はじめに
前回はSplunkの新規インストールとAppを利用したTwitterデータのサンプル投入をやりました。
「 でもやっぱり自分のタイムラインを取得したいよね! 」
ってことと、
「 汎用APIのときどうしたらいいの? 」
ってのを思うので今回は2通りの方法でTwitterのStream APIから自分のタイムラインデータを取得します。
App for Twitter Data
ではまずは前回も使ったApp for Twitter Dataを利用して自分のタイムラインをSplunkに取り込みます。
そもそも前回取得していたあのサンプルデータって何だったのでしょうか。
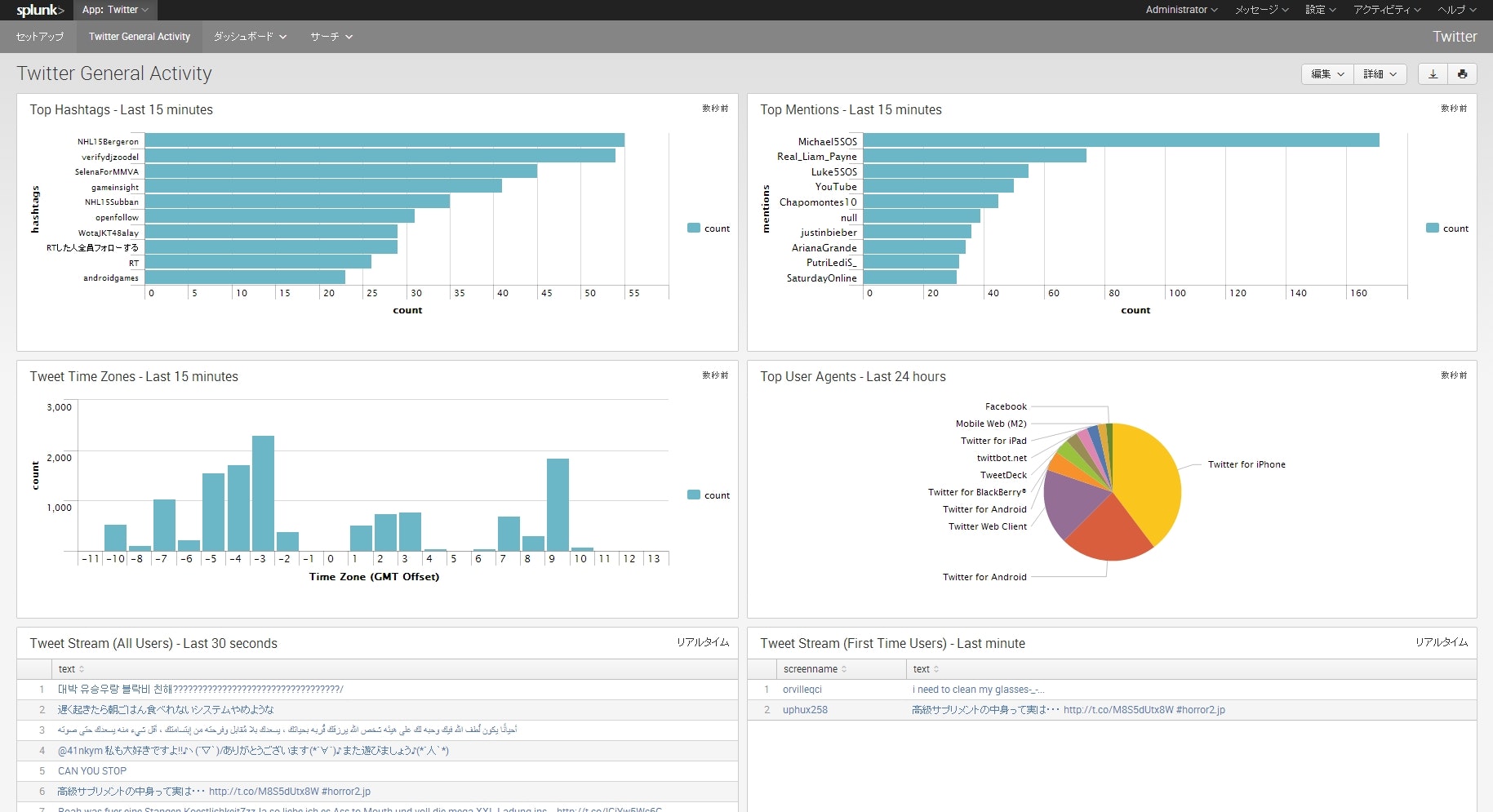
これは実はTwitterが提供している「 全ツイートの一部をランダムに取得するAPI 」から取ってきたデータでした。
Returns a small random sample of all public statuses. The Tweets returned by the default access level are the same, so if two different clients connect to this endpoint, they will see the same Tweets.
