch-{epoch number}.iter'.
resume_model (str): Load model definition file to use for resuming training
(it\'s necessary when you resume a training).
The file name is 'epoch-{epoch number}.model'.
resume_opt (str): Load optimization states from this file
(it\'s necessary when you resume a training).
The file name is 'epoch-{epoch number}.state'.
"""
def __init__(self, **kwargs):
self.Nj = kwargs['Nj']
self.use_visibility = kwargs['use_visibility']
self.epoch = kwargs['epoch']
self.gpu = (kwargs['gpu'] >= 0)
self.opt = kwargs['opt']
self.train = kwargs['train']
self.val = kwargs['val']
self.batchsize = kwargs['batchsize']
self.out = kwargs['out']
self.resume = kwargs['resume']
self.resume_model = kwargs['resume_model']
self.resume_opt = kwargs['resume_opt']
# validate arguments.
self._validate_arguments()
def _validate_arguments(self):
if self.gpu and not torch.cuda.is_available():
raise GPUNotFoundError('GPU is not found.')
for path in (self.train, self.val):
if not os.path.isfile(path):
raise FileNotFoundError('{0} is not found.'.format(path))
if self.opt not in ('MomentumSGD', 'Adam'):
raise UnknownOptimizationMethodError(
'{0} is unknown optimization method.'.format(self.opt))
if self.resume is not None:
for path in (self.resume, self.resume_model, self.resume_opt):
if not os.path.isfile(path):
raise FileNotFoundError('{0} is not found.'.format(path))
def _get_optimizer(self, model):
if self.opt == 'MomentumSGD':
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
elif self.opt == "Adam":
optimizer = optim.Adam(model.parameters())
return optimizer
def _train(self, model, optimizer, train_iter, log_interval, logger, start_time):
model.train()
for iteration, batch in enumerate(tqdm(train_iter, desc='this epoch')):
image, pose, visibility = Variable(batch[0]), Variable(batch[1]), Variable(batch[2])
if self.gpu:
image, pose, visibility = image.cuda(), pose.cuda(), visibility.cuda()
optimizer.zero_grad()
output = model(image)
loss = mean_squared_error(output, pose, visibility, self.use_visibility)
loss.backward()
optimizer.step()
if iteration % log_interval == 0:
log = 'elapsed_time: {0}, loss: {1}'.format(time.time() - start_time, loss.data[0])
logger.write(log)
def _test(self, model, test_iter, logger, start_time):
model.eval()
test_loss = 0
for batch in test_iter:
image, pose, visibility = Variable(batch[0]), Variable(batch[1]), Variable(batch[2])
if self.gpu:
image, pose, visibility = image.cuda(), pose.cuda(), visibility.cuda()
output = model(image)
test_loss += mean_squared_error(output, pose, visibility, self.use_visibility).data[0]
test_loss /= len(test_iter)
log = 'elapsed_time: {0}, validation/loss: {1}'.format(time.time() - start_time, test_loss)
logger.write(log)
def _checkpoint(self, epoch, model, optimizer, logger):
filename = os.path.join(self.out, 'pytorch', 'epoch-{0}'.format(epoch))
torch.save({'epoch': epoch + 1, 'logger': logger.state_dict()}, filename + '.iter')
torch.save(model.state_dict(), filename + '.model')
torch.save(optimizer.state_dict(), filename + '.state')
def start(self):
""" Train pose net. """
# initialize model to train.
model = AlexNet(self.Nj)
if self.resume_model:
model.load_state_dict(torch.load(self.resume_model))
# prepare gpu.
if self.gpu:
model.cuda()
# load the datasets.
train = PoseDataset(
self.train,
input_transform=transforms.Compose([
transforms.ToTensor(),
RandomNoise()]),
output_transform=Scale(),
transform=Crop(data_augmentation=True))
val = PoseDataset(
self.val,
input_transform=transforms.Compose([
transforms.ToTensor()]),
output_transform=Scale(),
transform=Crop(data_augmentation=False))
# training/validation iterators.
train_iter = torch.utils.data.DataLoader(train, batch_size=self.batchsize, shuffle=True)
val_iter = torch.utils.data.DataLoader(val, batch_size=self.batchsize, shuffle=False)
# set up an optimizer.
optimizer = self._get_optimizer(model)
if self.resume_opt:
optimizer.load_state_dict(torch.load(self.resume_opt))
# set intervals.
val_interval = 10
resume_interval = self.epoch/10
log_interval = 10
# set logger and start epoch.
logger = TrainLogger(os.path.join(self.out, 'pytorch'))
start_epoch = 1
if self.resume:
resume = torch.load(self.resume)
start_epoch = resume['epoch']
logger.load_state_dict(resume['logger'])
# start training.
start_time = time.time()
for epoch in trange(start_epoch, self.epoch + 1, desc=' total'):
self._train(model, optimizer, train_iter, log_interval, logger, start_time)
if epoch % val_interval == 0:
self._test(model, val_iter, logger, start_time)
if epoch % resume_interval == 0:
self._checkpoint(epoch, model, optimizer, logger)
性能検証
PyTorchは速いと評判なので,速度をChainerと比較してみました.検証には論文同様に以下のデータセットを用いました.
