はじめに
今日はSplunk用のサーバを作って、そこにTwitter APIから取得したストリームデータをぶち込んでいきたいと思います。
Splunkサーバの用意
スペック
Splunkサーバとして動作するマシンの要件は、公式のスペックシートを参照すると
| Platform | Recommended hardware capacity/configuration | Minimum supported hardware capacity |
|---|---|---|
| Non-Windows platforms | 2x six-core, 2+ GHz CPU, 12 GB RAM, Redundant Array of Independent Disks (RAID) 0 or 1+0, with a 64 bit OS installed. | 1x1.4 GHz CPU, 1 GB RAM |
| Windows platforms | 2x six-core, 2+ GHz CPU, 12 GB RAM, RAID 0 or 1+0, with a 64 bit OS installed. | Pentium 4 or equivalent at 2 GHz, 2 GB RAM |
ということが書いてあります。今回は例によってCentOSを使っていくので、最小要件は1x1.4 GHz CPU, 1 GB RAMあたりですね。
というわけで仮想マシンのスペックとしては
- CentOS 6.5, 2core-CPU, 4GB memory, 500GB HDD, 1 NIC(nat-mode)
くらいにします。
Splunkではデータ蓄積も行うのでHDDを少し多めの500GBにしました。あと、NICは普段ブリッジにしてるんですがNATにしてみました。不都合があればそのときに再構築します。
Splunkのインストール
では素のCentOSにSplunkをインストールしていきたいと思います。
yum install splunk-6.1.1-207789-linux-2.6-x86_64.rpm
基本的にこれで終わりです。rpmパッケージは事前にダウンロードして適当に仮想マシンへ転送しておきます。
Splunkのインストールができたら早速起動なんですが、Splunkの起動停止などはコマンドから実行します。
splunk start
splunk status
splunk stop
ただ、デフォルトだとこのsplunkコマンドのパスが通ってないので、.bashrcあたりにパス設定を書いておく必要があります。
export SPLUNK_HOME=/opt/splunk
PATH=$PATH:$HOME/bin:$SPLUNK_HOME/bin
export PATH
こんな感じ。これから分かるようにSplunk関係のファイルはこのSPLUNK_HOME以下に格納されるのでどんなのが並んでるか見てみてください。収集したデータもデフォルトではこの下に溜まっていきます。
ちなみに特に設定を変えなければこのディレクトリ以下を削除すればアンインストールできます。
さて、追記したらsourceでパスを通しましょう。そうするとSplunk関係のコマンドが見えるようになるはずです。
splunk start [--accept-license]
初回起動時にはライセンス同意事項の確認がずらりと出ます。最後に[y/N]で聞かれますが、問答無用で同意する場合は起動時に上の--accept-licenseオプションを付けてstartします。
また、Splunkはデフォルト設定ではOS起動時に立ち上がらないので、必要に応じてchkconfigあたりをいじるかsplunk enable boot-startを実行しておきましょう。
ここまでで大体Splunkサーバの用意が終了です。iptablesとか場合によってはいじらないといけないかもしれませんが、とりあえず考えないことにします。
Splunk Web UIにアクセス
それではインストールしたばかりのSplunkに早速アクセスしてみましょう。
Splunk Web UIはサーバの8000番ポートで動いているのでhttp://<サーバIP>:8000でアクセスすることができます。
- 別のクライアントマシンからアクセスしようとしたら何故か接続できませんでした。とりあえずteratermでSSH転送しときました。あとで調査します。
【追記】iptables -Fでセキュリティゆるくしたら見れるようになりました。CentOSはデフォルトではSSHしか通さないんですね。
デフォルトではadmin,changemeが管理者アカウントになっているのでそれでログインします。
ログイン後にパスワードを変更させられるので適当に変更しましょう。
これでめでたくSplunk Web UIにログインすることができました。
Twitterデータの投入
では次はTwitterデータの投入を行っていきます。Twitterということで専用のAppが公開されているのでそれを使います。
ホーム画面下部の他のAppを検索ボタンをクリック。
すると色々なAppが見えると思うので、素直に画面右上の検索ボックスからTwitterで検索しましょう。
多分1件App for Twitter Dataというのが見つかると思うのでそれをインストールしましょう。ここで聞かれるアカウントは最初のrpm入手に使ったSplunk.com側のアカウントです。
インストール後、再起動したらSplunk Web UIのホーム画面にTwitterのAppが作成されているはずです。
あとはセットアップ画面から Twitter API のトークンたちを入力してやれば...
