このチュートリアルの内容
このチュートリアルでは、Pepperによる画像認識について、その仕様や挙動を、サンプルを通じて説明します。
- 画像関係の仕様
- Choregrapheによる画像の確認方法
- 基本的な顔の処理
- 顔の学習と判別
- 画像の学習と判別
なお、 画像認識についてはバーチャルロボットでは動作確認手段はなく、Pepper実機が必要になります。 アルデバラン・アトリエ秋葉原などでPepper実機を使って実験などおこなってみていただければと思います。 (予約URL:http://pepper.doorkeeper.jp/events)
各種センサー仕様
Pepperの画像処理にかかわる仕様としては、以下のようなものがあります。
- 2Dカメラ×2 (額 [A], 口 [B]) ... 出力1920×1080, 15fps
- 3Dカメラ (赤外線照射: [C], 赤外線検出: [D]) ... ASUS Xtion 3Dセンサー, 出力320×240, 20fps
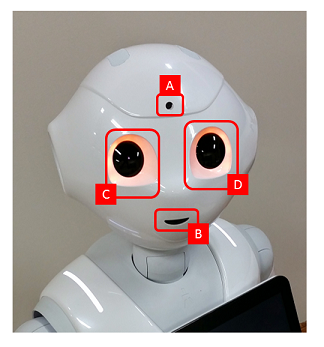
Pepperはこれらのカメラを利用して人や物体の認識をおこないます。
Choregrapheによる画像の確認方法
Pepperのカメラによる画像の情報はChoregrapheで確認することができます。
ビデオモニターパネルによる確認
Pepperの画像にかかわる操作には、ビデオモニターパネルを利用します。
ビデオモニターパネルは通常ポーズ ライブラリと同じ領域に配置されており、[ビデオモニター]タブを選択することで確認できます。見つからない場合は[表示]メニューから[ビデオモニター]を選択してください。

ビデオモニターパネルは、Pepperのカメラによる画像を確認する機能のほか、後述する視覚認識データベースの管理機能を提供します。
- カメラ画像 ... Pepperのカメラの内容を確認できます
- 再生/一時停止ボタン ... 再生すると、現在のカメラ画像をリアルタイムに確認できます。一時停止でこれを停止することができます
- 学習モードボタン ... 画像の学習モードに切り替えます。使用方法は 画像の学習 チュートリアルで説明します
- インポートボタン ... 視覚認識データベースをローカルファイルからChoregrapheにインポートします
- エクスポートボタン ... 視覚認識データベースをChoregrapheからローカルファイルへとエクスポートします
- 消去ボタン ... 現在の視覚認識データベースを消去します
- 送信ボタン ... 現在のChoregrapheに保持されている視覚認識データベースをPepperに送信します
