はじめに
前回でめでたく自分のタイムラインに流れるツイートを取得できるようになったと思うので、今回はそのデータを分析してみたいと思います。
データを確認
前回の投稿から1週間、ひたすらデータを食わせ続けたのでまずはどれくらい溜まっているか確認しましょう。
ホーム画面のSearch & Reportingからサーチを開きましょう。
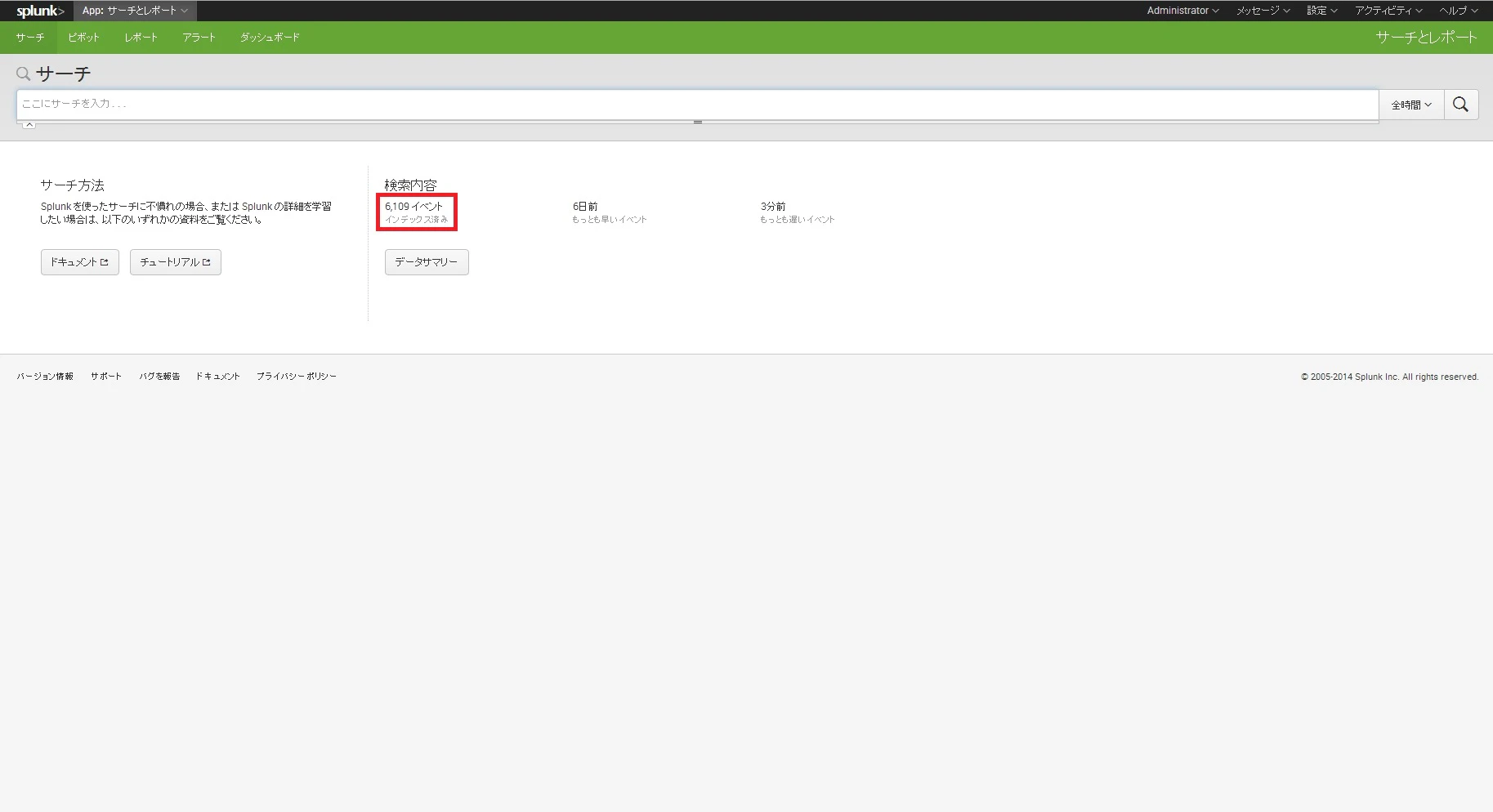
赤で囲んだところを見ると、現在Splunkで何件のデータを保持しているのかが分かります。
さらにすぐ下のデータサマリを開くと、

ホスト、ソース、ソースタイプの観点で件数を確認することができます。
-
ホスト
データの受信元。
現在登録しているデータ入力では全てホストをlocalhost.localdomainにしてあるので1個だけ。
Splunkでサーバクラスタのログ管理などをしている場合、ここに色々なホストが並ぶことになります。 -
ソース
実際に
データ入力で管理されるうち、どこから入力されたかで分類されます。
画像を見ると分かるようにRESTで3件のソースを持っていますが、登録名が違うので同じREST入力でも区別されます。 -
ソースタイプ
データの種別を表します。データ入力時に指定できます。
前回はソースタイプTwitterで設定しましたね。
このように3つの観点で大まかに分類されますが、クラスタなどを対象とする場合上記3つを上手く設定しておくとログの管理がしやすくなるかと思います。
では今回サーチするTwitterのタイムラインデータを見ていきます。