学習時間
CPU環境とGPU環境でそれぞれ100epoch学習させた時の所要時間を計測しました.なお,CPU環境とGPU環境として,それぞれAWSのm4.large,g2.2xlargeを利用しました.
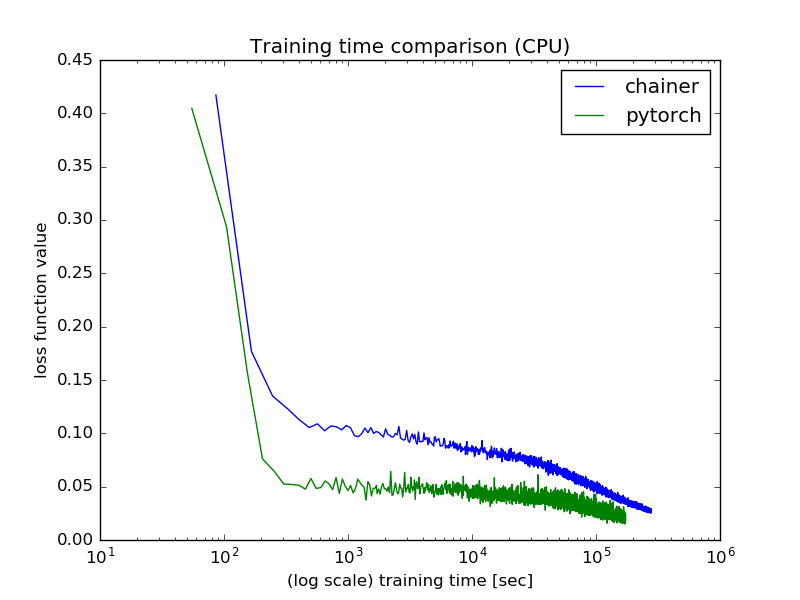
CPU環境
CPU環境では,PyTorchの方が1.6倍程度はやく学習が完了しました.
| ライブラリ | 所要時間 [h] |
|---|---|
| Chainer | 77.5 |
| PyTorch | 48.1 |
今回はChainerとPyTorchでそれぞれ実装されているMomentumSGDで学習させましたが,実装が異なるようで収束の様子が両者で異なっていました.ただし,学習セットに対してランダムなData Augmentationをかけているため,シードを揃える等すれば結果は異なってくるかも分かりません.
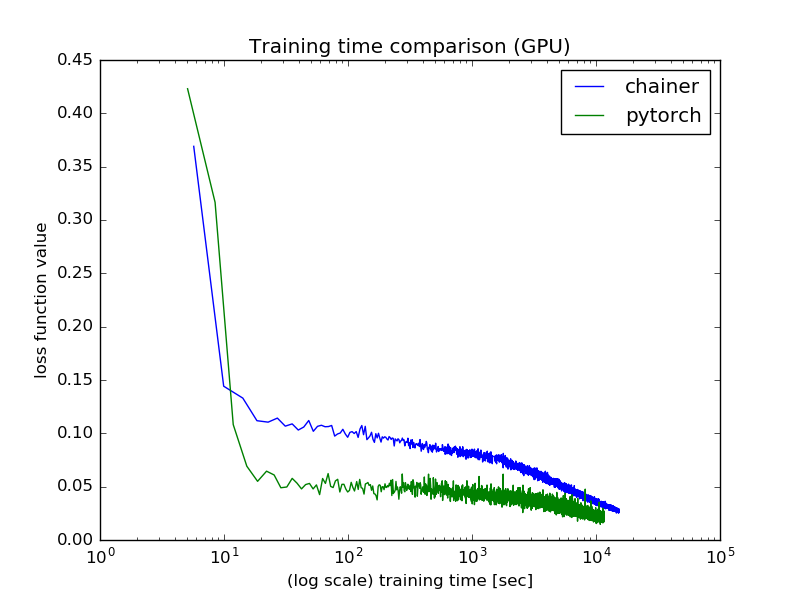
GPU環境
GPU環境では,PyTorchの方が1.3倍程度はやく学習が完了しました.
| ライブラリ | 所要時間 [h] |
|---|---|
| Chainer | 4.25 |
| PyTorch | 3.23 |
また,学習曲線はCPU環境と同様な傾向が見れました.
