2017/05追記
当記事の情報はすでに古くなっています。
新しい記事を投稿していますのでこれからTerraform for さくらのクラウドを利用される方はこちらを参照ください。
Terraform for さくらのクラウド スタートガイド(全5回)
こちらの記事は一応残しておきます。
連載目次
第1回:導入編
- 概要
- セットアップ
- 実践 Step1:サーバー1台構成
第2回:実践編
- 実践 Step2:構成/設定の変更
- リソースの追加
- リソースの変更
- count構文
- output機能
第3回:実践編2
- 実践 Step3:プロビジョニング
- プロビジョニング接続設定
- fileプロビジョニング
- remote-execプロビジョニング
- さくらのクラウドDNSリソースの利用
第4回:応用編
- 実践 Step4:Web/DB 2-Tier構成
- MySQLの利用
- スイッチによるプライベートネットワークの構築
- パケットフィルタ/シンプル管理:Slack通知の利用
第5回:応用編2(当記事)
- 実践 Step5:東京/石狩 マルチゾーン構成
- 東京と石狩でマルチゾーン構成
- GSLBによるゾーン間HA構成
- MySQL レプリケーション + PHP(mysqlnd_ms)によるDBのクラスタリング
-
null_resourceやtemplate_fileなどの特殊なリソース - tfファイルのリファクタリングとモジュール化
連載第5回です。
第1回から順番にお読みください。
実践 Step5:東京/石狩 マルチゾーン構成
前回の応用編で実運用ができる状態にだいぶ近づきました。
今回はさらに可用性を高める仕組みを導入し、
シンプル・安価ながら安定したサービス提供ができる環境を構築します。
前回(第4回)は以下のような構成でした。
第4回の構成
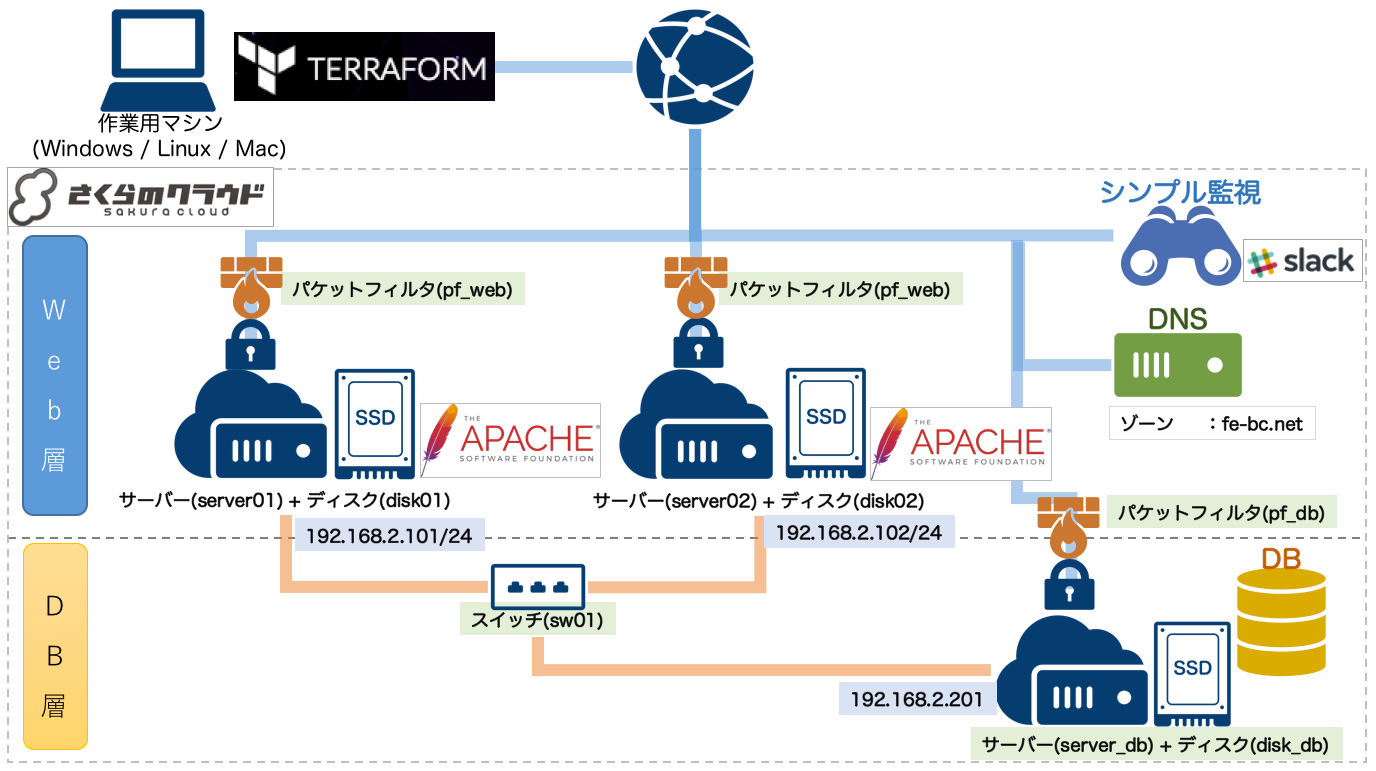
この構成に対し以下の対応を行います。
- 対応1:東京/石狩マルチゾーン化/ブリッジ接続
- 対応2:WebサーバーのロードバランシングにGSLBを利用
- 対応3:DBサーバーを冗長化、双方向レプリケーションを行う
これらの対応を行った後の構成は以下のようになります。
今回の構成
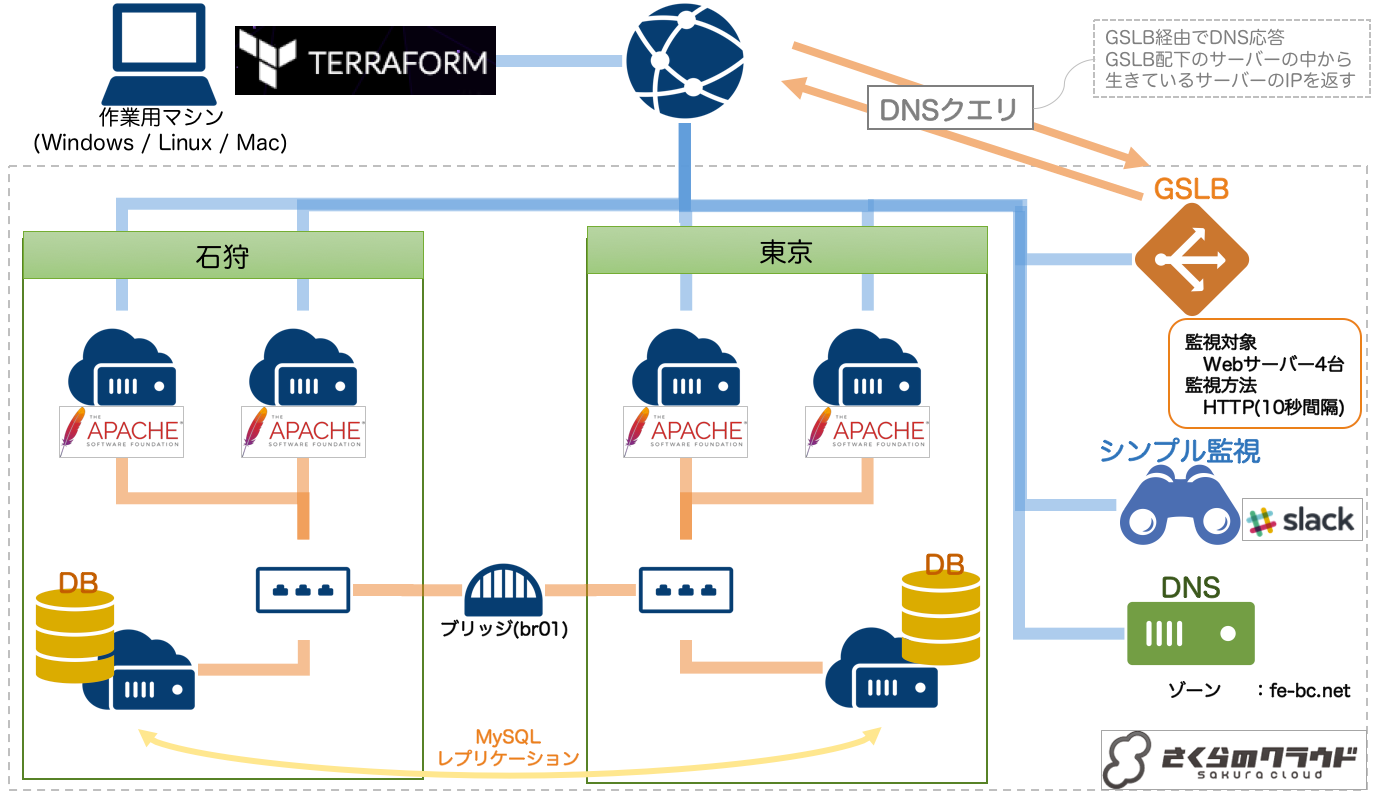
それぞれの対応をもう少し詳しく見ておきましょう。
対応1:東京/石狩マルチゾーン化/ブリッジ接続
これまでは石狩第1ゾーン(tfファイルでゾーンを明示しなかった場合のデフォルト)にのみサーバーを設置していましたが、東京にもサーバーを設置することでより効果的な負荷分散や地理的な災害対策が行えます。