Monitorによる確認
Choregrapheとあわせてインストールされる Monitor アプリケーションを使うこともできます。
Monitorアプリケーションは以下のように起動します。
-
Choregrapheと一緒にインストールされる Monitor アプリケーションを起動します。
-
Monitorアプリケーションの起動メニューで Camera をクリックします
-
接続先のPepperを問い合わせるダイアログが開くので、自分が利用しているPepperを選択します
-
Monitorのウィンドウが開くので、 再生ボタン をクリックします
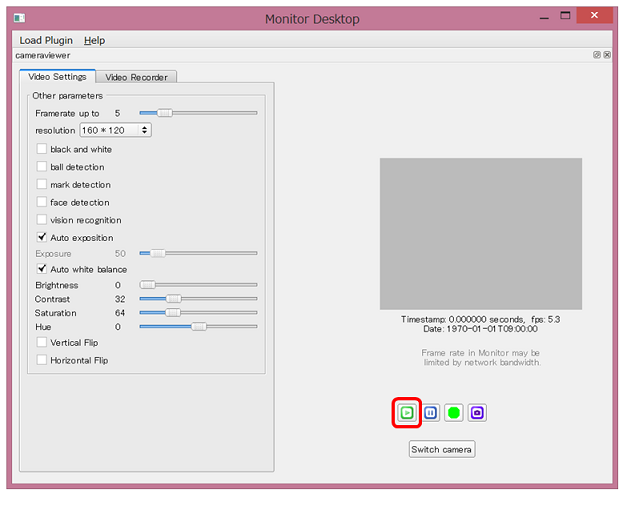
-
Pepperのカメラによる画像を確認することができます
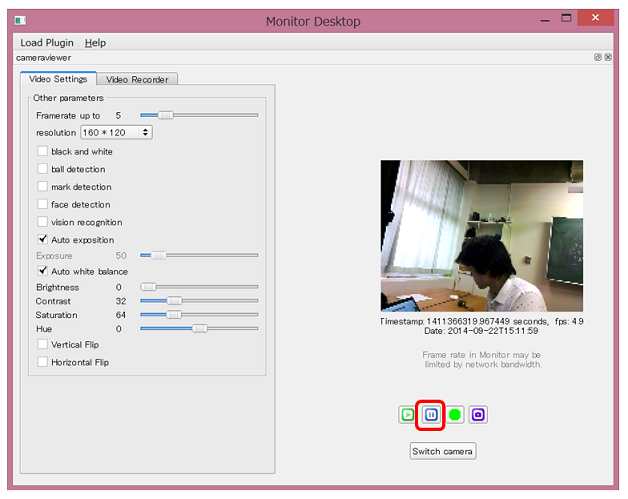
一時停止ボタン で再生を停止することができます -
画像以外にも、画像認識関係の情報を確認することができます。face detectionをチェック [A] することで、Pepperの顔認識の状況を確認 [B] することができます
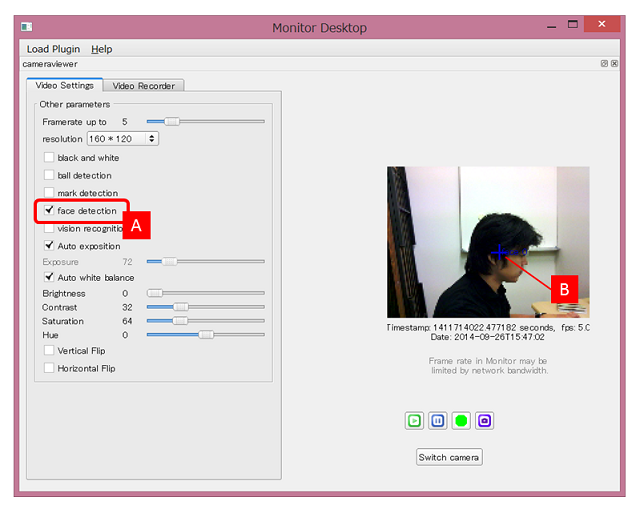
-
3Dカメラの内容を確認したい場合は、 [Load Plugin]メニューの[3dsensormonitor]を選択 します
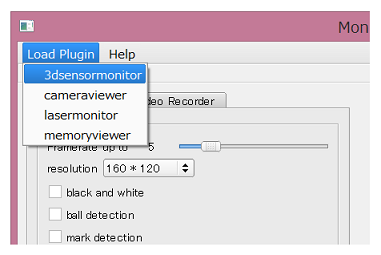
-
2Dカメラと同じ要領で、再生ボタン をクリックすると、デプスマップを確認することができます
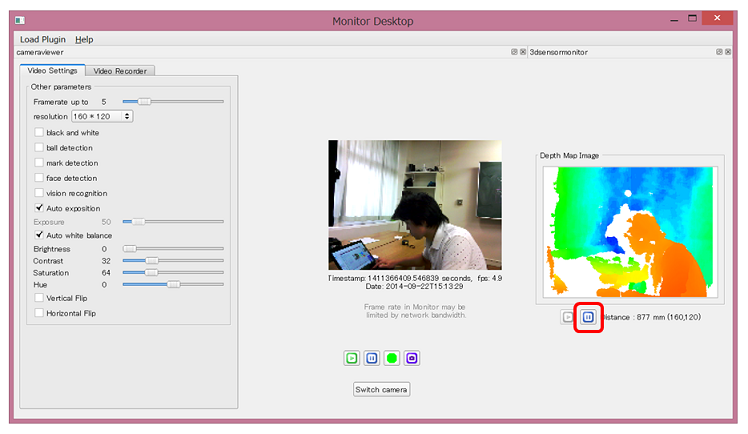
一時停止ボタン で再生を停止することができます
このMonitorアプリケーションによって、Pepperの認識している画像の内容を詳細に確認していくことができます。
基本的な顔認識
顔認識
標準ボックスとして提供されているFace Detectionボックスを利用することで、現在Pepperが認識している顔の数を取得することができます。ここでは、これまで何度か使用したSay Textボックスを組み合わせて、Pepperが認識している顔の数をしゃべらせてみる ことをやってみます。
つくってみる
-
利用するボックスの準備
- standardボックスライブラリ
- Vision > Face Detection ... 顔検出をおこない、検出した顔の数を出力する
- advancedボックスライブラリ ... ボックスライブラリの[advanced]タブを選択