予測実行時間
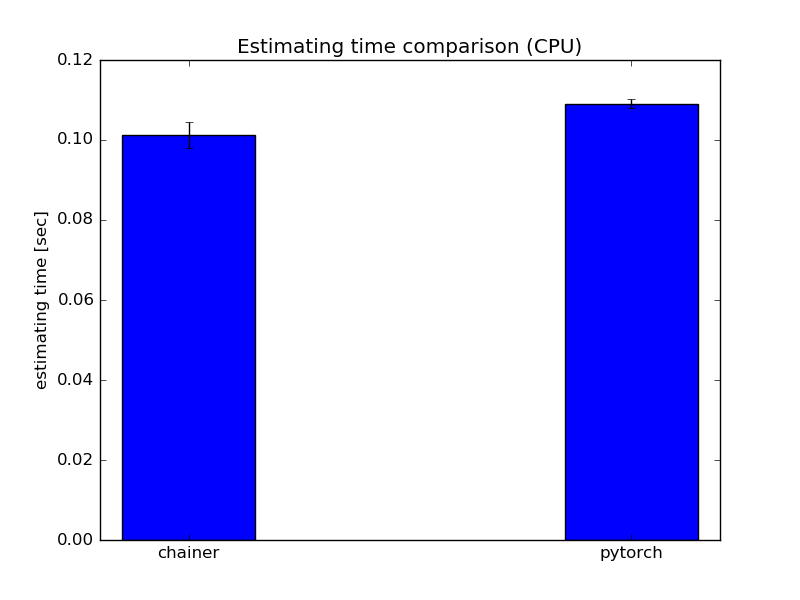
CPU環境とGPU環境でそれぞれ予測に要する時間を10,000回計測し,その平均を計算しました.環境は学習の時と同様です.
CPU環境
CPU環境では,ChainerとPyTorchの予測時間の平均はChainerの方がややはやいという結果になりました.
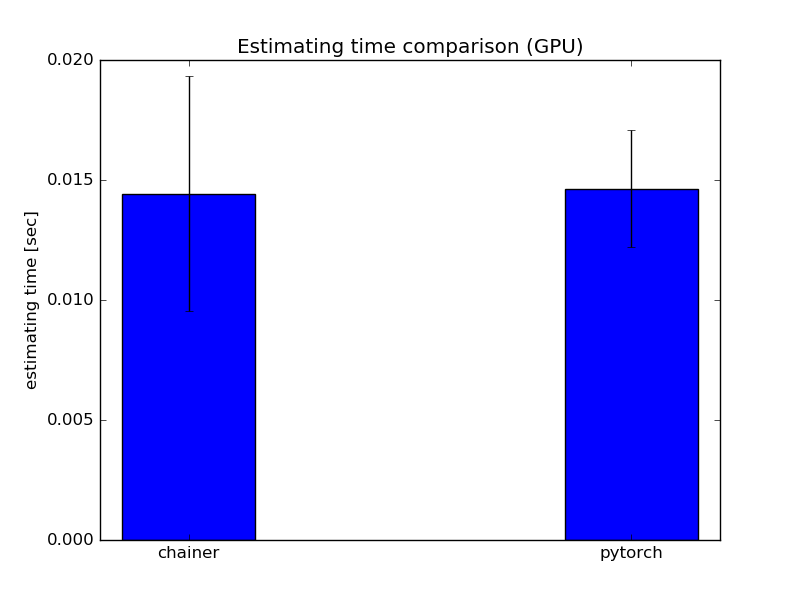
GPU環境
GPU環境では,ChainerとPyTorchの予測時間の平均はほぼ変わりませんでした.
まとめ
実装面でいえば,PyTorchはChainer同様に非常に書きやすかったです.PyTorchの方がややこなれていない感じはありましたが,今後に期待ができそうです.また,明示的に backward を実装しなくて良い点はメリットと言えそうです.
性能面でいえば,PyTorchはforward計算においてはChainerと同程度でしたが,学習速度はChainerよりも早いことは驚きでした.CPU環境ではむしろforward計算ではややPyTorchの方が遅いにも関わらず,学習では1.6倍の速度を得ていたことは面白いです.
backward を明示的に実装しないが学習ではPyTorchの方がはやいという結果から,PyTorchの方が自動微分に優れていると考えられます.次回は, backward を明示的に実装した場合に性能にどのような影響が出るか見てみたいと思います.
一応,コードはこちらにあります.よかったらPyTorch学習の際の参考にしてください.
追記
backward を明示的に実装した場合の性能影響を検証してみました.
PyTorchでDeepPoseを実装してみた PartⅡ
結論としては,backwardの実装差異はほぼ学習時間に影響を与えないことが分かりました.むしろ,学習時間へ支配的な影響を与えているのは,ネットワークの各層を計算するために要するConvolutionなどを,Pythonで実装しているか,Cで実装しているかの違いのようです.ただし,両ライブラリとも開発途中であり,バージョンによってはChainerの方がはやいこともあるようです.