で、それを指定しているのが/opt/splunk/etc/apps/twitter2/bin/stream_tweets.pyのスクリプトです。
詳しい部分は省きますが、このスクリプトが60秒に1回動き、その都度上記APIからツイートデータを取得しています。
さて、ではstream_tweets.pyのスクリプトを少しいじって自分のタイムラインを取得できるようにしましょう。
まずApp for Twitter Dataのセットアップ画面からEnable Twitter Input:のチェックを外してください。これでスクリプトの定期実行が停止します。
あるいはデータ入力の管理画面からスクリプトを直接無効にしてもOKです。
では次にスクリプト内の3箇所を下記のように修正してください。
vi /opt/splunk/etc/apps/twitter2/bin/stream_tweets.py
-
【137行】
def read_sample_tweet_stream(→def read_user_tweet_stream( -
【172行】
streamer.statuses.sample()→streamer.user() -
【200行】
read_user_tweet_stream(→read_user_tweet_stream(
上記のように設定したら、先ほどの逆の手順でスクリプトの定期実行を有効化してください。
設定がそのままであれば60秒毎に実行されるので、下記のログを確認してpythonのエラーが出ていなければ成功です。
tail -f /opt/splunk/var/log/splunk/splunkd.log
改めてAppのDashboardを確認したら自分のタイムラインデータが取り込まれているはずです。
(ただ、ダッシュボードのパネルはsampleデータの分析に適したものなので自分のTLにはイマイチです)
REST API Modular Input
汎用的なAPIも扱えるようにREST API Modular Inputを用いてタイムラインデータを取り込みます。
REST APIのセッティング
ではRESTの入力設定をしていきましょう。
設定 → データ入力 → REST → 新規
下記のように設定してください。書いてないところはとりあえず空白でOKです。
| 項目名 | 設定値 |
|---|---|
| Endpoint URL | https://userstream.twitter.com/2/user.json |
| HTTP Method | GET |
| Authentication Type | oauth1 |
| OAUTH 1 Client Key | <API key> |
| OAUTH 1 Client Secret | <API secret> |
| OAUTH 1 Access Token | <Access token> |
| OAUTH 1 Access Token Secret | <Access token secret> |
| Response Type | json |
| Streaming Request ? | ○ |
| ソースタイプの設定 | manual |
| ソースタイプ | |
| その他の設定 | ○ |
| インデックス | main |
- 多分下の4つくらいは特に関係ないと思います。(詳しくは試してない)
さて、上記の設定を終えたら適当に名前を付けて保存、有効化しましょう。
TLにツイートが流れてくるのを待ってもいいし、自分で何かつぶやいてみてもいいでしょう。
そうしたらサーチ画面から
sourcetype = Twitter user.screen_name = <アカウント名>
あたりで検索をかけてみましょう。
多分指定したアカウントのつぶやきがヒットします。
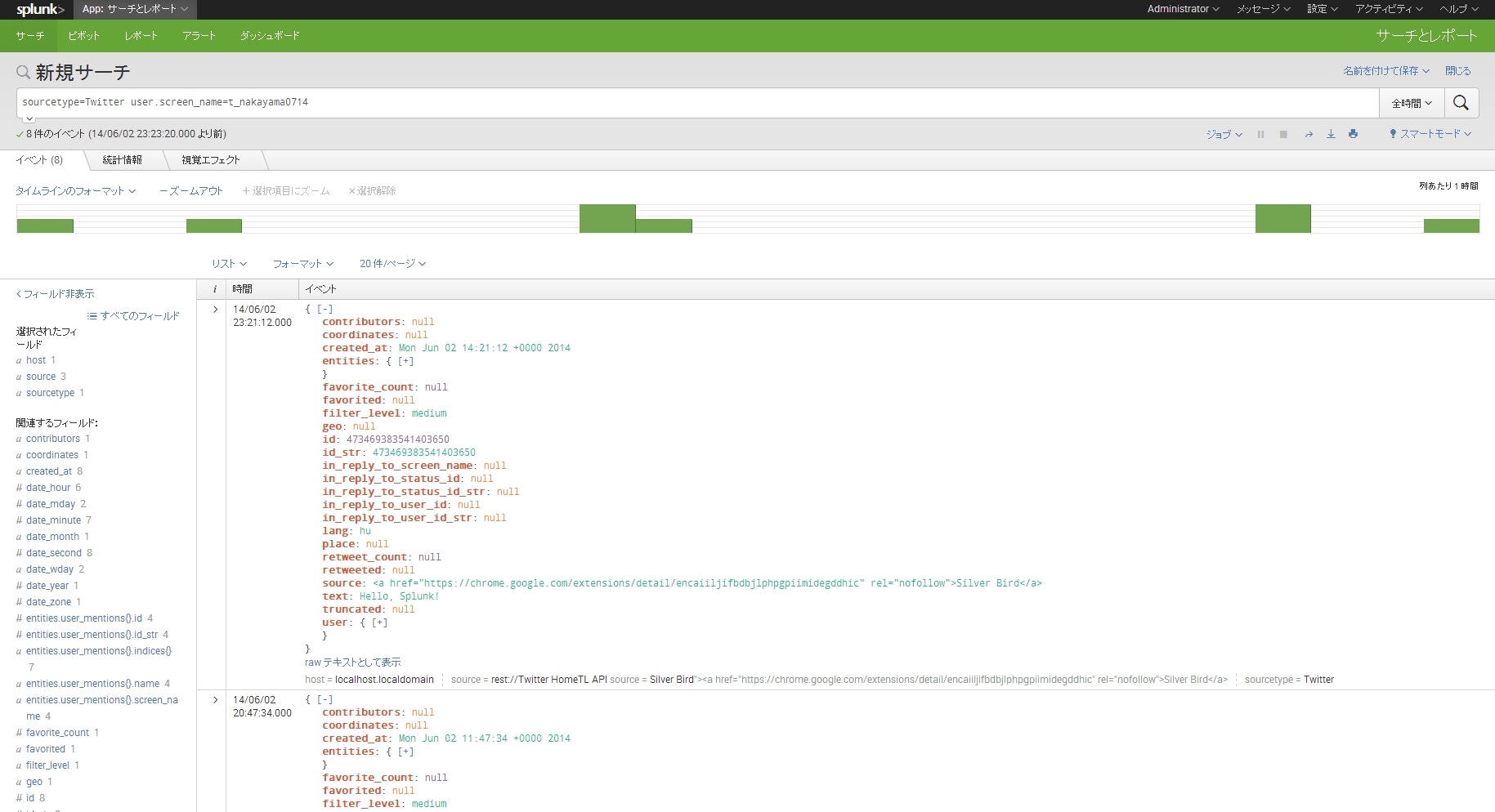
先ほど入力設定でResponse Type -> jsonを選択したためデータがjsonで取り込まれます。
また、Splunkはjsonの構造をkey-valueなノリで解釈してくれて、自動的にkeyをフィールドと認識してくれます。
