Pepperが周囲にあるものを見て、そこから何か動作を変えることができると、Pepperがより「空気を読んだ」振る舞いをできるようになるんでないかと思っているわけですが、どうも組み込みの画像認識モジュールは使い勝手がよくなく、うーんと思っていました。
そう思っていた矢先に、Cloud Vision APIの凄さを伝えるべくRasPi botとビデオを作った話を読みました。うへえ何それすごいと思って Cloud Vision APIのLimited Previewに申し込んでPepperに組み込んで遊んでみていました。(2016/2/19 Betaになりました・・・!)
今回は個人的にCloud Visionで遊ぶために作っているボックスを、簡単なものですがアップしましたのでそのネタを。
Pepperと画像認識
Pepperは標準で顔認識と、(顔以外の)画像認識用のモジュールを持っています。
コミュニケーションのためのロボットという名目もあり、搭載されている顔認識エンジンは非常に強力で、性別認識、年齢認識など申し分ないと個人的に思っています。ドキュメント中には顔認識はオムロンのものを使っていると言及があるので、OKAO Visionなんだと思いますが。
一方で画像認識については、ちょっと実用には向かないかな、という感じを持っています。
というのも、Pepperチュートリアル (7):画像認識#画像の学習のようにして対象の物体(カメラで撮影した画像の領域)を指示して学習させてあげるわけですが、当然物体をどの角度から撮影するかにより撮影画像は変化しますし、照明などの撮影時の環境にも依存しますから、実用にはそれなりの量の学習用データが必要になりそうです。
Cloud Vision用ボックス
そんな問題意識があったので、すでにGoogleが大量のデータで学習済みの画像分析処理がCloud Vision API経由で簡単に使えるようになるとなれば、これは試すしかないなと。さっそく、Choregraphe上で、Cloud Vision APIをボックスとして簡単に利用できるようにしてみました。
ボックスの場所
Cloud Vision API用ボックスはこれまで作ってきたボックスライブラリに追加しています。
PepperのALMemoryとMQTTを相互接続するボックスを作った話#ボックスライブラリの読み込み を参考にインポートしてください。
ボックス仕様
Google > Cloud Visionに以下の3つのボックスがあります。今回はCloud Vision APIのすべてのFeatureを実装してはおらず、とりあえず自分が使ってみているものだけを公開しています。
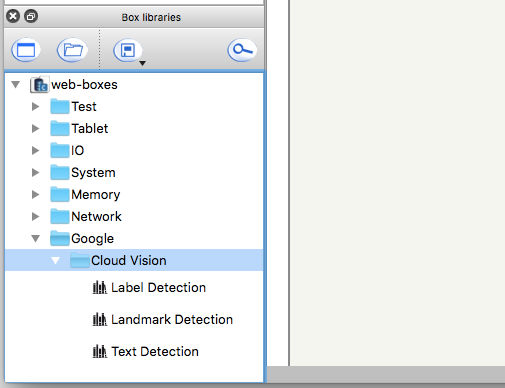
Label Detectionボックス
Cloud Vision APIのLABEL_DETECTION機能を利用するためのボックスです。
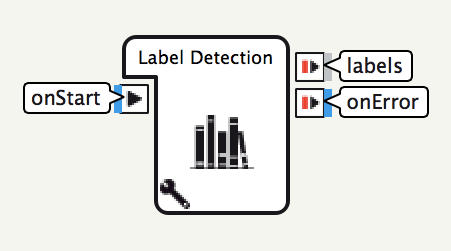
設定可能なパラメータ
LABEL_DETECTIONボックスには以下のパラメータが指定できます。LANDMARK_DETECTIONボックス, TEXT_DETECTIONボックスも同様の設定を持ちます。
- Endpoint: Cloud Vision APIのエンドポイントのURLを指定します。Cloud Vision APIのバージョンアップなどがない限りは変更する必要はありません。
{api_key}はAPI Keyパラメータで自動的に置換されます - API Key: Cloud Vision APIを利用可能なAPIキーを指定します
- Max Results: Cloud Vision APIが返す項目数の最大値を指定します
実行にはAPI Keyを指定する必要があります。詳しくは使い方の手順で詳しく説明します。
onStart入力
onStart入力には、Pepper内にある、解析させたい画像ファイルの絶対パスを与えます。
例えばTake Pictureボックスの場合、デフォルトでは /home/nao/recordings/cameras/image.jpg に画像が保存されますので、これを文字列として与えます。
labels出力
labels出力には、以下のようなリストが出力されます。
[[候補1のスコア, 候補1の名前], [候補2のスコア, 候補2の名前], ...]