しかもさくらのクラウドにはブリッジ接続というサービスがあります。
異なるリージョン・ゾーンにあるスイッチをL2で接続してくれるという便利なものです。
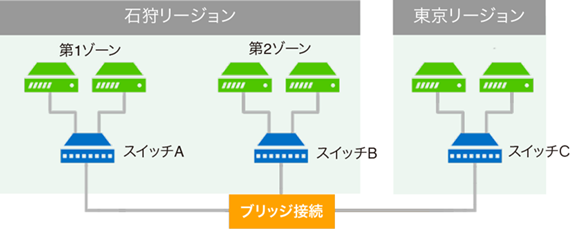
今回はこのブリッジ接続を用いて、各サーバーが東京/石狩をまたいで同一セグメントにいるかのような構成とします。
対応2:Webサーバのロードバランシング
WebサーバーのロードバランシングをDNSラウンドロビンからGSLBヘ変更します。
これまではさくらのクラウドDNSにWebサーバーのAレコードを台数分登録することでDNSラウンドロビンしていたのですが、
ダウンしているWebサーバーのレコードもDNS応答してしまうという問題がありました。
そこで、さくらのクラウドの提供するGSLB機能を利用します。
GSLBとは「Global Server Load Balancing」の略です。
ロードバランシングしたいFQDNの代理DNSサーバーとして動作してくれます。
配下のサーバーの死活監視(ping/http/https/tcp)を行い、生きているサーバーのDNSレコードを返すという動きです。
今回は東京/石狩の計4台のWebサーバーを配下に設定します。
対応3:DBサーバーを冗長化、双方向レプリケーションを行う
対応1により、ゾーン間をL2で結んだ状態となっています。
このネットワークを使い、DBサーバーを東京/石狩において双方向でMySQLレプリケーションを行います。
また、Webサーバー(PHPアプリ)からのDB接続にはmysqlnd_msを利用します。
まだまだ日本語情報が少ないですが、PHP側からは透過的に複数のMySQLサーバーを使えるというものです。
注意
稼働させるシステムによっては双方向レプリケーションがそぐわない場合もあります。
システム要件などよく確認の上で採用してください。
実践
前回の最終的な定義ファイル(tfファイル)はこちらです。
(長いのでgithubへのリンクとしています)
これを元に追加/変更していきます。
なお、今回は定義ファイル(tfファイル)について、変更内容やポイントだけ説明し、細部は省略します。
ここまで連載読んでいただいた方であれば十分に読み解いていけるとおもいます。
最終的な定義ファイル類はこちらに置きました。
今回のポイントは以下の通りです。
-
- 東京/石狩ゾーン指定方法
-
- ブリッジ接続方法
-
- GSLB利用方法
-
- MySQLレプリケーション対応