一番件数の多いrest://Twitter HomeTL APIをクリックします。ポチッ。
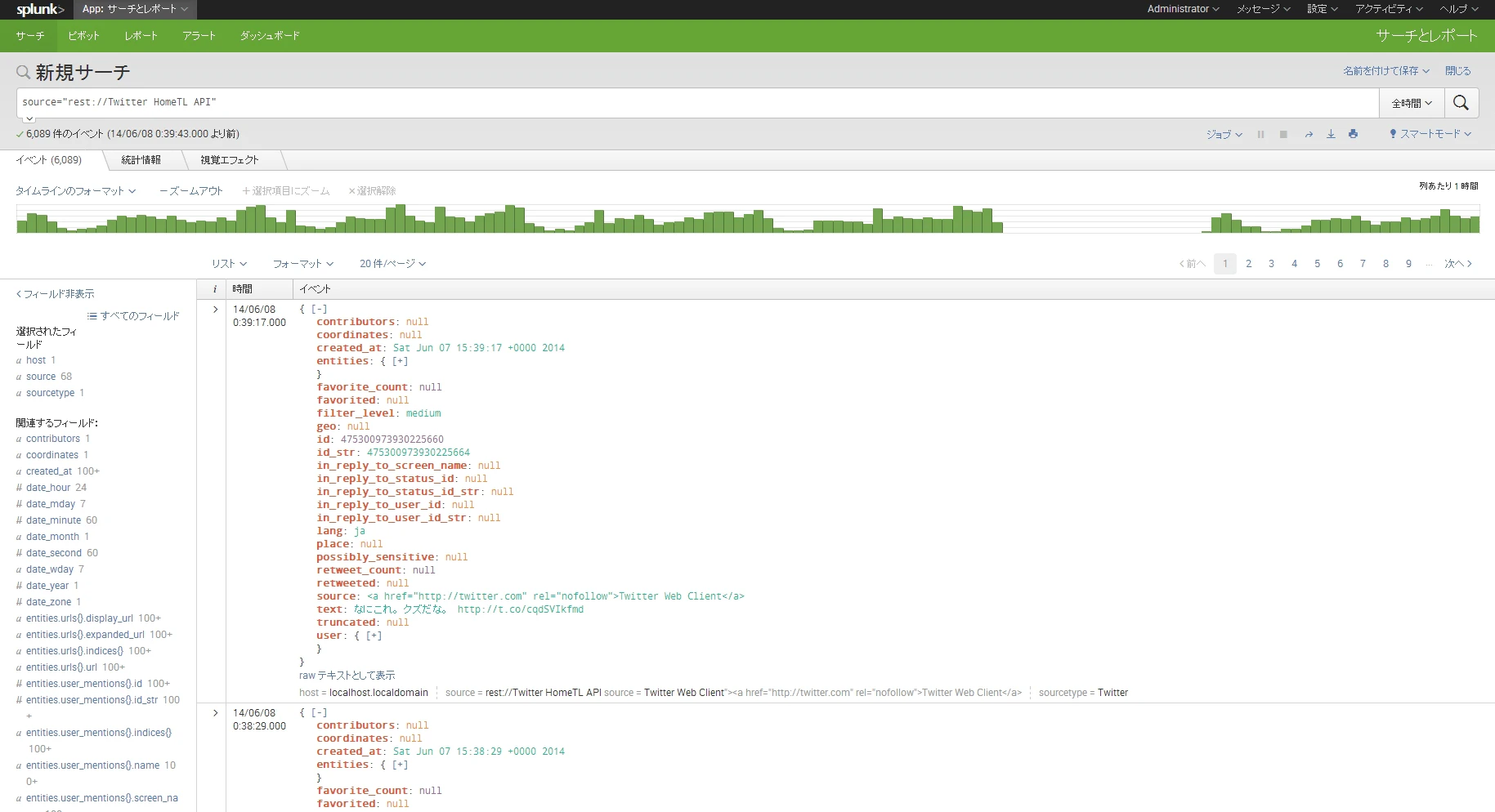
と、こんな感じでずらりと見ることができます。
サーチバーを見るとsource="rest://Twitter HomeTL API"となっていますね。
こんな感じでどんどん絞込をかけていくことになります。
分析してみる
では早速分析してみましょう。
とはいえ、まだ件数が6000件くらいしかないのでいい結果が得られるとは思えませんが。。。
今回は下記3点の分析を行います。
- 時間帯別つぶやき数
- 曜日別つぶやき数
- クライアント別つぶやき数
クエリに関して詳しい仕様等が知りたい方は
をご覧ください。
1つ目はv5系で少し古いですが、よく出来てていい感じです。
下2つは機械翻訳感丸出しで読んでて不愉快なレベルなのでおすすめしません。古いし。
無理に日本語読むくらいなら最初から英語版を読んだほうが楽かもしれません。最新ですし。
時間別つぶやき数
ではまず時間帯別に区切ってどれくらい分析されているのかを見て行きたいと思います。
使用するクエリはこちら。
source="rest://Twitter HomeTL API" | stats count by date_hour | sort by date_hour
上記クエリですが、source="rest://Twitter HomeTL API"のデータを元に統計を行っています。
SplunkのクエリではLinuxのようにパイプによる結果受け渡しが可能で、今回はタイムラインのツイートに統計を行っています。
