Pepperでを使って開発しているとなぜかネットワーク接続がしにくくなったり、APIの呼び出しから返ってくるのに時間がかかるようになる、ということがままあります。
Pepperの中で動いているのはLinuxベースのOSだし、SSHしてみるといろいろプロセスが動いていることも確認できます。また、NAOqiのプロセスの中でもさまざまなサードパーティー製のPythonコードが動いていることが想像できます。そんな中でリソース利用が重なったりして不安定になるというのは、想像の範囲内だとは思うんですよね。
ただ残念ながらPepperはモニタリング機能を十分に備えているわけではありません(Aldebaranではモニタリングしているかもしれないですが・・・少なくともPepperオーナーがみられるものはあまりない)。これはPepperオーナーが運用ノウハウを蓄積していく上でよろしくない状況ではと思っています。あくまでも個人的な思いとしてですけど。
そんなわけで、Pepperに組み込むタイプのロガーサービスを作ってみているのでメモ。かなりざっくりと作ってみた状態なんですけれども、ネタとして。
使う技術の概要
NAOqiに関しては、主に2.3系の情報です。2.4でどうなるか未確認・・・
LogManager: Pepperにおけるログの処理
NAOqi documentの How to receive and send logs in Python というページで紹介されているように、 LogManager というサービスを通してログの情報を得ることができます。
具体的には、Subscribe to LogManager to obtain logs というセクションで紹介されているように、以下のような感じで利用できます。
def onLogMessage(self, msg):
try:
self.sendEvent('log', msg)
except:
pass
...
self.logListener = self.session.service('LogManager').createListener()
self.logListener.setLevel(logLevel)
self.handlerId = self.logListener.onLogMessage.connect(self.onLogMessage)
onLogMessageシグナルにPythonの関数を関連づけることで、メッセージの情報を得ることができるわけです。
procファイルシステム: 稼働に関する情報の取得
NAOqi documentを読むとわかる通り、Pepperで動いているNAOqi OSはGentooベースのLinuxです。そのため、一般的なLinux環境と同様 /proc/ 以下を見ることでCPUの性能情報やロードアベレージなどの情報を得ることができます。
今回はサービスの実装はPythonベースでおこなっているので、 linux-metrics を使ってこの情報を得ることにしてみます。
qibuild: サービスのビルド・パッケージングツール
基本的にモニタリング処理は、常にバックグラウンドで動作させておきたくなるところです。
PepperのアプリはChoregrapheで作ることが一般的ですが、ここで作成されたアプリは、何らかの形でオートノマスライフから起動してもらい、適切なタイミングでオートノマスライフに制御を戻さなければなりません。これはちょっと今回の目的には適していません。
一方、Choregraphe以外にAldebaranが提供している開発ツールとして、qiBuild というツールセットがあります。
このドキュメントを見ていくと、NAOqiにはサービスという実装形式も存在することがわかります。 Choregrapheで作ったアプリはビヘイビアファイルが集まったファイルとしてパッケージングされますが、サービスの形ですとC++からコンパイルしたバイナリやPythonスクリプトをパッケージングしてインストールし、これらをPepper起動時に実行することができそうです。