-
- モジュール(
module)でのtfファイルのリファクタリング
- モジュール(
順番に見ていきましょう。
1) 東京/石狩ゾーン指定方法
現在はtfファイルで明示していないため、すべてのリソースがデフォルトの石狩第1ゾーン(is1a)に置かれています。
これをリソースごとに設置するゾーンを明示してあげることで複数ゾーンへの設置ができるようになります。
ゾーンの指定方法
プロバイダ設定、またはリソース設定にて指定可能です。
両方を指定することも可能です。
設定する値は、ゾーンごとに以下の文字列です。
- 石狩第1ゾーン :
is1a - 石狩第2ゾーン :
is1b - 東京第1ゾーン :
tk1a - サンドボックス :
tk1v(注意:サンドボックスではプロビジョニングが動かせません)
プロバイダ設定で指定する場合
プロバイダ設定で指定する場合は以下のように記載します。
この場合、各リソースで上書きしない限り、ここで指定したゾーンに設置されるようになります。
provider "sakuracloud" {
token = "[ACCESS_TOKEN]"
secret = "[ACCESS_TOKEN_SECRET]"
#ゾーン指定
zone = "is1a"
}
各リソースで指定する場合
プロバイダ設定で指定する場合は以下のように記載します。
リソース設定にてゾーンが指定された場合はプロバイダ設定で指定したゾーンを上書きします。
resource "sakuracloud_switch" "sw01" {
name = "sw01"
#ゾーン指定
zone = "is1a"
}
なお、以下のリソースは「グローバルリソース」と呼ばれる、全ゾーンで共通のリソースです。
全ゾーンに跨るリソースのため、ゾーンの指定はできません。
- SSH鍵
- スタートアップスクリプト
- DNS
- GSLB
- シンプル監視
2) ブリッジ接続方法
今回の対応の目玉のひとつ、東京と石狩をL2で結んでくれるブリッジの使い方です。
非常に簡単なのでtfファイルを示します。
# Bridge
resource "sakuracloud_bridge" "br01" {
name = "br01"
}
# Switch(石狩)
resource "sakuracloud_switch" "sw01" {
name = "sw01"
zone = "is1a"
bridge_id = "${sakuracloud_bridge.br01.id}"
}
# Switch(東京)
resource "sakuracloud_switch" "sw02" {