stats count by date_hour
書いてあるとおりですが、時間ごとのデータ数をカウントしています。
データ群にたいして統計処理を行うときはstatsコマンドを使いますが、今回はその中のcountを使っています。
で、カウントと言っても何別にカウントするかというのをbyで指定しています。ここで指定されているdate_hourというのはSplunkがデフォルトで持っているフィールドで、データの日時を認識して勝手に振り分けてくれる便利なやつです。
今回の例でデータの日時はというと、ツイートに含まれるcreated_atフィールドの値が日時にあたりますね。
date_***系で他にあるものをまとめてみます。
| フィールド名 | 説明 | 値 |
|---|---|---|
| date_second | データの秒 | 00~59 |
| date_minute | データの分 | 00~59 |
| date_hour | データの時 | 00~23 |
| date_wday | データの曜日 | monday,tuesday,...,sunday |
| date_mday | データの日 | 1~31 |
| date_month | データの月 | 1~12 |
| date_year | データの年 | **** |
| date_zone | データのタイムゾーン | -12~+14 |
統計を取る場合に時間を基準にすることはよくあるかと思うのでこのフィールドは非常に役立ちますね。
さて、最後にsort by date_hourですが、当然時間帯の値で並び替えるので効果としては問題無いと思うのですが、statsで統計処理を行うと結果はデータの一覧ではなく処理の結果で返ります。
今回の例で行けば、
| date_hour | count |
|---|---|
| 23 | 1000 |
| 11 | 500 |
というような調子になるかと思います。
で、欲しいのは当然時間でソートされた結果ですからsort by date_hourを行うわけです。
stats → sortの流れは定番っちゃ定番なので感覚的に使ってもいいかもしれませんが、パイプでの受け渡しがどうなっているかきちんと考えておくと難しいクエリも迷うこと無く書けるようになるかもしれません。
さて、それではクエリの結果を確認しましょう。
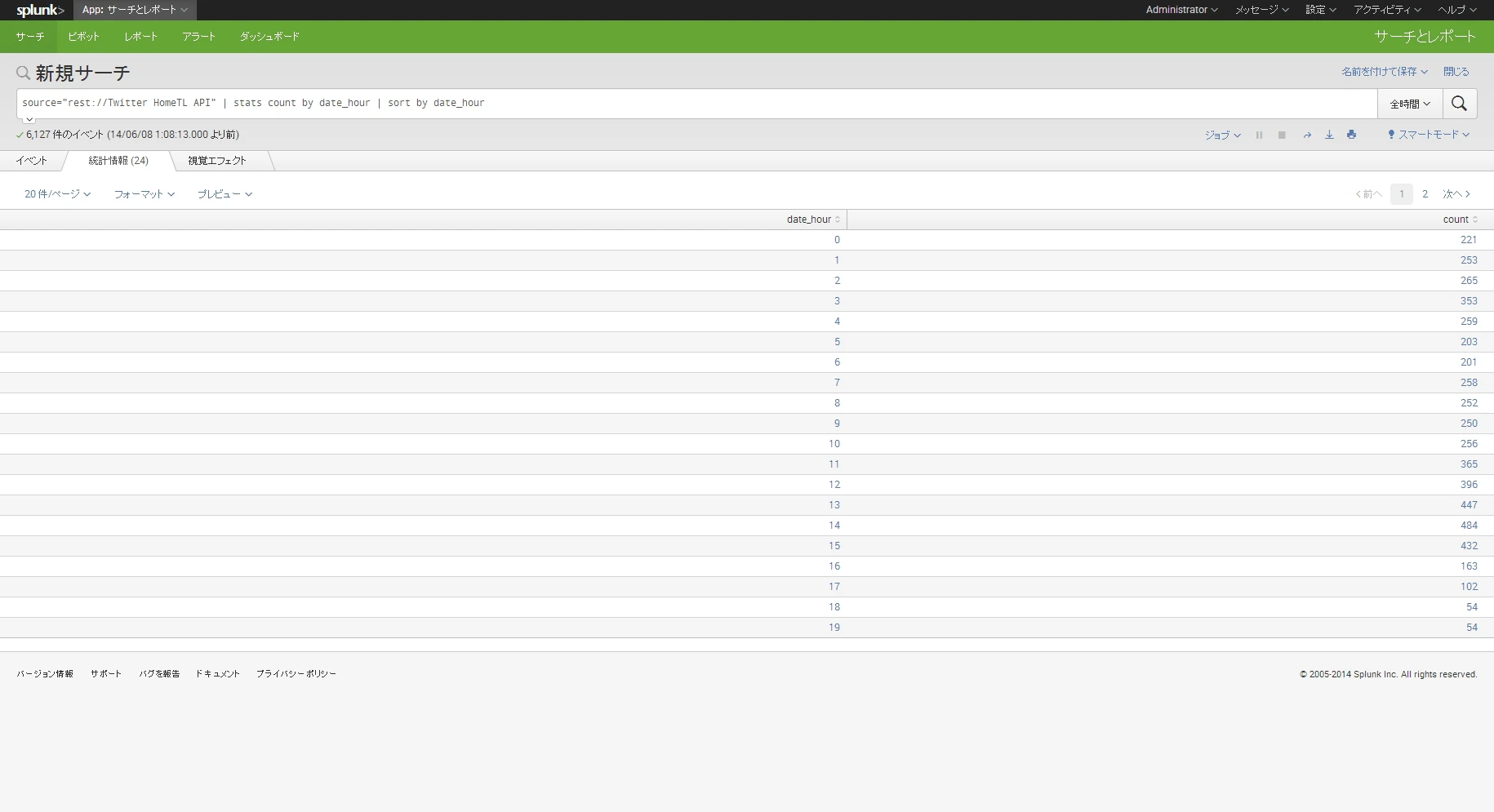
と、こんな感じの面白くない結果が出たと思います。
現在サーチバーの下にあるように、統計情報タブの情報を見ているわけですが隣の視覚エフェクトタブを見てみましょう。
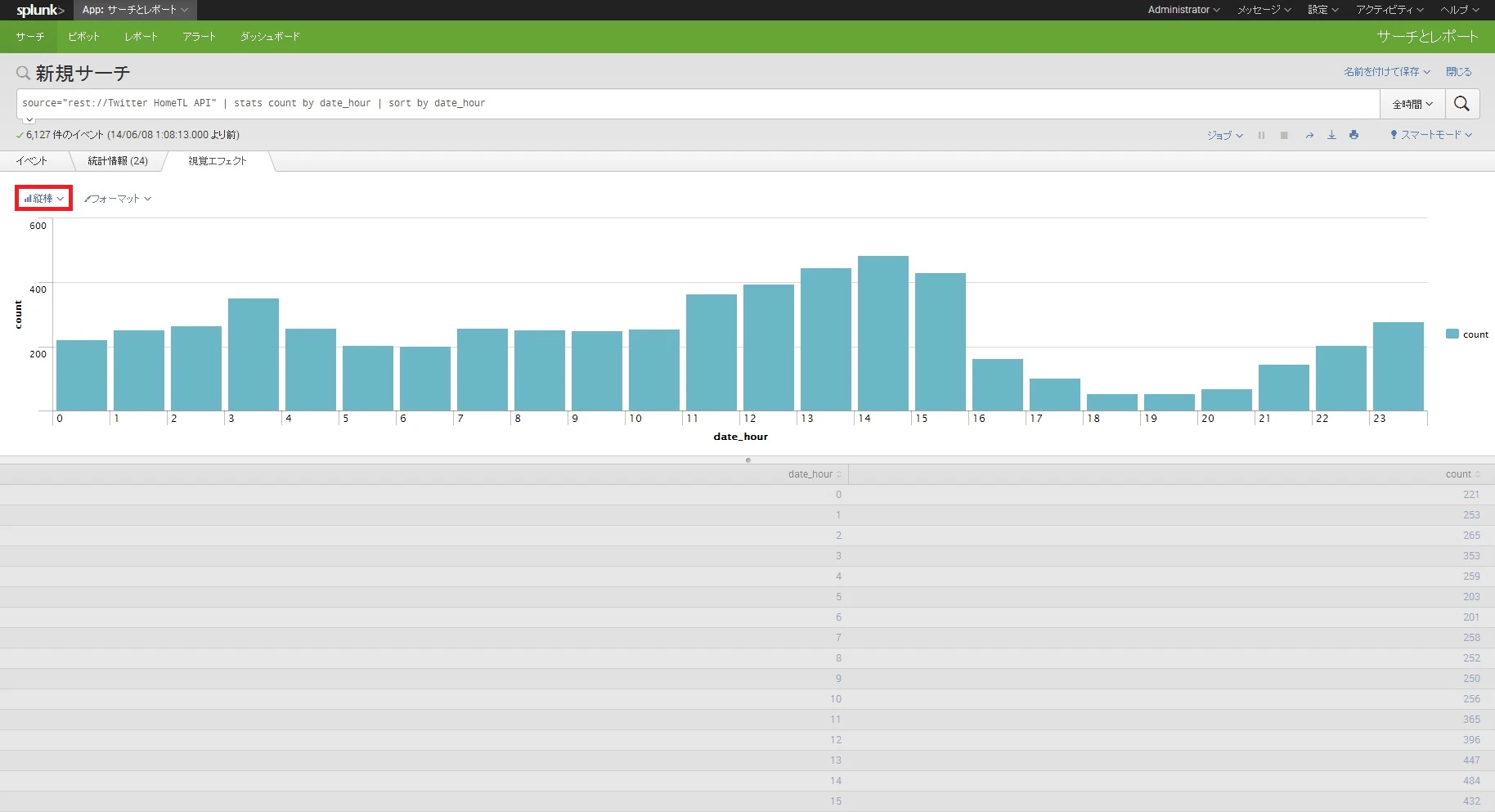
なんということでしょう。
何もしていないのにきれいなグラフが現れました。
赤で囲んだ部分から他の視覚エフェクトも選べますが、時間別統計であれば縦棒が最適でしょう。
このグラフを見るとわかりますが、18-19時台が一番ツイートが少なかったんですね。意外です。
逆に3時でも結構なツイート数があるのにも驚きます。
曜日別つぶやき数
それでは続いて曜日別つぶやき数を見てみましょう。
source="rest://Twitter HomeTL API" | stats count by date_wday | eval sort_field=case(date_wday=="monday",1, date_wday=="tuesday",2, date_wday=="wednesday",3,date_wday=="thursday",4, date_wday=="friday",5, date_wday=="saturday",6,date_wday=="sunday",7) | sort sort_field | fields - sort_field
ずいぶん長いですが、これで曜日別のツイート数を取得することができます。
stats count by date_wdayまではさっきの時間帯別のものと変わりないので説明を省きます。
eval sort_field=case(date_wday=="monday",1, date_wday=="tuesday",2, date_wday=="wednesday",3,date_wday=="thursday",4, date_wday=="friday",5, date_wday=="saturday",6,date_wday=="sunday",7)
ここで何をやっているかというと、ソート用のため各日付にソートが簡単なラベルを与えています。
先ほどSplunkは自分でdate_wdayを持っていると言いましたが、その曜日をソートする機能を標準では提供していません。
(マニュアルにあるのもこの方法です...)