(Twitter APIの設定についてはこの後で説明します)
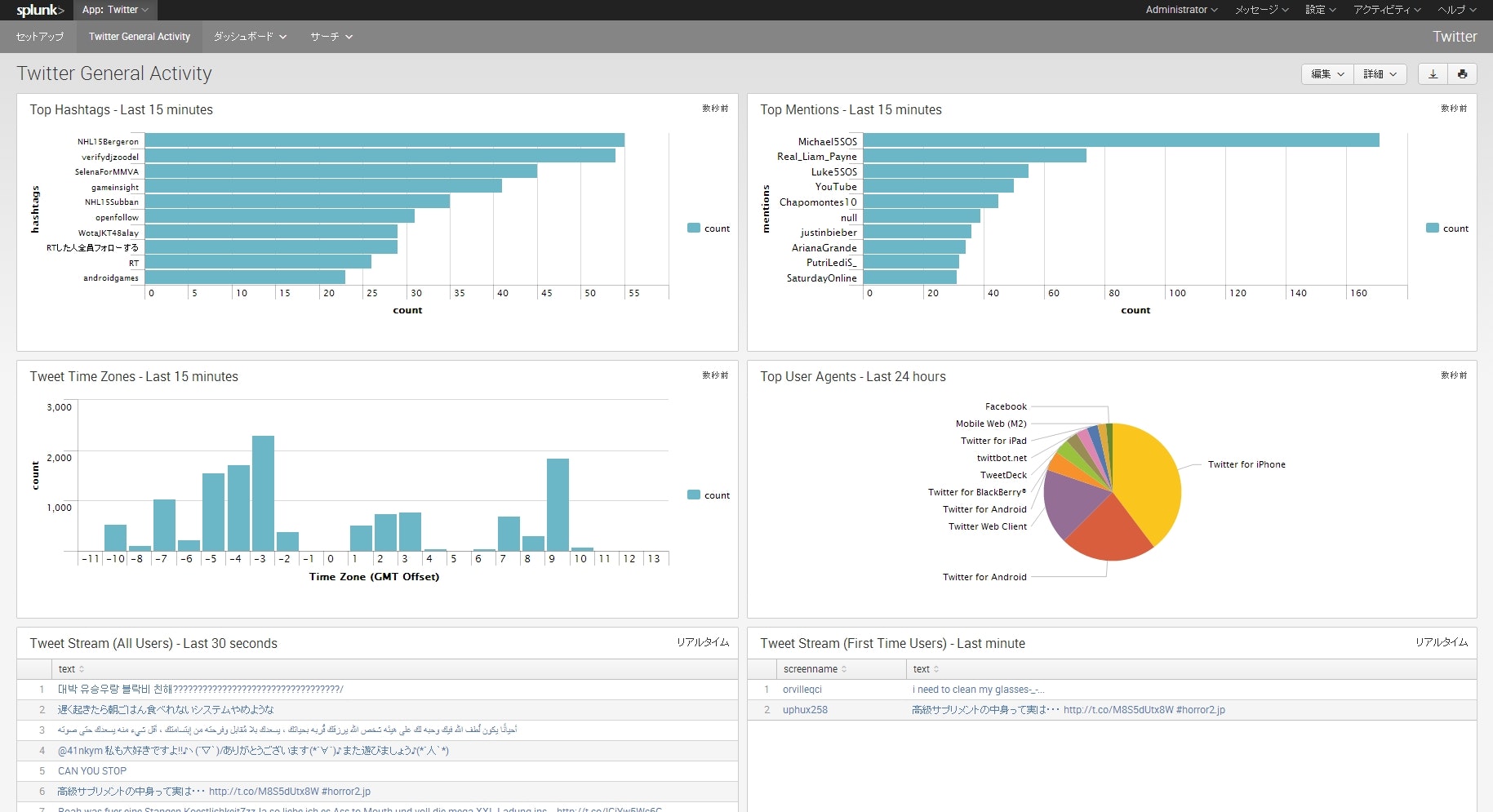
この通りTwitterに関するデータがずらりと出てきます。
ただ、ここのデータはどうやらサンプルデータのようなので次回以降で自分のTLにする方法を探します。
Twitter APIの設定
Twitterは外部にAPIを公開しており、そのAPIからTwitterデータの入手やAPI経由の投稿などが可能です。
Twitter APIの設定はDevelopersから行うことができます。
こちらから手持ちのアカウントでログインし、右上にある自分のアイコンからMy Applications → Create New Appボタンで新しいAPIを作成することができます。
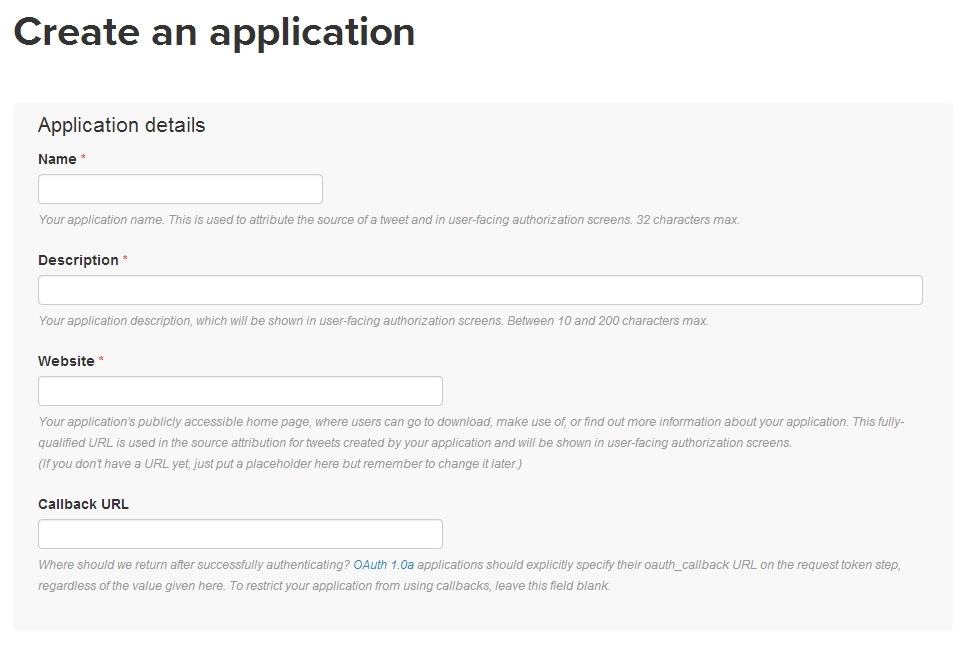