name = "sw02"
zone = "tk1a"
bridge_id = "${sakuracloud_bridge.br01.id}"
}
ブリッジsakuracloud_bridgeリソースを定義し、各ゾーンのスイッチにbridge_idを設定すればOKです。
簡単ですね![]()
3) GSLB利用方法
GSLBはさくらのクラウドDNSとの合わせ技で設定します。
以下のような定義になります。
/****************************************
GSLB(合計4台を配下に登録)
*****************************************/
resource "sakuracloud_gslb" "gslb" {
name = "gslb01"
health_check = {
protocol = "http"
delay_loop = 10
host_header = "web.fe-bc.net"
path = "/index.php"
status = "200"
}
servers = {
ipaddress = "${element(split("," , module.is1a_web_servers.ip_addresses),0)}"
}
servers = {
ipaddress = "${element(split("," , module.is1a_web_servers.ip_addresses),1)}"
}
servers = {
ipaddress = "${element(split("," , module.tk1a_web_servers.ip_addresses),0)}"
}
servers = {
ipaddress = "${element(split("," , module.tk1a_web_servers.ip_addresses),1)}"
}
}
/****************************************
さくらのクラウドDNS
*****************************************/
resource "sakuracloud_dns" "dns" {
zone = "fe-bc.net"
records = {
name = "web"
type = "CNAME"
#GSLBのFQDNをweb.fe-bc.netのCNAMEとして登録
value = "${sakuracloud_gslb.gslb.FQDN}." #注:末尾にピリオドつける!!