そこで、このクエリでは何をしているかというとevalコマンドで値を評価し、レコードに新たなフィールドsort_fieldを生成しています。
date_wdayの値がmondayならsort_fieldの値を1、というように曜日に対応して7までの値を振るようにしました。
もちろんソートできることが必要なだけなので、値はA~GなんかでもOKです。
そして、sort_fieldが与えられた各レコードをsort_fieldでソートします。
この時点では下記のような出力となります。
| date_wday | count | sort_field |
|---|---|---|
| monday | 1300 | 1 |
| tuesday | 700 | 2 |
で、当然ソートしてしまえばsort_fieldは不要なので
fields - sort_field
で削除します。fields + date_wday, countでも同じことができます。fieldsコマンドではカラムの選択、除外にも使えますし、表示の順序を変えることもできます。
では同じように視覚エフェクトで結果を見てみましょう。

ただ1週間しかデータを収集してないのでこちらの統計には一切信頼性がありませんね。。。
第一、金曜日はエラーでツイートの大半が取れていませんでしたし。
(ちなみにSplunkは自分自身のシステムログもモニタリングしていたりするので、エラーが多数上がる様子がしっかり収集されていました。優秀なんだか情けないんだか。)
クライアント別つぶやき数
では最後にクライアント別つぶやき数を集計したいと思います。
source="rest://Twitter HomeTL API" | spath source | fields source | rex field=source "(<[^>]*>)?(?<rex_source>[^<]*)" | top 10 rex_source
まずはspathですが、これはJSONまたはXMLのようなネスト構造を持つデータからフィールドを抜き出す場合に使います。これを指定しないと、クエリ先頭にあるsourceと解釈されてしまい、求める結果が得られませんので注意が必要です。
spathはデフォルトでデータの先頭5000文字までしか見ないため、大きなデータの場合pathで予め位置を指定してやる必要がありますが、Twitter程度なら大丈夫でしょう多分。