スコアは0.0~1.0の間の数値として表現されます。名前は文字列で表現されます。
onError出力
ボックスの実行時にエラーが発生した際に、エラー内容を示す文字列が出力されます。
Cloud Vision APIへのリクエストに失敗した場合はonErrorが出力されます。
Landmark Detection
Cloud Vision APIのLANDMARK_DETECTION機能を利用するためのボックスです。
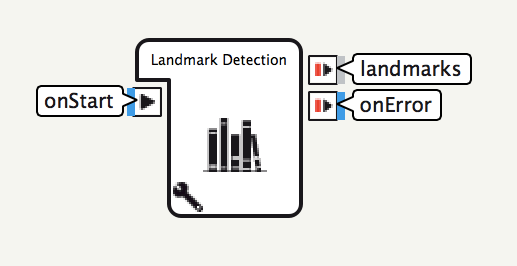
設定可能なパラメータおよびonStart入力, onError出力は、Label Detectionボックスと同様です。
landmarks出力
landmarks出力には、以下のようなリストが出力されます。
[[候補1のスコア, 候補1の名前, [候補1の緯度, 候補1の経度]],
[候補2のスコア, 候補2の名前, [候補1の緯度, 候補1の経度]], ...]
緯度の値は-90.0~+90.0、経度の値は-180.0~+180.0で表現されます。
Text Detection
Cloud Vision APIのTEXT_DETECTION機能を利用するためのボックスです。
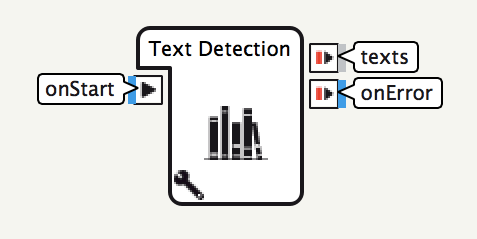
設定可能なパラメータ
TEXT_DETECTIONにはLABEL_DETECTIONなどで利用可能なパラメータに加え、言語指定に関するパラメータを指定することが可能です。
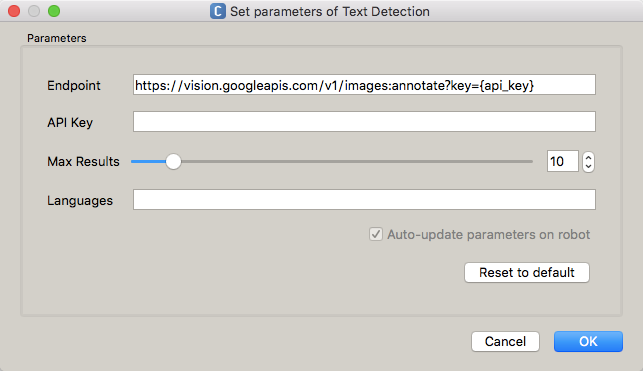
Languagesには、認識結果として期待する言語を、 https://cloud.google.com/translate/v2/using_rest#language-params の言語コードとしてスペース区切りで指定します。
この指定が空である場合、言語は自動的に検出されます。
texts出力
texts出力には、以下のようなリストが出力されます。
[[結果1の言語, 結果1の内容], [結果2の言語, 結果2の内容], ...]