}
}
GSLBのserversに監視したいサーバーの実IPアドレスを登録します。
今回はWebサーバー4台のグローバルIPを指定します。
また、DNSにCNAMEレコードを登録しています。
こうすることで、対象のFQDNへのDNSクエリがGSLBに対して行われるようになります。
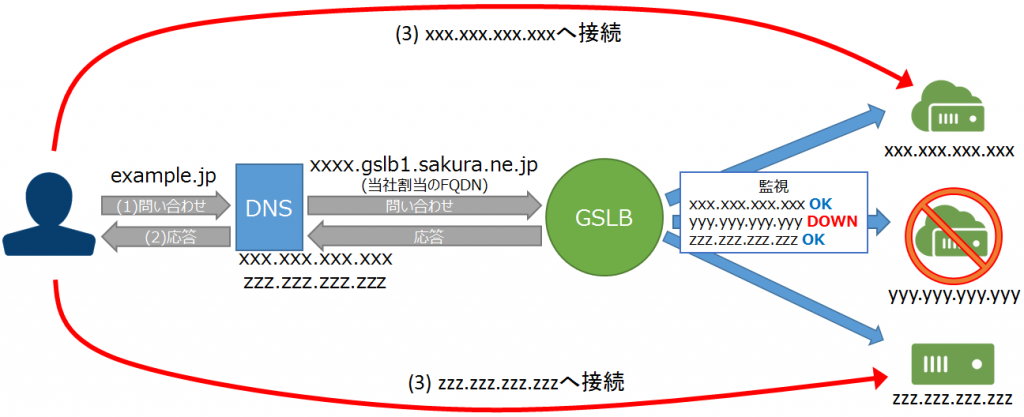
参考:DNSクエリの流れ
- クライアントがDNSサーバーへ
web.fe-bc.netのIPアドレス問い合わせ - DNSサーバーがCNAMEレコード(GSLBのFQDN)を返却
- クライアントがDNSサーバーヘGSLBのFQDNのIPアドレス問い合わせ
- GSLBは死活監視を行っている配下のサーバーから生きているサーバーのIPアドレスを返す
4) MySQLレプリケーション対応
今回の本筋とはあまり関係ありませんのでさらっと流します。
やっていることは以下の通りです。
- レプリケーションを有効にしたmy.cnfをあらかじめ作成しておく
- mysqlnd_ms用の設定ファイルをあらかじめ作成しておく
- 設定ファイル類をfileプロビジョニングでアップロード
- 必要なライブラリはremote-execプロビジョニング時にyumでインストール
今回は簡単なデモ用Webアプリからの利用しかしていないですが、
wordpressなどの本格的なWebアプリでも十分利用出来る構成です。
各リソースの定義を見れば大体読み解けると思いますが、以下の2点がポイントです。
- 1: レプリケーションの開始を制御するため
null_resourceを利用 - 2: プロビジョニングのコマンドの組み立てに
template_fileを利用
いづれもTerraformに組み込みのリソースで、tfファイルの制御に用いるものとなっています。
それぞれ見ていきましょう。
null_resourceについて
null_resourceとは、その名の通り実体を持たないリソースで、
複数のリソースに依存したリソースを定義するために利用します。
例えば、以下のようなnull_resourceを定義した場合、
サーバーAとサーバーBの作成が完了してからnull_resourceのプロビジョニングを実行するという
タイミングの制御のようなことができます。
resource sakuracloud_server "serverA"{
# (省略)
}
resource sakuracloud_server "serverB"{
# (省略)
}
resource "null_resource" "db_replication" {
triggers{
# 依存を定義
server_ids = "${sakuracloud_server.serverA.id},${sakuracloud_server.serverB.id}"
}
# MySQLレプリケーション開始
provisioner "remote-exec" {
connection {
user = "root"
host = "${var.server01_ip}"
private_key = "${file("${path.root}/${var.ssh_keyfile}")}"
}
inline = [
"cat << EOF | mysql -u root --password='${var.mysql_root_password}'\n${template_file.start_replication_sql01.rendered}\nEOF\n"
]
}
}
今回はMySQLレプリケーションの開始をこのnull_resourceを使うことで、
2台のMySQLサーバーの構築が終わってからCHANGE MASTERやSTART SLAVEといった
SQLを実行するようにタイミング調整しています。
template_fileについて
今回プロビジョニング時に実行するコマンドを組み立てるのにtemplate_fileというリソースを使いました。
これは、その名の通りテンプレート機能を提供するもので、以下のように利用します。
resource "template_file" "sample01" {
template = "${file(./sample.txt)}"
vars {
target_name = "hoge"
}
}
resource "template_file" "sample02" {
template = "${file(./sample.txt)}"
vars {
target_name = "fuga"
}
}
echo "Hello ${target_name}!"