qiBuildでビルドしたパッケージが今後ストアなどでどういう扱いになっていくかは正直よくわからないですが、少なくとも開発の場面では利用することができそうです。これなら今回の目的に使えそうです。
なお、ドキュメントはC++のコードのビルド・パッケージングを中心に説明していますが、Pythonでサービスを書いてパッケージングしてインストール、みたいなことも断片的ですが読み取れます。もうちょっとドキュメントが充実するといいですねえ・・・
Fluentd: ログの集約
これで、Pepper内でログやメトリクスの情報を得るサービスを常駐させる見通しができました。
あとはそのログやメトリクスをどう吐き出して処理するかなんですが、kazunori279さんの記事 Raspberry PiからFluentdでBigQueryにデータを送るウェザーステーションの作り方 がやりたいイメージにぴったりだったので、ここではFluentdを使って集約、BigQueryにためるモデルで考えてみることにします。
適当な絵で描くとこんな感じ。
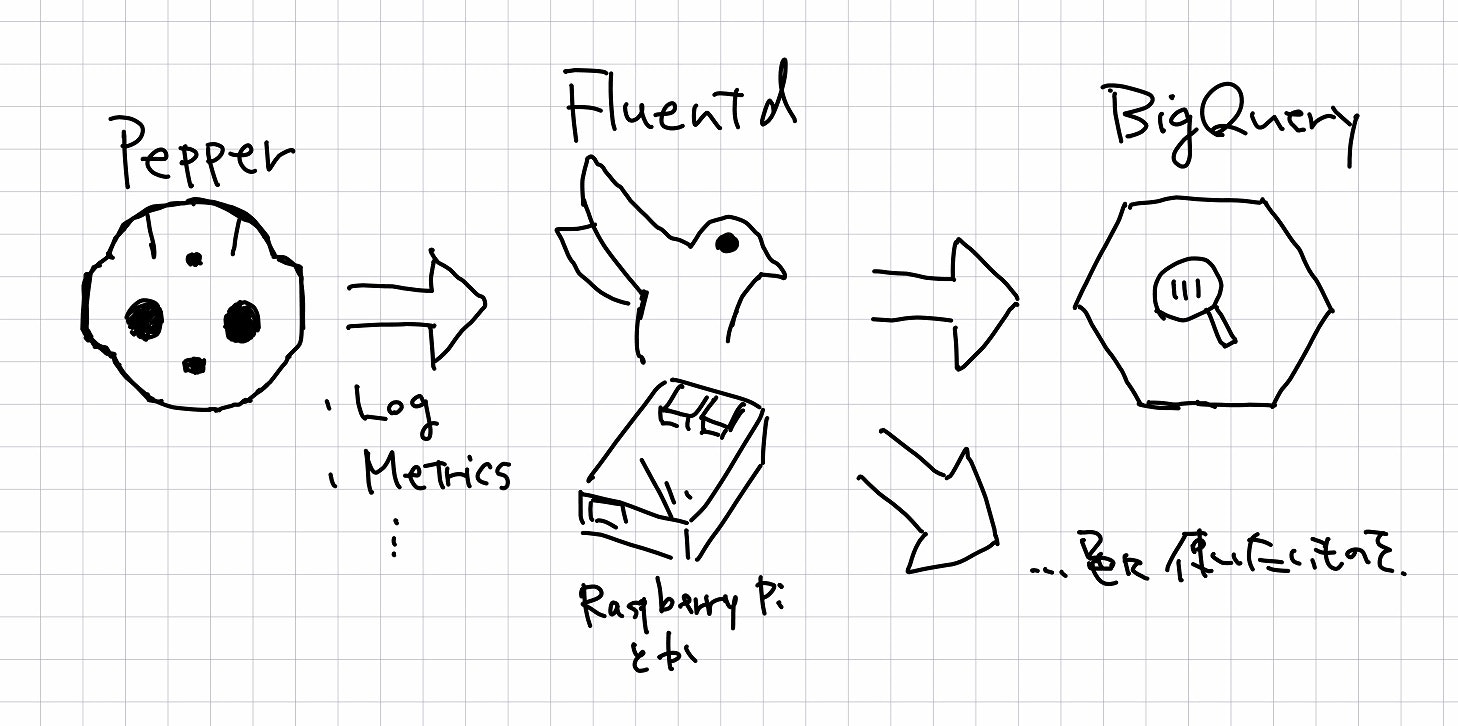
Fluentdをはさむことで、Pepperのログ・メトリクス出力側はそのままで、BigQueryだけでなく適宜別のサービスにログやメトリクスを投げつけることができるようになります。
また、NAOqiのログ /var/log/naoqi/tail-naoqi.log あたりを眺めていると、Debugレベルのログなど含めると高頻度でログが出力されるタイミングがあることがわかります。このような場合、送信状況により適切にバッファするなどの処理が必要となってきますが、この辺の機構を、まともに動くように自力で実装するのはおそろしい苦行となります。そんなわけで一段Fluentdをかませる形がいいかなと。
なお、ここで紹介されている fluent-logger-python ですが、このライブラリが依存しているライブラリ msgpack-python がCベースのコードで、Pepper上で動作させるためにはクロスコンパイル環境を用意してビルドしなければいけません。ですが、ありがたいことにMessagePackはPure Pythonな実装もあるようですので、今回は試しに msgpack-pure を使わせてもらう形で実装しています。
(開発が最近でも行われているという観点では u-msgpack-python でもよかったか・・・?今後試していきます。)
作ったもの
作ったものは https://github.com/yacchin1205/pepper-fluent-logger にあります。プロジェクトのディレクトリは fluentloggerディレクトリ です。
転送先Fluentdが起動していない場合の考慮など、まだかなり甘い作りですのであくまでもお試しとして・・・随時修正予定。
以下、ざっくりと使い方などを。
インストール方法
ビルドとインストールはUbuntu 14.04環境でおこないました。Macでも動きそうな気がします。なお、Windowsでは正常動作しません。生成されるスクリプトの一部の改行コードがCR+LFになってしまっており、Pepper上で正常に動作しなかったので。(ちゃんと確認してIssueあげてあげるか・・・)
qiBuildのインストール
qiBuildはpipでインストールすることができます。開発用のマシンで以下のように実行します。(適宜sudoするとかvirtualenv用意するとかしておく)
$ pip install qibuild
なお、qiBuildのすべての機能を利用するためには、環境にNAOqiのPython SDKがインストールされている必要があります。Python SDKはAldebaranのサイトから入手可能です。詳しくはNAOqi documentなど参照してください。