rex field=source "(<[^>]*>)?(?<rex_source>[^<]*)"
ですが、ここは正規表現を使ってsourceフィールドからrex_sourceの値を抜き出します。
Splunkに限らず大量のテキスト処理をする場合に正規表現は非常に強力なので覚えておいて損はないですね。
正規表現の解釈について解説はしませんが、元々sourceフィールドの値は
<a href="http://twicca.r246.jp/" rel="nofollow">twicca</a>
みたいな形をしていますから、上のような<a href>タグに囲まれたtwiccaというようなクライアント名をrex_sourceとして取得するわけなので上のような正規表現になります。
最後にtop 10 rex_sourceですが、指定フィールドの出現割合を集計し、そのTop10を出力します。
これまでのstats countでも同じようなことができますが、こちらは上位を絞って表示できたり、絶対数ではなく全体に対する 割合 で結果が出るなど違いがあります。
では結果を見てみましょう。これは円の視覚エフェクト見るのがいいでしょう。
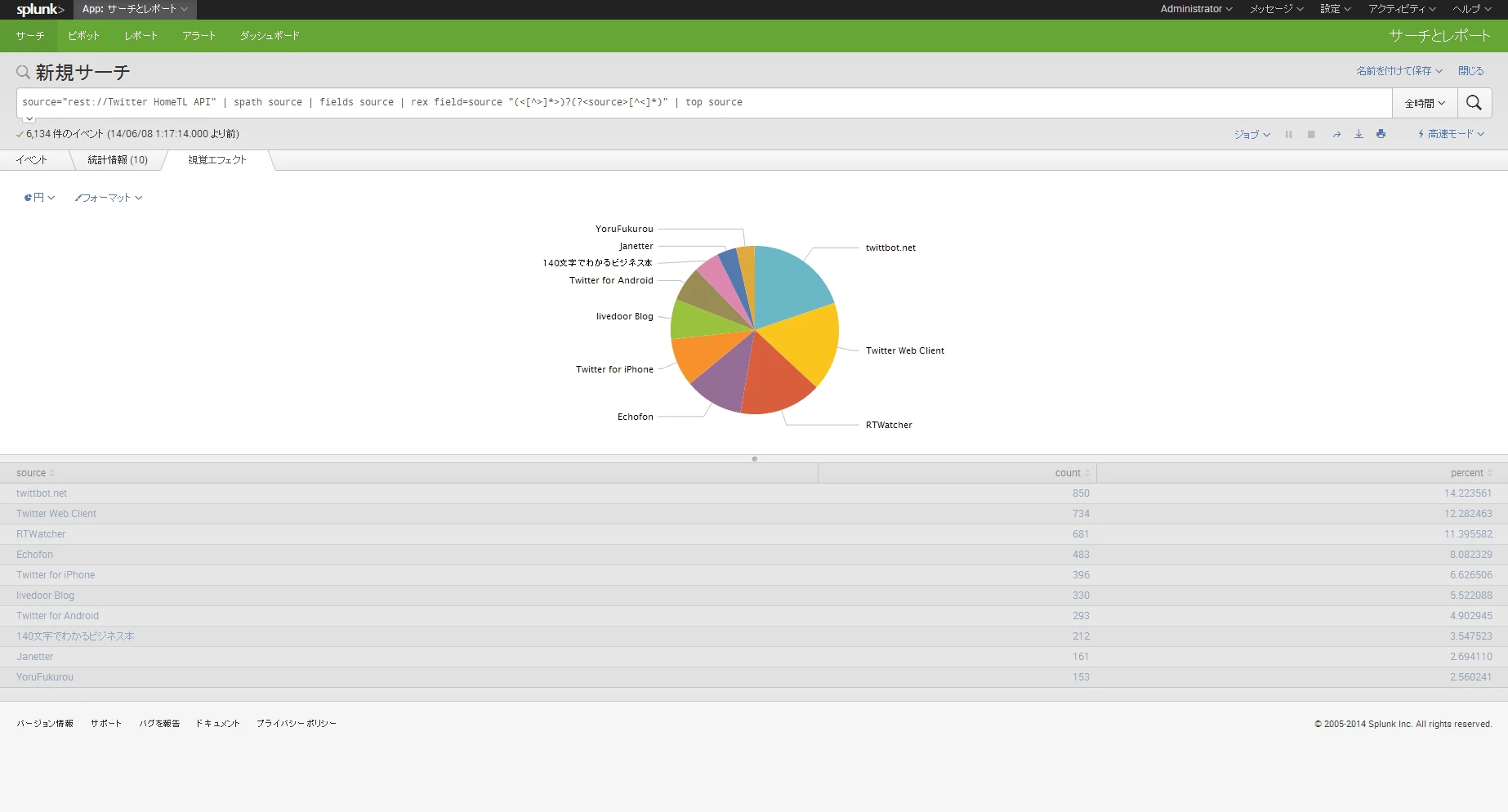
さて、これを見てみると1位がtwittbot.netということで、BOTのツイートがタイムラインの多くを占められていることがわかります。
あまり気づいていませんでしたが、確かにBOTの垂れ流しが多かったのでフォロワー整理をしてBOTをいくつか外しました。。。
雑感
今回はとりあえず思いつくような分析を3つやってみましたが、クエリに対する反応も速く、非常に使いやすい印象です。
まだデータが十分じゃないにせよフォロワー整理などもできたので、分析も無駄ではなかったかなと思ったりしています。
今回で3回目のSplunk記事ですけど、インストール、データ入力、分析とやってきたのでとりあえずは一段落です。
レポートのスケジューリングやダッシュボード作成には触れていませんが、どちらもGUIでポチポチやるだけなんで特に身構えることもないでしょう。
Splunkでのデータ収集は引き続き続けますが、やはり1日500MBの制限から大規模な分析ができないので次からはOSSを使った分析に手を出していこうかなと思います。