- Audio > Voice > Say Text ... 入力された文字列をしゃべる
- standardボックスライブラリ
-
ボックスをつなぐ
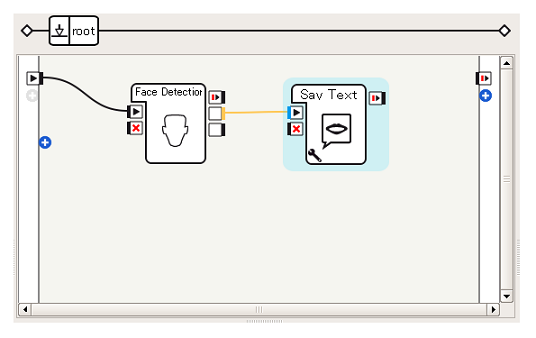
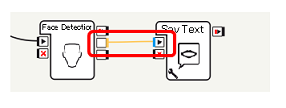
Face DetectionボックスのnumberOfFaces(オレンジ, タイプ:数)を、Say TextボックスのonStart(青, タイプ:文字列)を接続することで、Face Detectionボックスが出力するnumberOfFacesの値をPepperにしゃべらせることができます。
これでアプリケーションは完成です。顔を認識するとFace DetectionボックスがnumberOfFacesを出力するので、この出力を受けてPepperがしゃべります。
動作確認
Pepperに接続し、再生してみてください。
Pepperに顔を見せると、Pepperは「いち」「に」のように、視界に入っている顔の数をしゃべります。
なお、ロボットビューでは、Pepperが認識している顔の位置なども知ることができます。
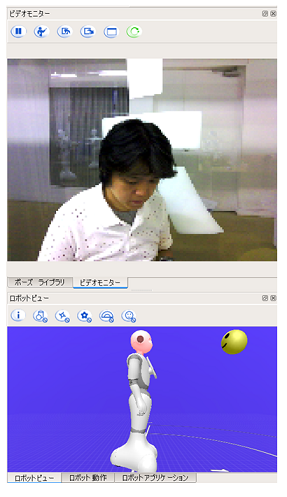
たとえば上のように、Pepperが顔を認識している状態では、ロボットビュー中に顔マークがあらわれます。これは、Pepperが認識している顔の位置を示しています。
(補足)Say Textボックスのカスタマイズ
今回のサンプルは「いち」「に」など数字を言うだけの単純なものです。Face Detectionボックスの動きを確認するには十分ですが、なにをしているのかわかりにくいアプリケーションになってしまっています。
ここでは例として、検出された顔の数が 1 ならば、「私の前に人が1人います」としゃべる ように変更してみましょう。
Say TextボックスはPythonボックスであり、しゃべりに関するAPI ALTextToSpeech API を利用しています。Say TextボックスからALTextToSpeechに渡す文字列を操作することができれば、しゃべる内容を変えることができます。
今回はSay Textボックス内で文字列の操作をおこなってみることにします。
Say TextボックスをダブルクリックするとPythonコードが開きますので、このコード中の onInput_onStart(self, p) 関数を探してください。以下のような行があることがわかります。
sentence = "\RSPD="+ str( self.getParameter("Speed (%)") ) + "\ "