このテンプレートを使う側は以下のようになります。
# プロビジョニング
provisioner "remote-exec" {
inline = [
"${template_file.sample01.rendered}"
"${template_file.sample02.rendered}"
]
}
${template_file.[リソースのID].rendered}とすればテンプレート内の
変数を展開した文字列を参照できます。
今回はmy.cnfの組み立てやCHANGE MASTERSQL文の組み立てに利用しています。
5) モジュール(module)でのtfファイルのリファクタリング
今回の構成では石狩/東京ゾーンに同じ構成のリソース(サーバー、ディスク、パケットフィルタなど)が必要になります。
tfファイルの該当部分をコピペしてもいいのですが、Terraformにはリソース定義を共通化できるmoduleという仕組みがあります。
今回はこれを使ってtfファイルをリファクタリングしています。
moduleについて
Terraformにはmoduleという仕組みがあります。
リソースの定義をひとまとめにしておいて、再利用するための仕組みです。
このmoduleのポイントは外部から変数を受け取れるということです。
簡単なmoduleの例を見てみましょう。
"./modules/sample_module"というディレクトリ配下に以下のファイルを作成します。
variable "disk_name" {
default = "diskname"
}
resource "sakuracloud_disk" "disk" {
name = "${var.disk_name}"
size = 100
source_archive_name = "Ubuntu 16.04 LTS 64bit"
}
通常のtfファイルですね。サイズが100GB、ソースとしてUbuntuを使うディスクの定義です。
variableもこれまで出てきたものと同様です。
今度はmoduleを利用する側のtfファイルを見てみましょう。
以下のようになります。
module "sample_disk01" {
source = "./modules/sample_module"
disk_name = "test01"
}
module "sample_disk02" {
source = "./modules/sample_module"
disk_name = "test02"
}
なんとなく読み取れると思いますが、sourceでモジュールの在り処を指定し、
モジュール側で定義された variableを指定するという形で利用します。
こうしておけば一つの定義を再利用できますね!!
なお、今回はモジュールの在り処として"./modules/sample_module"のようにローカルファイルパスを指定しましたが、他にも以下のようなものが指定できます。
- ローカルファイルパス
- GitHubのURL
- BitBucketのURL
- GitやMercurialのリポジトリ
- HTTP URLs
モジュールを使う場合の注意点としては、terraform planなどの実行の前に
あらかじめterraform getというコマンドを実行する必要があるということです。
(未実行の場合はその旨警告が表示されます)
ローカルファイルパスの場合でもterraform getの実行は必要ですので忘れずに実行しましょう。
実行
さて、今回も盛りだくさんです。
今回の最終的なtfファイル類はこちらにありますので、実行する場合はこちらを参考に必要なtfファイル類を準備してください。
さて、準備できたらterraform planとterraform applyするだけです。
(terraform getしていない場合は実行してから!!)
、、、出来ましたよね?
今回リソースが多いですので多少時間がかかると思います。気長に待ちましょう。
確認
GSLBの確認として各Webサーバーを落としてみたり、
DBの確認としてDBサーバーを落としてみたりしてみてください。
Webサーバー/DBサーバーともにいずれかがダウンしてもサービス継続できていますよね?
あまりデータ更新頻度の高くない参照中心のシステムであれば十分に実用に耐える可用性を持っています。
あとはシステムごとの性能要件に合わせてチューニングしたりサーバースペックを調整したり、
Webサーバーをスケールアウトさせてみたりしてみてください。
まとめ
ここまで全5回にわたって「Terraform for さくらのクラウド」でインフラ構築を行ってきました。
tfファイル = Code を中心としたインフラ構築、いわゆる「Infrastructure as code」の世界を
多少覗けましたでしょうか?
コード化することにより、インフラが「可視化」されただけでなく、これまでDevs特有のテクニックであった
バージョン管理やリファクタリングなどが使えるようになること、さらに「テスト〜コーディング〜レビュー〜デプロイ」というフローが作れることや、そのフローを自動化(例えばGithub + TravisCI)するなんてことも出来るようになりますね!
さくらのクラウドでは、イベントなどで配布されている2万円クーポンを活用すれば
10台を超える大量の分散サーバーを試す、なんてことも完全無料で出来ちゃいます。
これからTerraformを触ってみようとしている方は
Terraform for さくらのクラウドではじめの一歩を踏み出してみてはいかがでしょうか?
あとがき
もし分からないところ、読み解けないところがあればTwitterなどで(@yamamoto-febc)あてに
お気軽に質問ください。
ここまでお読みくださりありがとうございました。
以上です。