ワークツリーの準備
プロジェクトをビルドする前に、適当なディレクトリをワークツリーとして準備する必要があります。
適当なディレクトリを作成し、そのディレクトリに移動したうえで以下のコマンドを実行します。
$ qibuild init
$ qipy bootstrap
これにより、このディレクトリ以下でqibuildの各種コマンドを利用することができるようになり、Pythonスクリプトを含んだプロジェクトの操作が可能になります。
pepper-fluent-loggerのビルド・インストール
ワークツリーを準備したら、そのディレクトリの配下にpepper-fluent-loggerリポジトリをcloneしてきます。
あとは、fluentloggerディレクトリで以下のように実行することで、Pepperに配備可能なパッケージを作成することができます。
$ qipy install fluentloggerservice
$ qipkg make-package fluentloggerservice.pml
パッケージは fluentloggerservice-(バージョン).pkg のようなファイルとして作成されます。このファイルはqipkgコマンドを用いてPepperにインストールすることができます。
$ qipkg deploy-package fluentloggerservice-0.1.0.pkg --url nao@(PepperのIPアドレスもしくは名前)
これにより、fluentloggerserviceパッケージがPepperにインストールされ、パッケージ内のfluentlogger.pyが自動的に実行されるようになります。
どのような設定によりこの挙動を実現しているかは qiproject.xml とか manifest.xml とかを見ていただくのがよいかも。
動作確認
Fluentdの標準出力で動作確認してみる
まずはPepperからFluentdにログが流せるかどうか、標準出力を使って確認してみます。
FluentdはRaspberry Piにあらかじめインストールしてあるものとします。
今回は試しに、以下のような設定ファイルを準備してみます。
<source>
type forward
port 24224
</source>
<match pepper.**>
type stdout
</match>
デフォルトでは、fluentloggerserviceは pepper. から始まるタグ名でログやメトリクスを出力するようになっています。このタグ名に一致したものはすべて標準出力に出力する形にしてみます。
この定義ファイルを使ってFluentdを実行します。例えば以下のような感じ。
(RaspberryPi)$ fluentd -c fluentd-stdout.conf
これでRaspberry Piの24224ポートでforward入力プラグインが動作した状態になります。まずはこのforwardに入力されたイベントのうち、タグが pepper. から始まるものをすべて標準出力に表示させてみることにします。
次に、PepperにSSHし、以下のように qicli callコマンドを実行します。正常にfluentloggerserviceがインストールできていた場合、FluentLoggerServiceモジュールを呼び出すことができるはずです。
(Pepper)$ qicli call FluentLoggerService.setForwarder (Raspberry PiのIPアドレス) 24224
するとFluentdの標準出力に、以下のようにログが現れるはずです。
2015-10-30 06:49:05 +0000 [info]: reading config file path="fluentd-stdout.conf"
2015-10-30 06:49:06 +0000 [info]: starting fluentd-0.12.16
...