sentence += "\VCT="+ str( self.getParameter("Voice shaping (%)") ) + "\ "
sentence += str(p)
sentence += "\RST\ "
id = self.tts.post.say(str(sentence))
self.ids.append(id)
self.tts.wait(id, 0)
pにはSay Textボックスに入力された値が格納されており、 sentence += str(p) のところでALTextToSpeech APIに与える文字列を組み立てています。
そのため、この部分を sentence += "ぼくの前に人が" + str(p) + "人います" などと変更すると、「いち」ではなく、「ぼくのまえにひとがひとりいます」(「1人」は「ひとり」と話します)としゃべるようになります。
顔追跡
音声と同様 に、Pepperに顔のある方向を追跡させることが可能です。
音声の例では、首の角度のみを移動していましたが、ここでは、Face Trackerボックスを使って、顔のある方向に向かって進む ということをやってみます。
つくってみる
-
利用するボックスの準備(standardボックスライブラリ)
- Trackers > Face Tracker ... 顔の追跡をおこなう
-
ボックスをつなぐ
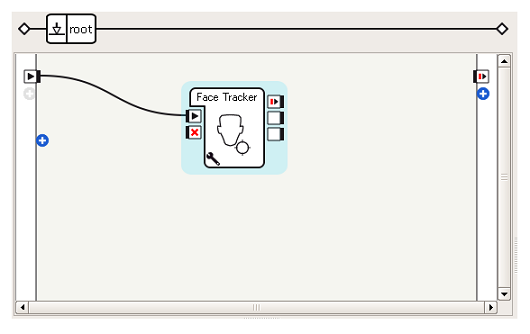
Face Trackerボックスを開始するだけで顔追跡をおこなうことができます。
-
パラメータを設定する
Face TrackerのパラメータのMode変数を Move に設定します。
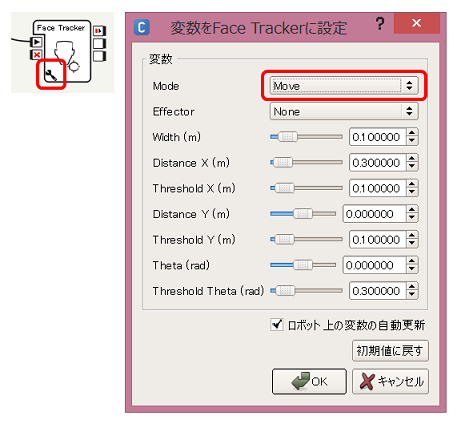
これでアプリケーションは完成です。Face Trackerボックスに、「顔を識別し、その方向へ向けて移動する」という大きな機能が実装されているので、フローとしてはこのような単純なもので実現することが可能です。
動作確認
Pepperに接続し、再生してみてください。
人間が近くにいるときは、首を曲げることで認識した顔を追跡しようとしますが、顔を向けたまま徐々に離れていくと、顔の方向に向かってPepperが移動します。
なお、有線でPepperに接続している場合は、予期しない方向に移動していかないように注意してください。
慣れないうちは、Pepperから凝視されながら追いかけられる感じで少し怖いですが、そのうち上目づかいがかわいいと思えてくる、かもしれません・・・!