なので面倒なフィールド調整などもいらず、非常に楽チンです。
では少しTwitterのjsonデータを見てみましょう。
| Key | Value |
|---|---|
| create_at | つぶやいた時刻 |
| source | つぶやいたクライアント |
| text | つぶやき本文 |
| user.screen_name | アカウント名 |
| user.description | プロフィール |
というような感じになっています。この辺りの値でしぼっていくと膨大なツイートの中からでも効率的に目的のツイート(群)を見つけることができます。
TwitterのAPI
今回はStream APIということでひたすらデータの流れてくるTwitter APIを使っています。なので、最初に触れたhttps://stream.twitter.com/1.1/statuses/sample.jsonなんかを受け続けると、あっという間にフリーライセンス制限(参照)に引っかかってしまいます。ごく一部とはいえ、全世界でつぶやかれるツイートですからね。
(実際ひっかかったのでSplunk建て直しました)
他にどんなAPIがあるのか少し調べてみました。
| API名 | 種別 | 説明 | Endpoint URL |
|---|---|---|---|
| User timeline | REST | 指定ユーザのつぶやきを取得 | https://api.twitter.com/1.1/statuses/user_timeline.json |
| Home timeline | REST | 指定ユーザのTL取得 | https://api.twitter.com/1.1/statuses/home_timeline.json |
| Show tweet | REST | 指定IDのつぶやきを取得 | https://api.twitter.com/1.1/statuses/show.json?id=xxx |
| Search tweet | REST | 指定条件の検索結果を取得 | https://api.twitter.com/1.1/search/tweets.json |
| User stream | STREAM | 指定ユーザのストリームを取得 | https://userstream.twitter.com/1.1/user.json |
| Site stream | STREAM | 複数ユーザのストリームを取得 | https://userstream.twitter.com/1.1/site.json |
| Filter stream | STREAM | 指定条件のストリームを取得 | https://stream.twitter.com/1.1/statuses/filter.json |
| Sample stream | STREAM | サンプルストリームを取得 | https://stream.twitter.com/1.1/statuses/sample.json |
確かにこうやって公開されているAPIが分かればTwitterクライアントの裏側がどうなっているか非常によくわかりますね。
AndroidにSample stream実装したらすぐ死にそう。
次回
とりあえずあとはしばらく放置しておけば勝手にデータが溜まってくるので、データがある程度溜まり次第 サーチの書き方 を勉強していきたいと思います。多分ドキュメントを淡々と読むことになりそう。 → 次回 できました。
-
ちょっと古い(最新のSplunkはv6.1)ですが基本的な文法を学ぶ分にはいいでしょう。多分。
参考
今回あれこれするにあたり下記を参考にさせていただきました。
-
Twitter for Splunk: Tracking Tweets
SplunkのTipsから。ここではFilter streamを使って解説していますね。
-
第3回Twitter API勉強会 - ストリーミングAPI
今回やってみるまでTwitter APIがどういう体系になってるのかよくわかってませんでした。