API名、API説明、使用するWebサイトURLが必須になっているのでそこを入力しましょう。
WebサイトURLは今回の例でいくと存在しないので適当でOKです。存在しなくても構いません。
APIが作成できたらAPIの管理画面に入って、API Keysタブに移動してください。
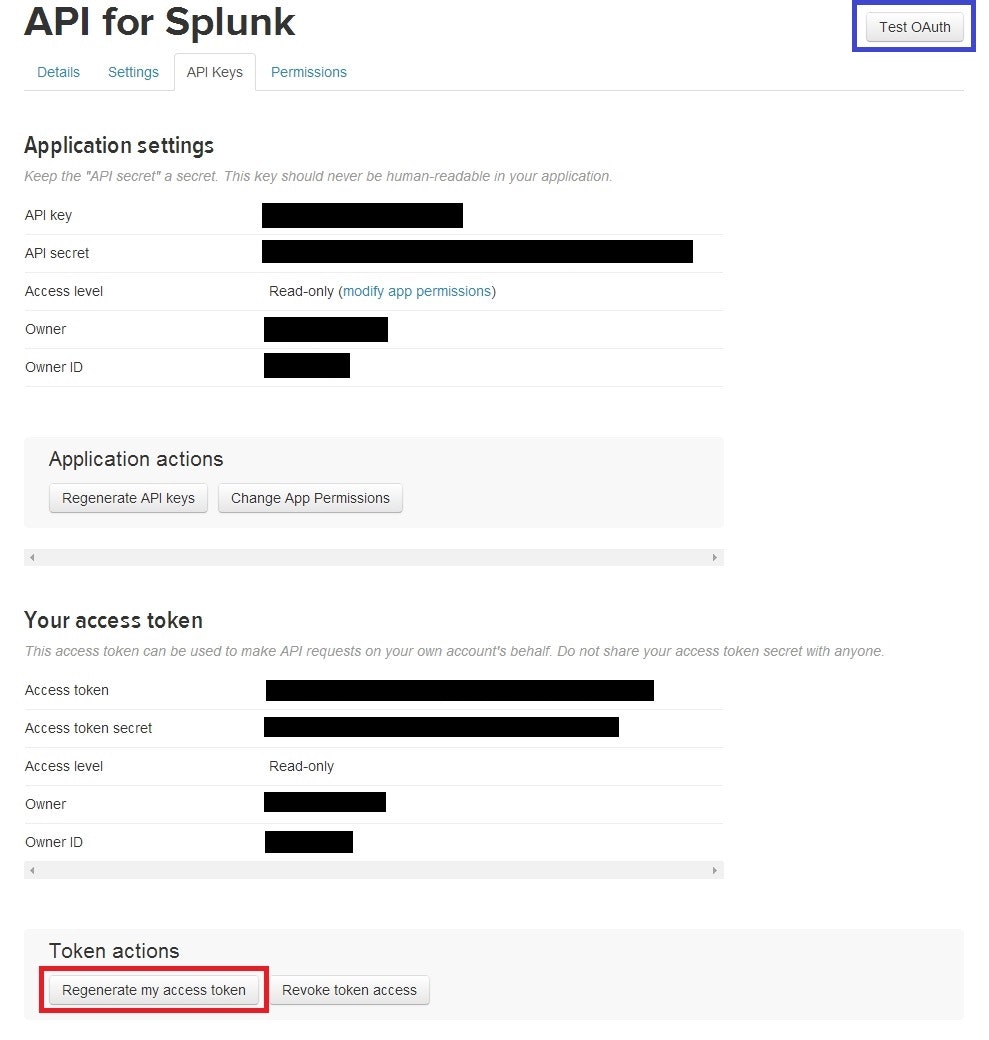
最初は上のApplication Settingsしか見えてないと思いますが、最初は赤で囲んだあたりにCreate my access tokenというボタンがあるのでaccess tokenを生成してください。
少し時間がかかりますが、30秒くらいでaccess tokenが発行されると思います。右上の青で囲んだTest OAuthボタンで遷移した先にずらっとキーが並んでいなければaccess tokenが発行されていないのでもう少し待つか再作成をしてみてください。
他のAPIへの応用
今回はTwitter APIからデータを取得していますが、結局はTwitter用のSplunk Appを使っているので「 じゃあ他のAPIからはどうデータ取るの? 」って話になりますが、一般のAPIに関してはREST API Modular Inputを使うといいようです。
こちらについてはまた別の機会に試したいと思います。
→ 次回 : SplunkにTwitterのデータをぶちこむ(自分のタイムライン)。
参考
参考にさせていただいたページです。
-
Splunkについて色々と試していらっしゃる方です。今回の内容ではその2までが含まれます。
-
How to Stream Twitter into Splunk in 10 Simple Steps
今回はTwitter Appを使ってデータを取得していますが、こちらでREST API Modular Inputを使ったデータ取得が紹介されています。