内容の文字列が複数行の場合、改行位置に\nが付加されます。
使い方
これらCloud Vision APIボックスは、以下のように利用します。
-
Cloud Vision APIの有効化とAPI Keyの準備
Cloud Vision APIのドキュメントのうち、Getting Startedを見ながら、Setting Up an API Keyまで進めます。
これで、自分のプロジェクトでCloud Vision APIが使えるようになります。 -
ビヘイビアの作成
Cloud Vision API用ボックスを使って、Choregrapheでビヘイビアを作成します。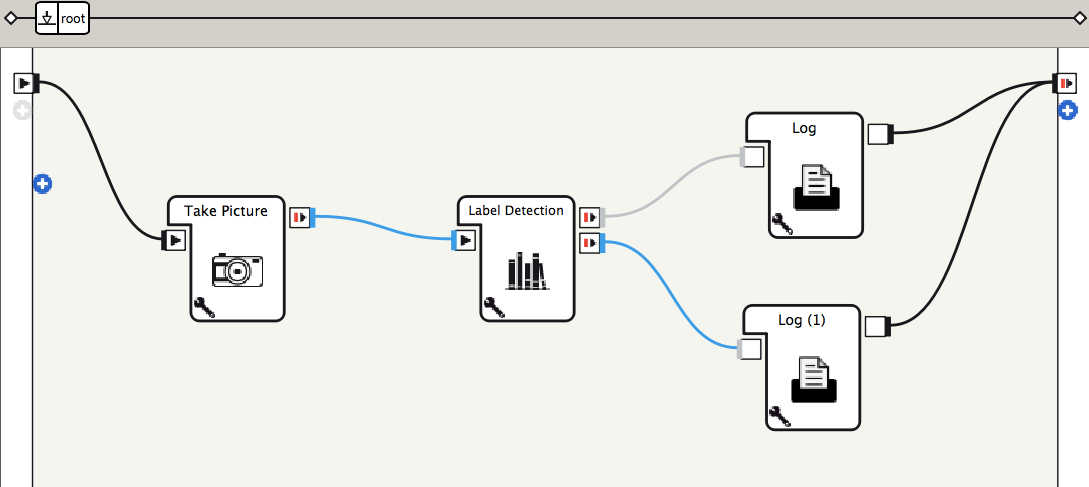
Pepperのカメラからの画像取得は、標準ボックスライブラリの Sensing > Vision > Camera Actions > Take Pictureボックスを改修して使用しています。詳しくはTake Pictureボックスの改修で説明します。 -
Cloud Vision APIボックスにAPI Keyを指定
ボックスにAPI Keyを設定します。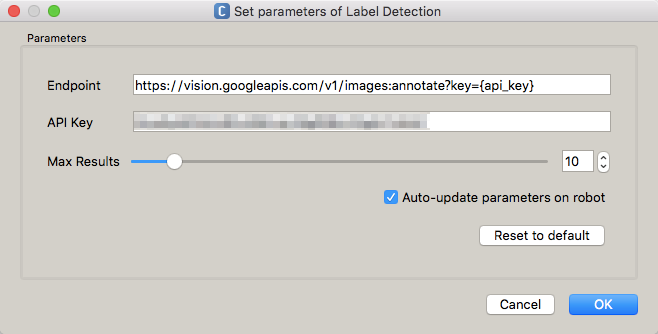
なお、ボックスにAPI Keyを指定するのはちょっと悩ましいなあと考え中・・・うっかりビヘイビアを公開してしまうとAPI Keyを不正に使われるおそれもありますしね・・・Preferencesに持たせるほうがよいのかもしれない。
これだけでPepperのカメラで撮影された画像をCloud Vision APIで処理してログに出力することができます。どんな出力がされるかは ボックスの出力例 で説明します。
Take Pictureボックスの改修
Choregraphe標準のTake PictureボックスはALPhotoCapture APIにアクセスを簡単におこなえるボックスですが、書き込み先が /home/nao/recording/cameras としてハードコーディングされています。
Take Pictureボックスの設定がデフォルトのままであれば、Take PictureボックスとLabel Detectionボックスの接続は以下のようにしてもOKです。

ただ、最近のアプリのガイドラインに従おうとするとホームディレクトリ以下に勝手にディレクトリを作るのではなく、User Writable Data PathをAPIに問い合わせて使えということにもなりそうな気がしていて、あんまり定数としてこの手のパスを含めたくないと思うのが人情です。
そこで、今回の例ではこんな感じにしています。
-
Take Pictureボックスの出力をString(文字列)に変更する
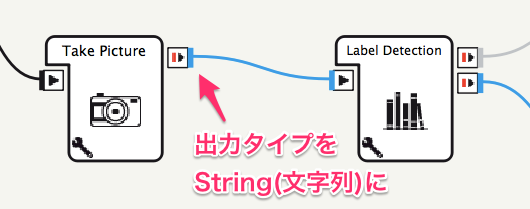
-
Take PictureボックスのPythonスクリプトを修正する
if self.photoCapture: self.photoCapture.setResolution(resolution) self.photoCapture.setCameraID(cameraID) self.photoCapture.setPictureFormat("jpg") # savedPath = を追加 savedPath = self.photoCapture.takePicture( self.recordFolder, fileName ) self.bIsRunning = False # onStopped呼び出し時に引数を追加 self.onStopped(savedPath[0])
バーチャルロボットなどではsavedPath変数が未定義になるのでエラーとなるわけですが、そもそも先行してALPhotoCapture APIが見つからないと怒られているはずなのでいいでしょうということで。
なお、Take Pictureボックスで、ALPhotoCapture.takePictureを何度か呼び出していると、takePictureメソッドから制御が戻ってこないケースがあるようです。この現象が起きるのは、今のところオートノマスライフをオンにしているときのみで、オートノマスライフをオフにしておくと起きないように見えます。ALVideoDeviceのsubscribeでブロックされる現象は以前も遭遇したことがあったので、もしかしたらオートノマスライフ時にアプリ間で競合状態などが生じているのかも、と想像しています。