2015-10-30 06:49:07 +0000 [info]: listening fluent socket on 0.0.0.0:24224
...
2015-10-30 06:49:20 +0000 pepper.cpu: {"cpu_iowait":0.0,"load_15min":1.66,"load_1min":1.88,"cpu_idle":68.82793017456359,"filedesc_allocated":3136,"filedesc_allocated_free":0,"cpu_user":20.94763092269328,"robot":"pepper","cpu_softirq":1.2468827930174626,"cpu_system":8.977556109725683,"load_5min":2.04,"filedesc_max":197836,"cpu_irq":0.0,"procs_blocked":0,"cpu_nice":0.0,"procs_running":1}
2015-10-30 06:49:20 +0000 pepper.net: {"tx_bytes":2062385,"nic":"wlan0","robot":"pepper","rx_bytes":1006156}
2015-10-30 06:49:20 +0000 pepper.net: {"tx_bytes":0,"nic":"eth0","robot":"pepper","rx_bytes":0}
2015-10-30 06:49:20 +0000 pepper.net: {"tx_bytes":957069,"nic":"usb0","robot":"pepper","rx_bytes":293005}
デフォルトでは、30秒おきにCPUとNICに関するメトリクスを取得し、Fluentdに対して情報を送るようになっています。これらは pepper.cpu と pepper.net というタグが付加されています。
この辺の動きは今後充実させていく予定・・・
NAOqiのログについては、デフォルトではLogManagerの監視はおこなわないようになっています。FluentLoggerService.setWatchingLogsメソッドを用いてLogManagerの監視を有効にすることができます。
(Pepper)$ qicli call FluentLoggerService.setWatchingLogs 1
(Pepper)$ qicli call FluentLoggerService.setWatchingLogLevel Debug
今回は、テストのためにDebugレベル以上のログを出力するよう設定してみます。
このあと、Raspberry Pi側で、
...
2015-10-30 06:49:41 +0000 pepper.log: {"category":"vision.alfacedetection","level":5,"timestamp":{"tv_sec":1446187781,"tv_usec":731470},"robot":"pepper","source":":process:0","location":"7592ec1d-b8fb-41dc-8c87-72289601164b:3910","message":"Found 0 face(s)","id":18093}
2015-10-30 06:48:53 +0000 pepper.log: {"category":"OKAOFaceDetection","level":5,"timestamp":{"tv_sec":1446187733,"tv_usec":231941},"robot":"pepper","source":":detectFaces:0","location":"7592ec1d-b8fb-41dc-8c87-72289601164b:3910","message":"Detecting faces took 15951 usec","id":13209}
...