顔の学習と判別
先の例では、ただ単純に「顔」を数えたり、追いかけたりしてみました。
ここでは、誰の顔なのかを覚えさせる 学習 についてみてみます。
顔の学習
Learn Faceボックスを利用することで、Pepperに顔と学習させることができます。
ここでは、 再生後5秒後にPepperが見た顔を「たろう」という名称で記憶させる ことをやってみます。
つくってみる
-
利用するボックスの準備(standardボックスライブラリ)
- Data Edit > Text Edit ... 任意の文字列を出力する
- Vision > Learn Face ... 顔と名称の対応を記憶する
-
ボックスをつなぐ
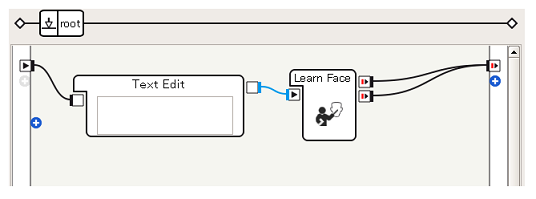
-
文字列を設定する
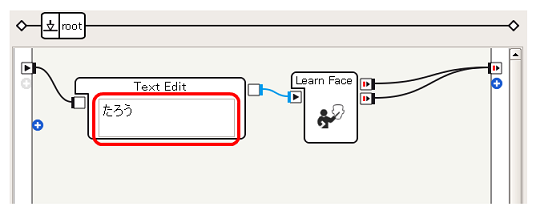
これで、Learn Faceによって、Pepperの見た顔が「たろう」として学習されるようなアプリケーションを実現することができます。
動作確認
Pepperに接続し再生後、Pepperのカメラの範囲内に顔が入るようにします。再生後5秒後、正常に顔が学習できた場合はPepperの目が緑色 に、失敗した場合は赤色 になります。
なお、 Unlearn All Facesボックス を実行することで、学習した顔データを消去することができます。
####
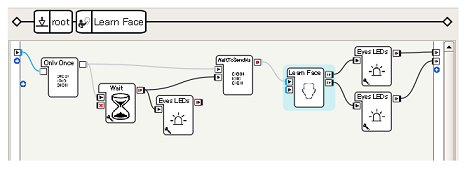
[参考]Learn Faceの中身
Learn Faceボックスの「5秒待つ」や「目が緑色に点灯」などはどのように実現しているのか、Learn Faceボックスをダブルクリックするとわかります。
Learn Faceボックスはフローダイアグラムボックスであり、Waitなどのより単純なボックスの集まりとして表現されていることがわかります。このように、ボックスの中身を覗くことで、ボックスの使い方を考える際の参考にすることができます。
顔の判別
顔を学習させたら、その学習データに基づいて、今Pepperが認識している顔が誰の顔なのかを判別し、その名前をしゃべらせる ことをやってみます。
つくってみる
-
利用するボックスの準備
- standardボックスライブラリ
- Vision > Face Reco. ... 顔の識別をおこなう
- advancedボックスライブラリ
- Audio > Voice > Say Text ... 前段のBoxから入力された文字列をしゃべる
- standardボックスライブラリ
-
ボックスをつなぐ