ボックスの出力例
このボックスを使っていくつか画像を認識させてみました。
Label Detectionボックス
いくつかPepperに物を見せて、Label Detectionボックスの出力を見てみました。
例えばコート。

こんな感じの出力が返ってきました。
[[0.98875492811203, 'clothing'],
[0.8403595685958862, 'room'],
[0.797779381275177, 'dress']]
「衣類」がスコア0.98となりよい感じです。ドアや壁からの推測なのか「部屋」としているのも面白い感じです。
次にビデオカメラ。

[[0.5420256853103638, 'cameras & optics'],
[0.5059739351272583, 'wall']]
スコアは低めですが、間違ってはいない感じです。いろいろなものが映り込んでいるので、ちょっと自信がなくなるのかもしれません。
次、椅子。

[[0.9610474705696106, 'chair'],
[0.9104857444763184, 'furniture'],
[0.5046526193618774, 'couch']]
何も考えず三脚も一緒に見せてしまいましたが、椅子のほうに反応してくれたよう。
いろいろ見せてみると、なるほどと思う結果を返してくれます。これらの認識結果に基づいて、話題を選択できたりすると面白いかもしれません。
Landmark Detectionボックス
Landmark Detectionボックスの実験。Pepperを外に連れ出すのはなかなかむつかしいので、旅行ガイドブックを見せてみました。

[[0.2688983678817749, 'Itsukushima', [34.31437683105469, 132.43777465820312]],
[0.2660306990146637, 'Itsukushima Shrine', [34.296932220458984, 132.31935119628906]]]
文字など風景以外の要素がかなり入っている気がするので判定してくれないかと思いましたが、スコアが低めではありますが厳島神社と判定してくれました。おもしろい。
Text Detectionボックス
Text DetectionボックスでOCR機能も試してみます。作業場にあったものを見せてみました。

こんな出力結果。
[['ja',
"ELECOM
日々のお掃除に
サッ!とひと拭き
お得用
1,日
ウエットクリーニングティッシュ
パソコンやデスクまわりに
600090
ぜ
アルカリ
SO
電澥イオン水
AL 150"]]
いくつか試してみましたが、かなり検出能力高いなあという感じです。
円形のアイコンの並びを数字だと思ってしまうのはちょっと悩ましい感じですが、「お徳用」みたいなフォントもある程度認識してくれるようなので、面白そうです。手書きの認識とかも試してみたいですねー
まとめ
こんな感じで、Pepperの認識機能の一部をGoogle Cloud Platformにお願いしてみるということを試してみています。
PepperのロードアベレージなどをPepperのログや稼働情報をFluentd経由でBigQueryに突っ込んでみる以来測り続けているわけですが、PepperのCPUは思いのほか忙しくしているようですし、クラウドサービスに移譲できる部分は移譲して・・・ということができると幸せになれるかもしれません。
あと、いろいろ画像を認識させていて、焼きそばの画像に対してCloud Visionが yakisoba と yi mein という2つの認識結果を返したのが面白かった。自分自身はyi meinを知らなかったので焼きそばの画像からyi meinを想起することはないわけですが、Cloud Vision APIはyi meinを知ってしまっているわけです・・・
人間の個体よりもCloud Visionのほうがずっと多くのものを見ているようなので、ここで得られた認識結果をコミュニケーションに使うためには、相手の人間の文脈に合わせてフィルタなどしてあげる必要があるのかなと。いろいろ工夫しどころがありそうで面白そうですねー・・・!