こんな感じでログが確認できれば成功です。
Google BigQueryに稼働情報をためてみる
Fluentdに流れてきたログをBigQueryに投げるのは、fluent-plugin-bigquery を使えばさっくりと実現できます。
まず、Google Cloud Platformのコンソールやツールを使い、以下をおこなっておきます。詳細はよい記事がいっぱいありますので割愛・・・
- ログ収集用のプロジェクトを作成
- サービスアカウントを作成する。キーペアの情報はJSONで得ておく
- プロジェクトにデータセット
sample, テーブルpepper_cpuを作っておく (スキーマはこんな感じ)
次に、作成したテーブルにログやメトリクスを突っ込むようなFluentdの設定ファイルを記述します。今回は以下のようにしました。
<source>
type forward
port 24224
</source>
<match pepper.cpu>
type bigquery
method insert
auth_method json_key
json_key (作成したサービスアカウントのJSONファイルへのパス)
project (プロジェクトのID)
dataset sample
table pepper_cpu
time_format %s
time_field time
fetch_schema true
field_integer time
</match>
<match pepper.**>
type stdout
</match>
pepper.cpuタグを持つデータがきたら、BigQueryのsample.pepper_cpuテーブルにinsertするように指示しています。標準出力の時と同様に、設定ファイルを指定してFluentdを実行します。
(RaspberryPi)$ fluentd -c fluentd-bq.conf
あとは、Pepper側で計測したpepper.cpuのデータがこのFluentdに流れてくると、sample.pepper_cpu テーブルにデータがinsertされていきます。
これでログ・メトリクス転送の枠組みは完成です。以下のように https://bigquery.cloud.google.com/ でクエリを発行することでテーブルの内容を確認できます。
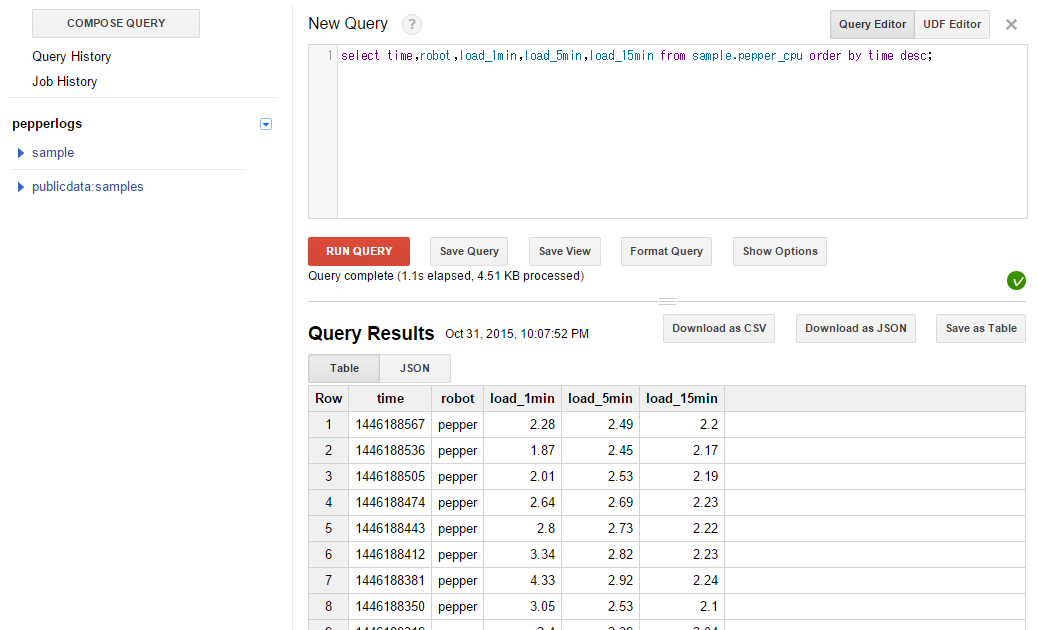
こんな感じで、稼働に関する情報を(まずはCPUだけですが)BigQueryに投げられるようになりました。
おわりに
以上のような感じで、PepperのログやメトリクスをFluentdで集約、BigQueryに突っ込む仕掛けを試してみています。
これはインフラ運用のお仕事の中で使っている枠組みでもあるのですが、
この枠組みだとPepperの台数が増えても、FluentdのForwarderを複数台にするくらいで割と簡単にスケールしそうなので(最終段のBigQueryが強いので)良い感じがするなあー、と思っています。
とりあえず気になっていたCPUの負荷やロードアベレージの変化を追っていってみますが、関節の温度やバッテリー残量の変化なども見ていけるとよいなあと。あと、使えそうだとわかってきたら、このロガー自身のオーバーヘッドも見ながら、C++への書き換えなんかも検討してみたいですねえ・・・