財務時系列データを使用した機械学習
当たり前のように金融データを入れて確度70%程度の結果をだしているサンプルが公式にありました。
動画が英語なのと専門的な言葉がいっぱいでてきてとんちんかんちんでした。
これを少しずつ理解していこうと思います。
動画内の資料は以下にありました。
https://github.com/corrieelston/datalab/blob/master/FinancialTimeSeriesTensorFlow.ipynb
[TensorFlowで株価予想] 9 - 年利6.79%
こちらも参考にさせて頂きましたが、以下の理由で動かなかったです。
・TensorFlowのバージョン違い 私は1.3を使用しています。
・quandlからYAHOOなどが撤退しデータがとれない。
・普通にバグってる?closingdataをfillnaで埋めた後の処理がなんかへんでlogとるとヘンテコな値がかえってきます。
logが取れてないのは直したのですが、pythonも初心者なので最初からやっていこうと思いました。
目標は
[TensorFlowで株価予想] 9 - 年利6.79%をもとにN225を予測してみたいと思います。
データの用意
日本の特に株価のデータがほしくなるといつもここで困ります。
財務時系列データを使用した機械学習はGCPのサービスで配布されているようで参考になりませんでした。
とりあえずお勉強のためなのでYAHOO Financeから手で落としてきます。
ダウンロードした銘柄は以下です。
Nikkei 225, Japan
Hang Seng, Hong Kong
DAX, German
Dow, US
S&P 500, US
Shanghai Composite Index (China)
BOVESPA, Brazil
現在無料で一番データがとりやすいのはOANDA REST API
かとおもっているのですが、いいのあったら教えてください。
またOANDAは日本の口座だと銘柄が少ないですが、海外だとN225などもとれます。
Node.jsで日本向けのv1仕様ですがラッパーをおいておきます。
github oanda rest api v1 wrapper
OANDAはリアルタイムのtickもストリーミングでくれるすごいやつです。
学習させる前にデータの整理と確認が必要
ここだけでもとても勉強になりました。
まずpipでやってしまったので各必要なものをインストールします。
pip3 install pandas wheel matplotlib
numpy+mklとscipyはwheelからインストールしないとエラーになりました。
http://www.lfd.uci.edu/~gohlke/pythonlibs/から
numpy+mklとscipyのpython35 AMD64のwhlをダウンロードし
pip3 install whlのファイルパス
で入れたら動きました。
pythonも初心者なので処理を簡単にします。
まずはCSVの読み込み
同一ディレクトリに[data]フォルダを作成しCSVをいれました。
謎の^はファイル名からとりました。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# ダウンロードしてきたやつ
INDEIES = ["N225", # Nikkei 225, Japan
"HSI", # Hang Seng, Hong Kong
"GDAXI", # DAX, German
"DJI", # Dow, US
"GSPC", # S&P 500, US
"SSEC", # Shanghai Composite Index (China)
"BVSP"] # BOVESPA, Brazil
def study():
closing = pd.DataFrame()
for index in INDEIES:
# na_valuesは文字列"null"のとき空として扱う CSVみるとnullって書いてあります。
df = pd.read_csv("./data/" + index + ".csv",na_values=["null"])
df["Date"] = pd.to_datetime(df["Date"])
df = df.set_index("Date")
closing[index] = df["Close"]
closing = closing.fillna(method="ffill")
print(closing.describe())
if __name__ == "__main__":
study()
python study.py
で実行できます。
| N225 | HSI | GDAXI | DJI | GSPC | SSEC | BVSP | |
|---|---|---|---|---|---|---|---|
| count | 2448.000000 | 2448.000000 | 2448.000000 | 2448.000000 | 2448.000000 | 2448.000000 | 2448.000000 |
| mean | 13349.392896 | 21913.031957 | 7880.838338 | 13917.580786 | 1550.122515 | 2866.851903 | 56766.236928 |
| std | 3908.292323 | 2993.790052 | 2091.218792 | 3344.255804 | 427.776169 | 783.055520 | 8250.928787 |
| min | 7054.979980 | 11015.839844 | 3666.409912 | 6547.049805 | 676.530029 | 1706.703003 | 29435.000000 |
| 25% | 9636.337158 | 20519.942383 | 6208.075073 | 11368.147216 | 1215.270020 | 2265.974182 | 51395.750000 |
| 50% | 13336.609863 | 22299.020508 | 7408.014893 | 13231.739746 | 1429.614990 | 2806.923950 | 56981.000000 |
| 75% | 16647.637695 | 23539.682129 | 9669.777344 | 16957.195313 | 1978.122467 | 3164.269348 | 63281.000000 |
| max | 20868.029297 | 31638.220703 | 12374.730469 | 21115.550781 | 2399.629883 | 6092.057129 | 73517.000000 |
グラフでも見てみる
以下を最後に追加
closing.plot()
plt.show()
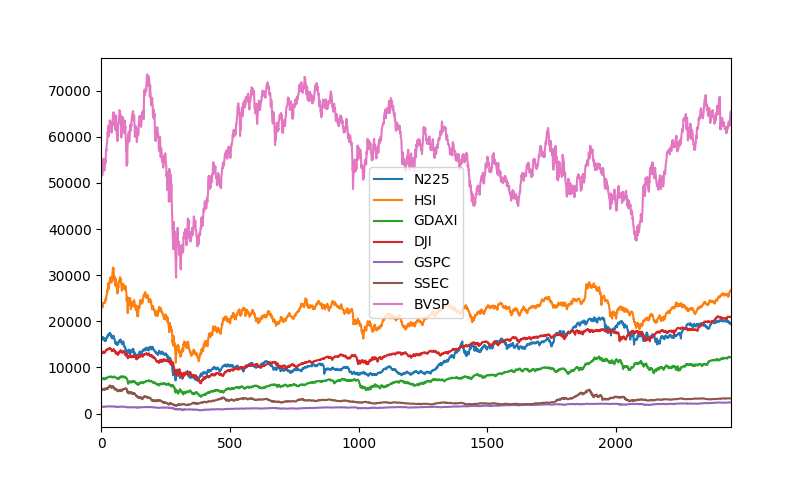
抜けもないしなんか大丈夫そう。
次回よりなんか金融工学っぽくなってきます。
前 ニューラルネットワークの機械学習を投資につかうまで 環境作成編
次 TensorFlowを投資につかうまで 衝撃のサンプル編 (2)