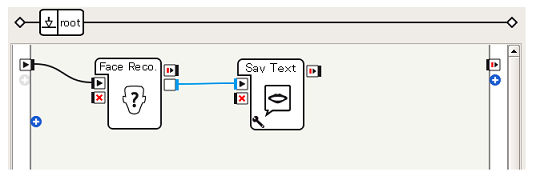
非常に単純で、Face Reco.ボックスの出力(青, 文字列)をSay Textボックスに与えているだけです。
動作確認
Pepperに接続、再生します。Pepperに顔を見せた場合に、「たろう」などと、学習した名前をしゃべれば成功です。
複数の顔をLearn Faceして、きちんとPepperが識別できるか、確かめてみてください。
画像の学習と判別
Choregrapheには視覚認識データベースの操作機能があり、これを利用することで、人の顔以外のものをPepperに学習させることができます。
画像の学習
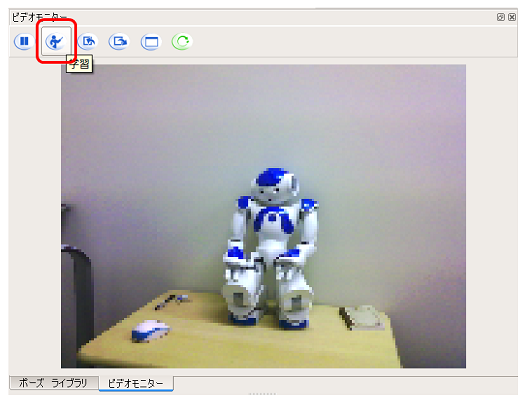
画像を学習するためには、Choregrapheのビデオモニター パネルを利用します。ここでは、アトリエにある NAO を学習させてみます。
-
Pepperに接続し、ビデオモニターに対象物が映った状態で、学習ボタン をクリックします
-
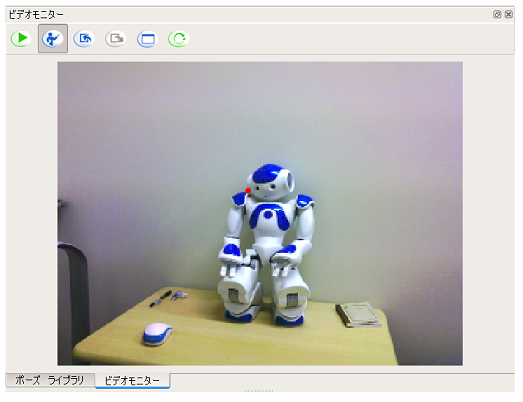
対象物の境界 でマウスの左ボタンをクリックします
-
直線を描く感覚で、頂点を左ボタンクリックして作成していきます
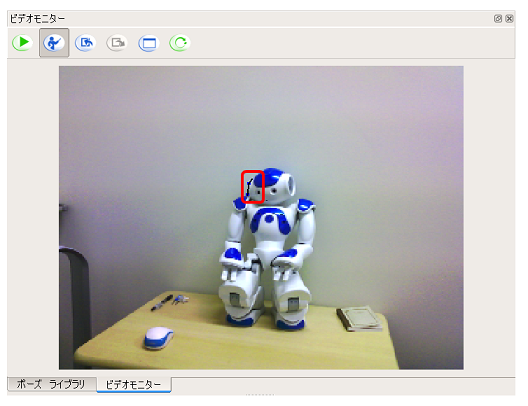
-
対象物を囲むように頂点を設定していき、最後に、開始点を左クリックします
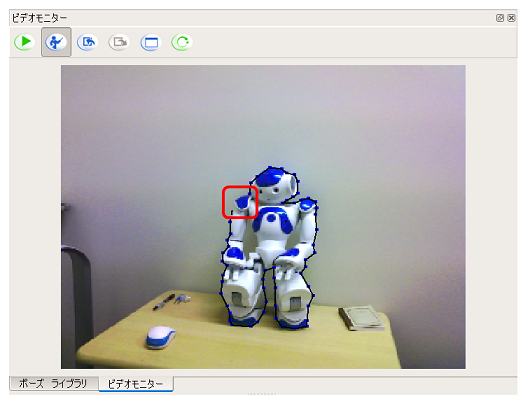
-
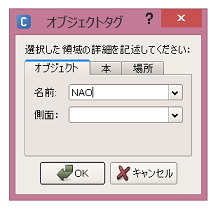
対象物の領域が識別され、情報入力を求めるダイアログが開くので、適当な情報を入力します
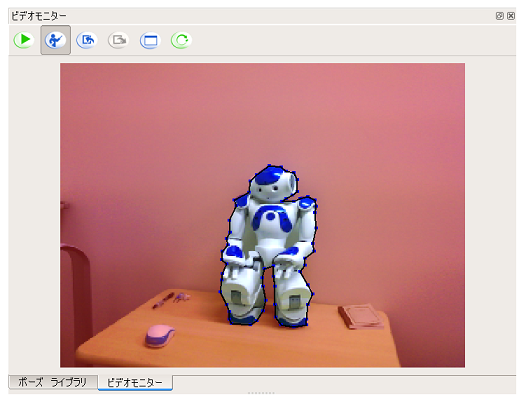
ここでは NAO と入力します。
-
Choregrapheの視覚認識データベースに登録された情報を、 [現在の視覚認識データベースをロボットに送信]ボタンをクリック してPepperに送信します
これで、PepperにNAOの画像的な特徴に対して、「NAO」という文字列を関連させることができました。
画像の判別
顔の判別と同様、学習させた視覚認識データベースの内容に基づいて、今見ているものが何なのかをしゃべらせる ことをやってみます。
つくってみる
Vision Reco.ボックスを利用することで、現在Pepperが見ている内容と視覚認識データベースを照合し、オブジェクトの名前を得ることができます。
-
利用するボックスの準備
- standardボックスライブラリ
- Vision > Vision Reco. ... 視覚認識データベースを照合する
- advancedボックスライブラリ
- Audio > Voice > Say Text ... 前段のBoxから入力された文字列をしゃべる
- standardボックスライブラリ
-
ボックスをつなぐ(1)
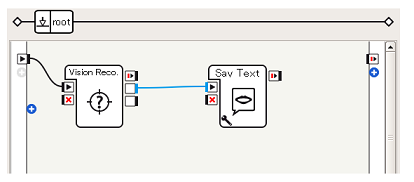
まず、顔の判別と同様、Vision Reco.ボックスのonPictureLabel出力(青, 文字列)をSay Textボックスに与えます。 -
ボックスをつなぐ(2)
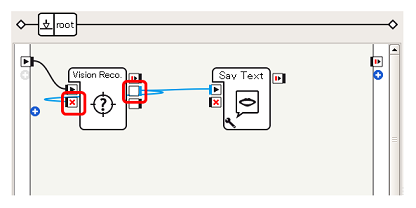
このサンプルでは、認識後しゃべっている間にVision Reco.ボックスの動作を停止するため(理由は後述)、Vision Reco.ボックスのonPictureLabel出力とonStop入力を接続します。
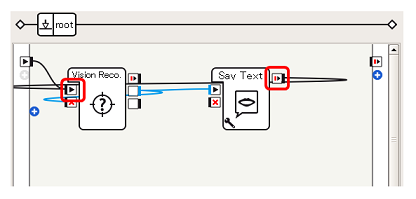
しゃべり終わったあと、Vision Reco.ボックスの動作を再開するため、Say Textボックスの onStopped出力 をVision Reco.ボックスの onStart入力に接続します。
####
[Tips]Vision Reco.ボックスの明示的な停止
Vision Reco.ボックスは画像を認識すると、認識している状況に変化がなくても定期的に出力をおこないます。
また、先に見たSay TextボックスからALTextToSpeech APIへの要求においては、Say Textボックスがすでに動作している場合でも、新たに入力された文字列は破棄されず次に処理できるよう蓄積されるようになっています。そのため、2.の接続だけだと、NAOを見せている間ずっと「NAO」「NAO」「NAO」としゃべり続けてしまうだけでなく、NAOをPepperの視界から外してもこれがしばらく続いてしまうことになります。
このような問題を防ぐため、Vision Reco.ボックスが認識結果を出力したのち、Vision Reco.ボックスをいったん停止、Say Textボックスが終わってからVision Reco.の動作を再開するということをおこなっています。
動作確認
Pepperに接続し、作成したアプリケーションを再生してみてください。
NAOを見せたときに「NAO」と言えば成功です。
このように、Pepperには画像認識のためのさまざまな機能が用意されています。視覚から得た情報でPepperをコントロールすることで、制御の幅が広がります。ぜひ色々、試してみてください。